陸地在望:告別節點之海
V8 的終極優化編譯器 Turbofan,是少數採用節點之海 (Sea of Nodes, SoN)的大規模生產編譯器之一。然而,自從大約三年前,我們開始逐步淘汰節點之海,轉而使用更傳統的控制流圖 (CFG) 中間表示 (IR),我們將其命名為 Turboshaft。目前為止,Turbofan 的整個 JavaScript 後端已完全採用了 Turboshaft,而 WebAssembly 在其整個管線中也完全使用了 Turboshaft。Turbofan 的兩個部分仍然使用一些節點之海:內建管線(我們正在逐步用 Turboshaft 替代)以及 JavaScript 管線的前端(我們正用另一個基於 CFG 的 IR,名為 Maglev 替代)。這篇博文將解釋我們放棄節點之海的原因。
12 年前,也就是 2013 年,V8 只有一個優化編譯器:Crankshaft。它使用基於控制流圖的中間表示。Crankshaft 的最初版本提供了顯著的性能提升,儘管在支持的功能上仍有很多限制。在接下來的幾年裡,團隊持續改進它,能在越來越多的情況下生成更快的代碼。然而,技術債逐漸開始堆積,並且 Crankshaft 出現了許多問題:
-
它包含了太多手工編寫的組合語代碼。每次向 IR 添加新的操作符時,其對應的組合語翻譯必須針對 V8 官方支持的四種架構(x64、ia32、arm、arm64)手動編寫。
-
它在優化asm.js方面表現不佳,而當時 asm.js 被認為是實現高性能 JavaScript 的一個重要步驟。
-
它無法在降級過程中引入控制流。換句話說,控制流在圖構建時就已確定,之後無法更改。這是一個主要的限制,因為編寫編譯器時的常見做法是先使用高級操作,然後將其降級為低級操作,通常會引入額外的控制流。例如對於高級操作
JSAdd(x,y),可能需要降級為類似於if (x is String and y is String) { StringAdd(x, y) } else { … }這樣的低級控制流。但在 Crankshaft 中,這是不可能的。 -
它不支持 try-catch,並且支持 try-catch 的工作非常具有挑戰性:多名工程師花費了數月時間嘗試支持它,但未能成功。
-
它存在許多性能問題和回退。使用某些特定功能或指令,或者遇到某些特定邊界情況的特性,可能導致性能下降 100 倍。這使得 JavaScript 開發者難以編寫效率高的代碼,並無法預測其應用的性能表現。
-
它包含許多 去優化循環:Crankshaft 會基於一些投機假設來優化函數,當那些假設不成立時,函數會被去優化,但太多時候,Crankshaft 會以相同的假設重新優化該函數,導致無休止的優化-去優化循環。
單獨看,每個問題或許都能解決。然而,將這些問題結合在一起,就似乎難以克服。因此,團隊決定用一個全新從頭開始編寫的編譯器來替代 Crankshaft:Turbofan。並且,與其使用傳統的 CFG IR,Turbofan 選擇使用一種被認為更強大的 IR:節點之海。當時,這種 IR 已在 Java HotSpot 虛擬機的 JIT 編譯器 C2 中使用了超過 10 年。
那麼,究竟什麼是節點之海?
