WebAssembly에 쓰레기 수집형 프로그래밍 언어를 효율적으로 도입하는 새로운 방법
WebAssembly Garbage Collection (WasmGC)에 대한 최근의 글은 쓰레기 수집(GC) 제안이 GC 언어를 Wasm에서 더 잘 지원하도록 어떻게 목표를 설정하는지 고수준에서 설명하고 있습니다. GC 언어들의 인기를 고려할 때 이는 매우 중요합니다. 이번 글에서는 Java, Kotlin, Dart, Python, C# 같은 GC 언어를 Wasm으로 포팅하는 기술적 세부 사항에 대해 살펴볼 것입니다. 실제로 두 가지 주요 접근 방식이 있습니다:
- 기존의 “전통적인” 포팅 방식은 해당 언어의 기존 구현을 WasmMVP(WebAssembly 최소 실행 프로덕트, 2017년에 출시된)를 컴파일하는 방식입니다.
- WasmGC 포팅 방식은 언어를 최근의 GC 제안에 정의된 Wasm 자체의 GC 구조로 컴파일하는 방식입니다.
이 두 가지 접근 방식이 무엇인지, 특히 크기와 속도에 관한 기술적 트레이드오프를 설명하겠습니다. 그렇게 하면서 WasmGC가 몇 가지 주요 이점이 있다는 것을 알게 되겠지만, 툴체인 및 가상 머신(VMs) 모두에서 새로운 작업이 필요하다는 것도 확인할 수 있습니다. 이번 글의 후반부에서는 이러한 영역에서 V8 팀이 무슨 작업을 하고 있는지, 그리고 벤치마크 수치를 다룰 것입니다. Wasm, GC, 또는 둘 다에 관심이 있다면 흥미롭게 보시길 바랍니다. 끝부분에 있는 데모와 시작하기 링크도 확인하세요!
“전통적인” 포팅 방식
언어들은 보통 새로운 아키텍처로 어떻게 포팅될까요? Python이 ARM 아키텍처에서 실행되길 원하거나 Dart가 MIPS 아키텍처에서 실행되길 원하는 경우를 예로 들겠습니다. 일반적인 아이디어는 VM을 해당 아키텍처로 다시 컴파일하는 것입니다. 그 외에도, VM에 아키텍처별 코드가 있다면, 예를 들어 동적 번역(JIT) 또는 사전 번역(AOT) 같은 경우, 새로운 아키텍처를 위한 JIT/AOT 백엔드를 구현하는 방식이 있습니다. 이 접근 방식은 합리적으로 보이는데, 주 코드베이스의 주요 부분은 그냥 새로운 아키텍처로 각각 다시 컴파일할 수 있기 때문입니다:

이 그림에서, 파서, 라이브러리 지원, 쓰레기 수집기, 최적화 도구 등이 메인 런타임에서 모든 아키텍처 간에 공유됩니다. 새로운 아키텍처로 포팅하려면 비교적 적은 코드 양으로 새로운 백엔드만 필요합니다.
Wasm은 저수준 컴파일러 대상으로 설계되었으므로, 전통적인 포팅 방식이 사용될 수 있다는 것은 놀라운 일이 아닙니다. Wasm 시작부터 다양한 사례에서 잘 작동되었음을 알 수 있는데, Python을 위한 Pyodide와 C#을 위한 Blazor가 그러한 예입니다(Blazor는 AOT와 JIT 컴파일 방식을 모두 지원하므로 위 설명의 좋은 예입니다). 이러한 모든 사례에서, 언어의 런타임은 다른 Wasm으로 컴파일된 프로그램처럼 WasmMVP로 컴파일되며, 따라서 결과는 WasmMVP의 선형 메모리, 테이블, 함수 등을 사용하게 됩니다.
앞서 언급했듯이, 이것이 보통 언어들이 새로운 아키텍처로 포팅되는 방식이므로, 기존 언어 구현 및 최적화를 포함한 거의 모든 VM 코드를 재사용할 수 있다는 점에서 매우 합리적으로 보입니다. 하지만, 이 접근 방식에는 몇 가지 Wasm에 특화된 단점이 있으며, 그 지점에서 WasmGC가 도움이 됩니다.
WasmGC 포팅 방식
간단히 말하면, WebAssembly의 GC 제안(“WasmGC”)은 구조체 및 배열 타입을 정의하고, 이들의 인스턴스를 생성하고 필드를 읽고/쓰기하며, 타입 간 캐스팅 등을 수행할 수 있도록 합니다(자세한 내용은 제안 개요를 참조하십시오). 이러한 객체들은 Wasm VM의 자체 GC 구현에 의해 관리되며, 이는 전통적인 포팅 방식과의 주요 차이점입니다.
