Eine neue Methode, um programmiersprachen mit Garbage Collection effizient in WebAssembly zu integrieren
Ein kürzlich erschienener Artikel über WebAssembly Garbage Collection (WasmGC) erklärt auf hoher Ebene, wie der Garbage Collection (GC) Vorschlag darauf abzielt, die Unterstützung von Programmiersprachen mit Garbage Collection in Wasm zu verbessern, was angesichts ihrer Beliebtheit sehr wichtig ist. In diesem Artikel werden wir uns mit den technischen Details befassen, wie GC-Sprachen wie Java, Kotlin, Dart, Python und C# nach Wasm portiert werden können. Es gibt tatsächlich zwei Hauptansätze:
- Der “traditionelle” Portierungsansatz, bei dem eine bestehende Implementierung der Sprache zu WasmMVP kompiliert wird, also dem 2017 eingeführten WebAssembly Minimum Viable Product.
- Der WasmGC Portierungsansatz, bei dem die Sprache direkt auf GC-Konstrukte in Wasm kompiliert wird, die im aktuellen GC-Vorschlag definiert sind.
Wir werden erklären, was diese beiden Ansätze sind und welche technischen Kompromisse zwischen ihnen bestehen, insbesondere hinsichtlich Größe und Geschwindigkeit. Dabei werden wir sehen, dass WasmGC mehrere große Vorteile hat, aber auch neue Arbeit sowohl in Toolchains als auch in virtuellen Maschinen (VMs) erfordert. Die späteren Abschnitte dieses Artikels werden erklären, was das V8-Team in diesen Bereichen tut, einschließlich Benchmark-Zahlen. Wenn Sie an Wasm, GC oder beidem interessiert sind, hoffen wir, dass Sie dies interessant finden, und stellen Sie sicher, dass Sie die Demonstration und die Links für den Einstieg am Ende überprüfen!
Der “Traditionelle” Portierungsansatz
Wie werden Sprachen typischerweise auf neue Architekturen portiert? Nehmen wir an, Python möchte auf der ARM-Architektur laufen, oder Dart möchte auf der MIPS-Architektur laufen. Die allgemeine Idee ist dann, die VM auf diese Architektur neu zu kompilieren. Darüber hinaus, wenn die VM architekturspezifischen Code wie Just-in-Time (JIT) oder Ahead-of-Time (AOT) Kompilierung hat, implementieren Sie auch ein Backend für JIT/AOT für die neue Architektur. Dieser Ansatz macht viel Sinn, weil oft der Hauptteil des Code-Basis einfach für jede neue Architektur, zu der Sie portieren, neu kompiliert werden kann:

In dieser Abbildung werden der Parser, die Bibliotheksunterstützung, der Garbage Collector, der Optimierer usw. zwischen allen Architekturen im Haupt-Laufzeitcode geteilt. Das Portieren auf eine neue Architektur erfordert nur ein neues Backend dafür, was relativ wenig Code ist.
Wasm ist ein Compiler-Ziel auf niedriger Ebene, und es ist daher nicht überraschend, dass der traditionelle Portierungsansatz verwendet werden kann. Seitdem Wasm zum ersten Mal eingeführt wurde, haben wir gesehen, dass dies in der Praxis in vielen Fällen gut funktioniert, wie z. B. Pyodide für Python und Blazor für C# (beachten Sie, dass Blazor sowohl AOT als auch JIT Kompilierung unterstützt, was es zu einem schönen Beispiel für all das macht). In allen diesen Fällen wird eine Laufzeit für die Sprache in WasmMVP kompiliert, genau wie jedes andere Programm, das zu Wasm kompiliert wird, und das Ergebnis verwendet daher die lineare Speicherstruktur, Tabelle, Funktionen usw.
Wie bereits erwähnt, werden auf diese Weise Sprachen typischerweise auf neue Architekturen portiert, was aus dem üblichen Grund sehr sinnvoll ist, dass Sie fast den gesamten bestehenden VM-Code wiederverwenden können, einschließlich Sprachimplementierung und Optimierungen. Es stellt sich jedoch heraus, dass es mehrere Wasm-spezifische Nachteile dieses Ansatzes gibt, und hier kann WasmGC helfen.
Der WasmGC Portierungsansatz
Kurz gesagt, der GC-Vorschlag für WebAssembly (“WasmGC”) ermöglicht es Ihnen, Struktur- und Array-Typen zu definieren und Operationen wie das Erstellen von Instanzen davon, das Lesen aus und Schreiben in Felder, das Konvertieren zwischen Typen usw. auszuführen (für weitere Details siehe Übersicht des Vorschlags). Diese Objekte werden durch die eigene GC-Implementierung der Wasm-VM verwaltet, was der Hauptunterschied zwischen diesem Ansatz und dem traditionellen Portierungsansatz ist.
