Orinoco: Müllentsorgung jüngerer Generation
JavaScript-Objekte in V8 werden auf einem Heap gespeichert, der vom Müllsammler von V8 verwaltet wird. In früheren Blogposts haben wir bereits darüber gesprochen, wie wir die Pausenzeiten der Müllsammlung reduzieren (mehr als einmal) und den Speicherverbrauch verringern. In diesem Blogbeitrag stellen wir den parallelen Scavenger vor, eine der neuesten Funktionen von Orinoco, V8s überwiegend nebenläufigem und parallel arbeitendem Müllsammler, und diskutieren Designentscheidungen sowie alternative Ansätze, die wir auf dem Weg implementiert haben.
V8 unterteilt seinen verwalteten Heap in Generationen, wobei Objekte zunächst im „Kindergarten“ der jungen Generation gespeichert werden. Wenn ein Objekt eine Müllsammlung überlebt, wird es in die Zwischen-Generation kopiert, die immer noch Teil der jungen Generation ist. Nach dem Überleben einer weiteren Müllsammlung werden diese Objekte in die alte Generation verschoben (siehe Abbildung 1). V8 implementiert zwei Müllsammler: einen, der häufig die junge Generation sammelt, und einen, der den gesamten Heap einschließlich der jungen und alten Generationen sammelt. Verweise von der alten zur jungen Generation sind Wurzeln für die Müllentsorgung der jungen Generation. Diese Verweise werden aufgezeichnet, um eine effiziente Wurzelidentifikation und Verweisaktualisierung zu ermöglichen, wenn Objekte verschoben werden.

Da die junge Generation relativ klein ist (bis zu 16MiB in V8), füllt sie sich schnell mit Objekten und erfordert häufige Sammlungen. Bis Version M62 verwendete V8 einen Cheney-Semispace-Kopier-Müllsammler (siehe unten), der die junge Generation in zwei Hälften teilt. Während der JavaScript-Ausführung steht nur eine Hälfte der jungen Generation zur Verfügung, um Objekte zu speichern, während die andere Hälfte leer bleibt. Während einer jungen Müllsammlung werden lebende Objekte von einer Hälfte in die andere Hälfte kopiert und dabei der Speicher kompakt gehalten. Bereits einmal kopierte lebende Objekte werden als Teil der Zwischen-Generation betrachtet und in die alte Generation befördert.
Ab Version v6.2 hat V8 den Standardalgorithmus für die Sammlung der jungen Generation auf einen parallelen Scavenger umgestellt, ähnlich wie Halsteads Semispace-Kopier-Müllsammler, mit dem Unterschied, dass V8 dynamisches statt statisches Work-Stealing über mehrere Threads verwendet. Im Folgenden erläutern wir drei Algorithmen: a) den Single-Threaded Cheney-Semispace-Kopier-Müllsammler, b) ein paralleles Mark-Evacuate-Verfahren und c) den parallelen Scavenger.
Single-Threaded Cheney’s Semispace Copy
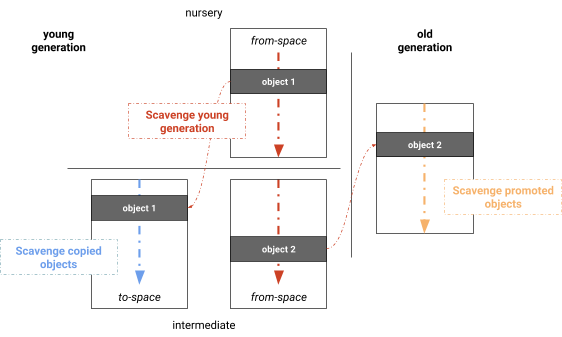
Bis Version v6.2 verwendete V8 Cheney’s Semispace-Kopier-Algorithmus, der sowohl für Single-Core-Ausführung als auch für ein Generationsschema gut geeignet ist. Vor einer Sammlung der jungen Generation werden beide Semispace-Hälften des Speichers zugewiesen und ordnungsgemäß beschriftet: Die Seiten, die die aktuelle Menge an Objekten enthalten, werden from-space genannt, während die Seiten, zu denen Objekte kopiert werden, to-space genannt werden.