首先,讓我們簡單回顧一下控制流圖(CFG):CFG 是一種用圖表示程序的方式,其中圖的節點代表程序的基本塊(即沒有入口或出口分支或跳轉的一連串指令),邊則表示程序的控制流。以下是一個簡單的例子:

基本區塊內的指令是隱式排序的:第一個指令應該在第二個指令之前執行,第二個指令應該在第三個指令之前執行,等等。在上述的小例子中,這感覺非常自然:v1 == 0 無法在 x % 2 被計算之前計算。但請考慮以下情況

在這裡,CFG 似乎要求 a * 2 在 b * 2 之前被計算,儘管我們完全可以倒過來計算它們。
這就是 Sea of Nodes 的作用所在:Sea of Nodes 不表示基本區塊,而僅表示指令之間的真正依賴關係。Sea of Nodes 中的節點是單一指令(而不是基本區塊),邊表示值的使用(意味著:從 a 到 b 的邊表示 a 使用了 b)。因此,下面是這個最後例子如何用 Sea of Nodes 表示的方式:

最終,編譯器需要生成匯編並依次安排這兩次乘法,但在此之前,它們之間已經沒有更多依賴。
現在讓我們把控制流加入混合。控制節點(例如 branch、goto、return)通常沒有彼此之間的值依賴,這會強制某個特定的順序,即使它們確實需要按特定順序排列。因此,為了表示控制流,我們需要一種新的邊類型,控制邊,它在沒有值依賴的節點上強制某些順序:

在這個例子中,如果沒有控制邊,就沒有東西能阻止 return 在 branch 之前被執行,這顯然是錯誤的。
這裡關鍵的是,控制邊僅在那些有如此輸入或輸出邊的操作上強制執行順序,而不是其他操作,例如算術操作。這是 Sea of Nodes 和控制流圖之間的主要區別。
現在讓我們把有效操作(例如,從內存中讀取和寫入)加入混合。與控制節點類似,有效操作通常沒有值依賴,但仍然不能以隨機順序執行。例如,a[0] += 42; x = a[0] 和 x = a[0]; a[0] += 42 是不等價的。因此,我們需要一種方式對有效操作強加順序(=安排)。我們可以重用控制鏈來達到這個目的,但這樣做會比所需的更嚴格。例如,考慮以下小代碼片段:
let v = a[2];
if (c) {
return v;
}
通過將 a[2](讀取內存)放在控制鏈上,我們會強制它在 c 的分支之前發生,即使實際上,如果它的結果僅在 then-分支的內部使用,這種加載可以輕鬆地發生在分支之後。在程序中對控制鏈上的許多節點進行操作,將會顛覆 Sea of Nodes 的目標,因為我們基本上只會得到一個 CFG 類似的 IR,其中只有純操作在其中漂浮。
所以,為了提供更多自由並真正受益於 Sea of Nodes,Turbofan 有另一種邊類型,效果邊,它對有副作用的節點施加了一些順序限制。現在讓我們忽略控制流,來看一個小例子:

在這個例子中,arr[0] = 42 和 let x = arr[a] 沒有值依賴(即,前者不是後者的輸入,反之亦然)。然而,由於 a 可能是 0,arr[0] = 42 應該在 x = arr[a] 之前執行,以使後者始終從數組中加載正確的值。
