Schnelles `for`-`in` in V8
for-in ist ein weit verbreitetes Sprachmerkmal, das in vielen Frameworks vorkommt. Trotz seiner Allgegenwärtigkeit ist es aus Implementierungsperspektive eines der obskureren Sprachkonstrukte. V8 hat große Anstrengungen unternommen, um dieses Merkmal so schnell wie möglich zu machen. Im Laufe des letzten Jahres wurde for-in vollständig spec-konform und je nach Kontext bis zu 3-mal schneller.
Viele beliebte Websites verlassen sich stark auf for-in und profitieren von dessen Optimierung. Zum Beispiel verbrauchte Facebook Anfang 2016 etwa 7 % seiner gesamten JavaScript-Zeit während des Startvorgangs in der Implementierung von for-in selbst. Auf Wikipedia war diese Zahl sogar noch höher und lag bei etwa 8 %. Durch die Verbesserung der Leistung in bestimmten langsamen Fällen verbesserte Chrome 51 die Leistung dieser beiden Websites erheblich:


Wikipedia und Facebook verbesserten ihre Gesamtskriptzeit um 4 % aufgrund verschiedener for-in-Verbesserungen. Beachten Sie, dass während desselben Zeitraums der Rest von V8 ebenfalls schneller wurde, was insgesamt eine Skriptverbesserung von mehr als 4 % ergab.
Im Rest dieses Blogbeitrags erklären wir, wie wir es geschafft haben, dieses Kernsprachenmerkmal zu beschleunigen und gleichzeitig einen langjährigen Spezifikationsverstoß zu beheben.
Die Spezifikation
TL;DR; Die Iterationssemantik von for-in sind aus Leistungsgründen unscharf.
Wenn wir uns den Spezifikationstext von for-in ansehen, ist er auf unerwartet unscharfe Weise geschrieben, was bei verschiedenen Implementierungen beobachtbar ist. Schauen wir uns ein Beispiel an, wenn wir über ein Proxy-Objekt mit den richtigen Traps iterieren.
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
In V8/Chrome 56 erhalten Sie folgende Ausgabe:
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
Im Gegensatz dazu erhalten Sie eine andere Reihenfolge der Anweisungen für dasselbe Snippet in Firefox 51:
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
Beide Browser respektieren die Spezifikation, aber einmal erzwingt die Spezifikation keine explizite Reihenfolge von Anweisungen. Um diese Schlupflöcher richtig zu verstehen, werfen wir einen Blick auf den Spezifikationstext:
EnumerateObjectProperties ( O ) Wenn die abstrakte Operation EnumerateObjectProperties mit Argument O aufgerufen wird, werden folgende Schritte durchgeführt:
- Behauptung: Type(O) ist Object.
- Geben Sie ein Iterator-Objekt (25.1.1.2) zurück, dessen next-Methode über alle String-Werte-Schlüssel von aufzählbaren Eigenschaften von O iteriert. Das Iterator-Objekt ist niemals direkt für ECMAScript-Code zugänglich. Die Mechanik und Reihenfolge der Enumerierung der Eigenschaften ist nicht spezifiziert, muss aber den unten angegebenen Regeln entsprechen.
Normalerweise sind Spezifikationsanweisungen präzise darüber, welche genauen Schritte erforderlich sind. Aber in diesem Fall beziehen sich die Anweisungen auf eine einfache Liste von Prosa, und sogar die Reihenfolge der Ausführung bleibt den Implementierern überlassen. Typischerweise liegt der Grund dafür darin, dass solche Teile der Spezifikation nachträglich geschrieben wurden, als JavaScript-Engines bereits unterschiedliche Implementierungen hatten. Die Spezifikation versucht, die losen Enden zu verknüpfen, indem sie die folgenden Anweisungen bereitstellt:
- Die throw- und return-Methoden des Iterators sind null und werden niemals aufgerufen.
- Die next-Methode des Iterators verarbeitet Objekteigenschaften, um zu bestimmen, ob der Eigenschaftsschlüssel als Iterator-Wert zurückgegeben werden soll.
- Zurückgegebene Eigenschaftsschlüssel schließen Schlüssel, die Symbole sind, nicht ein.
- Eigenschaften des Zielobjekts können während der Enumerierung gelöscht werden.
- Eine Eigenschaft, die vor ihrer Verarbeitung durch die next-Methode des Iterators gelöscht wird, wird ignoriert. Wenn dem Zielobjekt während der Enumerierung neue Eigenschaften hinzugefügt werden, ist nicht garantiert, dass die neu hinzugefügten Eigenschaften in der aktiven Enumerierung verarbeitet werden.
- Ein Methodenname wird von der next-Methode des Iterators in einer Enumeration höchstens einmal zurückgegeben.