이렇게 생각해 볼 수 있습니다: 전통적인 포팅 방식이 언어를 아키텍처에 포팅하는 방식이라면, WasmGC 접근 방식은 언어를 VM에 포팅하는 방식과 매우 비슷합니다. 예를 들어, Java를 JavaScript로 포팅하려면, J2CL 같은 컴파일러를 사용하여 Java 객체를 JavaScript 객체로 표현할 수 있으며, 이러한 JavaScript 객체들은 다른 모든 객체들과 마찬가지로 JavaScript VM에 의해 관리됩니다. 언어를 기존 VM에 포팅하는 것은 매우 유용한 기술로, JavaScript, JVM, CLR로 컴파일되는 모든 언어들에서 알 수 있습니다.
이 아키텍처/VM 은유는 정확하지는 않지만, 특히 WasmGC가 앞서 언급한 VM들보다 더 저수준을 목표로 하기 때문입니다. 그럼에도 불구하고, WasmGC는 VM이 관리하는 구조체와 배열, 그리고 그들의 형태와 관계를 설명하는 타입 시스템을 정의합니다. WasmGC로 포팅하는 과정은 언어의 구성 요소를 이들 원시 요소로 나타내는 과정입니다. 전통적인 WasmMVP로의 포팅(모든 것을 선형 메모리의 비타입 바이트로 낮추는 방식)보다 확실히 더 고수준입니다. 따라서 WasmGC는 언어를 VM으로 포팅하는 방식과 매우 유사하며, 특히 타겟 VM과의 우수한 통합 및 그 VM의 최적화를 재사용하는 장점 등 이와 같은 포팅의 장점을 공유합니다.
두 가지 접근 방식 비교
이제 GC 언어의 두 가지 포팅 방식을 이해했으니, 이들이 어떻게 비교되는지 살펴보겠습니다.
메모리 관리 코드 포함하기
실제로, 많은 Wasm 코드는 이미 가비지 컬렉터를 포함한 VM 내부에서 실행됩니다. 이는 웹 상에서나 Node.js, workerd, Deno, Bun 같은 런타임에서도 마찬가지입니다. 이러한 경우에 GC 구현을 포함하면 Wasm 바이너리의 크기가 불필요하게 커질 수 있습니다. 사실, 이는 WasmMVP를 사용하는 GC 언어뿐만 아니라, C, C++, Rust 같은 선형 메모리를 사용하는 언어에서도 발생하는 문제입니다. 이러한 언어의 코드는 어떤 방식으로든 흥미로운 할당을 수행하기 때문에 선형 메모리를 관리하기 위해 malloc/free를 함께 번들로 포함하게 되며, 이는 몇몇 KB의 코드를 요구합니다. 예를 들어, dlmalloc은 6KB가 필요하며, 크기를 줄이는 대신 속도를 포기한 emmalloc 같은 malloc 도 1KB 이상을 차지합니다. 반면 WasmGC는 VM이 자동으로 메모리를 관리해 주므로 GC나 malloc/free 같은 메모리 관리 코드를 Wasm에 포함할 필요가 없습니다. 이전에 언급된 WasmGC에 대한 글에서는 fannkuch 벤치마크 크기를 측정했고, WasmGC가 C나 Rust보다 훨씬 작았습니다—2.3 KB vs 6.1-9.6 KB—바로 이 이유 때문입니다.
순환 수집
브라우저에서 Wasm은 종종 JavaScript(및 JavaScript를 통한 웹 API)와 상호작용합니다. 그러나 WasmMVP(및 참조 유형 제안에서도)에서는 Wasm과 JS 사이에서 양방향 링크를 설정하여 세부적인 순환을 수집할 수 있는 방법이 없습니다. JS 객체로의 링크는 Wasm 테이블에만 배치될 수 있으며, Wasm으로의 링크는 Wasm 인스턴스 전체를 단일 큰 객체로만 참조할 수 있습니다. 다음과 같이 말이죠:

이는 컴파일된 VM에 일부가 있고 JavaScript에 일부가 있는 객체들의 특정 순환을 효율적으로 수집하기에 충분하지 않습니다. 반면 WasmGC에서는 VM이 인식하는 Wasm 객체를 정의할 수 있으며, 따라서 Wasm에서 JavaScript로 다시 적절한 참조를 생성할 수 있습니다:

스택 상의 GC 참조
GC 언어는 호출 스코프의 로컬 변수에서의 참조, 즉 스택 상의 참조를 인식해야 합니다. 이러한 참조는 객체 생존을 유지시키는 유일한 요소일 수 있기 때문입니다. GC 언어를 전통적으로 포팅하면 Wasm의 샌드박싱으로 인해 프로그램이 자신의 스택을 검사할 수 없어 문제가 됩니다. 전통적인 포팅의 해결책으로는 그림자 스택 사용(자동 적용 가능)이나 JavaScript 이벤트 루프의 턴 간 중간처럼 스택에 아무것도 없을 때만 GC를 실행하는 방법이 있습니다. 전통적인 포팅을 돕는 미래의 추가 사항으로는 Wasm에서 스택 스캐닝 지원이 있을 수 있습니다. 현재로서는 WasmGC만이 오버헤드 없이 스택 참조를 처리할 수 있으며, 이는 Wasm VM이 GC를 담당하기 때문에 완전히 자동으로 이루어집니다.
