Liftoff: ein neuer Basis-Compiler für WebAssembly in V8
V8 v6.9 beinhaltet Liftoff, einen neuen Basis-Compiler für WebAssembly. Liftoff ist standardmäßig auf Desktop-Systemen aktiviert. Dieser Artikel erläutert die Motivation für die Einführung einer weiteren Kompilierungsstufe und beschreibt die Implementierung und Leistung von Liftoff.

Seit WebAssembly eingeführt wurde vor mehr als einem Jahr, nimmt die Verbreitung im Web stetig zu. Große Anwendungen, die auf WebAssembly abzielen, sind aufgetaucht. Zum Beispiel umfasst Epics ZenGarden Benchmark ein 39,5 MB großes WebAssembly-Binary, und AutoDesk wird als 36,8 MB großes Binary ausgeliefert. Da die Kompilierungszeit im Wesentlichen linear zur Größe des Binaries ist, dauert der Start dieser Anwendungen eine beträchtliche Zeit. Auf vielen Maschinen sind es mehr als 30 Sekunden, was keine großartige Benutzererfahrung bietet.
Aber warum dauert es so lange, eine WebAssembly-App zu starten, wenn ähnliche JS-Apps viel schneller starten? Der Grund ist, dass WebAssembly vorhersehbare Leistung verspricht; sobald die App läuft, können Sie sicher sein, dass Ihre Leistungsziele konsequent erreicht werden (z. B. 60 Frames pro Sekunde, keine Audiolatenz oder Artefakte ...). Um dies zu erreichen, wird WebAssembly-Code in V8 vorher kompiliert, um Pausen durch einen Just-in-Time-Compiler zu vermeiden, die sichtbares Ruckeln in der App verursachen könnten.
Die bestehende Kompilierungspipeline (TurboFan)
V8s Ansatz zur Kompilierung von WebAssembly basierte auf TurboFan, dem Optimierungscompiler, den wir für JavaScript und asm.js entwickelt haben. TurboFan ist ein leistungsstarker Compiler mit einer graphenbasierten Zwischenrepräsentation (IR), die fortschrittliche Optimierungen wie Stärkenreduktion, Inlining, Codebewegung, Instruktionskombination und anspruchsvolle Registerzuweisung ermöglicht. TurboFans Design unterstützt das späte Einsteigen in die Pipeline, näher an den Maschinencode, wodurch viele der für die Unterstützung der JavaScript-Kompilierung erforderlichen Phasen umgangen werden. Durch das Design ist die Umwandlung von WebAssembly-Code in TurboFans IR (einschließlich SSA-Konstruktion) in einem einzigen Durchlauf sehr effizient, teilweise aufgrund des strukturierten Kontrollflusses von WebAssembly. Trotzdem verbraucht der Backend-Prozess der Kompilierung weiterhin beträchtlich Zeit und Speicher.
Die neue Kompilierungspipeline (Liftoff)
Das Ziel von Liftoff ist es, die Startzeit für WebAssembly-basierte Apps zu verkürzen, indem Code so schnell wie möglich generiert wird. Die Codequalität ist zweitrangig, da heißer Code ohnehin später mit TurboFan neu kompiliert wird. Liftoff vermeidet den Zeit- und Speicheraufwand für den Aufbau einer IR und generiert Maschinencode in einem einzigen Durchlauf über den Bytecode einer WebAssembly-Funktion.

Aus dem obigen Diagramm ist ersichtlich, dass Liftoff Code viel schneller generieren sollte als TurboFan, da die Pipeline nur aus zwei Schritten besteht. Tatsächlich führt der Funktionskörperdecoder einen einzigen Durchlauf über die rohen WebAssembly-Bytes durch und interagiert über Rückrufe mit der nächsten Stufe, sodass die Codegenerierung während des Dekodierens und Validierens des Funktionskörpers durchgeführt wird. Zusammen mit den Streaming-APIs von WebAssembly ermöglicht dies V8, WebAssembly-Code in Maschinencode zu kompilieren, während er über das Netzwerk heruntergeladen wird.