- Die Enumeration der Eigenschaften des Zielobjekts schließt die Enumeration von Eigenschaften seines Prototyps ein und den Prototyp des Prototyps und so weiter, rekursiv; aber eine Eigenschaft eines Prototyps wird nicht verarbeitet, wenn sie denselben Namen wie eine Eigenschaft hat, die bereits von der next-Methode des Iterators verarbeitet wurde.
- Die Werte der
[[Enumerable]]-Attribute werden nicht berücksichtigt, wenn festgestellt wird, ob eine Eigenschaft eines Prototyp-Objekts bereits verarbeitet wurde. - Die enumerierbaren Eigenschaftsnamen von Prototyp-Objekten müssen durch Aufruf von EnumerateObjectProperties und Übergabe des Prototyp-Objekts als Argument erhalten werden.
- EnumerateObjectProperties muss die eigenen Eigenschaftsschlüssel des Zielobjekts durch Aufruf seiner internen Methode
[[OwnPropertyKeys]]abrufen.
Diese Schritte erscheinen mühsam, allerdings enthält die Spezifikation auch eine Beispielimplementierung, die explizit und deutlich lesbarer ist:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
Nun, da Sie so weit gekommen sind, haben Sie möglicherweise bemerkt, dass V8 in dem vorherigen Beispiel die Beispielimplementierung der Spezifikation nicht genau befolgt. Zum Beispiel arbeitet der Generator für for-in incrementell, während V8 alle Schlüssel im Voraus sammelt – vor allem aus Leistungsgründen. Das ist vollkommen in Ordnung, und tatsächlich sagt der Spezifikationstext ausdrücklich aus, dass die Reihenfolge der Operationen A - J nicht definiert ist. Dennoch, wie Sie später in diesem Beitrag feststellen werden, gab es bis 2016 einige Sonderfälle, in denen V8 die Spezifikation nicht vollständig respektierte.
Der Enum-Cache
Die Beispielimplementierung des for-in Generators folgt einem inkrementellen Muster zum Sammeln und Ausgeben von Schlüsseln. In V8 werden die Eigenschaftsschlüssel in einem ersten Schritt gesammelt und erst dann in der Iterationsphase verwendet. Für V8 macht dies einige Dinge einfacher. Um zu verstehen, warum, müssen wir uns das Objektmodell ansehen.
Ein einfaches Objekt wie {a:'value a', b:'value b', c:'value c'} kann in V8 verschiedene interne Darstellungen haben, wie wir in einem detaillierten Folgebeitrag über Eigenschaften zeigen werden. Dies bedeutet, dass je nachdem, welchen Typ von Eigenschaften wir haben – In-Object, Fast oder Slow – die tatsächlichen Eigenschaftsnamen an verschiedenen Orten gespeichert sind. Dies macht das Sammeln von enumerierbaren Schlüsseln zu einer durchaus komplexen Aufgabe.
V8 verfolgt die Struktur des Objekts mithilfe einer versteckten Klasse oder sogenannter Map. Objekte mit derselben Map haben dieselbe Struktur. Zusätzlich hat jede Map eine gemeinsame Datenstruktur, das Descriptor-Array, welches Details über jede Eigenschaft enthält, wie etwa wo die Eigenschaften am Objekt gespeichert sind, der Eigenschaftsname und Details wie Enumerierbarkeit.
Nehmen wir für einen Moment an, unser JavaScript-Objekt hat seine endgültige Form erreicht und es werden keine weiteren Eigenschaften hinzugefügt oder entfernt. In diesem Fall könnten wir das Descriptor-Array als Quelle für die Schlüssel verwenden. Dies funktioniert, wenn es nur enumerierbare Eigenschaften gibt. Um den Aufwand zu vermeiden, nicht-enumerierbare Eigenschaften jedes Mal herauszufiltern, verwendet V8 einen separaten EnumCache, der über das Descriptor-Array der Map zugänglich ist.

Da V8 davon ausgeht, dass sich langsame Wörterbuchobjekte häufig ändern (d.h. durch Hinzufügen und Entfernen von Eigenschaften), gibt es für langsame Objekte mit Wörterbucheigenschaften kein Descriptor-Array. Daher bietet V8 keinen EnumCache für langsame Eigenschaften. Ähnliche Annahmen gelten für indizierte Eigenschaften, und deshalb sind sie ebenfalls vom EnumCache ausgeschlossen.
Lassen Sie uns die wichtigen Fakten zusammenfassen:
- Maps werden verwendet, um die Objektform zu verfolgen.
- Descriptor-Arrays speichern Informationen über Eigenschaften (Name, Konfigurierbarkeit, Sichtbarkeit).
- Descriptor-Arrays können zwischen Maps geteilt werden.
- Jedes Descriptor-Array kann einen EnumCache haben, der nur die enumerierbaren benannten Schlüssel, nicht die indizierten Eigenschaftsnamen, auflistet.