Es kann hilfreich sein, es so zu betrachten: Wenn der traditionelle Portierungsansatz die Art und Weise ist, wie man eine Sprache auf eine Architektur portiert, dann ähnelt der WasmGC-Ansatz stark der Art und Weise, wie man eine Sprache auf eine VM portiert. Zum Beispiel, wenn Sie Java auf JavaScript portieren möchten, können Sie einen Compiler wie J2CL verwenden, der Java-Objekte als JavaScript-Objekte darstellt, und diese JavaScript-Objekte werden dann von der JavaScript-VM wie alle anderen verwaltet. Das Portieren von Sprachen auf bestehende VMs ist eine sehr nützliche Technik, wie man an allen Sprachen sehen kann, die auf JavaScript, die JVM und die CLR kompiliert werden.
Diese Architektur/VM-Metapher ist keine exakte, insbesondere weil WasmGC beabsichtigt, auf einer niedrigeren Ebene zu operieren als die anderen VMs, die wir im letzten Absatz erwähnt haben. Trotzdem definiert WasmGC VM-verwaltete Strukturen und Arrays sowie ein Typsystem zur Beschreibung ihrer Formen und Beziehungen, und das Portieren nach WasmGC ist der Prozess der Repräsentation der Konstrukte Ihrer Sprache mit diesen Primitiven. Dies ist sicherlich höher als ein traditioneller Port zu WasmMVP (bei dem alles in ungetypte Bytes im linearen Speicher abgesenkt wird). Daher ist WasmGC dem Portieren von Sprachen zu VMs recht ähnlich, und es teilt die Vorteile solcher Ports, insbesondere eine gute Integration mit der Ziel-VM und die Wiederverwendung ihrer Optimierungen.
Vergleich der beiden Ansätze
Nun, da wir eine Vorstellung davon haben, wie die beiden Portierungsansätze für GC-Sprachen aussehen, lassen Sie uns sehen, wie sie sich vergleichen lassen.
Speicherverwaltungs-Code bereitstellen
In der Praxis wird viel Wasm-Code in einer VM ausgeführt, die bereits einen Garbage Collector hat, was im Web der Fall ist und auch in Laufzeiten wie Node.js, workerd, Deno und Bun. An solchen Orten fügt das Bereitstellen einer GC-Implementierung der Wasm-Binärdatei unnötige Größe hinzu. Tatsächlich ist dies nicht nur ein Problem bei GC-Sprachen in WasmMVP, sondern auch bei Sprachen, die linearen Speicher verwenden, wie C, C++ und Rust, da Code in diesen Sprachen, der jegliche Art von interessanter Zuweisung vornimmt, am Ende malloc/free einbinden wird, um linearen Speicher zu verwalten, was mehrere Kilobytes Code erfordert. Zum Beispiel benötigt dlmalloc 6K, und selbst ein malloc, das Geschwindigkeit gegen Größe eintauscht, wie emmalloc, nimmt über 1K ein. WasmGC hingegen lässt den Speicher automatisch von der VM verwalten, sodass wir in Wasm überhaupt keinen Speicherverwaltungs-Code benötigen—weder einen GC noch malloc/free. In dem zuvor erwähnten Artikel über WasmGC wurde die Größe des fannkuch-Benchmarks gemessen, und WasmGC war aus genau diesem Grund viel kleiner als C oder Rust—2.3 K gegenüber 6.1-9.6 K.
Zyklensammlung
In Browsern interagiert Wasm oft mit JavaScript (und über JavaScript mit Web-APIs), aber in WasmMVP (und sogar mit dem Referenztypen-Vorschlag) gibt es keine Möglichkeit, bidirektionale Verbindungen zwischen Wasm und JS zu haben, die es ermöglichen, Zyklen auf feinkörnige Weise zu sammeln. Verknüpfungen zu JS-Objekten können nur in der Wasm-Tabelle platziert werden, und Verknüpfungen zurück zu Wasm können sich nur auf die gesamte Wasm-Instanz als ein einziges großes Objekt beziehen, wie folgt:

Das reicht nicht aus, um spezifische Objektzyklen effizient zu sammeln, bei denen sich einige Objekte in der kompilierten VM und andere in JavaScript befinden. Mit WasmGC hingegen definieren wir Wasm-Objekte, die der VM bekannt sind, und wir können daher richtige Referenzen von Wasm zu JavaScript und zurück haben:

GC-Referenzen auf dem Stack
GC-Sprachen müssen sich der Referenzen auf dem Stack bewusst sein, also von lokalen Variablen in einem Aufrufbereich, da solche Referenzen möglicherweise das Einzige sind, was ein Objekt am Leben hält. In einem traditionellen Port einer GC-Sprache ist das ein Problem, weil Wasms Sandboxing Programme daran hindert, ihren eigenen Stack zu inspizieren. Es gibt Lösungen für traditionelle Ports, wie einen Schatten-Stack (der automatisch erstellt werden kann), oder die Sammlung von Müll nur dann, wenn nichts auf dem Stack ist (was zwischen den Runden der JavaScript-Ereignisschleife der Fall ist). Eine mögliche zukünftige Ergänzung, die traditionellen Ports helfen könnte, wäre Stack-Scan-Unterstützung in Wasm. Zurzeit kann nur WasmGC Stapelreferenzen ohne Overhead verwalten, und das geschieht völlig automatisch, da die Wasm-VM für die GC verantwortlich ist.