GC 효율성
연관된 문제는 GC를 수행하는 효율성입니다. 두 가지 포팅 방식 모두 여기서 잠재적인 장점을 가지고 있습니다. 전통적인 포팅은 특정 언어에 최적화된 기존 VM의 최적화를 재활용할 수 있으며, 예를 들어 내부 포인터나 단명 객체를 중점적으로 최적화하는 것에 초점이 맞추어져 있을 수 있습니다. 반면, 웹에서 실행되는 WasmGC 포트는 JavaScript GC를 빠르게 만드는 데 사용된 모든 기법을 재활용할 수 있는 장점이 있습니다. 여기에는 세대별 GC, 증분 수집 등과 같은 기술이 포함됩니다. WasmGC는 또한 GC를 VM에게 맡기며, 이를 통해 효율적인 쓰기 장벽 등의 작업을 단순화할 수 있습니다.
또 다른 WasmGC의 장점은 GC가 메모리 압박을 감지하고 이에 따라 힙 크기와 수집 빈도를 조절할 수 있다는 점입니다. 이는 JavaScript VM이 이미 웹에서 수행하고 있는 작업과 유사합니다.
메모리 단편화
시간이 지남에 따라, 특히 장기 실행 프로그램에서 WasmMVP 선형 메모리의 malloc/free 작업은 단편화를 초래할 수 있습니다. 예를 들어, 총 2MB 메모리가 있고 그 중간에 몇 바이트만 차지하는 작은 할당이 있다고 상상해 보십시오. C, C++, Rust와 같은 언어에서는 실행 중에 임의의 할당을 이동하는 것이 불가능합니다. 따라서 그 할당의 왼쪽에 거의 1MB, 오른쪽에도 거의 1MB가 남아 있습니다. 하지만 이는 두 개의 별도 단편으로, 1.5MB를 할당하려 하면 실패하게 됩니다. 왜냐하면 전체 미할당 메모리의 총량은 충분하지만, 연속된 공간이 아니기 때문입니다:

이러한 단편화는 Wasm 모듈이 더 자주 메모리를 증가시키도록 강요하며, 이것은 추가 오버헤드를 발생시키고 메모리 부족 오류를 초래할 수 있습니다; 개선책이 설계 중이기는 하지만, 이는 어려운 문제입니다. 이러한 문제는 GC 언어의 전통적인 포팅을 포함하여 모든 WasmMVP 프로그램에서 발생합니다(여기서 GC 객체 자체는 이동 가능할 수 있지만 런타임의 일부는 그렇지 않다는 점에 유의하십시오). 반면, WasmGC는 메모리가 VM에 의해 완전히 관리되기 때문에 GC 힙을 압축하고 단편화를 방지하기 위해 이를 이동할 수 있어 이런 문제를 피합니다.
개발 도구 통합
WasmMVP로 전통적으로 포팅할 경우, 객체는 선형 메모리에 배치됩니다. 이는 개발 도구가 유용한 정보를 제공하기 어렵게 만듭니다. 왜냐하면 이 도구들은 고수준의 유형 정보를 보지 못하고 바이트만 보기 때문입니다. 이에 반해 WasmGC에서는 VM이 GC 객체를 관리하기 때문에 더 나은 통합이 가능합니다. 예를 들어, Chrome에서는 힙 프로파일러를 사용하여 WasmGC 프로그램의 메모리 사용량을 측정할 수 있습니다:
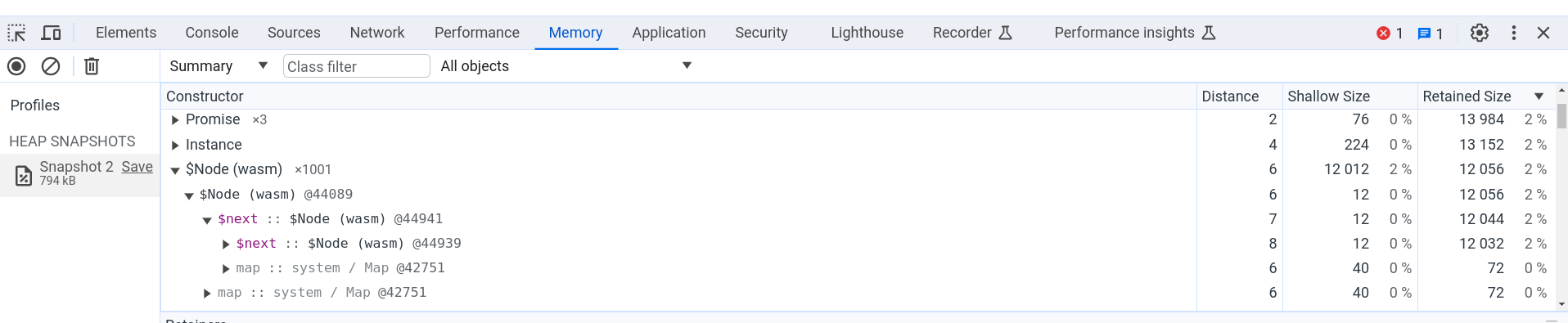