Die Mechanik des for-in
Nun wissen Sie teilweise, wie Maps funktionieren und wie der EnumCache mit dem Descriptor-Array zusammenhängt. V8 führt JavaScript durch Ignition, einen Bytecode-Interpreter, und TurboFan, den optimierenden Compiler aus, die beide for-in auf ähnliche Weise behandeln. Der Einfachheit halber verwenden wir einen pseudo-C++-Stil, um zu erklären, wie for-in intern implementiert wird:
// For-In Vorbereitung:
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// For-In Körper:
for (size_t i = 0; i < keys->length(); i++) {
// For-In Nächste:
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
For-in kann in drei Hauptschritte unterteilt werden:
- Vorbereiten der Schlüssel zur Iteration,
- Abrufen des nächsten Schlüssels,
- Auswerten des
for-inKörpers.
Der "Prepäre"-Schritt ist der komplexeste von diesen drei und hier kommt der EnumCache ins Spiel. Im obigen Beispiel können Sie sehen, dass V8 den EnumCache direkt verwendet, wenn er existiert und wenn es keine Elemente (ganzzahlige indizierte Eigenschaften) auf dem Objekt (und seinem Prototyp) gibt. Für den Fall, dass es indizierte Eigenschaftsnamen gibt, springt V8 zu einer in C++ implementierten Laufzeitfunktion, die diese an den bestehenden EnumCache anhängt, wie im folgenden Beispiel veranschaulicht:
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// Abrufen der aufzählbaren Eigenschaftsschlüssel aus einem möglicherweise geteilten EnumCache
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements)
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// Einfügung der Eigenschaftsschlüssel am Ende.
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
Falls kein bestehender EnumCache gefunden wurde, springen wir erneut zu C++ und folgen den anfänglich präsentierten Spezifikationsschritten:
FixedArray* JSObject::GetEnumKeys() {
// Abruf der Enum-Schlüssel des Empfängers.
FixedArray* keys = this->GetOwnEnumKeys();
// Durchlaufen der Prototypenkette.
for (JSObject* object : GetPrototypeIterator()) {
// Anhängen nicht-doppelter Schlüssel zur Liste.
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
Diese vereinfachte C++-Kodierung entspricht der Implementierung in V8 bis Anfang 2016, als wir begannen, die Methode UnionOfKeys näher zu betrachten. Wenn Sie genau hinsehen, werden Sie bemerken, dass wir einen naiven Algorithmus verwendet haben, um Duplikate aus der Liste auszuschließen, was bei vielen Schlüsseln in der Prototypkette zu schlechten Leistungen führen kann. So entschieden wir uns, in dem folgenden Abschnitt Optimierungen zu verfolgen.
Probleme mit for-in
Wie wir bereits im vorherigen Abschnitt angedeutet haben, weist die Methode UnionOfKeys eine schlechte Worst-Case-Leistung auf. Sie basierte auf der gültigen Annahme, dass die meisten Objekte schnelle Eigenschaften besitzen und daher von einem EnumCache profitieren. Die zweite Annahme ist, dass es nur wenige aufzählbare Eigenschaften in der Prototypkette gibt, was die Zeit zur Erkennung von Duplikaten begrenzt. Falls das Objekt jedoch langsame Dictionary-Eigenschaften und viele Schlüssel in der Prototypkette hat, wird UnionOfKeys zu einem Engpass, da wir jedes Mal, wenn wir in for-in eintreten, die aufzählbaren Eigenschaftsnamen sammeln müssen.
Neben Leistungsproblemen gab es ein weiteres Problem mit dem bestehenden Algorithmus, da er nicht konform zur Spezifikation war. Viele Jahre lang hatte V8 das folgende Beispiel falsch verstanden:
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
Ausgabe:
a
b
Vielleicht kontraintuitiv sollte dies nur a und nicht a und b ausgeben. Wenn Sie sich an den Spezifikationstext am Anfang dieses Beitrags erinnern, implizieren die Schritte G und J, dass nicht-auflistungspflichtige Eigenschaften des Empfängers die Eigenschaften in der Prototypkette überschreiben.
Um die Dinge noch komplizierter zu machen, führte ES6 das proxy-Objekt ein. Dies durchbrach viele Annahmen des V8-Codes. Um for-in auf eine spezifikationskonforme Weise zu implementieren, müssen wir die folgenden 5 von insgesamt 13 verschiedenen Proxy-Fallen auslösen.
| Interne Methode | Handler-Methode |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
Dies erforderte eine doppelte Version des ursprünglichen GetEnumKeys-Codes, der versuchte, der Beispielsimplementierung der Spezifikation genauer zu folgen. ES6-Proxies und das Fehlen der Behandlung von überschattenden Eigenschaften waren die Hauptmotivation für uns, Anfang 2016 die Art und Weise zu überarbeiten, wie wir alle Schlüssel für for-in extrahieren.