GC-Effizienz
Ein verwandtes Thema ist die Effizienz bei der Durchführung einer GC. Beide Portierungsansätze haben hier potenzielle Vorteile. Eine traditionelle Portierung kann Optimierungen einer bestehenden VM wiederverwenden, die möglicherweise auf eine bestimmte Programmiersprache zugeschnitten sind, wie zum Beispiel eine starke Fokussierung auf die Optimierung von Innenzeigern oder kurzlebigen Objekten. Eine WasmGC-Portierung, die im Web läuft, hat hingegen den Vorteil, die gesamte Arbeit zu nutzen, die bereits in die Beschleunigung der JavaScript-GC gesteckt wurde, einschließlich Techniken wie Generations-GC, inkrementelle Sammlung usw. WasmGC überlässt die GC der VM, was Dinge wie effiziente Schreibbarrieren vereinfacht.
Ein weiterer Vorteil von WasmGC ist, dass die GC für Dinge wie Speicherengpässe sensibel sein kann und ihre Heap-Größe und Sammlungsfrequenz entsprechend anpassen kann, ähnlich wie dies JavaScript-VMs bereits im Web tun.
Speicherfragmentierung
Mit der Zeit, insbesondere bei lang laufenden Programmen, können malloc/free-Operationen in der WasmMVP-linearen Speicherstruktur Fragmentierung verursachen. Stellen Sie sich vor, wir haben insgesamt 2 MB Speicher und genau in der Mitte davon eine bestehende kleine Zuweisung von nur wenigen Bytes. In Sprachen wie C, C++ und Rust ist es unmöglich, eine beliebige Zuweisung zur Laufzeit zu verschieben, daher haben wir fast 1MB links von dieser Zuweisung und fast 1MB rechts davon. Aber dies sind zwei separate Fragmente, und wenn wir versuchen, 1,5 MB zuzuweisen, wird dies scheitern, obwohl wir diese Menge an nicht zugewiesenem Gesamtspeicher tatsächlich haben:

Solche Fragmentierung kann ein Wasm-Modul dazu zwingen, seinen Speicher häufiger zu erweitern, was Overhead hinzufügt und zu Speicherfehlern führen kann; Verbesserungen werden entworfen, aber es ist ein herausforderndes Problem. Dies ist ein Problem in allen WasmMVP-Programmen, einschließlich traditioneller Portierungen von GC-Sprachen (beachten Sie, dass die GC-Objekte selbst beweglich sein könnten, nicht aber Teile der Laufzeit selbst). WasmGC hingegen vermeidet dieses Problem, da der Speicher vollständig von der VM verwaltet wird, die sie verschieben kann, um den GC-Heap zu verdichten und Fragmentierung zu vermeiden.
Integration von Entwicklerwerkzeugen
In einer traditionellen Portierung zu WasmMVP werden Objekte im linearen Speicher platziert, was es Entwicklertools schwer macht, nützliche Informationen bereitzustellen, da solche Werkzeuge nur Bytes sehen, ohne hochgradige Typinformationen. In WasmGC hingegen werden die GC-Objekte von der VM verwaltet, sodass eine bessere Integration möglich ist. Zum Beispiel können Sie in Chrome den Heap-Profiler verwenden, um die Speichernutzung eines WasmGC-Programms zu messen:
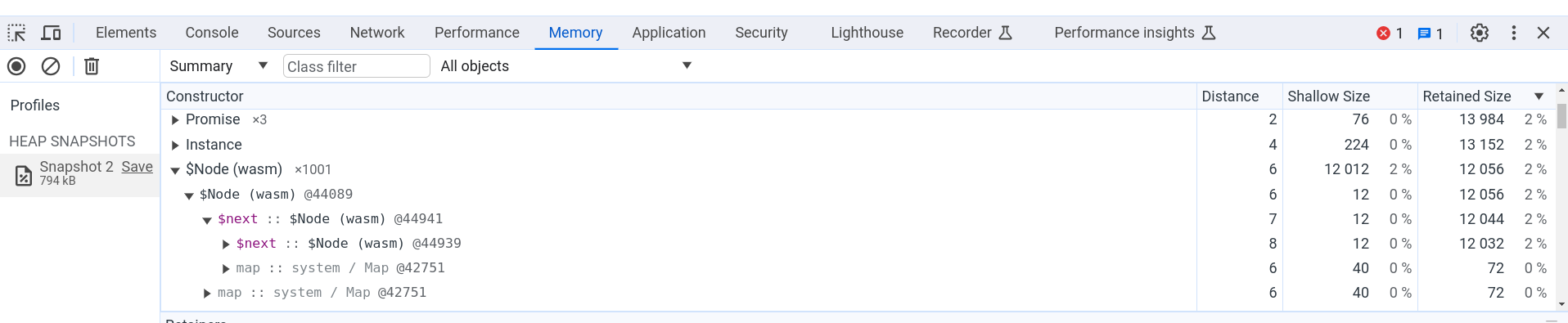
Die obige Abbildung zeigt den Speicher-Tab in den Chrome-DevTools, wo wir einen Heap-Snapshot einer Seite haben, die WasmGC-Code ausgeführt hat, der 1.001 kleine Objekte in einer Verketteten Liste erstellt hat. Sie können den Namen des Objekttyps $Node und das Feld $next sehen, das sich auf das nächste Objekt in der Liste bezieht. Alle üblichen Heap-Snapshot-Informationen sind vorhanden, wie die Anzahl der Objekte, die direkte Größe, die beibehaltene Größe usw., sodass wir leicht sehen können, wie viel Speicher tatsächlich von WasmGC-Objekten verwendet wird. Andere Chrome-DevTools-Funktionen wie der Debugger funktionieren ebenfalls mit WasmGC-Objekten.