위 그림은 Chrome DevTools의 Memory 탭을 보여줍니다. 여기에서는 연결 리스트에 1,001개의 작은 객체를 생성한 WasmGC 코드를 실행한 페이지의 힙 스냅샷을 볼 수 있습니다. 객체 타입 $Node의 이름과 리스트에서 다음 객체를 참조하는 필드 $next를 확인할 수 있습니다. 힙 스냅샷 정보에는 객체 수, 얕은 크기, 유지되는 크기 등과 같은 모든 일반적인 정보가 포함되어 있어 WasmGC 객체가 실제로 사용하는 메모리의 양을 쉽게 확인할 수 있습니다. Chrome DevTools의 디버거와 같은 다른 기능도 WasmGC 객체에서 작동합니다.
언어 의미론
전통적인 포팅에서는 VM을 다시 컴파일할 때 해당 언어를 구현하는 친숙한 코드를 실행하므로 기대하는 정확한 언어를 얻을 수 있습니다. 이는 큰 장점입니다! 반면, WasmGC 포팅에서는 효율성을 위해 일부 의미론적 타협을 고려할 수 있습니다. 이는 WasmGC가 새로운 GC 타입—구조체와 배열—를 정의하고 이를 컴파일하기 때문입니다. 그 결과, C, C++, Rust 또는 유사한 언어로 작성된 기존 VM 코드를 단순히 그 형태로 컴파일할 수 없으며, 이는 선형 메모리에만 컴파일되기 때문입니다. 따라서 WasmGC는 기존 VM 코드베이스의 대다수를 처리할 수 없습니다. 대신, WasmGC 포팅에서는 언어의 구성을 WasmGC 원시 요소로 변환하는 새로운 코드를 작성하는 경우가 일반적입니다. 이러한 변환을 수행하는 방법에는 다양한 트레이드오프를 가진 여러 가지 방식이 있습니다.
타협이 필요한지 여부는 특정 언어의 구성을 WasmGC에서 구현할 수 있는 방식에 따라 다릅니다. 예를 들어, WasmGC 구조체 필드는 고정된 인덱스와 타입을 가지므로 필드를 더 동적으로 액세스하려는 언어는 문제를 겪을 수 있습니다; 이를 해결하기 위한 다양한 방법이 존재하며, 해당 솔루션 공간에서 일부 옵션은 더 간단하거나 빠를 수 있지만 언어의 원래 의미론을 완전히 지원하지는 않을 수 있습니다. (WasmGC는 또한 내부 포인터가 부족한 등 현재 다른 제한 사항도 가지고 있습니다. 시간이 지나면서 이러한 문제들이 개선될 것으로 예상됩니다.)
우리가 언급했듯이, WasmGC로 컴파일하는 것은 기존의 VM으로 컴파일하는 것과 비슷하며, 그러한 포팅에서 타당한 많은 절충 사례들이 있습니다. 예를 들어, dart2js(Dart를 자바스크립트로 컴파일한 것)의 숫자는 Dart VM에서와 다르게 동작합니다 그리고 IronPython(Python을 .NET으로 컴파일한 것)의 문자열은 C#의 문자열처럼 동작합니다. 그 결과, 모든 언어 프로그램이 이러한 포팅에서 실행되지 않을 수도 있지만, 이러한 선택에는 합리적인 이유가 있습니다: dart2js에서 숫자를 자바스크립트 숫자로 구현하면 VM들이 이를 최적화하기 쉬워지고, IronPython에서 .NET 문자열을 사용하면 다른 .NET 코드에 추가적인 비용 없이 문자열을 전달할 수 있습니다.
WasmGC 포팅에서 절충이 필요할 수는 있지만, WasmGC는 특히 자바스크립트에 비해 컴파일러 타겟으로서 몇 가지 장점을 가지고 있습니다. 예를 들어, dart2js는 방금 언급한 숫자 제한이 있지만, dart2wasm(Dart를 WasmGC로 컴파일한 것)은 특별한 절충 없이 정확하게 작동합니다 (Wasm이 Dart가 필요한 숫자 타입을 효율적으로 표현할 수 있기 때문입니다).
