¡Tierra a la vista: dejando el Mar de Nodos
El compilador optimizador de última etapa de V8, Turbofan, es conocido por ser uno de los pocos compiladores de producción a gran escala que utiliza Sea of Nodes (SoN). Sin embargo, desde hace casi 3 años, hemos comenzado a deshacernos del Mar de Nodos y a recurrir a una Representación Intermedia (IR) más tradicional basada en Graphos de Flujo de Control (CFG), que hemos denominado Turboshaft. Hasta ahora, todo el backend de JavaScript de Turbofan usa Turboshaft en su lugar, y WebAssembly usa Turboshaft en toda su tubería. Dos partes de Turbofan aún usan algo del Mar de Nodos: la tubería integrada, que estamos reemplazando lentamente por Turboshaft, y el frontend de la tubería de JavaScript, que estamos reemplazando por Maglev, otra IR basada en CFG. Esta publicación en el blog explica las razones que nos llevaron a alejarnos del Mar de Nodos.
Hace 12 años, en 2013, V8 tenía un único compilador optimizador: Crankshaft. Utilizaba una Representación Intermedia basada en Graphos de Flujo de Control. La versión inicial de Crankshaft ofreció mejoras significativas de rendimiento a pesar de ser aún bastante limitada en lo que admitía. Durante los años siguientes, el equipo siguió mejorándolo para generar código aún más rápido en más situaciones. Sin embargo, la deuda técnica comenzó a acumularse y surgieron varios problemas con Crankshaft:
-
Contenía demasiado código ensamblador escrito a mano. Cada vez que se añadía un nuevo operador a la IR, su traducción al ensamblador tenía que escribirse manualmente para las cuatro arquitecturas oficialmente soportadas por V8 (x64, ia32, arm, arm64).
-
Tenía dificultades para optimizar asm.js, que en ese momento se veía como un paso importante hacia un JavaScript de alto rendimiento.
-
No permitía introducir flujo de control en las reductoras. Dicho de otra manera, el flujo de control se creaba en el momento de la construcción del grafo y luego se volvía definitivo. Esto era una gran limitación, dado que algo común al escribir compiladores es comenzar con operaciones de alto nivel y luego reducirlas a operaciones de bajo nivel, muchas veces introduciendo flujo de control adicional. Consideremos, por ejemplo, una operación de alto nivel
JSAdd(x,y), podría tener sentido reducirla más tarde a algo comoif (x es String and y es String) { StringAdd(x, y) } else { … }. Bueno, eso no era posible en Crankshaft. -
No se admitían bloques try-catch, y admitirlos era muy desafiante: varios ingenieros habían pasado meses tratando de soportarlos, sin éxito.
-
Sufría numerosos desplomes de rendimiento y reversiones. Usar una característica o instrucción específica, o tropezar con un caso límite específico de una característica, podía hacer que el rendimiento disminuyera en un factor de 100. Esto dificultaba que los desarrolladores de JavaScript escribieran código eficiente y anticiparan el rendimiento de sus aplicaciones.
-
Contenía muchos bucles de desoptimización: Crankshaft optimizaba una función usando algunas suposiciones especulativas, luego la función se desoptimizaba cuando esas suposiciones no se cumplían, pero muy a menudo, Crankshaft reoptimizaba la función con las mismas suposiciones, lo que conducía a bucles interminables de optimización-desoptimización.
Individualmente, probablemente cada uno de estos problemas podría haberse superado. Sin embargo, combinados, parecían demasiado. Por lo tanto, se tomó la decisión de reemplazar Crankshaft con un nuevo compilador escrito desde cero: Turbofan. Y, en lugar de usar una IR tradicional basada en CFG, Turbofan utilizaría una IR supuestamente más poderosa: Mar de Nodos. En ese momento, esta IR ya se había utilizado durante más de 10 años en C2, el compilador JIT de la Máquina Virtual Java HotSpot.
Pero, ¿qué es realmente el Mar de Nodos?
