Ein Praktikum über Faulheit: Faules Aufheben der Verlinkung von deoptimierten Funktionen
Vor ungefähr drei Monaten trat ich dem V8-Team (Google München) als Praktikant bei und habe seitdem am VM Deoptimizer gearbeitet — etwas völlig Neues für mich, das sich als interessantes und herausforderndes Projekt erwies. Der erste Teil meines Praktikums konzentrierte sich auf die Verbesserung der VM aus Sicherheitsaspekten. Der zweite Teil konzentrierte sich auf Leistungsverbesserungen. Nämlich auf das Entfernen einer Datenstruktur, die zum Entlinken zuvor deoptimierter Funktionen verwendet wurde und während der Garbage Collection zu einem Leistungsengpass wurde. Dieser Blog-Beitrag beschreibt diesen zweiten Teil meines Praktikums. Ich werde erklären, wie V8 früher deoptimierte Funktionen entlinkte, wie wir dies geändert haben und welche Leistungsverbesserungen erzielt wurden.
Lassen Sie uns (sehr) kurz die V8-Pipeline für eine JavaScript-Funktion rekapitulieren: V8s Interpreter, Ignition, sammelt Profiling-Informationen über diese Funktion, während er sie interpretiert. Sobald die Funktion heiß wird, werden diese Informationen an den V8 Compiler, TurboFan, weitergegeben, der optimierten Maschinencode erzeugt. Wenn die Profiling-Informationen nicht mehr gültig sind — beispielsweise weil eines der profilierten Objekte während der Laufzeit einen anderen Typ erhält — könnte der optimierte Maschinencode ungültig werden. In diesem Fall muss V8 ihn deoptimieren.
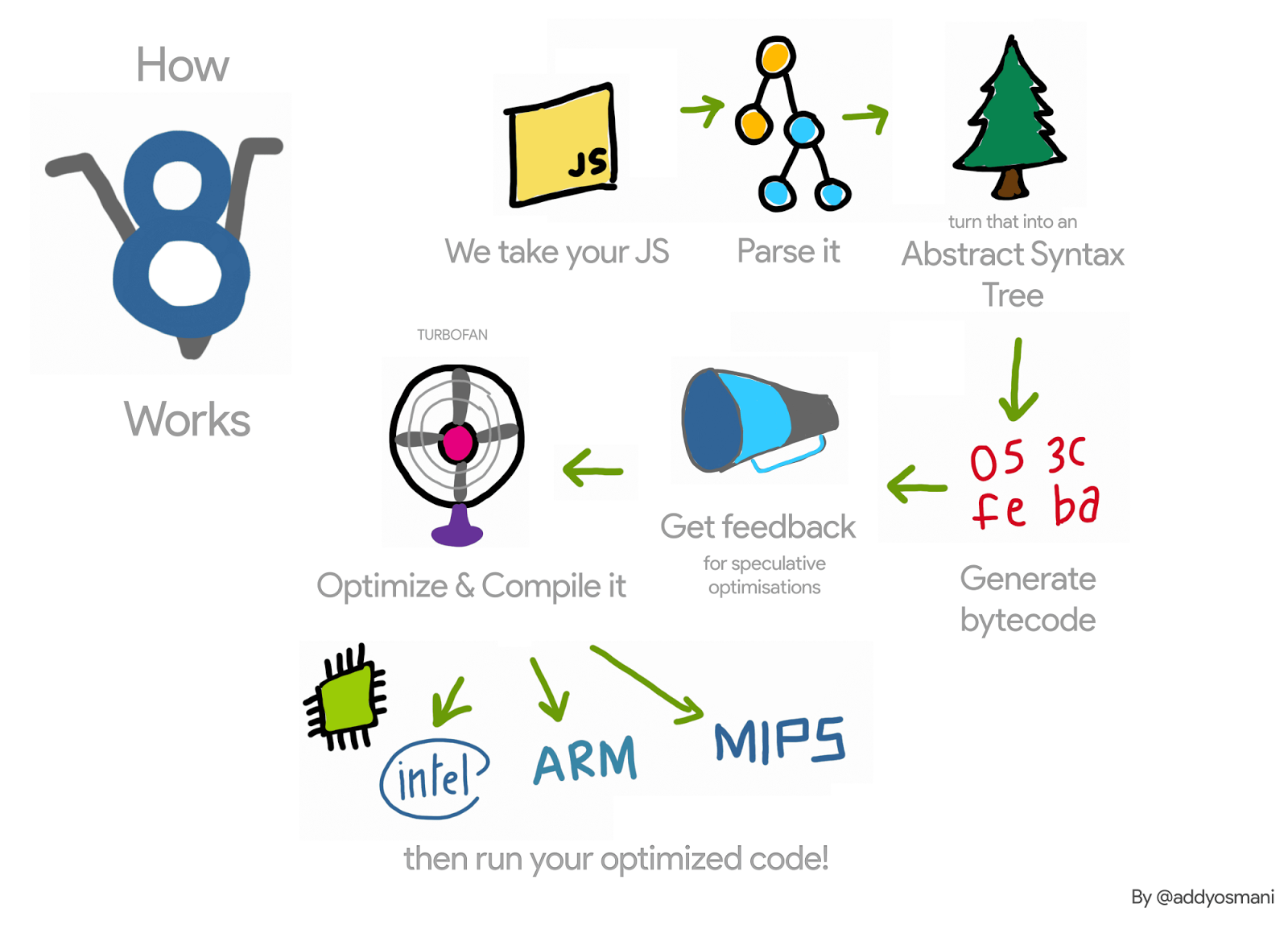
Bei der Optimierung generiert TurboFan ein Code-Objekt, d.h. den optimierten Maschinencode, für die Funktion unter Optimierung. Wenn diese Funktion das nächste Mal aufgerufen wird, folgt V8 dem Link zum optimierten Code für diese Funktion und führt ihn aus. Bei der Deoptimierung dieser Funktion müssen wir das Code-Objekt aufheben, um sicherzustellen, dass es nicht erneut ausgeführt wird. Wie geschieht das?
Zum Beispiel wird die Funktion f1 im folgenden Code viele Male aufgerufen (immer mit einem Integer als Argument). TurboFan erzeugt dann Maschinencode für diesen spezifischen Fall.
function g() {
return (i) => i;
}
// Erstellen eines Closures.