전통적인 포팅에서는 왜 이것이 문제가 되지 않을까요? 이는 단지 기존의 VM을 선형 메모리로 재컴파일하기 때문입니다. 여기서는 객체가 형식이 정해지지 않은 바이트로 저장되며, 이는 WasmGC보다 낮은 수준입니다. 형식이 정해지지 않은 바이트만 가지게 되면, 더 많은 저수준(및 잠재적으로 비안전한) 트릭을 수행할 수 있는 유연성을 가지게 됩니다. 기존의 VM을 재컴파일하면 해당 VM이 가지고 있는 모든 트릭을 활용할 수 있습니다.
툴체인 작업량
앞서 언급했듯이, WasmGC 포팅은 단순히 기존의 VM을 재컴파일할 수 없습니다. 특정 코드를 재사용할 수는 있을 것입니다(예: 파서 로직 및 AOT 최적화, 이들은 런타임에서 GC와 통합되지 않으므로). 하지만 일반적으로 WasmGC 포팅은 상당한 양의 새로운 코드를 필요로 합니다.
반면, WasmMVP로의 전통적인 포팅은 더 간단하고 빠를 수 있습니다: 예를 들어, Lua VM(C로 작성됨)을 Wasm으로 컴파일하는 데는 단 몇 분이면 됩니다. 하지만, Lua의 WasmGC 포팅은 더 많은 작업이 필요할 것입니다. Lua의 구조를 WasmGC 구조체와 배열로 낮추기 위한 코드를 작성해야 하며, WasmGC 타입 시스템의 특정한 제약 조건 내에서 이를 실제로 구현하는 방법을 결정해야 하기 때문입니다.
따라서 더 많은 툴체인 작업량은 WasmGC 포팅의 중요한 단점입니다. 그러나 이전에 언급한 모든 장점을 고려할 때, 우리는 WasmGC가 여전히 매우 매력적이라고 생각합니다! 이상적인 상황은 WasmGC 타입 시스템이 모든 언어를 효율적으로 지원할 수 있고, 모든 언어가 WasmGC 포팅을 구현하기 위해 작업하는 상황일 것입니다. 첫 번째 부분은 WasmGC 타입 시스템의 향후 추가에 의해 도울 수 있으며, 두 번째로는 툴체인 측면에서 가능한 한 작업을 공유함으로써 WasmGC 포팅에 관련된 작업을 줄일 수 있습니다. 운 좋게도 WasmGC는 툴체인 작업을 공유하는 것을 매우 실용적으로 만들어 준다는 것이 밝혀졌습니다. 이는 다음 섹션에서 살펴보겠습니다.
WasmGC 최적화
이미 언급했듯이, WasmGC 포팅은 적은 메모리 사용과 호스트 GC에서의 최적화를 재사용하는 등의 잠재적인 속도 장점을 가지고 있습니다. 이 섹션에서는 WasmMVP 대비 WasmGC의 다른 흥미로운 최적화 장점을 보여드리겠습니다. 이는 WasmGC 포팅이 설계되는 방식과 최종 결과의 속도에 큰 영향을 미칠 수 있습니다.
여기에서 주요 문제는 WasmGC가 WasmMVP보다 더 높은 수준이라는 것입니다. 이를 직관적으로 이해하려면, 전통적인 WasmMVP로의 포팅이 새로운 아키텍처로의 포팅과 같으며, WasmGC 포팅은 새로운 VM으로의 포팅과 같다는 점을 상기하십시오. 그리고 VM은 당연히 아키텍처에 대한 더 높은 수준의 추상화이며, 더 높은 수준의 표현은 종종 더 최적화 가능합니다. 이를 가상 코드로 명확히 볼 수 있습니다:
func foo() {
let x = allocate<T>(); // GC 객체를 할당.
x.val = 10; // 필드에 10 할당.
let y = allocate<T>(); // 다른 객체 할당.
y.val = x.val; // 이는 반드시 10이어야 함.
return y.val; // 이것도 10이어야 함.
}
주석이 나타내듯이, x.val은 10을 포함할 것이며, y.val도 마찬가지여서 최종 반환값도 10이 됩니다. 그런 다음 최적화는 할당을 삭제하여 이렇게 축소됩니다:
func foo() {
return 10;
}
좋습니다! 하지만 불행히도, 이는 WasmMVP에서는 불가능합니다. 왜냐하면 각 할당이 malloc 호출로 전환되는데, 이는 Wasm에서 부작용이 있는 선형 메모리에 복잡하고 방대한 함수입니다. 이러한 부작용 때문에 최적화는 두 번째 할당(y용)이 선형 메모리에 거주하는 x.val을 변경할 수 있다고 가정해야만 합니다. 메모리 관리는 복잡하며, 이를 Wasm 내에서 저수준으로 구현할 때 최적화 옵션이 제한됩니다.