Der Scavenger betrachtet Verweise im Aufrufstack und Verweise von der alten zur jungen Generation als Wurzeln. Abbildung 2 veranschaulicht den Algorithmus, bei dem der Scavenger zunächst diese Wurzeln scannt und erreichbare Objekte im from-space kopiert, die noch nicht in den to-space kopiert wurden. Objekte, die bereits eine Müllsammlung überlebt haben, werden in die alte Generation befördert (verschoben). Nach dem Wurzelscannen und der ersten Runde des Kopierens werden die Objekte im neu zugewiesenen to-space auf Verweise untersucht. Ähnlich werden alle beförderten Objekte auf neue Verweise zu from-space untersucht. Diese drei Phasen werden auf dem Haupt-Thread ineinander verschachtelt. Der Algorithmus wird fortgesetzt, bis keine neuen Objekte mehr entweder aus to-space oder der alten Generation erreichbar sind. Zu diesem Zeitpunkt enthält from-space nur noch unerreichbare Objekte, d.h. nur noch Müll.
![]()
Paralleles Mark-Evacuate
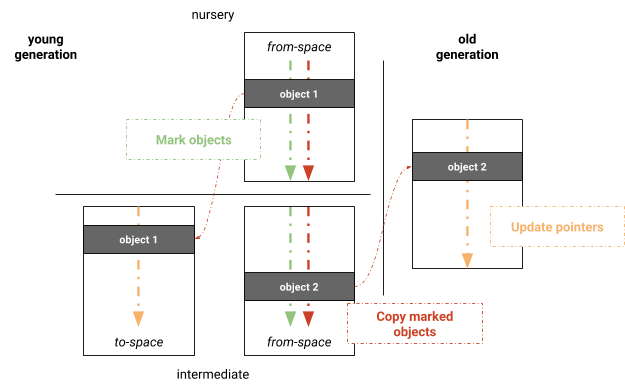
Wir experimentierten mit einem parallelen Mark-Evacuate-Algorithmus basierend auf dem vollständigen Mark-Sweep-Compact-Sammler von V8. Der Hauptvorteil liegt darin, die bereits vorhandene Müllsammel-Infrastruktur des vollständigen Mark-Sweep-Compact-Sammlers zu nutzen. Der Algorithmus besteht aus drei Phasen: Markieren, Kopieren und Aktualisieren der Zeiger, wie in Abbildung 3 gezeigt. Um zu vermeiden, dass Seiten in der jungen Generation gesäubert werden, um Freiliste zu erhalten, wird die junge Generation weiterhin mit einem Semispace verwaltet, das durch das Kopieren von lebenden Objekten in den to-space während der Müllsammlung immer kompakt gehalten wird. Die junge Generation wird zunächst parallel markiert. Nach dem Markieren werden die lebenden Objekte parallel in ihre entsprechenden Räume kopiert. Die Arbeit wird basierend auf logischen Seiten verteilt. Threads, die am Kopieren teilnehmen, behalten ihre eigenen lokalen Zuweisungspuffer (LABs), die nach Abschluss des Kopiervorgangs zusammengeführt werden. Nach dem Kopieren wird das gleiche Parallelisierungsschema für die Aktualisierung der interobjektspezifischen Zeiger angewendet. Diese drei Phasen werden im Gleichschritt ausgeführt, d.h., während die Phasen selbst parallel ausgeführt werden, müssen Threads synchronisiert werden, bevor sie zur nächsten Phase übergehen.