const f1 = g();
// Optimieren von f1.
for (var i = 0; i < 1000; i++) f1(0);
Jede Funktion hat auch ein Trampolin zum Interpreter — nähere Details in diesen Folien — und behält einen Zeiger auf dieses Trampolin in ihrem SharedFunctionInfo (SFI). Dieses Trampolin wird verwendet, wenn V8 wieder auf nicht optimierten Code zurückgehen muss. Daher kann der Deoptimizer bei einer Deoptimierung, die beispielsweise durch das Übergeben eines Arguments eines anderen Typs ausgelöst wird, einfach das Code-Feld der JavaScript-Funktion auf dieses Trampolin setzen.
Obwohl dies einfach erscheint, zwingt es V8 dazu, schwache Listen von optimierten JavaScript-Funktionen zu verwalten. Dies liegt daran, dass es möglich ist, verschiedene Funktionen zu haben, die auf dasselbe optimierte Code-Objekt zeigen. Wir können unser Beispiel wie folgt erweitern, und die Funktionen f1 und f2 zeigen beide auf denselben optimierten Code.
const f2 = g();
f2(0);
Wenn die Funktion f1 deoptimiert wird (zum Beispiel durch ihren Aufruf mit einem Objekt eines anderen Typs {x: 0}), müssen wir sicherstellen, dass der ungültige Code nicht erneut durch den Aufruf von f2 ausgeführt wird.
Daher iterierte V8 früher bei einer Deoptimierung über alle optimierten JavaScript-Funktionen und entlinkte diejenigen, die auf das deoptimierte Code-Objekt zeigten. Diese Iteration wurde in Anwendungen mit vielen optimierten JavaScript-Funktionen zu einem Leistungsengpass. Darüber hinaus verschlechterte V8 die Situation noch, indem es während Stop-the-World-Zyklen der Garbage Collection über diese Listen iterierte.
Um eine Vorstellung vom Einfluss dieser Datenstruktur auf die Leistung von V8 zu bekommen, schrieben wir ein Mikro-Benchmark, das ihre Nutzung betont, indem viele Scavenge-Zyklen ausgelöst werden, nachdem viele JavaScript-Funktionen erstellt wurden.
function g() {
return (i) => i + 1;
}
// Erstellt ein anfängliches Closure und optimieren.
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// Erstellen Sie 2 Millionen Closures; diese erhalten den vorher optimierten Code.
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// Jetzt Scavenges verursachen; alle sind langsam.
