Eingebettete Builtins
V8-Funktionen (Builtins) verbrauchen Speicher in jeder Instanz von V8. Die Anzahl der Builtins, deren durchschnittliche Größe und die Anzahl der V8-Instanzen pro Chrome-Browser-Tab haben erheblich zugenommen. Dieser Blog-Beitrag beschreibt, wie wir die mediane V8-Heap-Größe pro Website im vergangenen Jahr um 19 % reduziert haben.
Hintergrund
V8 wird mit einer umfangreichen Bibliothek von JavaScript (JS) eingebauten Funktionen ausgeliefert. Viele Builtins werden JS-Entwicklern direkt als Funktionen auf JS-Built-in-Objekten zur Verfügung gestellt, wie z. B. RegExp.prototype.exec und Array.prototype.sort; andere Builtins implementieren verschiedene interne Funktionalitäten. Der Maschinencode für Builtins wird von V8s eigenem Compiler generiert und bei der Initialisierung auf den verwalteten Heap-Zustand für jeden V8-Isolate geladen. Ein Isolate stellt eine isolierte Instanz der V8-Engine dar, und jeder Browser-Tab in Chrome enthält mindestens ein Isolate. Jedes Isolate hat seinen eigenen verwalteten Heap und damit seine eigene Kopie aller Builtins.
Im Jahr 2015 wurden Builtins größtenteils in selbstgehostetem JS, nativer Assembly oder in C++ implementiert. Sie waren relativ klein, und das Erstellen einer Kopie für jedes Isolate war weniger problematisch.
In den letzten Jahren hat sich in diesem Bereich viel verändert.
Im Jahr 2016 begann V8 mit Experimenten zu Builtins, die in CodeStubAssembler (CSA) implementiert wurden. Dies erwies sich als sowohl bequem (plattformunabhängig, lesbar) als auch effizient in der Codeerzeugung, sodass CSA-Builtins allgegenwärtig wurden. Aus verschiedenen Gründen neigen CSA-Builtins dazu, größeren Code zu erzeugen, und die Größe von V8-Builtins verdreifachte sich ungefähr, da immer mehr auf CSA portiert wurden. Bis Mitte 2017 war ihr Isolate-bezogener Overhead erheblich angestiegen und wir begannen, über eine systematische Lösung nachzudenken.
Ende 2017 implementierten wir die Lazy-Builtin- (und Bytecode-Handler-) Deserialisierung als ersten Schritt. Unsere anfängliche Analyse zeigte, dass die meisten Websites weniger als die Hälfte aller Builtins verwendeten. Mit der Lazy-Deserialisierung werden Builtins bei Bedarf geladen, und ungenutzte Builtins werden nie in das Isolate geladen. Die Lazy-Deserialisierung wurde in Chrome 64 mit vielversprechenden Speichereinsparungen ausgeliefert. Aber: Der Speicher-Overhead der Builtins war weiterhin linear zur Anzahl der Isolates.
Dann wurde Spectre offengelegt, und Chrome aktivierte schließlich Site-Isolation, um dessen Auswirkungen zu mildern. Die Site-Isolation beschränkt einen Chrome-Renderer-Prozess auf Dokumente aus einer einzigen Herkunft. Mit der Site-Isolation erstellen viele Browser-Tabs mehr Renderer-Prozesse und mehr V8-Isolates. Obwohl die Verwaltung des Isolate-bezogenen Overheads schon immer wichtig war, hat die Site-Isolation dies noch relevanter gemacht.
Eingebettete Builtins
Unser Ziel für dieses Projekt war es, den Isolate-bezogenen Builtin-Overhead vollständig zu eliminieren.
Die Idee dahinter war einfach. Konzeptuell sind Builtins über Isolates hinweg identisch und nur aufgrund von Implementierungsdetails an ein Isolate gebunden. Wenn wir Builtins wirklich Isolate-unabhängig machen könnten, könnten wir eine einzige Kopie im Speicher behalten und sie über alle Isolates hinweg teilen. Und wenn wir sie Prozess-unabhängig machen könnten, könnten sie sogar prozessübergreifend geteilt werden.
In der Praxis standen wir vor mehreren Herausforderungen. Der generierte Builtin-Code war weder Isolate- noch Prozess-unabhängig aufgrund eingebetteter Zeiger zu isolate- und prozessspezifischen Daten. V8 hatte kein Konzept, generierten Code auszuführen, der sich außerhalb des verwalteten Heaps befindet. Builtins mussten über Prozesse hinweg geteilt werden, idealerweise durch Wiederverwendung vorhandener Betriebssystemmechanismen. Und schließlich (dies sollte sich als das langwierige herausstellen) durfte die Leistung nicht merklich nachlassen.