Sprachsemantik
Wenn Sie eine VM bei einer traditionellen Portierung neu kompilieren, erhalten Sie die genaue Sprache, die Sie erwarten, da Sie den Ihnen vertrauten Code ausführen, der diese Sprache implementiert. Das ist ein großer Vorteil! Im Vergleich dazu könnten Sie bei einer WasmGC-Portierung Kompromisse in der Semantik eingehen müssen, im Austausch für Effizienz. Das liegt daran, dass wir bei WasmGC neue GC-Typen definieren—Strukturen und Arrays—und darauf kompilieren. Dadurch können wir nicht einfach eine in C, C++, Rust oder ähnlichen Sprachen geschriebene VM in diese Form kompilieren, da diese nur auf linearen Speicher kompiliert und daher WasmGC bei der großen Mehrheit bestehender VM-Codebasen nicht helfen kann. Stattdessen schreiben Sie bei einer WasmGC-Portierung typischerweise neuen Code, der die Konstrukte Ihrer Sprache in WasmGC-Primitiven transformiert. Und es gibt mehrere Möglichkeiten, diese Transformation durchzuführen, mit unterschiedlichen Kompromissen.
Ob Kompromisse notwendig sind oder nicht, hängt davon ab, wie die Konstrukte einer bestimmten Sprache in WasmGC implementiert werden können. Beispielsweise haben WasmGC-Strukturfelder feste Indexe und Typen, sodass eine Sprache, die Felder auf eine dynamischere Weise zugreifen möchte, Herausforderungen haben könnte; es gibt verschiedene Möglichkeiten, das zu umgehen, und in diesem Lösungsspektrum könnten einige Optionen einfacher oder schneller sein, aber nicht die vollständige ursprüngliche Semantik der Sprache unterstützen. (WasmGC hat auch andere aktuelle Einschränkungen, beispielsweise fehlen Innenzeiger; im Laufe der Zeit wird erwartet, dass solche Dinge verbessert werden.)
Wie bereits erwähnt, ist das Kompilieren zu WasmGC ähnlich wie das Kompilieren zu einer bestehenden VM, und es gibt viele Beispiele für kompromissbereite Ansätze, die in solchen Portierungen sinnvoll sind. Zum Beispiel verhalten sich Zahlen in dart2js (Dart, kompiliert in JavaScript) anders als in der Dart-VM, und verhalten sich Strings in IronPython (Python, kompiliert in .NET) wie C#-Strings. Daher können nicht alle Programme einer Sprache in solchen Portierungen ausgeführt werden, jedoch gibt es gute Gründe für diese Entscheidungen: Die Implementierung von dart2js-Zahlen als JavaScript-Zahlen ermöglicht es VMs, diese gut zu optimieren, und die Verwendung von .NET-Strings in IronPython bedeutet, dass man diese Strings ohne Overhead an anderen .NET-Code übergeben kann.
Während in WasmGC-Portierungen Kompromisse erforderlich sein können, hat WasmGC im Vergleich zu JavaScript als Compilerziel auch einige Vorteile. Zum Beispiel hat dart2js die erwähnten Numerik-Einschränkungen, aber dart2wasm (Dart, kompiliert in WasmGC) verhält sich genau so, wie es sein sollte, ohne Kompromisse (das ist möglich, da Wasm effiziente Darstellungen für die numerischen Typen bietet, die Dart benötigt).
Warum ist dies bei traditionellen Portierungen kein Problem? Einfach deshalb, weil sie eine bestehende VM in linearen Speicher umkompilieren, wobei Objekte in untypisierten Bytes gespeichert werden, die eine niedrigere Ebene darstellen als WasmGC. Wenn man nur untypisierte Bytes hat, hat man deutlich mehr Flexibilität, eine Vielzahl von niedrigstufigen (und potenziell unsicheren) Tricks anzuwenden, und durch das Umkompilieren einer bestehenden VM erhält man alle Tricks, die diese VM bieten kann.