반면, WasmGC에서는 더 높은 수준으로 작동합니다: 각 할당은 우리가 실제로 추론할 수 있는 VM 작업인 struct.new 명령을 실행하며, 최적화 도구는 참조를 추적하여 x.val이 값 10으로 정확히 한 번만 작성된다는 결론을 내릴 수 있습니다. 그 결과, 함수는 예상대로 간단한 10 반환으로 최적화될 수 있습니다!
할당 외에도, WasmGC는 명시적 함수 포인터 (ref.func)와 이를 사용한 호출(call_ref), 구조체 및 배열 필드의 타입(형식이 없는 선형 메모리와 달리) 등을 추가합니다. 그 결과, WasmGC는 WasmMVP보다 더 높은 수준의 중간 표현(IR)이며, 훨씬 더 최적화 가능합니다.
WasmMVP가 최적화에 제한이 있다면, 왜 그것이 그렇게 빠를까요? 결국 Wasm은 네이티브 속도에 거의 가까운 속도로 실행될 수 있습니다. 그 이유는 WasmMVP가 일반적으로 LLVM과 같은 강력한 최적화 컴파일러의 출력물이기 때문입니다. WasmGC 및 WasmMVP와 달리 LLVM IR은 할당 등을 위한 특별한 표현 방식을 가지고 있어, 우리가 논의한 것들을 LLVM이 최적화할 수 있습니다. WasmMVP의 설계는 대부분의 최적화가 Wasm 이전에 툴체인 수준에서 이루어지고, Wasm VM은 최적화의 '마지막 단계'(예: 레지스터 할당)를 수행한다는 점에 있습니다.
WasmGC가 WasmMVP와 유사한 툴체인 모델을 채택하고 특히 LLVM을 사용할 수 있을까요? 불행히도, 그렇지 않습니다. LLVM이 WasmGC를 지원하지 않기 때문입니다(어느 정도의 지원이 시도된 바 있습니다, 하지만 완전한 지원이 실제로 가능할지조차 알기 어렵습니다). 또한, 많은 GC 언어는 LLVM을 사용하지 않습니다–그 영역에는 다양한 컴파일러 툴체인이 존재합니다. 그래서 WasmGC에는 다른 접근 방식이 필요합니다.
다행히도, 앞서 언급했듯이 WasmGC는 매우 최적화 가능하며, 이는 새로운 옵션의 가능성을 열어줍니다. 이는 다음과 같은 관점으로 볼 수 있습니다:

WasmMVP와 WasmGC 워크플로우는 왼쪽의 동일한 두 개의 박스로 시작합니다: 소스 코드는 해당 언어가 자신에 대해 가장 잘 알고 있는 방식으로 처리되고 최적화됩니다. 그 다음에 차이가 나타나는데, WasmMVP의 경우 일반적인 최적화를 먼저 수행한 후 Wasm으로 낮춰야 하지만, WasmGC는 Wasm으로 먼저 낮춘 다음 이후에 최적화할 수 있는 옵션이 있습니다. 이는 변환 후 최적화가 주는 큰 이점 때문입니다: 그때는 모든 WasmGC로 컴파일되는 언어들 간 일반적인 최적화를 위한 툴체인 코드를 공유할 수 있습니다. 다음 그림은 그것이 어떻게 보이는지 보여줍니다:
로 전달됩니다.")
WasmGC로 컴파일한 후에 일반 최적화를 수행할 수 있기에 Wasm-to-Wasm 최적화기는 모든 WasmGC 컴파일러 툴체인에 도움을 줄 수 있습니다. 이러한 이유로 V8 팀은 모든 툴체인이 wasm-opt 커맨드라인 도구로 사용할 수 있는 Binaryen에 WasmGC에 대한 투자를 했습니다. 다음 하위 섹션에서 그것에 대해 중점적으로 살펴보겠습니다.
툴체인 최적화
Binaryen, 웹어셈블리 툴체인 최적화 프로젝트는 이미 WasmMVP 콘텐츠(예: 인라이닝, 상수 전파, 데드 코드 제거 등)에 대해 다양한 최적화를 보유하고 있었으며, 이러한 작업들 대부분은 WasmGC에도 적용됩니다. 하지만 앞서 언급했듯이, WasmGC는 WasmMVP보다 훨씬 더 많은 최적화를 가능하게 하며, 이에 따라 많은 새로운 최적화를 작성했습니다:
- Escape 분석을 통해 힙 할당을 로컬로 이동.
- 디버추얼라이제이션을 통해 간접 호출을 직접 호출로 변환(그 후 잠재적으로 인라인 가능).
- 더 강력한 전역 데드 코드 제거.
- 전체 프로그램 타입 인식 컨텐츠 흐름 분석 (GUFA).
- 캐스트 최적화(예: 중복 캐스트 제거 및 이를 더 초기 위치로 이동).