Codegenerierung in Liftoff
Liftoff ist ein einfacher und schneller Codegenerator. Es führt nur einen Durchlauf über die Opcodes einer Funktion durch und generiert Code für jeden Opcode jeweils einzeln. Bei einfachen Opcodes wie arithmetischen Operationen ist dies oft eine einzige Maschinenanweisung, kann jedoch bei anderen wie Aufrufen mehr sein. Liftoff verwaltet Metadaten über den Operand-Stack, um zu wissen, wo die Eingaben jeder Operation derzeit gespeichert sind. Dieser virtuelle Stack existiert nur während der Kompilierung. Der strukturierte Kontrollfluss und die Validierungsregeln von WebAssembly garantieren, dass der Speicherort dieser Eingaben statisch bestimmt werden kann. Daher ist ein tatsächlicher Laufzeit-Stack, auf den Operanden geschoben und herausgenommen werden, nicht notwendig. Während der Ausführung wird jeder Wert auf dem virtuellen Stack entweder in einem Register gehalten oder in den physischen Stack-Frame dieser Funktion ausgelagert. Bei kleinen Ganzzahlen (generiert durch i32.const) speichert Liftoff nur den Wert der Konstante im virtuellen Stack und generiert keinen Code. Erst wenn die Konstante durch eine nachfolgende Operation verwendet wird, wird sie ausgegeben oder mit der Operation kombiniert, zum Beispiel durch direktes Ausgeben einer addl <reg>, <const>-Anweisung auf x64. Dies verhindert, dass diese Konstante jemals in ein Register geladen wird, was zu besserem Code führt.
Lassen Sie uns eine sehr einfache Funktion durchgehen, um zu sehen, wie Liftoff dafür Code generiert.

Diese Beispiel-Funktion nimmt zwei Parameter und gibt ihre Summe zurück. Wenn Liftoff die Bytes dieser Funktion dekodiert, beginnt es zuerst mit der Initialisierung seines internen Zustands für die lokalen Variablen gemäß der Aufrufkonvention für WebAssembly-Funktionen. Für x64 übergibt V8's Aufrufkonvention die beiden Parameter in den Registern rax und rdx.
Für get_local-Anweisungen generiert Liftoff keinen Code, sondern aktualisiert stattdessen nur seinen internen Zustand, um widerzuspiegeln, dass diese Registerwerte jetzt auf den virtuellen Stack gestapelt werden. Die i32.add-Anweisung entnimmt dann die beiden Register und wählt ein Register für den Ergebniswert aus. Wir können keines der Eingabe-Register für das Ergebnis verwenden, da beide Register weiterhin auf dem Stack erscheinen, um die lokalen Variablen zu halten. Wenn man sie überschreiben würde, würden die Werte, die durch eine spätere get_local-Anweisung zurückgegeben werden, verändert. Daher wählt Liftoff ein freies Register, in diesem Fall rcx, und berechnet die Summe von rax und rdx in dieses Register. rcx wird dann auf den virtuellen Stack gestapelt.
Nach der i32.add-Anweisung ist der Funktionskörper beendet, daher muss Liftoff die Funktion Rückgabe zusammenstellen. Da unsere Beispiel-Funktion einen Rückgabewert hat, erfordert die Validierung, dass am Ende des Funktionskörpers genau ein Wert auf dem virtuellen Stack sein muss. Daher generiert Liftoff Code, der den Rückgabewert, der in rcx gehalten wird, in das richtige Rückgaberegister rax verschiebt und dann aus der Funktion zurückkehrt.