Primero, un pequeño recordatorio sobre el grafo de flujo de control (CFG): un CFG es una representación de un programa como un grafo donde los nodos del grafo representan bloques básicos del programa (es decir, una secuencia de instrucciones sin ramas o saltos entrantes o salientes), y los bordes representan el flujo de control del programa. Aquí hay un ejemplo simple:

Las instrucciones dentro de un bloque básico están implícitamente ordenadas: la primera instrucción debe ejecutarse antes que la segunda, y la segunda antes que la tercera, etc. En el pequeño ejemplo anterior, parece muy natural: v1 == 0 no puede ser calculado antes de que x % 2 haya sido computado de todas maneras. Sin embargo, considera

Aquí, el CFG aparentemente impone que a * 2 sea calculado antes que b * 2, aunque podríamos calcularlos en el orden contrario sin problemas.
Ahí es donde entra Sea of Nodes: Sea of Nodes no representa bloques básicos, sino solo dependencias verdaderas entre las instrucciones. Los nodos en Sea of Nodes son instrucciones individuales (en lugar de bloques básicos), y los bordes representan usos de valores (es decir: un borde de a a b representa el hecho de que a usa b). Entonces, aquí está cómo se representaría este último ejemplo con Sea of Nodes:

Eventualmente, el compilador tendrá que generar ensamblaje y, por lo tanto, programará secuencialmente estas dos multiplicaciones, pero hasta entonces, ya no hay dependencia entre ellas.
Ahora vamos a añadir flujo de control a la mezcla. Los nodos de control (por ejemplo, branch, goto, return) típicamente no tienen dependencias de valores entre sí que obliguen a un horario particular, aunque definitivamente deben programarse en un orden específico. Por lo tanto, para representar el flujo de control, necesitamos un nuevo tipo de borde, bordes de control, que imponen cierto orden en los nodos que no tienen dependencia de valores:

En este ejemplo, sin bordes de control, nada impediría que los return se ejecutaran antes del branch, lo cual obviamente sería incorrecto.
Lo crucial aquí es que los bordes de control solo imponen un orden de las operaciones que tienen esos bordes entrantes o salientes, pero no sobre otras operaciones como las aritméticas. Esta es la principal diferencia entre Sea of Nodes y los gráficos de flujo de control.
Ahora agreguemos operaciones con efectos (por ejemplo, cargas y almacenes desde y hacia memoria) a la mezcla. Similar a los nodos de control, las operaciones con efectos a menudo no tienen dependencias de valores, pero aún así no pueden ejecutarse en un orden aleatorio. Por ejemplo, a[0] += 42; x = a[0] y x = a[0]; a[0] += 42 no son equivalentes. Entonces, necesitamos una forma de imponer un orden (= un horario) en las operaciones con efectos. Podríamos reutilizar la cadena de control para este propósito, pero esto sería más estricto de lo necesario. Por ejemplo, considera este pequeño fragmento:
let v = a[2];
if (c) {
return v;
}
Al poner a[2] (que lee memoria) en la cadena de control, forzaríamos que ocurra antes de la rama en c, aunque en la práctica, esta carga podría fácilmente ocurrir después de la rama si su resultado solo se usa dentro del cuerpo de la rama 'then'. Tener muchos nodos del programa en la cadena de control derrotaría el objetivo de Sea of Nodes, ya que básicamente terminaríamos con una IR tipo CFG donde solo flotarían operaciones puras.
Entonces, para disfrutar de más libertad y beneficiarnos realmente de Sea of Nodes, Turbofan tiene otro tipo de borde, bordes de efecto, que imponen cierto orden en los nodos que tienen efectos secundarios. Ignorando el flujo de control por ahora, veamos un pequeño ejemplo:

En este ejemplo, arr[0] = 42 y let x = arr[a] no tienen dependencia de valores (es decir, el primero no es una entrada del segundo, y viceversa). Sin embargo, dado que a podría ser 0, arr[0] = 42 debería ejecutarse antes de x = arr[a] para que este último siempre cargue el valor correcto del arreglo.
Nota que, aunque Turbofan tiene una única cadena de efectos (que se divide en ramas y se fusiona nuevamente cuando el flujo de control se fusiona) que se utiliza para todas las operaciones con efectos, es posible tener múltiples cadenas de efectos, donde las operaciones que no tienen dependencias podrían estar en diferentes cadenas de efectos, relajando cómo pueden ser programadas (ver Capítulo 10 de SeaOfNodes/Simple para más detalles). Sin embargo, como explicaremos más adelante, mantener una única cadena de efectos ya es muy propenso a errores, por lo que no intentamos en Turbofan tener múltiples cadenas.