注意,儘管 Turbofan 有一個單一的效果鏈(在分支時分裂,當控制流合併時重新合併),用於所有有效操作,但有可能有多個效果鏈,其中沒有依賴的操作可以位於不同的效果鏈上,從而放鬆它們可以如何安排(請參閱SeaOfNodes/Simple 的第 10 章了解更多細節)。然而,正如我們稍後解釋的那樣,維持一個單一的效果鏈已經非常容易出錯,因此我們在 Turbofan 中並未嘗試擁有多個效果鏈。
當然,大多數真實的程序將同時包含控制流和有效操作。

注意,store 和 load 需要控制輸入,因為它們可能受到各種檢查(例如類型檢查或邊界檢查)的保護。
此範例很好地展示了 Sea of Nodes 相較於 CFG 的強大功能:y = x * c 僅在 else 分支中使用,因此可以自由漂移到 branch 之後,而不是按照原始 JavaScript 代碼中寫的那樣在之前計算。同樣,arr[0] 也僅在 else 分支中使用,因此可能也會在 branch 之後漂移(儘管在實際操作中,Turbofan 不會向下移動 arr[0],原因稍後會解釋)。
為了比較,以下是對應的 CFG 的樣子:

顯然,我們開始看到 SoN 的主要問題:它與編譯器的輸入(源代碼)和輸出(組合語言)相比距離更加遙遠,這使其理解起來更不直觀。此外,始終明確顯示效果和控制依賴使得快速推理圖形以及編寫降級變得困難(因為降級必須始終顯式維護控制和效果鏈,而這在 CFG 中是隱式的)。
問題開始出現…
經過超過十年的 Sea of Nodes 使用經驗,我們認為它的缺點超過了優勢,至少對於 JavaScript 和 WebAssembly 而言是如此。我們將在下面詳述其中的一些問題。
手動/視覺檢查和理解 Sea of Nodes 圖形很困難
我們已經看到,在小程序中 CFG 更易於閱讀,因為它更接近原始源代碼,而這是開發人員(包括編譯器工程師\!)習慣於編寫的代碼。對於尚未被說服的讀者,讓我提供一個稍大的示例,以便您更好地理解問題所在。請考慮以下的 JavaScript 函數,它連接一個字符串數組:
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
以下是對應的 Sea of Nodes 圖形,此時圖形處於 Turbofan 編譯管道的中間階段(這意味著已經進行了一些降級):
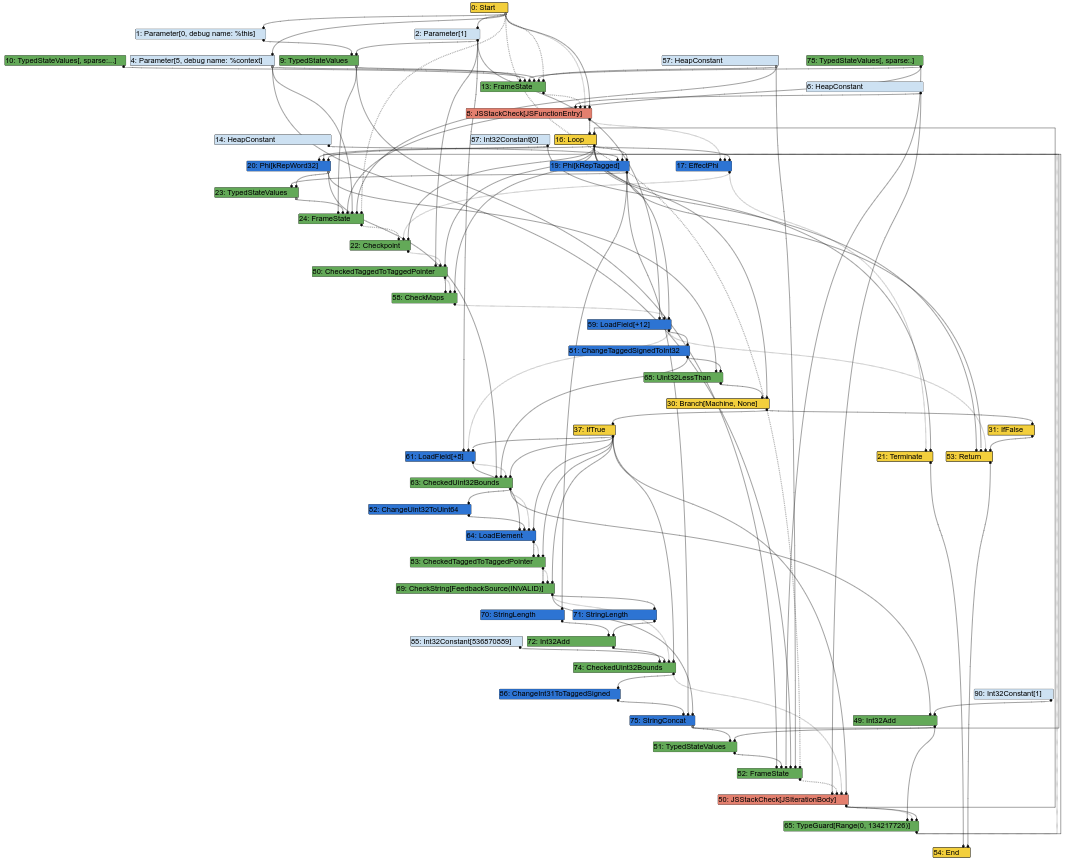
顯然,這開始看起來像是一鍋混亂的節點。作為編譯器工程師,我的重要工作之一是查看 Turbofan 圖形,以便理解 bug,或尋找優化的機會。然而,當圖形像這樣時,很難去分析。畢竟,編譯器的輸入是源代碼,它是類 CFG 的(指令在某個塊中具有固定位置),而編譯器的輸出是組合語言,它也是類 CFG 的(指令在某個塊中也具有固定位置)。擁有類 CFG 的 IR 將使編譯器工程師更容易將 IR 的元素與源代碼或生成的組合語言匹配。
相比之下,以下是對應的 CFG 圖形(我們已開始用 CFG 替換 Sea of Nodes,因此有此圖):
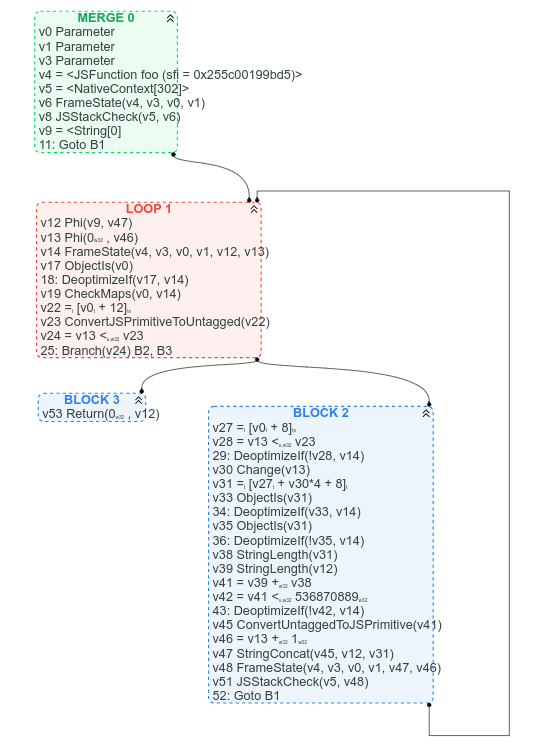
首先,在 CFG 中,循環在哪裡很明顯,退出條件也清晰可見,我們可以根據期望的指令位置輕鬆找到某些指令:例如 arr.length 位於循環頭(它是 v22 = [v0 + 12]),字符串連接則位於循環結尾(v47 StringConcat(...))。