Der Einfachheit halber enthält das obige Beispiel keine Blöcke (if, loop …) oder Verzweigungen. Blöcke in WebAssembly führen zu Kontrollzusammenführungen, da Code zu jedem übergeordneten Block verzweigen kann und if-Blöcke übersprungen werden können. Diese Zusammenführungspunkte können von unterschiedlichen Stack-Zuständen erreicht werden. Der darauf folgende Code muss jedoch einen spezifischen Stack-Zustand annehmen können, um Code zu generieren. Daher speichert Liftoff den aktuellen Zustand des virtuellen Stacks als den Zustand, der für den Code nach dem neuen Block angenommen wird (d. h. wenn man zum Kontroll-Level zurückkehrt, auf dem man sich derzeit befindet). Der neue Block wird dann mit dem aktuell aktiven Zustand fortgesetzt, wobei möglicherweise geändert wird, wo Stack-Werte oder lokale Variablen gespeichert werden: Einige könnten in den Stack ausgelagert oder in anderen Registern gehalten werden. Beim Verzweigen zu einem anderen Block oder beim Beenden eines Blocks (was dasselbe ist wie das Verzweigen zum übergeordneten Block) muss Liftoff Code generieren, der den aktuellen Zustand an den erwarteten Zustand an diesem Punkt anpasst, sodass der Code, der für das Ziel ausgegeben wird, die Werte dort findet, wo er sie erwartet. Die Validierung garantiert, dass die Höhe des aktuellen virtuellen Stacks der Höhe des erwarteten Zustands entspricht, sodass Liftoff nur Code generieren muss, um Werte zwischen Registern und/oder dem physischen Stack-Frame zu verschieben, wie unten gezeigt.
Schauen wir uns ein Beispiel dafür an.

Das obige Beispiel geht von einem virtuellen Stack mit zwei Werten auf dem Operand-Stack aus. Bevor der neue Block gestartet wird, wird der oberste Wert auf dem virtuellen Stack als Argument für die if-Anweisung entnommen. Der verbleibende Stack-Wert muss in ein anderes Register gelegt werden, da er derzeit den ersten Parameter überschattet, aber wenn man zu diesem Zustand zurückverzweigt, könnte man zwei verschiedene Werte für den Stack-Wert und den Parameter halten müssen. In diesem Fall entscheidet sich Liftoff dafür, ihn in das rcx-Register zu deduplizieren. Dieser Zustand wird dann gespeichert, und der aktive Zustand wird innerhalb des Blocks geändert. Am Ende des Blocks verzweigt man implizit zurück zum übergeordneten Block, sodass wir den aktuellen Zustand in den Snapshot zusammenführen, indem wir das Register rbx in das rcx-Register verschieben und das Register rdx aus dem Stack-Frame neu laden.
Upgrade von Liftoff zu TurboFan
Mit Liftoff und TurboFan hat V8 jetzt zwei Kompilierebenen für WebAssembly: Liftoff als Basiskompiler für schnellen Start und TurboFan als optimierenden Kompiler für maximale Leistung. Dies wirft die Frage auf, wie man die beiden Compiler kombinieren kann, um die beste Benutzererfahrung insgesamt zu bieten.
Für JavaScript verwendet V8 den Ignition-Interpreter und den TurboFan-Compiler und setzt eine dynamische Upgrade-Strategie ein. Jede Funktion wird zuerst in Ignition ausgeführt, und wenn die Funktion heiß wird, kompiliert TurboFan sie in hochoptimierten Maschinen-Code. Ein ähnlicher Ansatz könnte auch für Liftoff verwendet werden, aber die Abwägungen unterscheiden sich hier ein wenig:
- WebAssembly erfordert kein Typ-Feedback, um schnellen Code zu generieren. Während JavaScript stark davon profitiert, Typ-Feedback zu sammeln, ist WebAssembly statisch typisiert, sodass die Engine sofort optimierten Code generieren kann.
- WebAssembly-Code sollte vorhersehbar schnell laufen, ohne eine lange Aufwärmphase. Einer der Gründe, warum Anwendungen WebAssembly verwenden, ist die vorhersehbar hohe Leistung im Web. Daher können wir es uns weder leisten, längere Zeit suboptimale Codeausführung zu tolerieren, noch akzeptieren wir Pausen für die Kompilierung während der Ausführung.
