Beschleunigung von V8-Heap-Snapshots
Dieser Blog-Beitrag wurde von José Dapena Paz (Igalia) verfasst, mit Beiträgen von Jason Williams (Bloomberg), Ashley Claymore (Bloomberg), Rob Palmer (Bloomberg), Joyee Cheung (Igalia) und Shu-yu Guo (Google).
In diesem Beitrag über V8-Heap-Snapshots werde ich über einige von Bloomberg-Ingenieuren entdeckte Leistungsprobleme sprechen und wie wir diese gelöst haben, um die JavaScript-Speicheranalyse schneller als je zuvor zu machen.
Das Problem
Bloomberg-Ingenieure arbeiteten daran, ein Speicherleck in einer JavaScript-Anwendung zu diagnostizieren. Es trat mit Out-Of-Memory-Fehlern auf. Für die getestete Anwendung war das V8-Heap-Limit auf etwa 1400 MB konfiguriert. Normalerweise sollte der Garbage Collector von V8 in der Lage sein, die Heap-Nutzung unter diesem Limit zu halten, daher deuteten die Fehler darauf hin, dass es wahrscheinlich ein Leck gab.
Eine gängige Technik zur Debugging eines routinemäßigen Szenarios mit Speicherlecks wie diesem ist es, zuerst einen Heap-Snapshot zu erfassen, diesen dann im "Memory"-Reiter der DevTools zu laden und herauszufinden, was am meisten Speicher verbraucht, indem man die verschiedenen Zusammenfassungen und Objektattribute untersucht. Im UI der DevTools kann der Heap-Snapshot im "Memory"-Reiter aufgenommen werden. Für Node.js-Anwendungen kann der Heap-Snapshot programmgesteuert ausgelöst werden mit dieser API:
require('v8').writeHeapSnapshot();
Sie wollten mehrere Snapshots zu verschiedenen Zeitpunkten im Lebenszyklus der Anwendung erfassen, sodass der Memory-Viewer der DevTools verwendet werden konnte, um die Unterschiede zwischen den Heaps zu verschiedenen Zeiten anzuzeigen. Das Problem war jedoch, dass das Erfassen eines einzelnen vollständigen Snapshots (500 MB) über 30 Minuten dauerte!
Es war diese Langsamkeit im Workflow zur Speicheranalyse, die wir beheben mussten.
Eingrenzung des Problems
Dann begannen Bloomberg-Ingenieure, das Problem mithilfe einiger V8-Parameter zu untersuchen. Wie in diesem Beitrag beschrieben, haben Node.js und V8 einige praktische Befehlszeilen-Parameter, die dabei helfen können. Diese Optionen wurden genutzt, um die Heap-Snapshots zu erstellen, die Reproduktion zu vereinfachen und die Beobachtbarkeit zu verbessern:
--max-old-space-size=100: Dies begrenzt den Heap auf 100 Megabyte und hilft, das Problem viel schneller zu reproduzieren.--heapsnapshot-near-heap-limit=10: Dies ist ein spezifischer Node.js-Befehlszeilen-Parameter, der Node.js anweist, einen Snapshot zu erstellen, wenn der Speicher kurz davor steht, erschöpft zu werden. Es ist konfiguriert, bis zu 10 Snapshots insgesamt zu erstellen. Dies verhindert ein „Thrashing“, bei dem das speicherarme Programm viel Zeit damit verbringt, mehr Snapshots als nötig zu erzeugen.--enable-etw-stack-walking: Ermöglicht Tools wie ETW, WPA und xperf, den JS-Stack zu sehen, der in V8 aufgerufen wurde. (verfügbar in Node.js v20+)--interpreted-frames-native-stack: Dieses Flag wird in Kombination mit Tools wie ETW, WPA und xperf verwendet, um den nativen Stack beim Profilieren zu sehen. (verfügbar in Node.js v20+).
Wenn die Größe des V8-Heaps das Limit erreicht, erzwingt V8 eine Garbage Collection, um die Speichernutzung zu reduzieren. Es benachrichtigt auch den Embedder darüber. Das --heapsnapshot-near-heap-limit-Flag in Node.js erstellt bei Benachrichtigung einen neuen Heap-Snapshot. Im Testfall sinkt die Speichernutzung, aber nach mehreren Iterationen kann die Garbage Collection letztlich nicht genügend Speicherplatz freimachen, sodass die Anwendung mit einem Out-Of-Memory-Fehler beendet wird.
Sie machten Aufzeichnungen mit dem Windows Performance Analyzer (siehe unten), um das Problem einzugrenzen. Dies zeigte, dass die meiste CPU-Zeit im V8 Heap Explorer aufgewendet wurde. Insbesondere dauerte es etwa 30 Minuten, nur um den Heap zu durchlaufen, jeden Knoten zu besuchen und den Namen zu sammeln. Das schien nicht viel Sinn zu machen – warum sollte das Aufzeichnen des Namens jeder Eigenschaft so lange dauern?
Zu diesem Zeitpunkt wurde ich gebeten, mir das Problem anzusehen.
Quantifizieren des Problems
Der erste Schritt war die Unterstützung in V8 hinzuzufügen, um besser zu verstehen, wo die Zeit während der Erfassung von Heap-Snapshots aufgewendet wird. Der Erfassungsprozess selbst ist in zwei Phasen unterteilt: Generierung und Serialisierung. Wir haben diesen Patch upstream aufgenommen, um ein neues Befehlszeilenflag --profile_heap_snapshot in V8 einzuführen, das die Protokollierung der Zeiten für die Generierung und Serialisierung aktiviert.
Mit diesem Flag haben wir einige interessante Dinge gelernt!
Zunächst konnten wir die genaue Zeit beobachten, die V8 mit der Erstellung jedes Snapshots verbrachte. In unserem reduzierten Testfall dauerte der erste Snapshot 5 Minuten, der zweite 8 Minuten und jeder nachfolgende Snapshot benötigte immer mehr Zeit. Fast die gesamte Zeit wurde für die Erstellungsphase aufgewendet.
Dies ermöglichte uns auch, die mit der Snapshot-Erstellung verbrachte Zeit mit einem trivialen Overhead zu quantifizieren, was uns half, ähnliche Verlangsamungen in anderen weit verbreiteten JavaScript-Anwendungen zu isolieren und zu identifizieren – insbesondere ESLint auf TypeScript. So wussten wir, dass das Problem nicht spezifisch für eine Anwendung war.
Darüber hinaus stellten wir fest, dass das Problem sowohl unter Windows als auch unter Linux auftrat. Das Problem war also auch nicht plattformspezifisch.
Erste Optimierung: Verbesserte StringsStorage-Hashing
Um herauszufinden, was die übermäßige Verzögerung verursachte, profilierte ich das fehlerhafte Skript mit dem Windows Performance Toolkit.
Als ich die Aufzeichnung mit dem Windows Performance Analyzer öffnete, fand ich Folgendes:
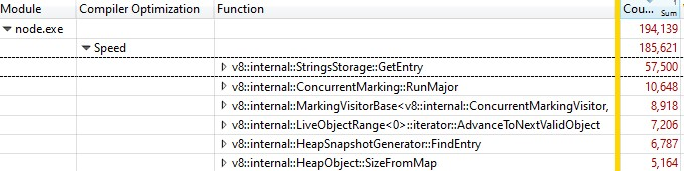
Ein Drittel der Samples wurde in v8::internal::StringsStorage::GetEntry verbracht:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
Da dies mit einem Release-Build ausgeführt wurde, wurden die Informationen zu den eingebetteten Funktionsaufrufen in StringsStorage::GetEntry() zusammengefasst. Um genau herauszufinden, wie viel Zeit die eingebetteten Funktionsaufrufe beanspruchten, fügte ich der Aufschlüsselung die Spalte „Source Line Number“ hinzu und stellte fest, dass die meiste Zeit auf Zeile 182 verbracht wurde, die einen Aufruf von ComputeStringHash() enthielt:
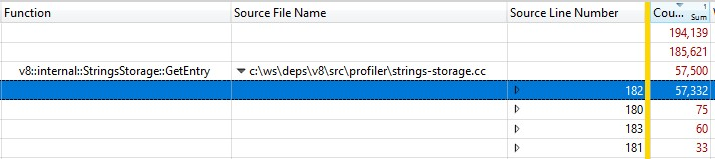
Über 30 % der Zeit für die Snapshot-Erstellung wurden in ComputeStringHash() verbracht, aber warum?