可以說,在 CFG 版本中,值使用鏈條更難追踪,但我認為大多數情況下,清楚地看到圖形的控制流結構比看到一鍋值節點更有益。
太多節點位於效果鏈上並且/或者有控制輸入
為了從 Sea of Nodes 中受益,圖形中的大多數節點應該自由漂浮,而無需控制或效果鏈。不幸的是,在典型的 JavaScript 圖形中並非如此,因為幾乎所有通用 JavaScript 操作都可能具有任意副作用。然而在 Turbofan 中這些應該是罕見的,因為我們有反饋,應該允許我們將它們降級為更多的專門操作。
即便如此,每個內存操作都需要效果輸入(因為 Load 不應漂浮到 Stores 之後,反之亦然)以及控制輸入(因為在操作之前可能有類型檢查或邊界檢查)。即便是一些純操作,比如除法也需要控制輸入,因為它們可能有被檢查保護的特殊情況。
讓我們看一個具體的例子,從以下 JavaScript 函數開始:
function foo(a, b) {
// 假設 `a.str` 和 `b.str` 是字符串
return a.str + b.str;
}
以下是對應的 Turbofan 圖形。為了更清楚起見,我用紅色虛線突出了一部分效果鏈,並用數字註解了一些節點,便於討論。
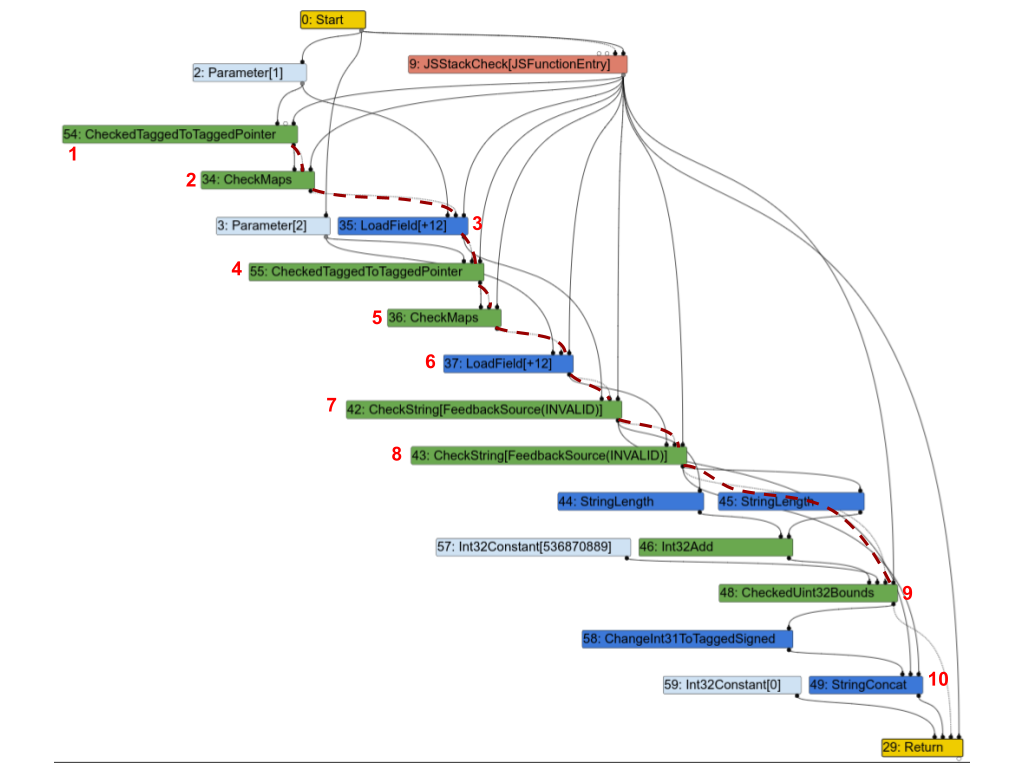
第一個觀察是幾乎所有節點都位於效果鏈上。讓我們逐一查看其中一些節點,看它們是否真的需要如此:
1(CheckedTaggedToTaggedPointer): 這檢查了函數的第一個輸入是否為指針,而不是“小整數”(參見 V8 的指針壓縮)。它自己本身並不真的需要一個影響輸入,但實際上,仍然需要它在影響鏈上,因為它保護後續的節點。2(CheckMaps): 現在我們知道第一個輸入是指針,該節點載入了它的“map”(參見 V8 中的隐藏類),並檢查它是否與該對象的反饋記錄相匹配。3(LoadField): 現在我們知道第一個對象是具有正確地圖的指針,我們可以載入它的.str字段。4、5和6是對第二個輸入的重複。7(CheckString): 現在我們已經載入了a.str,此節點檢查它是否確實是一個字符串。8: 對第二個輸入的重複。9: 檢查a.str和b.str的總長度是否小於 V8 中字符串的最大長度。10(StringConcat): 最後將兩個字符串連接起來。
這個圖表對於 JavaScript 程式中的 Turbofan 圖表來說非常典型:檢查地圖、載入值、檢查載入值的地圖等等,最後進行一些計算。在很多情況下,就像這個例子,的大部分指令最終都在效果鏈或控制鏈上,這對操作執行順序施加了嚴格的限制,完全削弱了 Sea of Nodes 的目的。
記憶體操作不容易漂浮
讓我們考慮以下 JavaScript 程式:
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
考慮到 x 和 y 分別只在 if-else 的單側中使用,我們可能希望 SoN 允許它們自由地漂浮到“then”和“else”分支的內部。然而,實際上,讓 SoN 實現這一點並不比在 CFG 中更容易。我們來看一下 SoN 的圖表以理解原因:

當我們構建 SoN 圖表時,我們會沿著構建效果鏈,因此第二個 Load 緊接在第一個 Load 之後,接著效果鏈必須拆分以到達兩個 return(如果您想知道為什麼 return 甚至在效果鏈上,那是因為在返回函數前可能存在帶有副作用的操作,比如 Store)。由於第二個 Load 是兩個 return 的前置節點,因此它必須在 branch 之前調度,因此 SoN 不允許任何一個 Load 自由地向下漂浮。
為了將 Load 向下移動到“then”和“else”分支,我們必須計算它們之間不存在副作用,以及第二個 Load 和 return 之間也不存在副作用,然後我們可以在第二個 Load 之前而不是之後拆分效果鏈。在 SoN 圖表或 CFG 上進行這種分析非常相似。
現在我們已經提到很多節點最終都在效果鏈上,並且帶有副作用的節點通常不會自由漂浮得太遠,是個好時機來認識到,在某種意義上,SoN 只是 CFG,其中純節點是自由漂浮的。實際上,控制節點和控制鏈總是反映等效 CFG 的結構。而且,當分支的兩個目的地都有副作用(這在 JavaScript 中很常見)時,效果鏈在控制鏈拆分和合併的地方正好拆分和合併(如上述例子:控制鏈在 branch 處拆分,並由效果鏈通過 Load 鏡像拆分;如果程序在 if-else 後繼續,兩個鏈會在同一地方左右合併)。因此,帶有副作用的節點通常最終被約束在兩個控制節點之間排程,即基本快中。而在這個基本塊中,效果鏈將把帶有副作用的節點限制在與源代碼中相同的順序中。最終,只有純節點實際上自由漂浮。
一種獲得更多漂浮節點的方法是使用多個效果鏈,如前所述,但這是有代價的:首先,管理單個效果鏈已經很困難,管理多個會更困難。其次,在像 JavaScript 這樣的動態語言中,我們最後會遇到很多可能混疊的記憶體訪問,這意味著多個效果鏈可能需要頻繁合併,因此削弱了使用多個效果鏈的部分優勢。
手動管理效果鏈和控制鏈很困難
如前節所述,雖然效果鏈和控制鏈有些區別,但是在實際中,效果鏈通常與控制鏈具有相同的“形狀”:如果分支的目的地包含有影響的操作(這通常會發生),則效果鏈將在分支處拆分,並在控制流合併時合併回來。 因為我們正在處理 JavaScript,很多節點都有副作用,而且我們有很多分支(通常是基於某些物件的類型進行分支),這導致我們必須同時跟蹤效果鏈和控制鏈,而使用 CFG 時,我們只需要跟蹤控制鏈即可。
歷史證明,手動管理效果鏈和控制鏈既容易出錯,又難以閱讀和維護。以下是來自 JSNativeContextSpecialization 階段的代碼範例:
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effect effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effect this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
由於這裡需要處理的分支和情況多樣,我們最終需要管理 3 條不同的效果鏈。這很容易出錯,可能使用了錯誤的效果鏈。事實上,我們最初確實出錯了,而且在幾個月後才發現了這個錯誤:

對於這個問題,我會將責任歸咎於 Turbofan 和 Sea of Nodes,而不僅僅是後者。在 Turbofan 中使用更好的輔助工具可以簡化效果鏈和控制鏈的管理,但這在 CFG 中根本不是問題。