Y, por supuesto, la mayoría de los programas reales contendrán tanto flujo de control como operaciones con efectos.

Nota que store y load necesitan entradas de control, ya que podrían estar protegidos por varias verificaciones (como verificaciones de tipo o límites).
Este ejemplo es una buena demostración del poder de Sea of Nodes en comparación con CFG: y = x * c solo se utiliza en la rama else, por lo que flota libremente después de la branch en lugar de ser computado antes, como estaba escrito en el código original de JavaScript. Esto es similar para arr[0], que solo se utiliza en la rama else y podría flotar después de la branch (aunque, en la práctica, Turbofan no moverá arr[0] hacia abajo, por razones que explicaré más adelante).
Para comparar, aquí está cómo se vería el CFG correspondiente:

Ya comenzamos a ver el problema principal con SoN: está mucho más alejado tanto de la entrada (código fuente) como de la salida (ensamblaje) del compilador en comparación con CFG, lo que lo hace menos intuitivo para entender. Además, tener dependencias de efecto y control siempre explícitas hace difícil razonar rápidamente sobre el gráfico y escribir conversiones descendentes (ya que las conversiones siempre deben mantener explícitamente la cadena de control y efecto, que son implícitas en un CFG).
Y comienzan los problemas...
Después de más de una década lidiando con Sea of Nodes, pensamos que tiene más desventajas que ventajas, al menos en lo que a JavaScript y WebAssembly respecta. Entraremos en detalles en algunos de los problemas a continuación.
Inspeccionar y entender manualmente/visualmente un gráfico de Sea of Nodes es complicado
Ya hemos visto que en programas pequeños el CFG es más fácil de leer, ya que está más cerca del código fuente original, que es lo que los desarrolladores (¡incluyendo ingenieros de compiladores!) están acostumbrados a escribir. Para los lectores no convencidos, permítanme ofrecer un ejemplo ligeramente más grande, para que comprendan mejor el problema. Considere la siguiente función de JavaScript, que concatena una matriz de cadenas:
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
Aquí está el gráfico correspondiente de Sea of Nodes, en el medio del pipeline de compilación de Turbofan (lo que significa que ya se han realizado algunas conversiones descendentes):
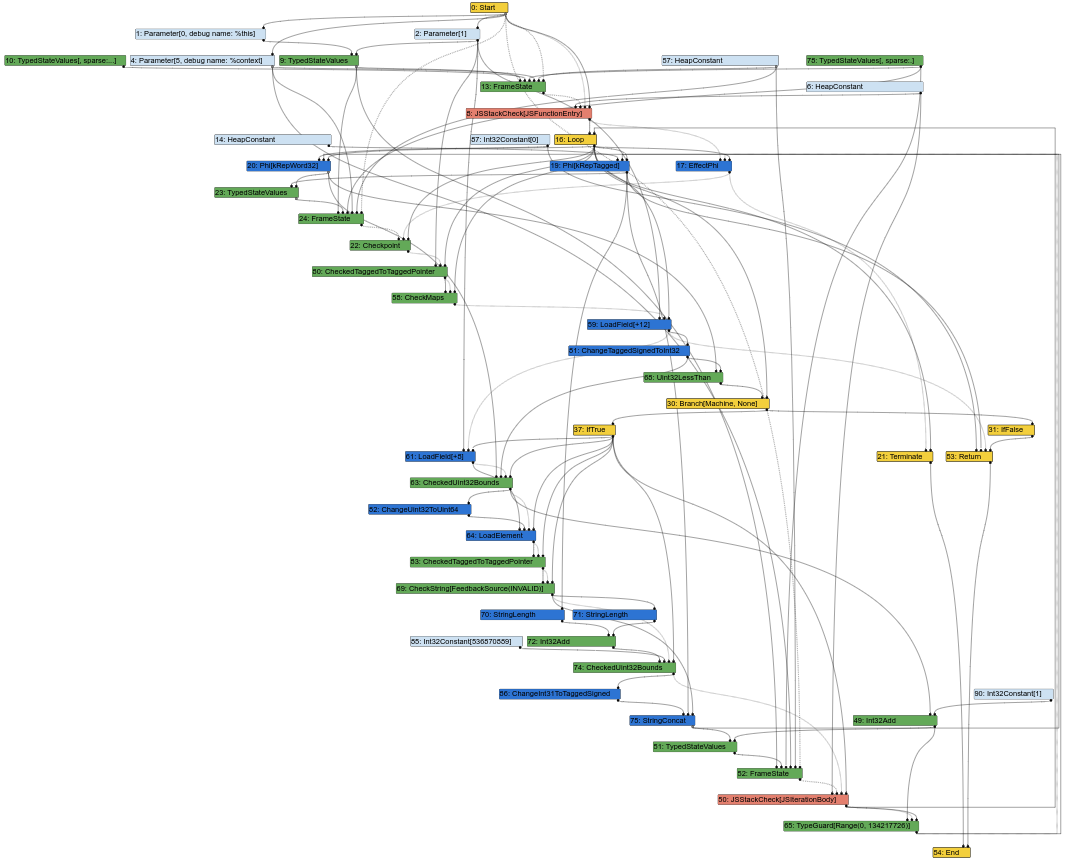
Este comienza a parecerse a una sopa desordenada de nodos. Y, como ingeniero de compiladores, una gran parte de mi trabajo consiste en observar gráficos de Turbofan para comprender errores o encontrar oportunidades de optimización. Bueno, no es fácil hacerlo cuando el gráfico se ve así. Después de todo, la entrada de un compilador es el código fuente, que es parecido a CFG (las instrucciones tienen una posición fija en un bloque determinado), y la salida del compilador es ensamblaje, que también es parecido a CFG (las instrucciones también tienen una posición fija en un bloque determinado). Tener una IR parecida a CFG facilita que los ingenieros de compiladores correspondan elementos de la IR con el código fuente o el ensamblaje generado.
Para comparar, aquí está el gráfico de CFG correspondiente (que tenemos disponible porque ya hemos comenzado el proceso de reemplazar sea of nodes con CFG):
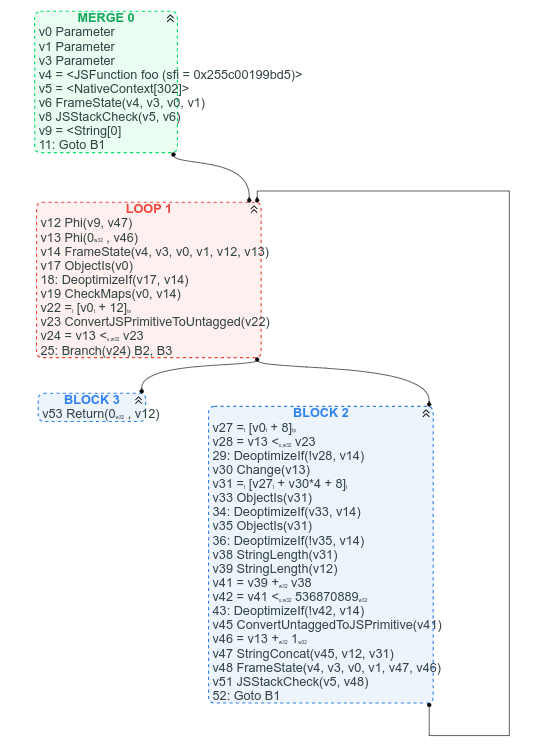
Entre otras cosas, con el CFG, está claro dónde está el bucle, es evidente cuál es la condición de salida del bucle, y es fácil encontrar algunas instrucciones en el CFG basándose en dónde esperamos que estén: por ejemplo, arr.length se puede encontrar en el encabezado del bucle (v22 = [v0 + 12]), y la concatenación de cadenas puede encontrarse hacia el final del bucle (v47 StringConcat(...)).
Es discutible que las cadenas de uso de valores sean más difíciles de seguir en la versión CFG, pero argumentaría que, la mayoría de las veces, es mejor ver claramente la estructura de flujo de control del gráfico que una sopa de nodos de valor.