Sprechen wir zunächst über StringsStorage. Es dient dazu, eine einzigartige Kopie aller Strings zu speichern, die im Heap-Snapshot verwendet werden. Für schnellen Zugriff und zur Vermeidung von Duplikaten verwendet diese Klasse eine Hashmap, die durch ein Array gestützt wird, wobei Kollisionen durch Speichern von Elementen an der nächsten freien Position im Array behandelt werden.
Ich begann zu vermuten, dass das Problem durch Kollisionen verursacht werden könnte, die zu langen Suchvorgängen im Array führen könnten. Daher fügte ich umfassende Logs hinzu, um die generierten Hash-Schlüssel zu sehen und bei der Einfügung zu sehen, wie weit die tatsächliche Position des Eintrags von der berechneten Position des Hash-Schlüssels aufgrund von Kollisionen entfernt war.
In den Logs war etwas nicht in Ordnung: Der Offset vieler Elemente lag über 20 und im schlimmsten Fall sogar im Bereich von Tausenden!
Ein Teil des Problems wurde durch numerische Strings verursacht – insbesondere Strings für eine breite Reihe aufeinanderfolgender Zahlen. Der Hash-Schlüssel-Algorithmus hatte zwei Implementierungen, eine für numerische Strings und eine andere für andere Strings. Während die String-Hash-Funktion recht klassisch war, würde die Implementierung für numerische Strings im Wesentlichen den Wert der Zahl zurückgeben, der durch die Anzahl der Ziffern vorangestellt wurde:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
Diese Funktion war problematisch. Ein paar Beispiele für Probleme mit dieser Hash-Funktion:
- Sobald wir einen String einfügten, dessen Hash-Schlüsselwert eine kleine Zahl war, stießen wir auf Kollisionen, wenn wir versuchten, eine andere Zahl an dieser Position zu speichern. Ähnliche Kollisionen traten auch auf, wenn wir versuchten, aufeinanderfolgende Zahlen nacheinander zu speichern.
- Noch schlimmer: Wenn bereits viele aufeinanderfolgende Zahlen in der Map gespeichert waren und wir versuchten, einen String zu speichern, dessen Hash-Schlüsselwert in diesem Bereich lag, mussten wir den Eintrag entlang aller belegten Positionen bewegen, um eine freie Position zu finden.
Was habe ich getan, um dies zu beheben? Da das Problem hauptsächlich durch Zahlen verursacht wird, die als Strings dargestellt werden und in aufeinanderfolgende Positionen fallen, habe ich die Hash-Funktion so modifiziert, dass der resultierende Hash-Wert um 2 Bits nach links rotiert wird.
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
Für jedes Paar aufeinanderfolgender Zahlen würden wir 3 freie Positionen dazwischen einführen. Diese Modifikation wurde ausgewählt, weil empirische Tests mit mehreren Arbeitssätzen zeigten, dass sie am besten geeignet war, um Kollisionen zu minimieren.
Dieser Hashing-Fix wurde in V8 integriert.
Zweite Optimierung: Caching von Quellpositionen
Nach der Behebung des Hashing-Problems haben wir das Profil erneut betrachtet und eine weitere Optimierungsmöglichkeit gefunden, die einen erheblichen Teil des Overheads reduzieren würde.
Beim Erstellen eines Heap-Snapshots versucht V8 für jede Funktion im Heap, deren Startposition in Form eines Paars aus Zeilen- und Spaltennummern aufzuzeichnen. Diese Informationen können von den DevTools verwendet werden, um einen Link zum Quellcode der Funktion anzuzeigen. Während der üblichen Kompilierung speichert V8 jedoch nur die Startposition jeder Funktion als linearen Offset vom Beginn des Skripts. Um die Zeilen- und Spaltennummern basierend auf dem linearen Offset zu berechnen, muss V8 das gesamte Skript durchlaufen und dort die Zeilenumbrüche aufzeichnen. Diese Berechnung erweist sich als sehr teuer.
Normalerweise, nachdem V8 die Offsets der Zeilenumbrüche in einem Skript berechnet hat, speichert es diese in einem neu zugewiesenen Array, das dem Skript zugeordnet ist. Leider kann die Snapshot-Implementierung den Heap beim Durchlaufen nicht verändern, sodass die neu berechneten Zeileninformationen nicht zwischengespeichert werden können.