調度器過於複雜
最終,所有指令都必須被調度以生成組合語言代碼。調度指令的理論相對簡單:每條指令應在其值、控制和效果輸入(忽略循環)的後面進行調度。
讓我們來看一個有趣的例子:

你會注意到雖然源 JavaScript 程式有兩個相同的除法運算,Sea of Node 圖中只有一個。實際上,Sea of Nodes 開始時會有兩個除法運算,但由於這是純操作(假設是雙精度輸入),消除冗餘會輕鬆將它們去重成一個。
然後,在進入調度階段時,我們需要找到一個位置來調度這個除法運算。顯然,它不能放在 case 1 或 case 2 之後,因為另一個用到了它。所以,它必須被調度在 switch 的前面。缺點是現在,即使在 c 是 3 的情況下,a / b 也會被計算,這時實際上它並不需要被計算。這是一個真正的問題,可能導致很多已去重的指令飄移到其使用者的公共支配點,從而減慢許多路徑的執行速度,這些路徑其實並不需要它們。
然而,還是有解決方法的:Turbofan 的調度器會嘗試識別這些情況並複製指令,這樣它們只會在需要的路徑上被計算。缺點是,這使得調度器變得更加複雜,需要額外的邏輯來弄清楚哪些節點可以且應該被複製,以及如何複製它們。
基本上,我們一開始有 2 個除法,然後“優化”到了單個除法,再進一步優化回到了 2 個除法。而且,這不僅僅發生在除法上,許多其他操作也會經歷類似的循環。
找到訪問圖表的良好順序是困難的
編譯器的每一個階段都需要訪問圖表,無論是為了降低節點,進行局部優化,還是對整個圖表進行分析。在 CFG 中,訪問節點的順序通常是直截了當的:從首個區塊開始(假設是單入口函數),迭代每個區塊的節點,然後移動到後繼節點,以此類推。在窗口優化階段(例如強度削減),按此順序處理圖表的一個良好屬性是:輸入總是在處理節點之前被優化,因此只需訪問每個節點一次,就足以應用大多數窗口優化。舉例來說,考慮以下這段削減序列:

總計花了三步來優化整個序列,而每一步都執行了有用的工作。之後,死代碼消除會移除 v1 和 v2,使得最終指令數比初始序列少了一條。
使用 Sea of Nodes,無法從頭到尾處理純指令,因為它們並不在任何控制或效果鏈上,因此沒有指向純根或類似東西的指針。相反,對 Sea of Nodes 圖進行窺孔優化的常用方式是從結尾開始(例如 return 指令),然後沿著值、效果和控制輸入向上進行。這有一個很好的特性,就是不會訪問任何未使用的指令,但優點大致到此為止,因為對於窺孔優化,這是你可能得到的最差的訪問順序。在上面的例子中,以下是我們將採取的步驟:
- 首先訪問
v3,但在此時無法將它降低,然後轉向其輸入- 訪問
v1,將它降低為a << 3,然後繼續查看它的使用情況,以確定是否因為v1的降低使它們能被優化。- 再次訪問
v3,但此時仍無法降低(這次,我們不會再次訪問其輸入)
- 再次訪問
- 訪問
v2,將它降低為b << 3,然後繼續查看它的使用情況,以確定是否因為此次降低使它們能被優化。- 再次訪問
v3,將它降低為(a & b) << 3。
- 再次訪問
- 訪問
因此,總共訪問了 v3 3 次,但只降低了一次。
我們早些時候測量了這種影響對典型 JavaScript 程序的影響,並發現平均來說,每 20 次訪問中只有一次能改變節點\!