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
Beim Ausführen dieses Benchmarks konnten wir beobachten, dass V8 etwa 98% seiner Ausführungszeit mit der Garbage-Collection verbrachte. Wir entfernten dann diese Datenstruktur und verwendeten stattdessen einen Ansatz für das Lazy Unlinking. Dies haben wir auf x64 beobachtet:

Obwohl dies nur ein Mikro-Benchmark ist, der viele JavaScript-Funktionen erstellt und viele Garbage-Collection-Zyklen auslöst, gibt er uns eine Vorstellung von dem durch diese Datenstruktur eingeführten Aufwand. Weitere realistischere Anwendungen, bei denen wir etwas Aufwand sahen und die diese Arbeit motivierten, waren der Router Benchmark, implementiert in Node.js, und der ARES-6 Benchmark Suite.
Lazy Unlinking
Anstatt optimierten Code bei der Deoptimierung von JavaScript-Funktionen zu entkoppeln, verschiebt V8 dies auf den nächsten Aufruf solcher Funktionen. Wenn solche Funktionen aufgerufen werden, überprüft V8, ob sie deoptimiert wurden, entkoppelt sie und fährt dann mit ihrer Lazy-Kompilation fort. Wenn diese Funktionen nie wieder aufgerufen werden, werden sie nie entkoppelt und die deoptimierten Code-Objekte werden nicht gesammelt. Da wir jedoch während der Deoptimierung alle eingebetteten Felder des Code-Objekts ungültig machen, halten wir nur dieses Code-Objekt am Leben.
Der Commit, der diese Liste mit optimierten JavaScript-Funktionen entfernte, erforderte Änderungen in mehreren Teilen der VM, aber die grundlegende Idee ist wie folgt. Beim Erstellen des optimierten Code-Objekts überprüfen wir, ob es sich um den Code einer JavaScript-Funktion handelt. Falls ja, erstellen wir in seinem Prolog Maschinen-Code, um zurückzuspringen, falls das Code-Objekt deoptimiert wurde. Bei der Deoptimierung ändern wir den deoptimierten Code nicht – Code-Patching entfällt. Daher bleibt sein Bit marked_for_deoptimization gesetzt, wenn die Funktion erneut aufgerufen wird. TurboFan generiert Code, um dies zu überprüfen, und wenn es gesetzt ist, springt V8 zu einer neuen eingebauten Funktion, CompileLazyDeoptimizedCode, die den deoptimierten Code von der JavaScript-Funktion entkoppelt und dann mit der Lazy-Kompilation fortfährt.
Im Detail besteht der erste Schritt darin, Anweisungen zu generieren, die die Adresse des gerade zusammengestellten Codes laden. Das können wir auf x64 mit folgendem Code tun:
Label current;
// Effektive Adresse der aktuellen Anweisung in rcx laden.
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
Danach müssen wir bestimmen, wo im Code-Objekt das Bit marked_for_deoptimization liegt.
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
Dann können wir das Bit testen und falls es gesetzt ist, zum eingebauten CompileLazyDeoptimizedCode springen.
// Testen, ob das Bit gesetzt ist, d. h., ob der Code für die Deoptimierung markiert ist.
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// Zum eingebauten Code springen, falls das Bit gesetzt ist.
__ j(not_zero, /* handle to builtin code here */, RelocInfo::CODE_TARGET);
Auf der Seite dieses eingebauten CompileLazyDeoptimizedCode ist alles, was noch zu tun bleibt, den Code-Feld aus der JavaScript-Funktion zu entkoppeln und ihn auf die Trampolin-Adresse des Interpreter-Einstiegs zu setzen. Wenn wir davon ausgehen, dass die Adresse der JavaScript-Funktion im Register rdi ist, können wir den Pointer zu SharedFunctionInfo mit folgendem Code erhalten:
// Feldlesung, um das SharedFunctionInfo zu erhalten.
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
…und ähnlich das Trampolin mit:
// Feldlesung, um das Code-Objekt zu erhalten.
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
Dann können wir es verwenden, um den Funktionsslot für den Code-Zeiger zu aktualisieren:
// Aktualisieren des Code-Feldes der Funktion mit dem Trampolin.
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// Write-Barrier, um das Feld zu schützen.
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
Dies produziert das gleiche Ergebnis wie zuvor. Allerdings müssen wir uns anstelle der Pflege beim Deoptimizer jetzt während der Code-Generierung darum kümmern. Daher die handgeschriebene Assembly.
Das oben Beschriebene ist wie es in der x64-Architektur funktioniert. Wir haben es für ia32, arm, arm64, mips und mips64 ebenfalls implementiert.
Diese neue Technik ist bereits in V8 integriert und ermöglicht, wie wir später besprechen werden, Leistungsverbesserungen. Es gibt jedoch einen kleinen Nachteil: Früher berücksichtigte V8 das Entlinken nur bei einer Deoptimierung. Jetzt muss es dies bei der Aktivierung aller optimierten Funktionen tun. Außerdem ist der Ansatz zur Überprüfung des Bits marked_for_deoptimization nicht so effizient, wie er sein könnte, da wir einige Arbeiten durchführen müssen, um die Adresse des Code-Objekts zu erhalten. Beachten Sie, dass dies beim Eintritt in jede optimierte Funktion geschieht. Eine mögliche Lösung für dieses Problem besteht darin, im Code-Objekt einen Zeiger auf sich selbst zu behalten. Anstatt bei jedem Funktionsaufruf Arbeit zu leisten, um die Adresse des Code-Objekts zu finden, würde V8 dies nur einmal nach seiner Konstruktion tun.
Ergebnisse
Wir betrachten nun die gewonnenen Leistungssteigerungen und Regressionen, die mit diesem Projekt erzielt wurden.
Allgemeine Verbesserungen auf x64
Das folgende Diagramm zeigt einige Verbesserungen und Regressionen im Vergleich zum vorherigen Commit. Beachten Sie, je höher, desto besser.
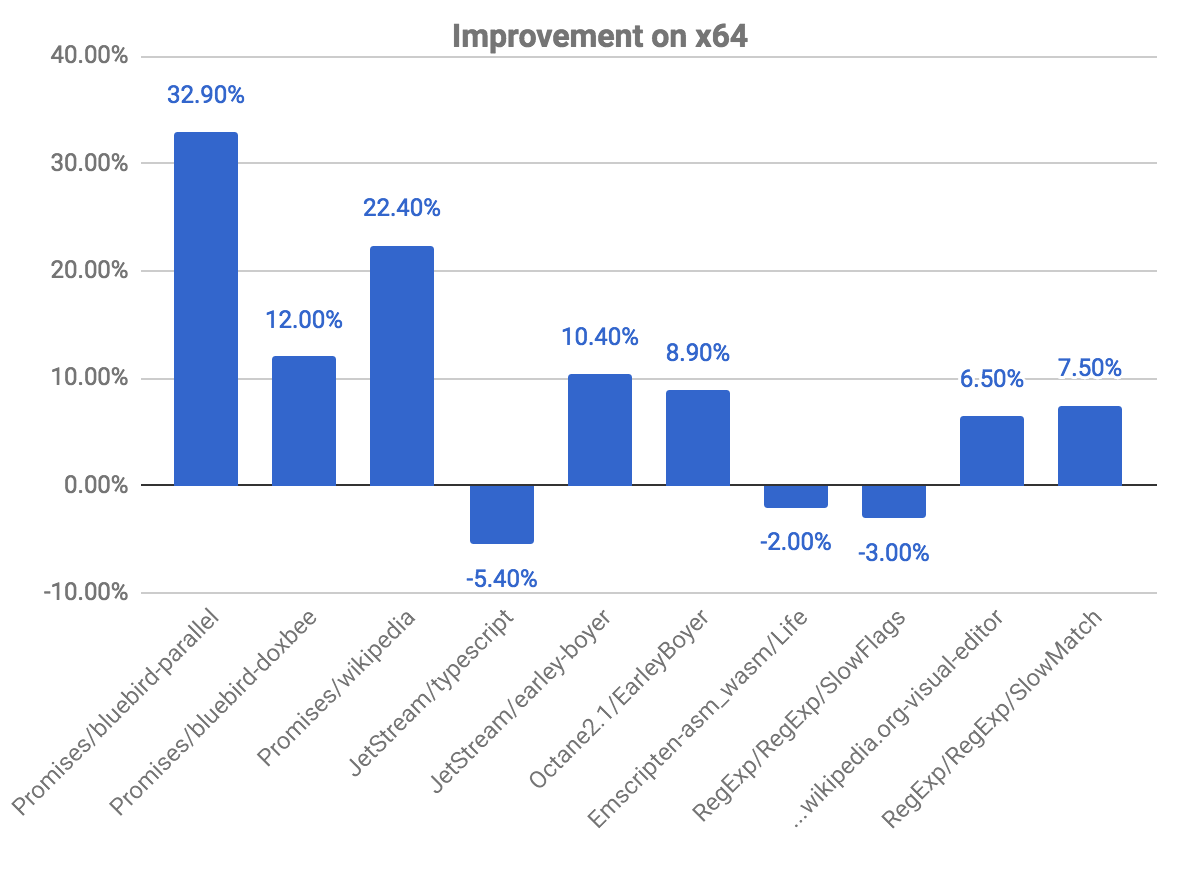
Die Benchmarks für promises zeigen die größten Verbesserungen, wobei fast 33 % Gewinn für den bluebird-parallel-Benchmark und 22,40 % für wikipedia beobachtet wurden. Wir haben auch einige Regressionen in einigen Benchmarks beobachtet. Dies hängt mit dem oben erklärten Problem zusammen, die Überprüfung, ob der Code für die Deoptimierung markiert ist.
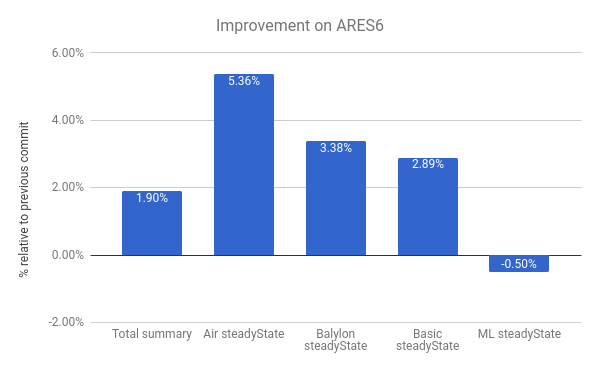
Wir sehen auch Verbesserungen in der ARES-6-Benchmark-Suite. Beachten Sie, dass auch in diesem Diagramm gilt: Je höher, desto besser. Diese Programme verbrachten früher beträchtlich viel Zeit mit GC-bezogenen Aktivitäten. Mit Lazy-Unlinking verbessern wir die Leistung insgesamt um 1,9 %. Der bemerkenswerteste Fall ist Air steadyState, bei dem wir eine Verbesserung von rund 5,36 % erzielen.
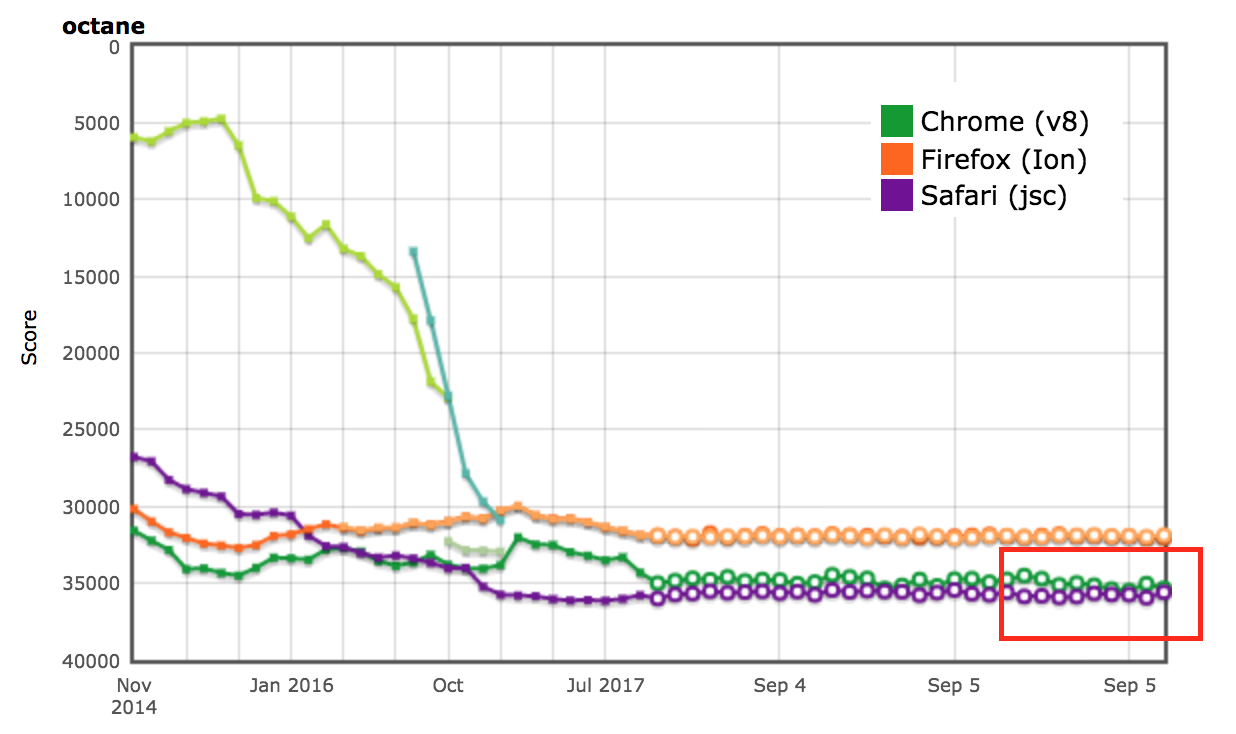
AreWeFastYet-Ergebnisse
Die Leistungsergebnisse für die Octane- und ARES-6-Benchmark-Suiten zeigten sich auch auf dem AreWeFastYet-Tracker. Wir haben diese Leistungsergebnisse am 5. September 2017 unter Verwendung der bereitgestellten Standardmaschine (macOS 10.10 64-Bit, Mac Pro, Shell) überprüft.

Einfluss auf Node.js
Wir können auch Leistungsverbesserungen im router-benchmark-Test sehen. Die folgenden beiden Diagramme zeigen die Anzahl der Operationen pro Sekunde für jeden getesteten Router. Je höher, desto besser. Wir haben zwei Arten von Experimenten mit dieser Benchmark-Suite durchgeführt. Erstens haben wir jeden Test isoliert durchgeführt, um die Leistungsverbesserung unabhängig von den verbleibenden Tests zu sehen. Zweitens haben wir alle Tests gleichzeitig durchgeführt, ohne die VM zu wechseln, wodurch eine Umgebung simuliert wird, in der jeder Test mit anderen Funktionen integriert ist.
Beim ersten Experiment haben wir festgestellt, dass die Tests router und express etwa doppelt so viele Operationen wie zuvor in derselben Zeit ausführen. Beim zweiten Experiment haben wir noch größere Verbesserungen gesehen. In einigen Fällen, wie routr, server-router und router, führt der Benchmark etwa 3,80×, 3× und 2× mehr Operationen aus, jeweils. Dies geschieht, weil V8 nach und nach mehr optimierte JavaScript-Funktionen testweise akkumuliert. Daher muss V8, wenn ein Test ausgeführt wird und ein Garbage-Collection-Zyklus ausgelöst wird, die optimierten Funktionen des aktuellen Tests und der vorherigen Tests besuchen.


Weitere Optimierung
Da V8 die Verkettungsliste der JavaScript-Funktionen im Kontext nicht mehr beibehält, können wir das Feld next aus der Klasse JSFunction entfernen. Obwohl dies eine einfache Änderung ist, ermöglicht sie uns, die Größe eines Zeigers pro Funktion einzusparen, was bedeutende Einsparungen bei mehreren Webseiten darstellt:
| Benchmark | Art | Speicherersparnis (absolut) | Speicherersparnis (relativ) |
|---|---|---|---|
| facebook.com | Durchschnittliche effektive Größe | 170 KB | 3.70% |
| twitter.com | Durchschnittliche Größe der zugewiesenen Objekte | 284 KB | 1.20% |
| cnn.com | Durchschnittliche Größe der zugewiesenen Objekte | 788 KB | 1.53% |
| youtube.com | Durchschnittliche Größe der zugewiesenen Objekte | 129 KB | 0.79% |
Danksagungen
Während meines Praktikums erhielt ich viel Unterstützung von mehreren Personen, die stets bereit waren, meine zahlreichen Fragen zu beantworten. Daher möchte ich mich bei folgenden Personen bedanken: Benedikt Meurer, Jaroslav Sevcik und Michael Starzinger für Diskussionen über die Funktionsweise des Compilers und des Deoptimierers, Ulan Degenbaev für seine Hilfe mit dem Garbage Collector, wann immer ich ihn kaputt gemacht habe, und Mathias Bynens, Peter Marshall, Camillo Bruni und Maya Armyanova für das Korrekturlesen dieses Artikels.
Abschließend ist dieser Artikel mein letzter Beitrag als Google-Praktikant, und ich möchte diese Gelegenheit nutzen, mich bei allen im V8-Team herzlich zu bedanken, insbesondere bei meinem Betreuer Benedikt Meurer, dafür, dass er mich betreut und mir die Möglichkeit gegeben hat, an einem so interessanten Projekt zu arbeiten — ich habe definitiv viel gelernt und meine Zeit bei Google genossen!