Die Lösung? Vor der Erstellung des Heap-Snapshots durchlaufen wir jetzt alle Skripte im V8-Kontext, um die Offsets der Zeilenumbrüche zu berechnen und zu speichern. Da dies nicht geschieht, wenn wir den Heap für die Erstellung des Heap-Snapshots durchlaufen, ist es dennoch möglich, den Heap zu verändern und die Startpositionen der Quellzeilen als Cache abzulegen.
Der Fix für das Caching der Zeilenumbruch-Offsets wurde ebenfalls in V8 integriert.
Haben wir es schnell gemacht?
Nachdem beide Fixes aktiviert wurden, haben wir das Profil erneut betrachtet. Beide unserer Fixes wirken sich nur auf die Snapshot-Erstellungszeit aus, sodass die Zeit für die Snapshot-Serialisierung erwartungsgemäß nicht beeinflusst wurde.
Beim Arbeiten mit einem JS-Programm, das…
- Entwicklungs-JS enthält, ist die Erstellungszeit 50 % schneller 👍
- Produktions-JS enthält, ist die Erstellungszeit 90 % schneller 😮
Warum gab es einen drastischen Unterschied zwischen Produktions- und Entwicklungs-Code? Der Produktions-Code wird durch Bündelung und Minifizierung optimiert, sodass es weniger JS-Dateien gibt und diese Dateien tendenziell groß sind. Es dauert länger, die Positionen der Quellzeilen für diese großen Dateien zu berechnen, daher profitieren sie am meisten davon, wenn wir die Quellpositionen zwischenspeichern und die Berechnungen nicht wiederholen müssen.
Die Optimierungen wurden sowohl in Windows- als auch in Linux-Zielumgebungen validiert.
Für das ursprünglich besonders herausfordernde Problem, das die Ingenieure von Bloomberg hatten, wurde die Gesamtdurchlaufzeit zur Erfassung eines 100-MB-Snapshots von schmerzhaften 10 Minuten auf sehr angenehme 6 Sekunden reduziert. Das entspricht einem 100-fachen Gewinn! 🔥
Die Optimierungen sind generische Gewinne, die unserer Ansicht nach weitreichend anwendbar sind für jeden, der Speicher-Debugging mit V8, Node.js und Chromium durchführt. Diese Verbesserungen wurden in V8 v11.5.130 eingeführt, was bedeutet, dass sie in Chromium 115.0.5576.0 zu finden sind. Wir freuen uns darauf, dass Node.js diese Optimierungen in der nächsten semver-major-Version übernimmt.
Was steht als Nächstes an?
Zunächst wäre es sinnvoll, wenn Node.js die neue --profile-heap-snapshot-Flag in NODE_OPTIONS akzeptiert. In einigen Anwendungsfällen können Benutzer die Kommandozeilenoptionen, die direkt an Node.js übergeben werden, nicht kontrollieren und müssen sie über die Umgebungsvariable NODE_OPTIONS konfigurieren. Heute filtert Node.js die in der Umgebungsvariable eingestellten V8-Kommandozeilenoptionen und erlaubt nur eine bekannte Teilmenge, was es schwieriger machen könnte, neue V8-Flags in Node.js zu testen, wie es in unserem Fall passiert ist.
Die Genauigkeit der Informationen in Snapshots kann weiter verbessert werden. Heute werden die Quellcode-Zeileninformationen jedes Skripts in einer Darstellung direkt im V8-Heap gespeichert. Und das ist ein Problem, weil wir den Heap präzise messen möchten, ohne dass der Leistungsüberwachungsoverhead das zu beobachtende Subjekt beeinflusst. Idealerweise würden wir den Cache der Zeileninformationen außerhalb des V8-Heaps speichern, um die Informationen des Heap-Snapshots genauer zu machen.
Schließlich, jetzt, da wir die Generierungsphase verbessert haben, sind die größten Kosten nun in der Serialisierungsphase. Weitere Analysen könnten neue Optimierungsmöglichkeiten in der Serialisierung aufdecken.
Credits
Dies war möglich dank der Arbeit der Ingenieure von Igalia und Bloomberg.