- Ein wichtiges Entwurfsziel des Ignition-Interpreters für JavaScript ist es, den Speicherverbrauch zu reduzieren, indem Funktionen überhaupt nicht kompiliert werden. Wir haben jedoch festgestellt, dass ein Interpreter für WebAssembly viel zu langsam ist, um die vorhersehbar hohe Leistungsfähigkeit zu gewährleisten. Tatsächlich haben wir einen solchen Interpreter erstellt, aber da er 20× oder mehr langsamer als kompilierter Code ist, ist er nur für Debugging-Zwecke nützlich, unabhängig davon, wie viel Speicher er spart. Angesichts dessen muss die Engine den kompilierten Code dennoch speichern; letztendlich sollte nur der kompakteste und effizienteste Code gespeichert werden, nämlich der TurboFan-optimierte Code.
Aus diesen Einschränkungen haben wir geschlossen, dass dynamisches Tier-Up derzeit kein geeigneter Kompromiss für die Implementierung von WebAssembly in V8 ist, da es die Codegröße erhöhen und die Leistung für eine unbestimmte Zeitspanne reduzieren würde. Stattdessen haben wir uns für eine Strategie des eager Tier-Up entschieden. Unmittelbar nachdem die Liftoff-Kompilierung eines Moduls abgeschlossen ist, startet die WebAssembly-Engine Hintergrundthreads, um optimierten Code für das Modul zu generieren. Dies ermöglicht es V8, den Code schnell auszuführen (nach Abschluss von Liftoff), und dennoch den performantesten TurboFan-Code so früh wie möglich bereitzustellen.
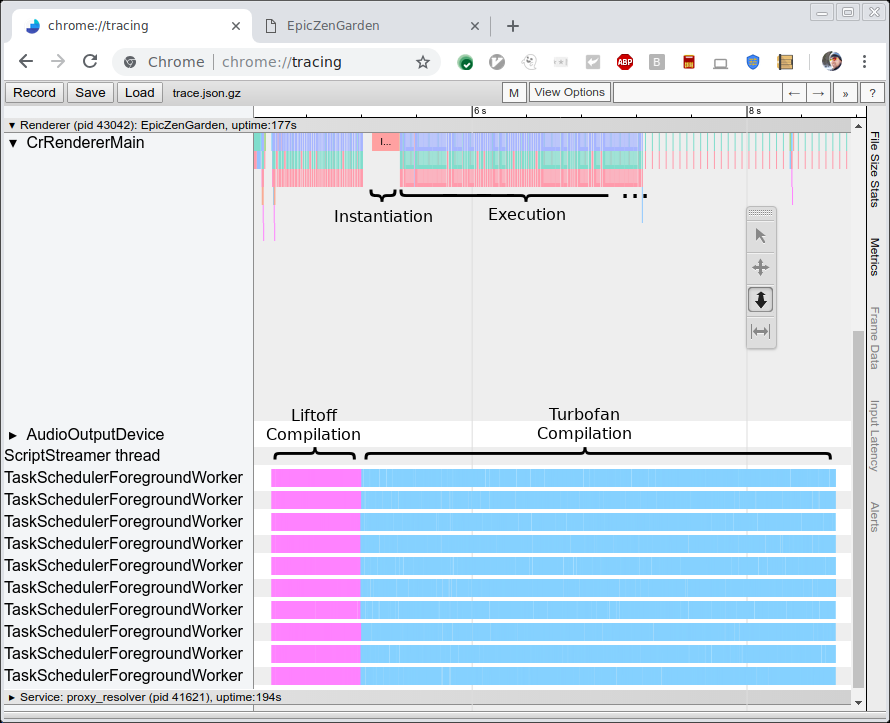
Das unten stehende Bild zeigt die Ablaufverfolgung der Kompilierung und Ausführung des EpicZenGarden-Benchmarks. Es zeigt, dass wir direkt nach der Liftoff-Kompilierung das WebAssembly-Modul instanziieren und ausführen können. Die TurboFan-Kompilierung dauert immer noch mehrere Sekunden, sodass während dieser Tier-Up-Periode die beobachtete Ausführungsleistung allmählich zunimmt, da einzelne TurboFan-Funktionen verwendet werden, sobald sie fertiggestellt sind.