Der KeyAccumulator
Wir haben eine separate Hilfsklasse, den KeyAccumulator, eingeführt, die sich mit den Komplexitäten des Sammelns der Schlüssel für for-in befasst. Mit dem Wachstum der ES6-Spezifikation erforderten neue Funktionen wie Object.keys oder Reflect.ownKeys ihre eigene leicht modifizierte Version des Sammelns von Schlüsseln. Durch eine einzige konfigurierbare Stelle konnten wir die Leistung von for-in verbessern und duplizierten Code vermeiden.
Der KeyAccumulator besteht aus einem schnellen Teil, der nur eine begrenzte Anzahl von Aktionen unterstützt, diese aber sehr effizient abschließen kann. Der langsame Akkumulator unterstützt alle komplexen Fälle, wie ES6-Proxies.

Um überschattende Eigenschaften ordnungsgemäß herauszufiltern, müssen wir eine separate Liste nicht enumerierbarer Eigenschaften führen, die wir bisher gesehen haben. Aus Leistungsgründen tun wir dies erst, nachdem wir herausfinden, dass es enumerierbare Eigenschaften in der Prototypenkette eines Objekts gibt.
Leistungsverbesserungen
Mit dem KeyAccumulator wurden einige weitere Muster optimierbar. Das erste war, die geschachtelte Schleife der ursprünglichen Methode UnionOfKeys zu vermeiden, die langsame Sonderfälle verursachte. In einem zweiten Schritt führten wir detailliertere Vorprüfungen durch, um vorhandene EnumCaches zu nutzen und unnötige Kopiervorgänge zu vermeiden.
Um zu veranschaulichen, dass die spezifikationskonforme Implementierung schneller ist, werfen wir einen Blick auf die folgenden vier verschiedenen Objekte:
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
- Das Objekt
fastPropertieshat standardmäßige schnelle Eigenschaften. - Das Objekt
fastPropertiesWithPrototypehat zusätzliche nicht enumerierbare Eigenschaften in der Prototypenkette, indem esObject.prototypeverwendet. - Das Objekt
slowPropertieshat langsame Wörterbuch-Eigenschaften. - Das Objekt
elementshat nur indizierte Eigenschaften.
Der folgende Graph vergleicht die ursprüngliche Leistung einer for-in-Schleife, die eine Million Mal in einer engen Schleife ausgeführt wird, ohne Unterstützung unseres optimierenden Compilers.
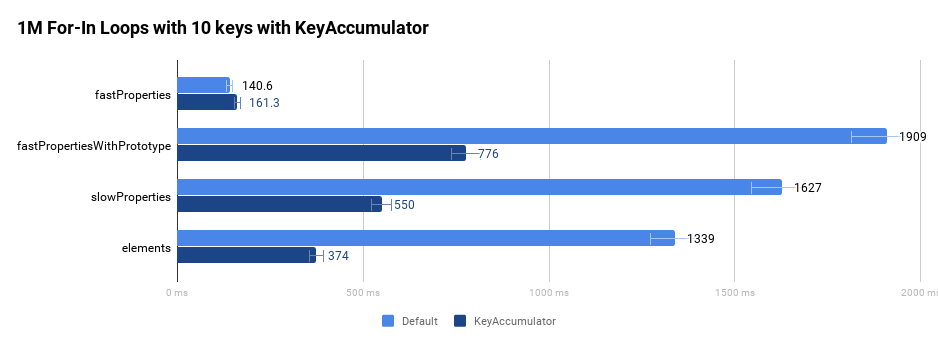
Wie in der Einführung beschrieben, wurden diese Verbesserungen insbesondere auf Wikipedia und Facebook sehr sichtbar.
Neben den anfänglichen Verbesserungen, die in Chrome 51 verfügbar sind, ergab eine zweite Leistungsoptimierung eine weitere signifikante Verbesserung. Der folgende Graph zeigt unsere Tracking-Daten der gesamten Zeit, die während des Starts auf einer Facebook-Seite für Skripting verwendet wurde. Die ausgewählte Spanne um die V8-Revision 37937 entspricht einer zusätzlichen Leistungsverbesserung von 4 %!

Um die Bedeutung der Verbesserung von for-in zu unterstreichen, können wir uns auf die Daten eines Tools stützen, das wir 2016 erstellt haben und das es uns ermöglicht, V8-Messungen über eine Reihe von Websites zu extrahieren. Die folgende Tabelle zeigt die relative Zeit, die in V8-C++-Einstiegspunkten (Laufzeitfunktionen und Built-ins) für Chrome 49 auf einer Reihe von etwa 25 repräsentativen realen Websites verbracht wurde.
| Position | Name | Gesamtzeit |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |