JavaScript-Codeabdeckung
Codeabdeckung liefert Informationen darüber, ob und optional wie oft bestimmte Teile einer Anwendung ausgeführt wurden. Sie wird häufig verwendet, um festzustellen, wie gründlich eine Testsuite eine bestimmte Codebasis prüft.
Warum ist das nützlich?
Als JavaScript-Entwickler finden Sie sich möglicherweise oft in einer Situation wieder, in der die Codeabdeckung nützlich sein könnte. Zum Beispiel:
- Interessiert an der Qualität Ihrer Testsuite? Ein großes Legacy-Projekt umgestalten? Die Codeabdeckung kann Ihnen genau zeigen, welche Teile Ihrer Codebasis abgedeckt sind.
- Möchten Sie schnell wissen, ob ein bestimmter Teil der Codebasis erreicht wurde? Anstatt mit
console.logfür printf-ähnliches Debugging oder durch manuelles Durchlaufen des Codes zu instrumentieren, kann die Codeabdeckung Live-Informationen darüber anzeigen, welche Teile Ihrer Anwendungen ausgeführt wurden. - Oder optimieren Sie vielleicht auf Geschwindigkeit und möchten wissen, auf welche Bereiche Sie sich konzentrieren sollten? Ausführungszähldaten können heiße Funktionen und Schleifen aufzeigen.
JavaScript-Codeabdeckung in V8
Früher in diesem Jahr haben wir native Unterstützung für die JavaScript-Codeabdeckung in V8 hinzugefügt. Die erste Version in Version 5.9 bot Abdeckung auf Funktionsebene (zeigt, welche Funktionen ausgeführt wurden), die später in Version 6.2 um Abdeckung auf Blockebene erweitert wurde (ebenso, aber für einzelne Ausdrücke).
Für JavaScript-Entwickler
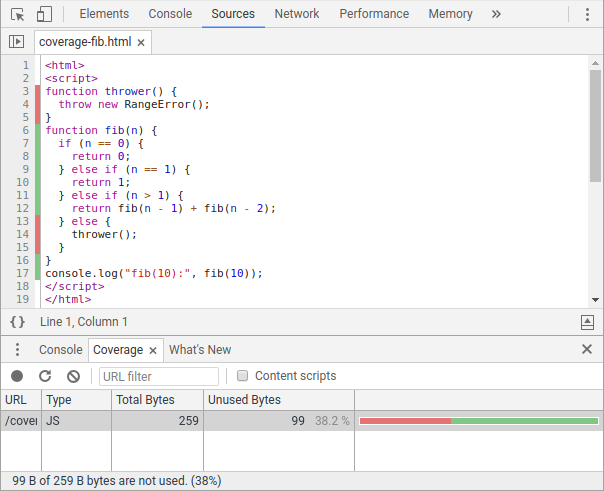
Derzeit gibt es zwei Hauptmöglichkeiten, auf Abdeckungsinformationen zuzugreifen. Für JavaScript-Entwickler zeigt der Abdeckung-Tab in den Chrome DevTools JS- (und CSS-) Abdeckungsverhältnisse an und hebt toten Code im Quelltext-Panel hervor.
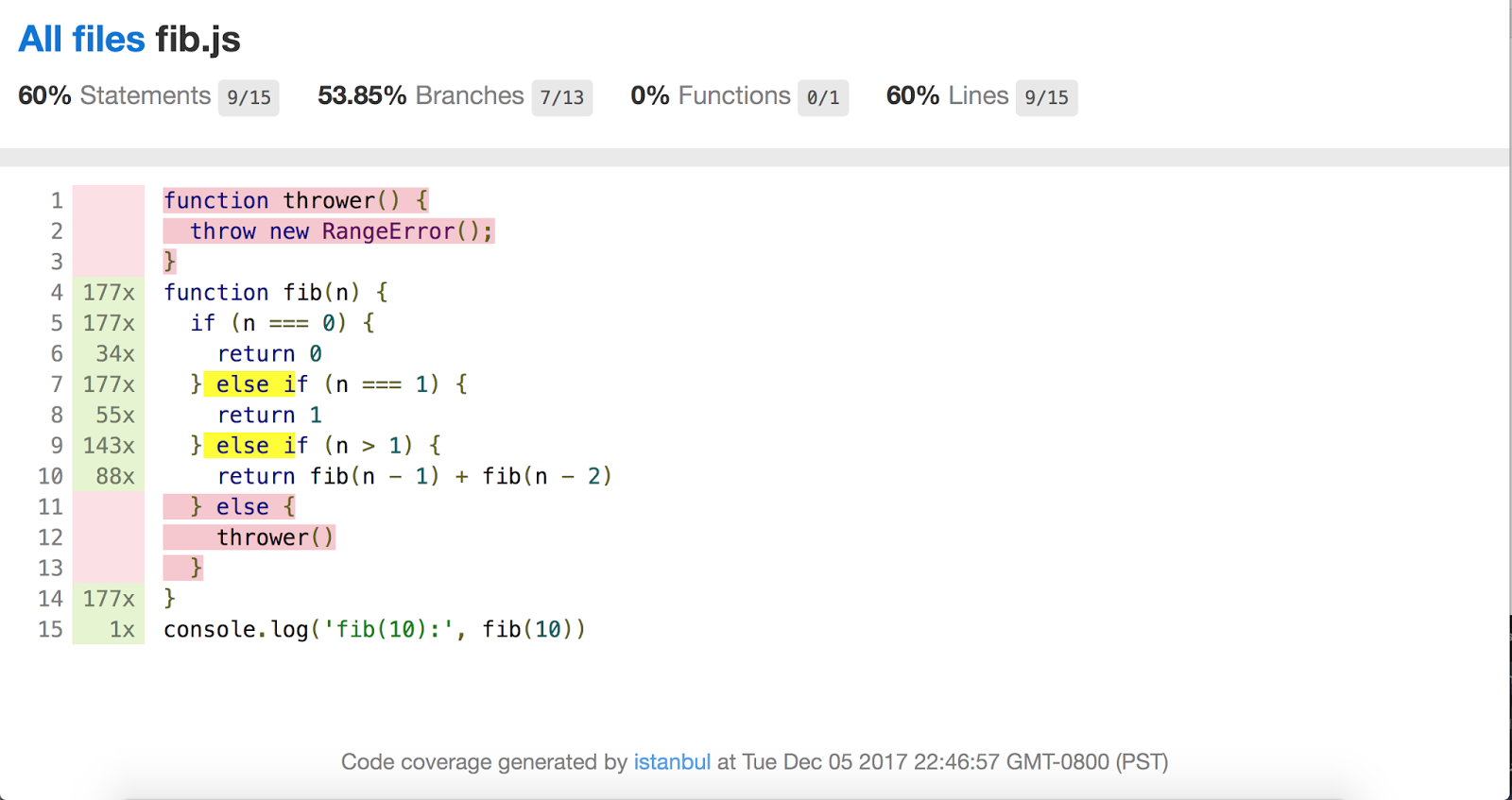
Dank Benjamin Coe gibt es auch fortlaufende Bestrebungen, die Abdeckungsinformationen von V8 in das beliebte Istanbul.js Codeabdeckungstool zu integrieren.
Für Einbinder
Einbinder und Framework-Autoren können direkt an die Inspector-API andocken, um mehr Flexibilität zu erhalten. V8 bietet zwei verschiedene Abdeckungsmodi:
-
Best-effort-Abdeckung sammelt Abdeckungsinformationen mit minimaler Auswirkung auf die Laufzeitleistung, könnte jedoch Daten zu garbage-gesammelten (GC) Funktionen verlieren.
-
Präzise Abdeckung stellt sicher, dass keine Daten durch den GC verloren gehen, und Benutzer können wählen, ob sie Ausführungszähldaten anstelle von binärer Abdeckungsinformation erhalten möchten; die Leistung kann jedoch durch erhöhten Overhead beeinträchtigt sein (siehe den nächsten Abschnitt für weitere Details). Präzise Abdeckung kann entweder auf Funktionsebene oder Blockebene gesammelt werden.
Die Inspector-API für präzise Abdeckung lautet wie folgt:
-
Profiler.startPreciseCoverage(callCount, detailed)aktiviert die Sammlung von Abdeckungsdaten, optional mit Aufrufzählungen (im Gegensatz zu binärer Abdeckung) und Blockgranularität (im Gegensatz zu Funktionengranularität); -
Profiler.takePreciseCoverage()gibt gesammelte Abdeckungsinformationen als Liste von Quelltextbereichen zusammen mit zugehörigen Ausführungszählungen zurück; und -
Profiler.stopPreciseCoverage()deaktiviert die Sammlung und gibt zugehörige Datenstrukturen frei.
Ein Dialog über das Inspector-Protokoll könnte so aussehen:
// Der Einbinder weist V8 an, präzise Abdeckung zu sammeln.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// Der Einbinder fordert Abdeckungsdaten an (Delta seit der letzten Anfrage).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// Die Antwort enthält eine Sammlung verschachtelter Quelltextbereiche.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // Blockgranularität.
"ranges": [ // Ein Array verschachtelter Bereiche.
{
"startOffset": 50, // Byte-Offset, inklusive.
"endOffset": 224, // Byte-Offset, exklusiv.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"Anzahl": 0
}, {
"StartVersatz": 134,
"EndVersatz": 144,
"Anzahl": 0
}, {
"StartVersatz": 192,
"EndVersatz": 223,
"Anzahl": 0
},
]},
"SkriptId": "199",
"Url": "file:///coverage-fib.html"
}
]
}}
// Schließlich weist der Einbettende V8 an, die Sammlung zu beenden und
// verwandte Datenstrukturen freizugeben.