Leistung
Zwei Kennzahlen sind interessant, um die Leistung des neuen Liftoff-Compilers zu bewerten. Erstens möchten wir die Kompilierungsgeschwindigkeit (d.h. Zeit zur Codeerzeugung) mit TurboFan vergleichen. Zweitens möchten wir die Leistung des generierten Codes (d.h. Ausführungsgeschwindigkeit) messen. Die erste Kennzahl ist hier interessanter, da es das Ziel von Liftoff ist, die Startzeit durch möglichst schnelle Codegenerierung zu reduzieren. Andererseits sollte die Leistung des generierten Codes immer noch ziemlich gut sein, da dieser Code möglicherweise mehrere Sekunden oder sogar Minuten auf leistungsschwacher Hardware ausgeführt wird.
Leistung der Codegenerierung
Um die Leistung des Compilers selbst zu messen, haben wir eine Reihe von Benchmarks ausgeführt und die reine Kompilierungszeit mithilfe von Tracing gemessen (siehe Bild oben). Wir führen beide Benchmarks auf einer HP Z840-Maschine (2 x Intel Xeon E5-2690 @2.6GHz, 24 Kerne, 48 Threads) und auf einem MacBook Pro (Intel Core i7-4980HQ @2.8GHz, 4 Kerne, 8 Threads) aus. Beachten Sie, dass Chrome derzeit nicht mehr als 10 Hintergrundthreads verwendet, sodass die meisten Kerne der Z840-Maschine ungenutzt bleiben.
Wir führen drei Benchmarks aus:
- EpicZenGarden: Die ZenGarden-Demo, die auf dem Epic-Framework läuft
- Tanks!: Eine Demo der Unity-Engine
- AutoDesk
- PSPDFKit
Für jeden Benchmark messen wir die reine Kompilierungszeit mithilfe der oben gezeigten Tracing-Ausgabe. Diese Zahl ist stabiler als jede von der Benchmark selbst gemeldete Zeit, da sie nicht davon abhängt, dass eine Aufgabe im Hauptthread geplant wird, und keine bezogene Arbeit wie das Erstellen der eigentlichen WebAssembly-Instanz einschließt.
Die untenstehenden Diagramme zeigen die Ergebnisse dieser Benchmarks. Jeder Benchmark wurde dreimal ausgeführt, und wir geben die durchschnittliche Kompilierungszeit an.


Wie erwartet generiert der Liftoff-Compiler sowohl auf der High-End-Desktop-Workstation als auch auf dem MacBook viel schneller Code. Der Geschwindigkeitsvorteil von Liftoff gegenüber TurboFan ist auf der weniger leistungsfähigen MacBook-Hardware sogar noch größer.
Leistung des generierten Codes
Auch wenn die Leistung des generierten Codes ein sekundäres Ziel ist, möchten wir das Benutzererlebnis in der Startphase mit hoher Leistung beibehalten, da Liftoff-Code möglicherweise mehrere Sekunden ausgeführt wird, bevor TurboFan-Code fertig ist.
Für die Messung der Liftoff-Codeleistung haben wir das Tier-Up deaktiviert, um reine Liftoff-Ausführungen zu messen. In diesem Setup führen wir zwei Benchmarks aus:
-
Unity headless Benchmarks
Dies ist eine Reihe von Benchmarks, die im Unity-Framework laufen. Sie sind headless und können daher direkt in der d8-Shell ausgeführt werden. Jeder Benchmark gibt einen Score aus, der nicht unbedingt proportional zur Ausführungsleistung ist, aber ausreicht, um die Leistung zu vergleichen.
-
Dieser Benchmark zeigt die Zeit an, die benötigt wird, um verschiedene Aktionen auf einem PDF-Dokument auszuführen, sowie die Zeit für die Initialisierung des WebAssembly-Moduls (einschließlich Kompilierung).