Die folgenden Abschnitte beschreiben unsere Lösung im Detail.
Isolate- und prozessunabhängiger Code
Builtins werden durch die interne Compiler-Pipeline von V8 generiert, die Referenzen auf Heap-Konstanten (befindlich im verwalteten Heap des Isolate), Aufrufziele (Code-Objekte, ebenfalls im verwalteten Heap) sowie auf isolate- und prozess-spezifische Adressen (z. B.: C-Runtime-Funktionen oder einen Zeiger auf das Isolate selbst, auch ‚external references‘ genannt) direkt in den Code einbettet. In x64-Assembly könnte ein Ladevorgang eines solchen Objekts wie folgt aussehen:
// Eine eingebettete Adresse in das Register rbx laden. REX.W movq rbx,0x56526afd0f70
V8 verfügt über einen dynamischen Garbage Collector, und der Standort des Zielobjekts kann sich im Laufe der Zeit ändern. Sollte das Ziel während der Sammlung verschoben werden, aktualisiert der GC den generierten Code, um auf den neuen Standort zu zeigen.
Auf x64 (und den meisten anderen Architekturen) verwenden Aufrufe anderer Code-Objekte eine effiziente Call-Instruktion, die das Aufrufziel durch einen Offset vom aktuellen Program Counter spezifiziert (ein interessanter Aspekt: V8 reserviert seinen gesamten CODE_SPACE auf dem verwalteten Heap beim Start, um sicherzustellen, dass alle möglichen Code-Objekte innerhalb eines adressierbaren Offsets voneinander bleiben). Der relevante Teil der Aufrufsequenz sieht so aus:
// Aufrufinstruktion, die sich bei [pc + <offset>] befindet.
call <offset>
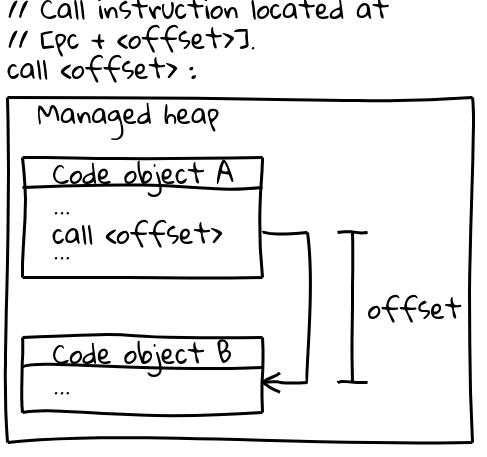
Code-Objekte selbst befinden sich auf dem verwalteten Heap und sind verschiebbar. Wenn sie verschoben werden, aktualisiert der GC den Offset an allen relevanten Aufruforten.
Um eingebettete Objekte zwischen Prozessen zu teilen, muss generierter Code sowohl unveränderlich als auch isolierungs- und prozessunabhängig sein. Beide oben genannten Instruktionssequenzen erfüllen diese Anforderungen nicht: Sie betten Adressen direkt in den Code ein und werden zur Laufzeit vom GC gepatcht.
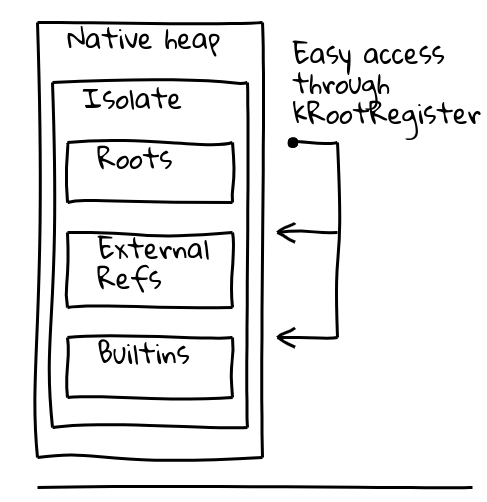
Um beide Probleme zu lösen, führten wir eine Indirektion durch ein spezielles, sogenanntes Root-Register ein, das einen Zeiger auf eine bekannte Position innerhalb der aktuellen Isolate enthält.