Aufwand für die Toolchain
Wie wir im vorherigen Abschnitt erwähnt haben, kann man eine bestehende VM nicht einfach in eine WasmGC-Portierung umkompilieren. Man könnte bestimmten Code wiederverwenden (wie etwa Parser-Logik und AOT-Optimierungen, da diese nicht zur Laufzeit mit dem GC integriert werden), aber im Allgemeinen erfordert eine WasmGC-Portierung eine beträchtliche Menge an neuem Code.
Im Vergleich dazu können traditionelle Portierungen zu WasmMVP einfacher und schneller sein: Zum Beispiel kann die Lua-VM (geschrieben in C) in nur wenigen Minuten in Wasm kompiliert werden. Eine WasmGC-Portierung von Lua hingegen würde mehr Aufwand erfordern, da man Code schreiben müsste, um die Lua-Konstrukte in WasmGC-Strukturen und -Arrays umzuwandeln, und man müsste entscheiden, wie dies innerhalb der spezifischen Einschränkungen des WasmGC-Typsystems zu tun ist.
Ein größerer Aufwand für die Toolchain ist daher ein wesentlicher Nachteil der WasmGC-Portierung. Dennoch halten wir WasmGC angesichts all der zuvor genannten Vorteile für sehr attraktiv! Die ideale Situation wäre eine, in der das Typsystem von WasmGC alle Sprachen effizient unterstützen könnte und alle Sprachen den Aufwand betreiben würden, eine WasmGC-Portierung zu implementieren. Der erste Teil davon wird durch zukünftige Ergänzungen zum WasmGC-Typsystem erleichtert, und für den zweiten Teil können wir die Arbeit, die in WasmGC-Portierungen steckt, reduzieren, indem wir den Aufwand auf der Seite der Toolchain so weit wie möglich teilen. Glücklicherweise stellt sich heraus, dass WasmGC es sehr praktikabel macht, die Toolchain-Arbeit zu teilen, wie wir im nächsten Abschnitt sehen werden.
WasmGC optimieren
Wir haben bereits erwähnt, dass WasmGC-Portierungen potenzielle Geschwindigkeitsvorteile haben, wie etwa die Nutzung von weniger Speicher und die Wiederverwendung von Optimierungen im Host-GC. In diesem Abschnitt zeigen wir weitere interessante Optimierungsvorteile von WasmGC gegenüber WasmMVP auf, die einen großen Einfluss darauf haben können, wie WasmGC-Portierungen entworfen werden und wie schnell die Endergebnisse sind.
Das Schlüsselproblem hierbei ist, dass WasmGC höherstufig ist als WasmMVP. Um ein Gefühl dafür zu bekommen, erinnern Sie sich daran, dass wir bereits gesagt haben, dass eine traditionelle Portierung zu WasmMVP wie eine Portierung zu einer neuen Architektur ist, während eine WasmGC-Portierung einer Portierung zu einer neuen VM ähnelt – und VMs sind natürlich höherstufige Abstraktionen über Architekturen, und höherstufige Darstellungen sind oft optimierbarer. Dies sehen wir vielleicht noch deutlicher an einem konkreten Beispiel in Pseudocode:
func foo() {
let x = allocate<T>(); // Ein GC-Objekt zuweisen.
x.val = 10; // Ein Feld auf 10 setzen.
let y = allocate<T>(); // Ein weiteres Objekt zuweisen.
y.val = x.val; // Dies muss 10 sein.
return y.val; // Auch dies muss 10 sein.
}
Wie die Kommentare angeben, enthält x.val den Wert 10, ebenso wie y.val, sodass die endgültige Rückgabe ebenfalls 10 beträgt. Der Optimierer kann sogar die Zuweisungen entfernen, was zu diesem Ergebnis führt:
func foo() {
return 10;
}
Großartig! Leider ist das in WasmMVP nicht möglich, da jede Zuweisung in einen Aufruf von malloc umgewandelt wird, eine umfangreiche und komplexe Funktion im Wasm, die Nebeneffekte auf den linearen Speicher hat. Aufgrund dieser Nebeneffekte muss der Optimierer davon ausgehen, dass die zweite Zuweisung (für y) möglicherweise x.val ändert, da sich dieser ebenfalls im linearen Speicher befindet. Speicherverwaltung ist komplex, und wenn wir sie auf niedriger Ebene innerhalb von Wasm implementieren, sind unsere Optimierungsmöglichkeiten begrenzt.