該圖形訪問順序難以找到好的安排的另一個結果是狀態追蹤既困難又昂貴。 許多優化需要沿著圖形追蹤某些狀態,例如載入消除或逃逸分析。然而,這在 Sea of Nodes 中很難做到,因為在某一點上,很難知道某一狀態是否需要保持活著,因為難以確定未處理的節點是否需要該狀態來被處理。 因此,Turbofan 的載入消除階段在大型圖形上有一個退出機制,避免耗費過多時間完成並消耗太多內存。相比之下,我們為新的 CFG 編譯器編寫了一個新的載入消除階段,其基準測試表明速度最多提高了 190 倍(它具有更好的最壞情況複雜度,因此在大型圖形上實現速度提升相對容易),且使用內存更少。
記憶體不友好
Turbofan 中幾乎所有階段都會就地修改圖形。考慮到節點在內存中相當大(主要原因是每個節點同時包含指向其輸入和其使用的指針),我們試圖最大限度地重用節點。然而,當我們將節點降級為多個節點的序列時,不可避免地必須引入新的節點,這些新節點必然無法與原始節點在內存中分配得很近。結果就是,我們越深入 Turbofan 管道,執行的階段越多,圖形對緩存的友好性就越低。以下是此現象的示例:

很難估計對記憶體的影響,但由於有新的 CFG 編譯器,我們可以比較兩者之間的緩存失敗次數:Sea of Nodes 平均比我們的新 CFG IR 多大約 3 倍的 L1 dcache 失敗次數,有些階段甚至多達 7 倍。我們估算這耗費了最多 5% 的編譯時間,儘管此數據可能存在一定偏差。但請記住,在 JIT 編譯器中,快速編譯是至關重要的。
與控制流相關的類型有限
讓我們看看下面這段 JavaScript 函數:
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
如果到目前為止我們只看到 x 和 x+1 的結果是小整數(“小整數”是 31 位整數,參見在 V8 中的值標記),那麼我們會推測情況會保持不變。如果我們發現 x 超過了 31 位整數,那麼我們將取消優化。同樣,若 x+1 產生的結果超過 31 位,我們也會取消優化。這意味著我們需要檢查 x+1 是否小於或大於 31 位可容納的最大值。讓我們看看對應的 CFG 和 SoN 圖形:

(假設 CheckedAdd 操作是將其輸入相加並在結果溢出 31 位時取消優化)
使用 CFG,很容易意識到當執行 CheckedAdd(v1, 1) 時,v1 會保證小於 42,因此沒有必要檢查 31 位溢出。我們因此可以輕鬆地將 CheckedAdd 替換為常規的 Add,此操作執行速度更快,且不需要取消優化狀態(否則需要知道取消優化後如何繼續執行)。
然而,使用 SoN 圖形,由於 CheckedAdd 是一個純操作,它會在圖形中自由流動,因此在計算調度並決定將其放置在分支之後之前,無法移除檢查(在這一點上,我們已回到 CFG,因此不再進行 SoN 專屬的優化)。
在 V8 中,由於此 31 位小整數的優化,這類受檢查操作是非常常見的,而能夠將受檢查操作替換為未檢查操作,可能對 Turbofan 生成代碼的品質產生重大影響。因此,Turbofan 的 SoN 在 CheckedAdd 上添加了一個控制輸入,此舉可以啟用此優化,但也意味著在純節點上引入了調度約束,也就是回到 CFG。
以及許多其他問題……
傳播失效性很困難。 通常,在某些降級過程中,我們意識到當前節點實際上不可到達。在 CFG 中,我們可以在此處簡單地剪切當前基本塊,接下來的塊將自動變得顯然不可到達,因為它們不再有任何前置節點。在 Sea of Nodes 中要更加困難,因為必須修補控制與效果鏈。因此,當效果鏈中的某個節點失效時,我們必須沿著效果鏈向前行走到下一次合併,並在過程中消滅沿途的所有內容,還需要小心處理控制鏈上的節點。