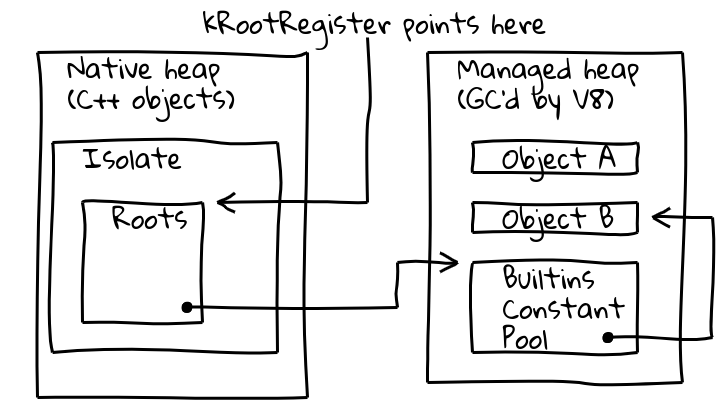
Die Isolate-Klasse von V8 enthält die Root-Tabelle, die ihrerseits Zeiger auf Root-Objekte auf dem verwalteten Heap enthält. Das Root-Register hält dauerhaft die Adresse der Root-Tabelle.
Der neue, isolierungs- und prozessunabhängige Weg, ein Root-Objekt zu laden, wird somit:
// Lade die konstante Adresse, die sich beim gegebenen
// Offset von den Roots befindet.
REX.W movq rax,[kRootRegister + <offset>]
Heap-Konstanten aus den Roots können direkt wie oben aus der Root-Liste geladen werden. Andere Heap-Konstanten verwenden eine zusätzliche Indirektion durch einen globalen eingebetteten Konstantenpool, der selbst in der Root-Liste gespeichert ist:
// Lade den eingebetteten Konstantenpool und dann die
// gewünschte Konstante.
REX.W movq rax,[kRootRegister + <offset>]
REX.W movq rax,[rax + 0x1d7]
Für Code-Ziele wechselten wir zunächst zu einer komplizierteren Aufrufsequenz, bei der das Ziel-Code-Objekt zunächst aus dem globalen eingebetteten Konstantenpool wie oben geladen wird, die Zieladresse in ein Register geladen wird und schließlich ein indirekter Aufruf durchgeführt wird.
Mit diesen Änderungen wurde generierter Code isolierungs- und prozessunabhängig, und wir konnten damit beginnen, ihn zwischen Prozessen zu teilen.
Teilen zwischen Prozessen
Wir haben zunächst zwei Alternativen bewertet. Eingebettete Objekte könnten entweder durch mmap-ing einer Datendatei in den Speicher geteilt werden; oder sie könnten direkt im Binärprogramm eingebettet werden. Wir haben den letzteren Ansatz gewählt, da er den Vorteil hatte, dass wir automatisch Standard-OS-Mechanismen zur gemeinsamen Nutzung von Speicher zwischen Prozessen wiederverwenden würden, und die Änderung würde keine zusätzliche Logik von V8-Einbettungen wie Chrome erfordern. Wir waren zuversichtlich in diesen Ansatz, da Darts AOT-Kompilierung generated Code bereits erfolgreich binär eingebettet hatte.
Eine ausführbare Binärdatei ist in mehrere Abschnitte unterteilt. Beispielsweise enthält eine ELF-Binärdatei Daten im Abschnitt .data (initialisierte Daten), .ro_data (initialisierte read-only Daten) und .bss (nicht initialisierte Daten), während nativer ausführbarer Code in .text abgelegt wird. Unser Ziel war es, eingebetteten Code in den Abschnitt .text zusammen mit nativem Code zu packen.
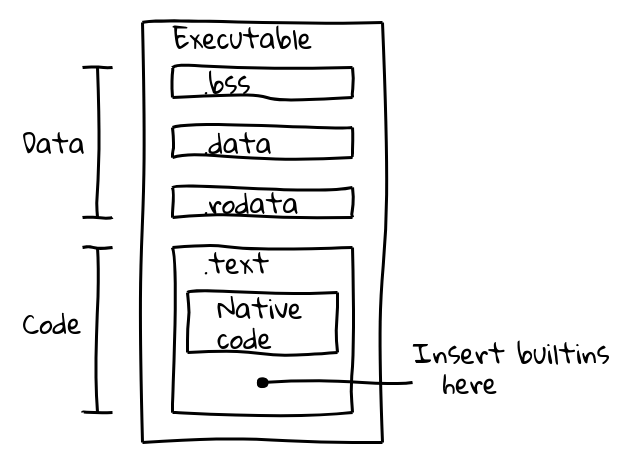
Dies wurde durch die Einführung eines neuen Build-Schritts erreicht, der die interne Compiler-Pipeline von V8 nutzt, um nativen Code für alle eingebetteten Objekte zu generieren und deren Inhalte in embedded.cc auszugeben. Diese Datei wird dann in die endgültige V8-Binärdatei kompiliert.