Im Gegensatz dazu arbeiten wir in WasmGC auf einer höheren Ebene: Jede Zuweisung führt die Anweisung struct.new aus, eine VM-Operation, die wir tatsächlich nachvollziehen können, und ein Optimierer kann auch Referenzen verfolgen, um zu dem Schluss zu kommen, dass x.val genau einmal mit dem Wert 10 beschrieben wird. Dadurch können wir diese Funktion wie erwartet auf eine einfache Rückgabe von 10 optimieren!
Abgesehen von Zuweisungen fügt WasmGC weitere Funktionen hinzu, wie explizite Funktionszeiger (ref.func) und Aufrufe, die diese verwenden (call_ref), Typen für Felder von Strukturen und Arrays (im Gegensatz zu untypisiertem linearem Speicher) und mehr. Daher ist WasmGC eine höherstufige Intermediate Representation (IR) als WasmMVP und deutlich optimierbarer.
Wenn WasmMVP nur begrenzte Optimierungsmöglichkeiten bietet, warum ist es dann trotzdem so schnell? Wasm kann schließlich nahe an der vollen nativen Geschwindigkeit laufen. Das liegt daran, dass WasmMVP in der Regel das Ergebnis eines leistungsstarken optimierenden Compilers wie LLVM ist. LLVM IR hat, ähnlich wie WasmGC und im Gegensatz zu WasmMVP, eine spezielle Darstellung für Speicherzuweisungen und dergleichen, sodass LLVM die Dinge optimieren kann, über die wir gesprochen haben. Das Design von WasmMVP sieht vor, dass die meisten Optimierungen auf der Toolchain-Ebene vor Wasm stattfinden, und Wasm-VMs übernehmen nur die „letzte Meile“ der Optimierung (wie z. B. die Registerzuweisung).
Kann WasmGC ein ähnliches Toolchain-Modell wie WasmMVP übernehmen und insbesondere LLVM nutzen? Leider nein, da LLVM WasmGC nicht unterstützt (ein gewisser Support wurde untersucht, aber es ist schwer vorstellbar, wie eine vollständige Unterstützung überhaupt funktionieren könnte). Außerdem verwenden viele GC-Sprachen LLVM nicht – es gibt eine breite Vielfalt an Compiler-Toolchains in diesem Bereich. Deshalb brauchen wir für WasmGC etwas anderes.
Glücklicherweise ist WasmGC, wie erwähnt, sehr optimierbar, und das eröffnet neue Möglichkeiten. Hier ist eine Art, das zu betrachten:

Sowohl die WasmMVP- als auch die WasmGC-Workflows beginnen mit den gleichen beiden Kästchen links: Wir starten mit Quellcode, der auf eine sprachspezifische Weise verarbeitet und optimiert wird (was jede Sprache am besten über sich selbst weiß). Dann tritt ein Unterschied auf: Für WasmMVP müssen wir zuerst allgemeine Optimierungen vornehmen und dann auf Wasm absenken, während wir bei WasmGC die Möglichkeit haben, zuerst auf Wasm abzusenken und später zu optimieren. Das ist wichtig, da es von großem Vorteil ist, nach der Absenkung zu optimieren: Dann können wir Toolchain-Code für allgemeine Optimierungen zwischen allen Sprachen, die nach WasmGC kompilieren, teilen. Die nächste Abbildung zeigt, wie das aussieht:
.")
Da wir allgemeine Optimierungen nach der Kompilierung in WasmGC durchführen können, kann ein Wasm-zu-Wasm-Optimizer allen WasmGC-Compiler-Toolchains helfen. Aus diesem Grund hat das V8-Team in WasmGC in Binaryen investiert, das alle Toolchains als wasm-opt-Kommandozeilenwerkzeug verwenden können. Darauf werden wir im nächsten Unterabschnitt eingehen.
Toolchain-Optimierungen
Binaryen, das WebAssembly-Toolchain-Optimizer-Projekt, hatte bereits eine breite Palette von Optimierungen für WasmMVP-Inhalte wie Inlining, Konstantenweiterleitung, Dead-Code-Eliminierung usw., von denen fast alle auch für WasmGC gelten. Wie bereits erwähnt, ermöglicht uns WasmGC jedoch, weit mehr Optimierungen durchzuführen als WasmMVP, und wir haben dementsprechend viele neue Optimierungen geschrieben:
- Escape-Analyse zur Verschiebung von Heap-Speicherzuweisungen in Lokale.
- Devirtualisierung, um indirekte Aufrufe in direkte umzuwandeln (die dann potenziell inlined werden können).
- Leistungsstärkere globale Dead-Code-Eliminierung.
- Typbewusste Content-Flow-Analyse für das gesamte Programm (GUFA).
- Cast-Optimierungen wie das Entfernen redundanter Casts und deren Verschiebung an frühere Stellen.
- Typ-Beschneidung.
- Typ-Zusammenführung.
- Typ-Verfeinerung (für Lokale, Globale, Felder und Signaturen).
Das ist nur eine kurze Liste einiger Arbeiten, die wir geleistet haben. Weitere Informationen zu Binaryens neuen GC-Optimierungen und deren Verwendung finden Sie in den Binaryen-Dokumenten.