{"id":37,"Methode":"Profiler.stopPreciseCoverage"}
Ebenso kann die bestmögliche Abdeckung mithilfe von Profiler.getBestEffortCoverage() abgerufen werden.
Hinter den Kulissen
Wie im vorherigen Abschnitt erwähnt, unterstützt V8 zwei Hauptmodi der Codeabdeckung: bestmögliche und präzise Abdeckung. Lesen Sie weiter für einen Überblick über deren Implementierung.
Bestmögliche Abdeckung
Sowohl die bestmögliche als auch die präzise Abdeckungsmodi nutzen stark andere V8-Mechanismen wieder, von denen der erste als Aufrufzähler bezeichnet wird. Jedes Mal, wenn eine Funktion durch den Ignition-Interpreter von V8 aufgerufen wird, erhöhen wir einen Aufrufzähler im Feedback-Vektor der Funktion. Wenn die Funktion später „hot“ wird und durch den optimierenden Compiler höhergestuft wird, wird dieser Zähler verwendet, um Inlining-Entscheidungen zu lenken, welche Funktionen inline geschaltet werden sollen. Und jetzt verlassen wir uns auch darauf, um die Codeabdeckung zu melden.
Der zweite wiederverwendete Mechanismus bestimmt den Quellbereich von Funktionen. Beim Melden der Codeabdeckung müssen die Aufrufzähler mit einem zugehörigen Bereich innerhalb der Quelldatei verknüpft werden. Zum Beispiel müssen wir im unten stehenden Beispiel nicht nur melden, dass die Funktion f genau einmal ausgeführt wurde, sondern auch, dass der Quellbereich von f bei Zeile 1 beginnt und in Zeile 3 endet.
function f() {
console.log('Hallo Welt');
}
f();
Erneut hatten wir Glück und konnten bestehende Informationen innerhalb von V8 wiederverwenden. Funktionen wussten bereits aufgrund von Function.prototype.toString ihre Start- und Endpositionen im Quellcode, da diese die Position der Funktion innerhalb der Quelldatei kennen müssen, um den entsprechenden Teilstring zu extrahieren.
Beim Sammeln der bestmöglichen Abdeckung werden diese beiden Mechanismen einfach verknüpft: Zuerst finden wir alle lebenden Funktionen, indem wir den gesamten Heap durchlaufen. Für jede gesehene Funktion melden wir die Aufrufzahl (gespeichert im Feedback-Vektor, auf den wir von der Funktion aus zugreifen können) und den Quellbereich (praktischerweise auf der Funktion selbst gespeichert).
Beachten Sie, dass, da Aufrufzähler unabhängig davon geführt werden, ob die Abdeckung aktiviert ist, die bestmögliche Abdeckung keine Laufzeitkosten verursacht. Es verwendet auch keine dedizierten Datenstrukturen und muss daher weder explizit aktiviert noch deaktiviert werden.
Warum wird dieser Modus also als bestmöglich bezeichnet, was sind seine Einschränkungen? Funktionen, die außer Sichtweite geraten, können vom Garbage Collector freigegeben werden. Das bedeutet, dass die zugehörigen Aufrufzähler verloren gehen und wir in der Tat völlig vergessen, dass diese Funktionen jemals existierten. Ergo „bestmöglich“: Obwohl wir unser Bestes versuchen, können die gesammelten Abdeckungsinformationen unvollständig sein.
Präzise Abdeckung (Funktionalitätsebene)
Im Gegensatz zum bestmöglichen Modus garantiert die präzise Abdeckung, dass die bereitgestellten Abdeckungsinformationen vollständig sind. Um dies zu erreichen, fügen wir alle Feedback-Vektoren dem Root-Set von V8 hinzu, sobald die präzise Abdeckung aktiviert wird, und verhindern so deren Sammlung durch den GC. Während dies sicherstellt, dass keine Informationen verloren gehen, erhöht es den Speicherverbrauch, indem Objekte künstlich am Leben gehalten werden.
Der präzise Abdeckungsmodus kann auch Ausführungszählungen liefern. Dies fügt eine weitere Herausforderung für die präzise Abdeckungsimplementierung hinzu. Denken Sie daran, dass der Aufrufzähler jedes Mal erhöht wird, wenn eine Funktion durch den V8-Interpreter aufgerufen wird, und dass Funktionen höhergestuft und optimiert werden können, sobald sie „hot“ werden. Optimierte Funktionen erhöhen jedoch nicht mehr ihren Aufrufzähler, weshalb der optimierende Compiler deaktiviert werden muss, damit die gemeldete Ausführungsanzahl genau bleibt.