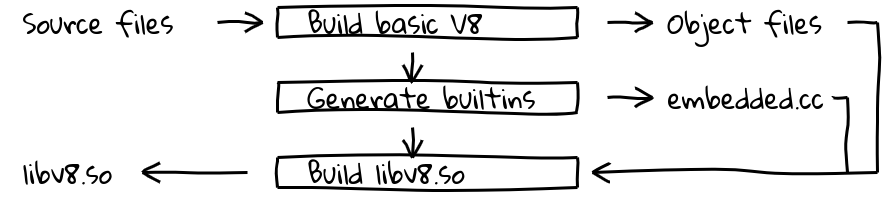
Die Datei embedded.cc enthält selbst sowohl Metadaten als auch generierten eingebetteten Maschinencode als eine Reihe von .byte-Direktiven, die den C++-Compiler (in unserem Fall clang oder gcc) anweisen, die angegebene Byte-Sequenz direkt in die Ausgabedatei (und später die ausführbare Datei) einzufügen.
// Informationen über eingebettete Objekte sind in
// einer Metadaten-Tabelle enthalten.
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[Metadaten abgeschnitten]
// Gefolgt vom generierten Maschinencode.
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[eingebetteter Code abgeschnitten]
Inhalte des Abschnitts .text werden zur Laufzeit in einen read-only ausführbaren Speicherbereich geladen, und das Betriebssystem wird Speicher zwischen Prozessen teilen, solange er nur positionsunabhängigen Code ohne verschiebbare Symbole enthält. Genau das war unser Ziel.
Aber V8-Code-Objekte bestehen nicht nur aus dem Instruktionsstrom, sondern enthalten auch verschiedene (manchmal isolate-abhängige) Metadaten. Normale Code-Objekte kombinieren sowohl Metadaten als auch den Instruktionsstrom in einem variabel großen Code-Objekt, das sich auf dem verwalteten Heap befindet.
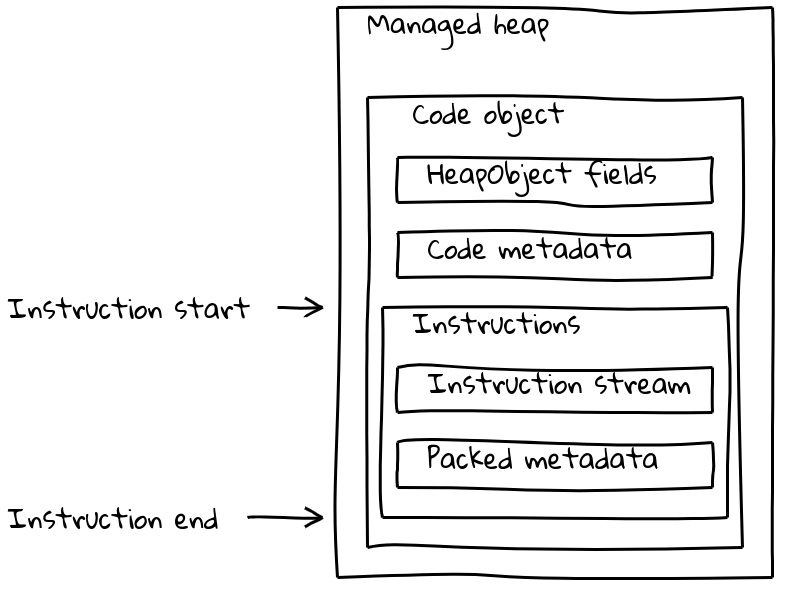
Wie wir gesehen haben, befinden sich eingebettete Builtins mit ihrem nativen Instruktionsstream außerhalb des verwalteten Heaps und sind im .text-Abschnitt eingebettet. Um ihre Metadaten zu erhalten, hat jedes eingebettete Builtin auch ein kleines zugehöriges Code-Objekt auf dem verwalteten Heap, das Off-Heap-Trampolin genannt wird. Metadaten werden auf dem Trampolin wie bei Standard-Code-Objekten gespeichert, während der inline-Instruktionsstrom einfach eine kurze Sequenz enthält, die die Adresse der eingebetteten Instruktionen lädt und dorthin springt.