Parallel Scavenge
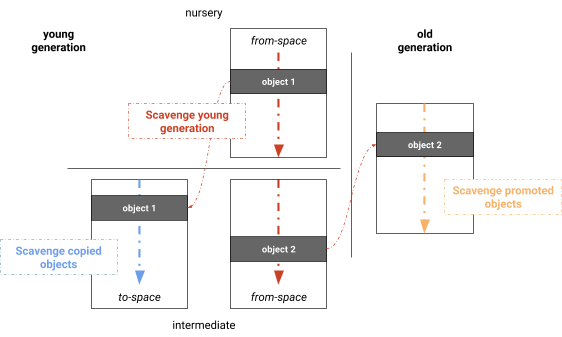
Der parallele Mark-Evacuate-Sammler trennt die Phasen der Lebendheitsberechnung, des Kopierens lebender Objekte und der Aktualisierung von Zeigern. Eine offensichtliche Optimierung besteht darin, diese Phasen zu kombinieren, was zu einem Algorithmus führt, der Markierung, Kopieren und Aktualisierung von Zeigern gleichzeitig durchführt. Durch das Zusammenführen dieser Phasen erhalten wir tatsächlich den parallelen Scavenger, der von V8 verwendet wird, eine Version ähnlich dem Halstead’s Semispace-Sammler, mit dem Unterschied, dass V8 dynamisches Work-Stealing und einen einfachen Lastenausgleichsmechanismus für das Scannen der Wurzeln verwendet (siehe Abbildung 4). Wie der auf Einzel-Thread-synchronisierte Cheney-Algorithmus, bestehen die Phasen aus: Scannen der Wurzeln, Kopieren innerhalb der jungen Generation, Förderung in die alte Generation und Aktualisierung von Zeigern. Wir stellten fest, dass die Mehrheit des Wurzelsatzes in der Regel die Referenzen von der alten Generation zur jungen Generation sind. In unserer Implementierung werden Erinnerungssets pro Seite aufrechterhalten, was den Wurzelsatz unter den Müllsammel-Threads auf natürliche Weise verteilt. Objekte werden dann parallel verarbeitet. Neu aufgefundene Objekte werden einer globalen Arbeitsliste hinzugefügt, von der Müllsammel-Threads stehlen können. Diese Arbeitsliste bietet schnellen, task-lokalen Speicher sowie globalen Speicher zum Teilen von Arbeit. Eine Schranke stellt sicher, dass Tasks nicht vorzeitig beendet werden, wenn der gerade verarbeitete Subgraph nicht für Work-Stealing geeignet ist (z. B. eine lineare Kette von Objekten). Alle Phasen werden parallel und innerhalb jedes Tasks ineinandergreifend ausgeführt, wodurch die Auslastung der Worker-Tasks maximiert wird.

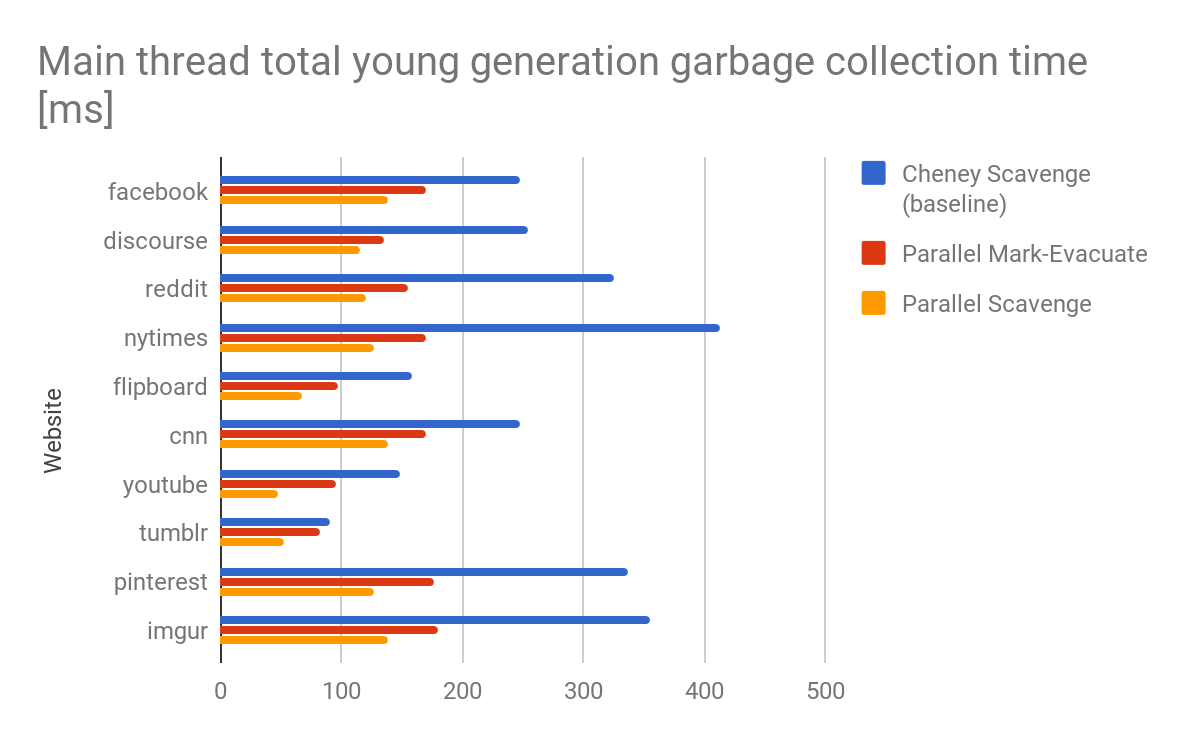
Ergebnisse und Resultate
Der Scavenger-Algorithmus wurde ursprünglich mit optimaler Einzelkernleistung entwickelt. Seitdem hat sich die Welt verändert. CPU-Kerne sind oft reichlich vorhanden, selbst auf Low-End-Mobilgeräten. Wichtiger ist, dass diese Kerne oftmals tatsächlich aktiv sind und laufen. Um diese Kerne voll auszuschöpfen, musste eine der letzten sequentiellen Komponenten des Müllsammlers von V8, der Scavenger, modernisiert werden.