- 타입 가지치기.
- 타입 병합.
- 타입 세분화(예: 로컬, 전역, 필드 및 서명).
위는 우리가 수행한 작업들 중 일부를 간단히 나열한 것입니다. Binaryen의 새로운 GC 최적화와 이를 사용하는 방법에 대한 자세한 내용은 Binaryen 문서를 참조하십시오.
Binaryen에서 이러한 모든 최적화의 효과를 측정하기 위해, Java를 WasmGC로 컴파일하는 J2Wasm 컴파일러의 결과물에서 wasm-opt를 실행한 경우와 실행하지 않은 경우의 Java 성능을 살펴보겠습니다:

여기서 "wasm-opt 없음"은 Binaryen의 최적화를 실행하지는 않지만, 여전히 VM 및 J2Wasm 컴파일러에서의 최적화는 실행하는 경우를 의미합니다. 도표에 나타난 것처럼, 각 벤치마크에서 wasm-opt는 상당한 속도 향상을 제공하며, 평균적으로 1.9배 더 빠릅니다.
요약하자면, wasm-opt는 WasmGC로 컴파일하는 모든 툴체인에서 사용될 수 있으며 각 툴체인에 일반적인 최적화를 재구현할 필요가 없습니다. 그리고 Binaryen의 최적화를 지속적으로 개선하면 wasm-opt를 사용하는 모든 툴체인에 이점이 제공되며, 마치 LLVM의 개선이 LLVM을 사용하여 WasmMVP로 컴파일하는 모든 언어에 도움을 주는 것과 같습니다.
툴체인 최적화는 전체 그림의 한 부분일 뿐입니다. 다음에서 보게 될 것처럼, Wasm VM에서의 최적화도 절대적으로 중요합니다.
V8 최적화
앞서 언급했듯이, WasmGC는 WasmMVP보다 더 최적화될 수 있으며, 이를 통해 툴체인만이 아니라 VM도 혜택을 받을 수 있습니다. 이는 중요한데 GC 언어는 WasmMVP로 컴파일되는 언어와 다르기 때문입니다. 예를 들어 중요한 최적화 중 하나인 인라인화를 살펴봅시다: C, C++, Rust와 같은 언어는 컴파일 시 인라인화되지만, Java와 Dart 같은 GC 언어는 일반적으로 런타임에서 인라인화와 최적화를 수행하는 VM에서 실행됩니다. 이러한 성능 모델은 언어 설계와 사람들이 GC 언어에서 코드를 작성하는 방식 모두에 영향을 미쳤습니다.
예를 들어 Java와 같은 언어에서는 모든 호출이 간접 호출로 시작됩니다 (자식 클래스가 부모 함수 호출을 재정의할 수 있음). 툴체인이 간접 호출을 직접 호출로 전환할 때 이점이 있습니다. 그러나 실제 Java 프로그램에서는 코드 패턴이 많거나 적어도 직접 호출로 정적으로 유추할 수 없는 경로가 많은 경우가 있습니다. 이러한 경우를 잘 처리하기 위해 V8에서는 추측 인라인화를 구현했습니다. 즉, 런타임에서 발생하는 간접 호출을 기록하고 호출 지점의 동작이 비교적 간단한 경우 (소수의 호출 대상), 적합한 가드 체크와 함께 거기서 인라인화합니다. 이는 모든 것을 툴체인에 맡기는 것보다는 Java가 일반적으로 최적화되는 방식에 더 가깝습니다.
실제 데이터는 이러한 접근 방식을 검증합니다. Google Sheets Calc Engine에서 성능을 측정했는데, 이는 스프레드시트 수식을 계산하는 데 사용되는 Java 코드베이스로 이제까지는 J2CL을 사용하여 JavaScript로 컴파일되었습니다. V8 팀은 Sheets 및 J2CL과 협력하여 해당 코드를 WasmGC로 포팅하여 Sheets에 기대되는 성능 혜택을 제공하고, WasmGC 스펙 프로세스에 유용한 실제 피드백을 제공하고자 했습니다. 성능을 살펴본 결과, 추측 인라인화는 V8에서 WasmGC를 위해 구현된 가장 중요한 개별 최적화로 나타났으며, 아래 차트에서 보여줍니다:

“기타 최적화”는 추측 인라인화를 제외한 다른 최적화로, 측정 목적으로 비활성화할 수 있는 최적화를 포함합니다: 로드 제거, 타입 기반 최적화, 분기 제거, 상수 폴딩, 탈출 분석, 공통 부분 표현 제거. “최적화 없음”은 이러한 최적화뿐만 아니라 추측 인라인화도 모두 비활성화된 상태를 의미합니다 (V8에는 비활성화할 수 없는 다른 최적화도 존재하므로 여기 표시된 숫자는 대략적인 값일 뿐입니다). 약 30% 속도 향상(!)이라는 매우 큰 개선이 모든 기타 최적화와 비교하여 추측 인라인화 덕분에 이루어진 것을 보여줍니다.