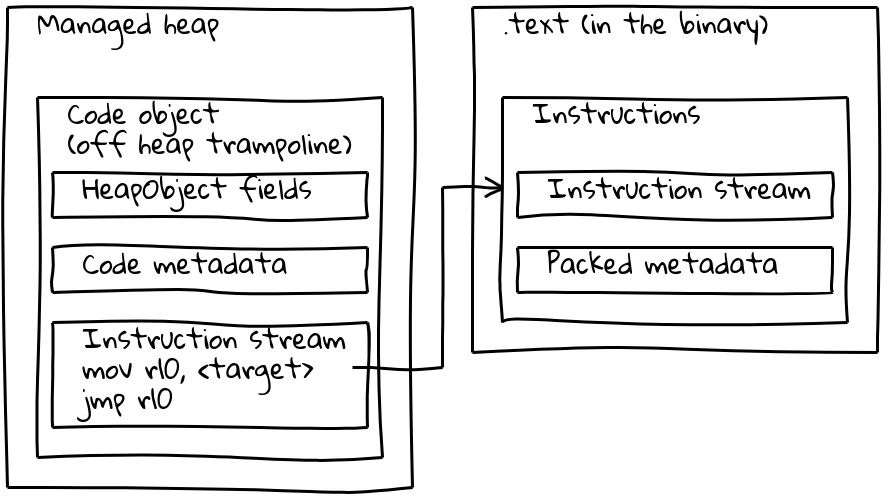
Das Trampolin ermöglicht es V8, alle Code-Objekte einheitlich zu handhaben. Für die meisten Zwecke ist es irrelevant, ob das gegebene Code-Objekt sich auf Standard-Code auf dem verwalteten Heap oder auf ein eingebettetes Builtin bezieht.
Optimierung für Leistung
Mit der in den vorherigen Abschnitten beschriebenen Lösung waren eingebettete Builtins im Wesentlichen funktionsfähig, aber Benchmarks zeigten, dass sie mit erheblichen Verlangsamungen einhergingen. Beispielsweise verschlechterte unsere anfängliche Lösung Speedometer 2.0 insgesamt um mehr als 5%.
Wir begannen, nach Optimierungsmöglichkeiten zu suchen, und identifizierten die Hauptursachen für die Verlangsamungen. Der generierte Code war aufgrund häufiger indirekter Zugriffe auf von isolate- und prozessabhängigen Objekten langsamer. Root-Konstanten wurden aus der Root-Liste geladen (1 Indirektion), andere Heap-Konstanten aus dem globalen Constant-Pool der Builtins (2 Indirektionen), und externe Referenzen mussten zusätzlich aus einem Heap-Objekt entpackt werden (3 Indirektionen). Der schlimmste Fall war unsere neue Aufrufsequenz, die das Trampolin-Code-Objekt laden, dieses aufrufen und dann zur Zieladresse springen musste. Schließlich scheint es, dass Aufrufe zwischen dem verwalteten Heap und dem binär eingebetteten Code inhärent langsamer waren, möglicherweise aufgrund der langen Sprungweite, die die Verzweigungsvorhersage der CPU beeinträchtigt.
Unsere Arbeit konzentrierte sich daher darauf, 1. Indirektionen zu reduzieren und 2. die Aufrufsequenz für Builtin zu verbessern. Um ersteres anzugehen, änderten wir das Isolate-Objekt-Layout, um die meisten Objektladungen in eine einzelne Root-relative Ladeoperation umzuwandeln. Der globale Constant-Pool der Builtins existiert weiterhin, enthält jedoch nur selten zugegriffene Objekte.
Die Aufrufsequenzen wurden in zwei Bereichen erheblich verbessert. Builtin-zu-Builtin-Aufrufe wurden in eine einzelne pc-relative Aufrufinstruktion umgewandelt. Dies war nicht für zur Laufzeit generierten JIT-Code möglich, da der pc-relative Offset den maximalen 32-Bit-Wert überschreiten könnte. Hier haben wir das Off-Heap-Trampolin in alle Aufrufstellen eingebettet, wodurch die Aufrufsequenz von 6 auf nur 2 Instruktionen reduziert wurde.
Mit diesen Optimierungen konnten wir die Rückschritte bei Speedometer 2.0 auf etwa 0,5% begrenzen.
Ergebnisse
Wir haben die Auswirkungen eingebetteter Builtins auf x64 anhand der 10k beliebtesten Websites bewertet und mit den oben beschriebenen Lazy- und Eager-Deserialization verglichen.