Der große Vorteil eines parallelen Mark-Evacuate-Sammlers ist, dass genaue Lebendheitsinformationen verfügbar sind. Diese Informationen können z.B. dazu verwendet werden, das Kopieren komplett zu vermeiden, indem Seiten, die hauptsächlich lebende Objekte enthalten, einfach verschoben und erneut verknüpft werden, was auch vom vollständigen Mark-Sweep-Compact-Sammler durchgeführt wird. In der Praxis war dies jedoch hauptsächlich bei synthetischen Benchmarks beobachtbar und kaum auf echten Websites zu sehen. Der Nachteil des parallelen Mark-Evacuate-Sammlers ist der Aufwand, drei separate Phasen im Gleichschritt durchzuführen. Dieser Aufwand ist besonders spürbar, wenn der Müllsammler auf einen Heap mit größtenteils toten Objekten angewendet wird, was bei vielen realen Webseiten der Fall ist. Beachten Sie, dass das Aufrufen von Müllsammlungen auf Heaps mit größtenteils toten Objekten eigentlich das ideale Szenario ist, da die Müllsammlung normalerweise durch die Größe der lebenden Objekte begrenzt ist.
Der parallele Scavenger schließt diese Leistungslücke, indem er eine Leistung bietet, die nahe am optimierten Cheney-Algorithmus bei kleinen oder fast leeren Heaps liegt, während er gleichzeitig eine hohe Durchsatzleistung liefert, falls die Heaps größer werden und viele lebende Objekte enthalten.
V8 unterstützt, neben vielen anderen Plattformen, auch Arm big.LITTLE. Während das Auslagern von Arbeit auf kleine Kerne der Akkulaufzeit zugute kommt, kann dies zu Verzögerungen im Haupt-Thread führen, wenn Arbeitspakete für kleine Kerne zu groß sind. Wir stellten fest, dass Seitenebene-Parallelität nicht zwangsläufig die Arbeit auf big.LITTLE für eine Müllsammlung der jungen Generation ausgleicht, aufgrund der begrenzten Anzahl von Seiten. Der Scavenger löst dieses Problem von Natur aus durch mittelgrobe Synchronisation unter Verwendung expliziter Arbeitslisten und Work-Stealing.