추측 인라인화 외에도, WasmGC는 V8의 기존 Wasm 지원을 기반으로 구축되어 동일한 최적화 파이프라인, 레지스터 할당, 티어링 등에서 이점을 제공합니다. 그 외에도, WasmGC의 특정 측면은 추가적인 최적화에서 이점을 얻을 수 있으며, 가장 명백한 것은 WasmGC가 제공하는 새로운 명령어들을 최적화하는 것입니다. 예를 들어 타입 캐스트의 효율적인 구현을 가지는 것입니다. 또 다른 중요한 작업은 최적화기에서 WasmGC의 타입 정보를 사용하는 것입니다. 예를 들어 ref.test는 런타임에 참조가 특정 타입인지 확인하고, 해당 확인이 성공하면 ref.cast, 동일한 타입으로의 캐스트도 성공해야 합니다. 이는 다음 Java 패턴과 같은 것을 최적화하는 데 도움이 됩니다:
if (ref instanceof Type) {
foo((Type) ref); // 이 다운캐스트는 제거될 수 있습니다.
}
이러한 최적화는 추측 인라인화 이후에 특히 유용합니다. 그 경우 툴체인이 Wasm을 생성할 때 보았던 것보다 더 많은 정보를 볼 수 있습니다.
전체적으로 WasmMVP에서는 툴체인과 VM 최적화가 비교적 명확하게 분리되어 있었습니다: 툴체인에서 가능한 한 많이 수행하고 VM에는 필요한 최적화만 남기는 방식으로 VM을 단순하게 유지할 수 있었습니다. WasmGC에서는 이 균형이 약간 바뀔 수 있습니다. 왜냐하면 GC 언어에서는 런타임에서 더 많은 최적화를 수행할 필요가 있으며, WasmGC 자체도 더 최적화 가능하므로 툴체인과 VM 최적화 간에 더 많은 중첩이 가능해지기 때문입니다. 생태계가 이 분야에서 어떻게 발전할지는 흥미로운 관찰이 될 것입니다.
데모 및 상태
오늘부터 WasmGC를 사용할 수 있습니다! W3C에서 단계 4에 도달한 후, WasmGC는 이제 완전히 표준으로 확정되었으며 Chrome 119가 이를 지원하며 출시되었습니다. 해당 브라우저(또는 WasmGC를 지원하는 다른 브라우저. 예를 들어, Firefox 120은 이번 달 말에 WasmGC 지원과 함께 출시될 예정입니다)를 사용하면, Dart가 WasmGC로 컴파일되어 위젯, 레이아웃 및 애니메이션을 포함한 애플리케이션 로직을 구동하는 Flutter 데모를 실행할 수 있습니다.

시작하기
WasmGC를 사용하는 데 관심이 있다면, 아래 링크가 유용할 수 있습니다:
- Dart, Java (J2Wasm), Kotlin, OCaml (wasm_of_ocaml), Scheme (Hoot)를 포함한 다양한 툴체인들이 이미 WasmGC를 지원합니다.
- 개발 도구 섹션에서 보여준 출력 결과를 생성한 작은 프로그램의 소스 코드는 손으로 작성한 “hello world” WasmGC 프로그램의 예입니다. (특히
$Node타입이 정의되고struct.new를 사용하여 생성되는 것을 확인할 수 있습니다.) - Binaryen 위키에는 컴파일러가 최적화가 잘 되는 WasmGC 코드를 생성하는 방법에 대한 문서가 있습니다. 앞서 언급한 다양한 WasmGC 대상 툴체인 링크는 학습에 유용할 수 있으며, 예를 들어 Java, Dart, Kotlin에서 사용하는 Binaryen 패스 및 플래그를 확인할 수 있습니다.
요약
WasmGC는 WebAssembly에서 GC 언어를 구현하기 위한 새로운 유망한 방법입니다. VM이 Wasm으로 다시 컴파일되는 전통적인 방식이 여전히 일부 경우에 가장 적합할 수 있지만, WasmGC가 제공하는 이점 덕분에 WasmGC 포팅이 널리 사용되는 기술이 되기를 희망합니다: WasmGC 포팅은 전통적인 포팅보다 더 작을 수 있으며—C, C++, Rust로 작성된 WasmMVP 프로그램보다도 더 작을 수 있으며—순환 수집, 메모리 사용, 개발자 도구 등과 같은 웹 통합 문제에서 더 나은 통합을 제공합니다. 또한 WasmGC는 더 최적화 가능한 표현 방식으로, 상당한 속도 향상을 제공하며 언어 간에 더 많은 툴체인 작업을 공유할 기회를 제공합니다.