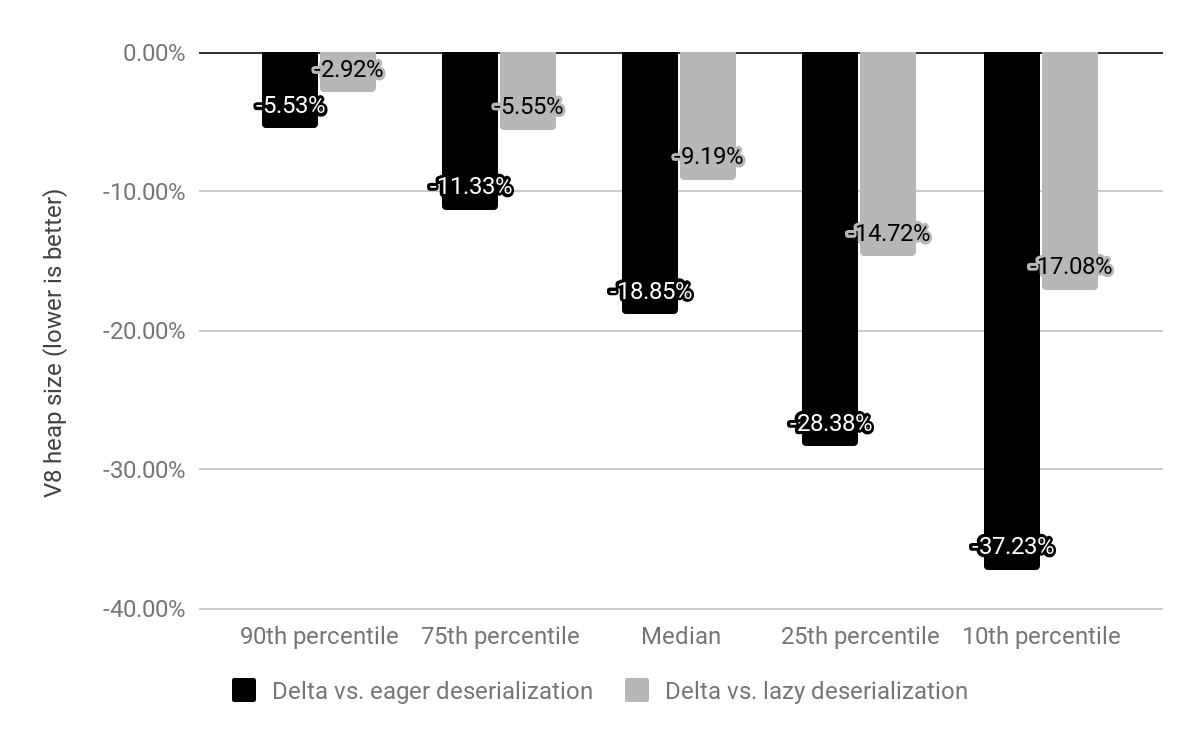
Während Chrome zuvor mit einem speichergemappten Snapshot ausgeliefert wurde, den wir für jedes Isolate deserialisierten, wird der Snapshot jetzt durch eingebettete Builtins ersetzt, die weiterhin speichergemappt sind, aber nicht deserialisiert werden müssen. Die Kosten für Builtins betrugen früher c*(1 + n), wobei n die Anzahl der Isolates und c die Speicherkosten aller Builtins sind, während sie jetzt nur noch c * 1 betragen (in der Praxis bleibt ein kleiner Overhead pro Isolate auch für Off-Heap-Trampoline bestehen).
Im Vergleich zur Eager-Deserialization reduzierten wir die mediane V8-Heap-Größe um 19%. Die mediane Chrome-Renderer-Prozessgröße pro Seite ist um 4% gesunken. Absolut liegt die Ersparnis im 50. Perzentil bei 1,9 MB, im 30. Perzentil bei 3,4 MB und im 10. Perzentil bei 6,5 MB pro Seite.
Signifikante zusätzliche Speicherersparnisse werden erwartet, sobald Bytecode-Handler ebenfalls binär eingebettet werden.
Eingebettete Builtins werden in Chrome 69 auf x64 eingeführt, und mobile Plattformen folgen in Chrome 70. Unterstützung für ia32 wird voraussichtlich Ende 2018 veröffentlicht.
Hinweis: Alle Diagramme wurden mit Vyacheslav Egorovs großartigem Shaky Diagramming-Tool generiert.