引入新的控制流很困難。 由於控制流節點必須位於控制鏈上,因此在常規降級過程中不可能引入新的控制流。因此,如果圖中有一個純節點,例如 Int32Max,它返回兩個整數中的最大值,而我們最終希望它降級為 if (x > y) { x } else { y },在 Sea of Nodes 中這並不容易做到,因為我們需要想出一種方法來確定將此子圖插入到控制鏈上的哪個位置。實現此目的的一種方式是從一開始就將 Int32Max 放到控制鏈上,但這感覺是在浪費:節點是純的,應該允許自由移動。因此,Sea of Nodes 的典型解決方法(無論是 Turbofan 還是其發明者 Cliff Click 在Coffee Compiler Club聊天中提到的方法)是推遲這種降級直到我們有調度(以及 CFG)。結果是,我們在管道的中間有一個計算調度並降級圖的階段,許多散亂的優化都被打包到一起,因為它們都需要調度。相比之下,使用 CFG,我們可以在管道中更早或更晚執行這些優化。
此外,還記得介紹部分提到的 Crankshaft(Turbofan 的前身)的一個問題,即在構建圖之後幾乎不可能引入控制流。Turbofan 在這方面稍有改進,因為降低控制鏈上的節點可以引入新的控制流,但仍然有限。
弄清迴圈中包含什麼是很困難的。 由於許多節點漂浮在控制鏈之外,很難弄清每個迴圈中包含哪些內容。因此,基本優化(例如迴圈剝離和迴圈展開)很難實現。
編譯速度慢。 這是我已經提到的多種問題的直接後果:很難找到節點的良好訪問順序,導致許多無用的重新訪問,狀態跟踪成本高昂,記憶體使用性差,緩存區域性差……這可能對於提前編譯器來說不是大問題,但在 JIT 編譯器中,編譯速度慢意味著我們在優化代碼就緒之前一直在執行慢速未優化的代碼,而且還會佔用其他任務(例如,其他編譯作業或垃圾回收器)的資源。這種情況的一個結果是,我們被迫對新優化的編譯時間 -加速平衡進行非常仔細的思考,通常會偏向於減少優化以保持快速優化。
Sea of Nodes 會徹底毀壞任何現有的調度。 JavaScript 源代碼通常不會手動進行以 CPU 微架構為導向的優化。然而,WebAssembly 代碼可以如此,無論是在源級(例如 C++),還是通過提前編譯 (AOT) 編譯工具鏈(例如 Binaryen/Emscripten)。結果是,WebAssembly 的代碼可以安排為適合大多數架構的方式(例如,減少溢出的需求,假設有 16 個寄存器)。然而,SoN 總是會丟棄初始調度,只能依賴其自己的調度器,這因 JIT 編譯的時間限制,可能容易比 AOT 編譯器(或仔細考慮其代碼調度的 C++ 開發者所能實現的調度)更糟。我們曾看到 WebAssembly 因此受影響的案例。而且,不幸的是,對於 Turbofan 來說,為 WebAssembly 使用 CFG 編譯器、為 JavaScript 使用 SoN 編譯器也不可行,因為為兩者使用相同的編譯器能夠跨兩種語言進行內聯。
Sea of Nodes: 優雅但對 JavaScript 不實用
因此,總結一下,我們對 Sea of Nodes 和 Turbofan 存在的主要問題如下:
-
它 過於複雜。效果和控制鏈條難以理解,導致許多微妙的錯誤。圖表難以閱讀和分析,使得新優化難以實現和完善。
-
它 過於有限。由於我們正在編譯 JavaScript 程式碼,因此有太多節點位於效果和控制鏈條上,與傳統的控制流圖 (CFG) 相比,並沒有提供太多的優勢。此外,由於在降低過程中很難引入新的控制流,即使是基本的優化實現起來也會變得困難。
-
編譯速度 過於緩慢。狀態追蹤成本高昂,因為很難找到一種良好的順序來遍訪圖表。緩存區的局部性很差。而在縮減階段達到固定點需要花費過多時間。
因此,經過十年處理 Turbofan 並與節點海模型作鬥爭後,我們最終決定放棄它,轉而回到更傳統的控制流圖 (CFG) 中介表示 (IR)。到目前為止,我們對新 IR 的使用經驗非常積極,並且我們非常高興回到 CFG 中:編譯時間相比節點海減少了一半,編譯器代碼變得簡單且更短,調查錯誤通常也變得更容易等等。 不過,這篇文章已經相當長了,所以我在這裡打住。請關注我們即將發布的部落格文章,將會解釋我們的新 CFG IR,即 Turboshaft 的設計。