Um die Effektivität all dieser Optimierungen in Binaryen zu messen, betrachten wir die Java-Performance mit und ohne wasm-opt auf der Ausgabe des J2Wasm-Compilers, der Java nach WasmGC kompiliert:

Hier bedeutet „ohne wasm-opt“, dass wir Binaryens Optimierungen nicht ausführen, aber dennoch in der VM und im J2Wasm-Compiler optimieren. Wie in der Abbildung gezeigt, sorgt wasm-opt bei jedem dieser Benchmarks für eine signifikante Beschleunigung, durchschnittlich sind sie 1,9× schneller.
Zusammenfassend lässt sich sagen, dass wasm-opt von jeder Toolchain genutzt werden kann, die für WasmGC kompiliert, wodurch die Notwendigkeit entfällt, allgemeine Optimierungen in jeder Toolchain neu zu implementieren. Und während wir weiterhin Binaryens Optimierungen verbessern, profitieren alle Toolchains, die wasm-opt verwenden, davon, ebenso wie Verbesserungen von LLVM allen Sprachen zugutekommen, die mit LLVM zu WasmMVP kompilieren.
Optimierungen in der Toolchain sind nur ein Teil des Puzzles. Wie wir als nächstes sehen werden, sind auch Optimierungen in Wasm-VMs absolut entscheidend.
V8-Optimierungen
Wie bereits erwähnt, ist WasmGC besser optimierbar als WasmMVP, und nicht nur Toolchains können davon profitieren, sondern auch VMs. Und das erweist sich als wichtig, weil GC-Sprachen sich von Sprachen unterscheiden, die zu WasmMVP kompilieren. Betrachtet man beispielsweise das Inlining, eine der wichtigsten Optimierungen: Sprachen wie C, C++ und Rust führen das Inlining zur Kompilierzeit aus, während GC-Sprachen wie Java und Dart typischerweise in einer VM laufen, die zur Laufzeit inlined und optimiert. Dieses Leistungsmodell hat sowohl das Sprachdesign als auch die Art und Weise beeinflusst, wie Menschen Code in GC-Sprachen schreiben.
In einer Sprache wie Java beginnen beispielsweise alle Aufrufe als indirekt (eine Kindklasse kann eine Elternfunktion überschreiben, selbst wenn ein Kind mit einer Referenz des Elterntyps aufgerufen wird). Wir profitieren immer dann, wenn die Toolchain einen indirekten Aufruf in einen direkten umwandeln kann, aber in der Praxis haben Code-Muster in realen Java-Programmen oft Pfade, die tatsächlich viele indirekte Aufrufe enthalten, oder zumindest solche, die statisch nicht als direkt abgeleitet werden können. Um diese Fälle gut zu handhaben, haben wir spekulatives Inlining in V8 implementiert, das heißt, indirekte Aufrufe werden zur Laufzeit erfasst, und wenn wir sehen, dass eine Aufrufstelle ein ziemlich einfaches Verhalten aufweist (wenige Aufrufziele), dann inlinen wir an dieser Stelle mit geeigneten Schutzüberprüfungen, was der normalen Optimierung in Java näher kommt, als wenn wir solche Dinge vollständig der Toolchain überlassen würden.
Daten aus der Praxis bestätigen diesen Ansatz. Wir haben die Leistung der Google Sheets Calc Engine gemessen, die aus einem auf Java basierenden Code besteht, der zur Berechnung von Tabellenkalkulationsformeln verwendet wird und bislang mit J2CL zu JavaScript kompiliert wurde. Das V8-Team hat in Zusammenarbeit mit Sheets und J2CL diesen Code auf WasmGC portiert, sowohl aufgrund der zu erwartenden Leistungsvorteile für Sheets als auch um nützliches Feedback für den Spezifikationsprozess von WasmGC zu liefern. Die Leistungsmessungen dort zeigen, dass spekulatives Inlining die bedeutendste individuelle Optimierung ist, die wir für WasmGC in V8 implementiert haben, wie die folgende Grafik zeigt:

„Andere Optimierungen“ bezieht sich hier auf Optimierungen abgesehen vom spekulativen Inlining, die wir zwecks Messung deaktivieren konnten, dazu gehören: Ladungsbeseitigung, typbasierte Optimierungen, Zweigbeseitigung, Konstantenfaltung, Escape-Analyse und gemeinsame Teilausdrucksbeseitigung. „Ohne Optimierungen“ bedeutet, dass wir all diese sowie das spekulative Inlining ausgeschaltet haben (es gibt jedoch andere Optimierungen in V8, die wir nicht so leicht deaktivieren können; aus diesem Grund sind die hier vorgestellten Zahlen nur eine Annäherung). Die sehr große Verbesserung durch das spekulative Inlining – etwa eine 30%-ige Beschleunigung (!) – im Vergleich zu allen anderen Optimierungen zusammen zeigt, wie wichtig Inlining zumindest für kompilierte Java-Anwendungen ist.