Präzise Abdeckung (Block-Ebene)
Die Abdeckung auf Block-Ebene muss Abdeckung melden, die bis auf die Ebene einzelner Ausdrücke korrekt ist. Zum Beispiel könnte in folgendem Codeblock die Blockabdeckung erkennen, dass der else-Zweig des Konditionalausdrucks : c niemals ausgeführt wird, während die Abdeckung auf Funktionalitätsebene nur weiß, dass die Funktion f (in ihrer Gesamtheit) abgedeckt ist.
function f(a) {
return a ? b : c;
}
f(true);
Wie Sie sich aus den vorherigen Abschnitten erinnern können, hatten wir bereits Funktionsaufrufanzahlen und Quellbereiche innerhalb von V8 bereitgestellt. Leider war dies nicht der Fall für Blockabdeckung, und wir mussten neue Mechanismen implementieren, um sowohl Ausführungszählungen als auch ihre entsprechenden Quellbereiche zu sammeln.
Der erste Aspekt betrifft Quellbereiche: Angenommen, wir haben eine Ausführungszählung für einen bestimmten Block, wie können wir sie einem Abschnitt des Quellcodes zuordnen? Dafür müssen wir relevante Positionen beim Parsen der Quelldateien sammeln. Vor der Blockabdeckung hat V8 dies bereits in gewissem Maße getan. Ein Beispiel ist die Sammlung von Funktionsbereichen aufgrund von Function.prototype.toString, wie oben beschrieben. Ein weiteres Beispiel ist, dass Quellpositionen verwendet werden, um den Rückverfolgungsstapel für Error-Objekte zu erstellen. Aber keines dieser Beispiele reicht aus, um Blockabdeckung zu unterstützen; das erste ist nur für Funktionen verfügbar, während das zweite nur Positionen speichert (z. B. die Position des if-Tokens für if-else-Anweisungen), nicht aber Quellbereiche.
Wir mussten daher den Parser erweitern, um Quellbereiche zu sammeln. Um dies zu demonstrieren, betrachten Sie eine if-else-Anweisung:
if (cond) {
/* Then-Zweig. */
} else {
/* Else-Zweig. */
}
Wenn die Blockabdeckung aktiviert ist, sammeln wir die Quellbereiche der then- und else-Zweige und verknüpfen sie mit dem analysierten IfStatement-AST-Knoten. Das Gleiche wird für andere relevante Sprachkonstrukte durchgeführt.
Nachdem die Quellbereichssammlung beim Parsen durchgeführt wurde, besteht der zweite Aspekt darin, die Ausführungszählungen zur Laufzeit zu verfolgen. Dies geschieht durch Einfügen eines neuen dedizierten IncBlockCounter-Bytecodes an strategischen Positionen innerhalb des generierten Bytecode-Arrays. Zur Laufzeit erhöht der IncBlockCounter-Bytecode-Handler einfach den entsprechenden Zähler (erreichbar über das Funktionsobjekt).
Im obigen Beispiel einer if-else-Anweisung würden solche Bytecodes an drei Stellen eingefügt werden: unmittelbar vor dem Körper des then-Zweigs, vor dem Körper des else-Zweigs und unmittelbar nach der if-else-Anweisung (solche Fortsetzungszähler sind aufgrund der Möglichkeit nicht-lokaler Kontrollstrukturen innerhalb eines Zweigs erforderlich).
Schließlich funktioniert die Berichterstattung über Blockgranularität ähnlich wie die Berichterstattung über Funktionsgranularität. Aber zusätzlich zu den Aufrufzählungen (aus dem Feedback-Vektor) berichten wir jetzt auch über die Sammlung von interessanten Quellbereichen zusammen mit ihren Blockzählungen (gespeichert auf einer Hilfsdatenstruktur, die von der Funktion abgeleitet wird).
Wenn Sie mehr über die technischen Details hinter der Codeabdeckung in V8 erfahren möchten, lesen Sie die Design-Dokumente zu Abdeckung und Blockabdeckung.
Fazit
Wir hoffen, dass Ihnen diese kurze Einführung in die native Codeabdeckungsunterstützung von V8 gefallen hat. Bitte probieren Sie es aus und zögern Sie nicht, uns mitzuteilen, was für Sie funktioniert und was nicht. Sagen Sie Hallo auf Twitter (@schuay und @hashseed) oder melden Sie einen Fehler unter crbug.com/v8/new.
Die Unterstützung der Codeabdeckung in V8 war eine Teamleistung, und Dank ist angebracht für alle, die dazu beigetragen haben: Benjamin Coe, Jakob Gruber, Yang Guo, Marja Hölttä, Andrey Kosyakov, Alexey Kozyatinksiy, Ross McIlroy, Ali Sheikh, Michael Starzinger. Vielen Dank!