Wie zuvor führen wir jeden Benchmark dreimal aus und verwenden den Durchschnitt der drei Durchläufe. Da der Wertebereich der aufgezeichneten Zahlen zwischen den Benchmarks erheblich variiert, geben wir die relative Leistung von Liftoff im Vergleich zu TurboFan an. Ein Wert von +30% bedeutet, dass der Liftoff-Code 30% langsamer läuft als der TurboFan-Code. Negative Zahlen zeigen an, dass Liftoff schneller ausgeführt wird. Hier sind die Ergebnisse:

Auf Unity läuft der Liftoff-Code durchschnittlich etwa 50% langsamer als der TurboFan-Code auf dem Desktop-Rechner und 70% langsamer auf dem MacBook. Interessanterweise gibt es einen Fall (Mandelbrot-Skript), bei dem der Liftoff-Code den TurboFan-Code übertrifft. Dies ist wahrscheinlich ein Ausreißer, bei dem beispielsweise der Register-Allokator von TurboFan in einer heißen Schleife schlecht arbeitet. Wir untersuchen, ob TurboFan in diesem Fall verbessert werden kann.

Beim PSPDFKit-Benchmark läuft der Liftoff-Code 18-54% langsamer als der optimierte Code, während die Initialisierung wie erwartet deutlich verbessert wird. Diese Zahlen zeigen, dass bei realem Code, der auch über JavaScript-Aufrufe mit dem Browser interagiert, der Leistungsverlust von nicht optimiertem Code im Allgemeinen niedriger ist als bei rechnerintensiveren Benchmarks.
Und nochmals sei angemerkt, dass wir für diese Zahlen das Tier-Up komplett ausgeschaltet haben, sodass nur Liftoff-Code ausgeführt wurde. In Produktionskonfigurationen wird der Liftoff-Code nach und nach durch TurboFan-Code ersetzt, sodass die geringere Leistung von Liftoff-Code nur für einen kurzen Zeitraum anhält.
Zukünftige Arbeiten
Nach dem ersten Start von Liftoff arbeiten wir daran, die Startzeit weiter zu verbessern, den Speicherverbrauch zu reduzieren und die Vorteile von Liftoff mehr Benutzern zugänglich zu machen. Insbesondere arbeiten wir an der Verbesserung der folgenden Punkte:
- Liftoff auf ARM und ARM64 portieren, um es auch auf Mobilgeräten zu verwenden. Derzeit ist Liftoff nur für Intel-Plattformen (32 und 64 Bit) implementiert, was hauptsächlich Desktop-Anwendungsfälle abdeckt. Um auch mobile Nutzer zu erreichen, werden wir Liftoff auf weitere Architekturen portieren.
- Dynamisches Tier-Up für Mobilgeräte implementieren. Da Mobilgeräte tendenziell viel weniger Speicher haben als Desktopsysteme, müssen wir unsere Tiering-Strategie für diese Geräte anpassen. Einfach alle Funktionen mit TurboFan neu zu kompilieren, verdoppelt leicht den Speicherbedarf, um den gesamten Code zumindest vorübergehend zu halten (bis der Liftoff-Code verworfen wird). Stattdessen experimentieren wir mit einer Kombination aus Lazy-Kompilierung mit Liftoff und dynamischem Tier-Up von heißen Funktionen in TurboFan.
- Leistung der Liftoff-Code-Generierung verbessern. Die erste Iteration einer Implementierung ist selten die beste. Es gibt mehrere Dinge, die optimiert werden können, um die Kompilierungsgeschwindigkeit von Liftoff weiter zu erhöhen. Dies wird schrittweise in den nächsten Releases geschehen.
- Leistung des Liftoff-Codes verbessern. Abgesehen vom Compiler selbst können auch die Größe und Geschwindigkeit des generierten Codes verbessert werden. Auch dies wird schrittweise in den nächsten Releases erfolgen.
Fazit
V8 enthält jetzt Liftoff, einen neuen Basis-Compiler für WebAssembly. Liftoff reduziert die Startzeit von WebAssembly-Anwendungen erheblich mit einem einfachen und schnellen Code-Generator. Auf Desktopsystemen erreicht V8 immer noch die maximale Spitzenleistung, indem der gesamte Code im Hintergrund mit TurboFan neu kompiliert wird. Liftoff ist standardmäßig in V8 v6.9 (Chrome 69) aktiviert und kann explizit mit den Flags --liftoff/--no-liftoff und chrome://flags/#enable-webassembly-baseline gesteuert werden.