Abgesehen vom spekulativen Inlining baut WasmGC auf der bestehenden Wasm-Unterstützung in V8 auf, was bedeutet, dass es von derselben Optimierer-Pipeline, Registerzuteilung, Tiering usw. profitiert. Zusätzlich können spezifische Aspekte von WasmGC von weiteren Optimierungen profitieren, wobei die offensichtlichste darin besteht, die neuen Instruktionen, die WasmGC bereitstellt, zu optimieren, wie zum Beispiel eine effiziente Implementation von Typumwandlungen. Ein weiterer wichtiger Beitrag unsererseits war die Nutzung der Typinformationen von WasmGC im Optimierer. Beispielsweise prüft ref.test, ob eine Referenz zur Laufzeit von einem bestimmten Typ ist, und nach einem erfolgreichen Test wissen wir, dass ref.cast, eine Umwandlung in denselben Typ, ebenfalls erfolgreich sein muss. Das hilft, Muster wie dieses in Java zu optimieren:
if (ref instanceof Type) {
foo((Type) ref); // Diese Abwärtsumwandlung kann eliminiert werden.
}
Diese Optimierungen sind besonders nützlich nach spekulativem Inlining, weil wir dann mehr Zusammenhänge sehen als die Toolchain beim Erstellen des Wasm.
Insgesamt gab es in WasmMVP eine ziemlich klare Trennung zwischen Toolchain- und VM-Optimierungen: Wir haben so viel wie möglich in der Toolchain gemacht und nur notwendige Optimierungen der VM überlassen, was sinnvoll war, da dies die VMs einfacher hielt. Mit WasmGC könnte sich dieses Gleichgewicht etwas verschieben, denn wie wir gesehen haben, besteht eine Notwendigkeit, mehr Optimierungen zur Laufzeit für GC-Sprachen vorzunehmen, und auch WasmGC selbst ist besser optimierbar, was eine größere Überschneidung zwischen Toolchain- und VM-Optimierungen ermöglicht. Es wird interessant sein zu sehen, wie sich das Ökosystem hier entwickelt.
Demo und Status
Sie können WasmGC ab heute verwenden! Nachdem WasmGC Phase 4 im W3C erreicht hat, ist es nun ein vollständiger und finalisierter Standard, und Chrome 119 wurde mit Unterstützung dafür veröffentlicht. Mit diesem Browser (oder jedem anderen Browser, der WasmGC unterstützt; beispielsweise wird erwartet, dass Firefox 120 noch in diesem Monat mit WasmGC-Unterstützung erscheint) können Sie diese Flutter-Demo ausführen, bei der Dart, kompiliert zu WasmGC, die Logik der Anwendung steuert, einschließlich ihrer Widgets, Layouts und Animationen.

Erste Schritte
Wenn Sie daran interessiert sind, WasmGC zu verwenden, könnten die folgenden Links hilfreich sein:
- Verschiedene Toolchains unterstützen heute WasmGC, darunter Dart, Java (J2Wasm), Kotlin, OCaml (wasm_of_ocaml) und Scheme (Hoot).
- Der Quellcode des kleinen Programms, dessen Ausgabe wir im Abschnitt „Entwicklertools“ gezeigt haben, ist ein Beispiel dafür, wie man ein „Hello World“-Programm in WasmGC manuell schreibt. (Insbesondere können Sie den
$Node-Typ sehen, der definiert und dann mitstruct.newerstellt wird.) - Das Binaryen-Wiki enthält Dokumentation darüber, wie Compiler WasmGC-Code erzeugen können, der gut optimiert werden kann. Die vorherigen Links zu den verschiedenen auf WasmGC zielenden Toolchains können ebenfalls lehrreich sein. Beispielsweise können Sie sich die Binaryen-Passes und -Flags ansehen, die von Java, Dart und Kotlin verwendet werden.
Zusammenfassung
WasmGC ist eine neue und vielversprechende Methode, um GC-Sprachen in WebAssembly zu implementieren. Traditionelle Portierungen, bei denen eine VM nach Wasm recompiliert wird, werden in einigen Fällen weiterhin sinnvoll sein. Wir hoffen jedoch, dass WasmGC-Portierungen aufgrund ihrer Vorteile eine beliebte Technik werden: WasmGC-Portierungen können kleiner sein als traditionelle Portierungen – sogar kleiner als WasmMVP-Programme, die in C, C++ oder Rust geschrieben wurden – und sie integrieren sich besser mit dem Web in Bezug auf Themen wie Zyklensammlung, Speicherauslastung, Entwickler-Tools und mehr. WasmGC ist außerdem eine besser optimierbare Repräsentation, die bedeutende Geschwindigkeitsvorteile sowie Möglichkeiten zur gemeinsamen Nutzung von Toolchain-Bemühungen zwischen Sprachen bietet.