Demasiados nodos están en la cadena de efectos y/o tienen una entrada de control
Para beneficiarse de Sea of Nodes, la mayoría de los nodos en el gráfico deberían flotar libremente, sin cadena de control ni efectos. Desafortunadamente, eso no es realmente el caso en el gráfico típico de JavaScript, porque casi todas las operaciones genéricas de JS pueden tener efectos secundarios arbitrarios. Deberían ser raros en Turbofan, sin embargo, ya que tenemos feedback que debería permitir reducirlos a operaciones más específicas.
Aun así, cada operación de memoria necesita tanto una entrada de efecto (ya que una carga no debería flotar más allá de las escrituras y viceversa) como una entrada de control (ya que podría haber una verificación de tipo o de límites antes de la operación). Incluso algunas operaciones puras como la división necesitan entradas de control porque podrían tener casos especiales protegidos por verificaciones.
Veamos un ejemplo concreto, comenzando por la siguiente función de JavaScript:
function foo(a, b) {
// suponiendo que `a.str` y `b.str` son cadenas
return a.str + b.str;
}
Aquí está el gráfico correspondiente de Turbofan. Para mayor claridad, he destacado parte de la cadena de efectos con líneas rojas discontinuas y anotado algunos nodos con números para poder discutirlos a continuación.
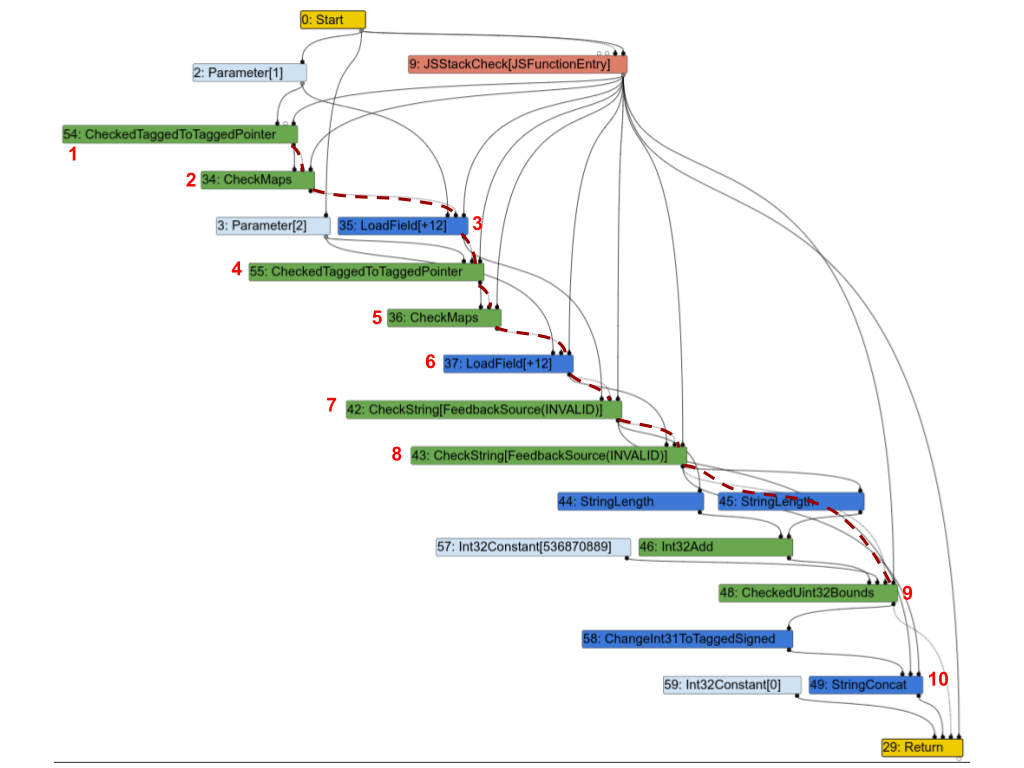
La primera observación es que casi todos los nodos están en la cadena de efectos. Repasemos algunos de ellos y veamos si realmente necesitan estar:
1(CheckedTaggedToTaggedPointer): esto verifica que la primera entrada de la función sea un puntero y no un “entero pequeño” (ver Compresión de Punteros en V8). Por sí solo, no necesitaría una entrada de efecto, pero en la práctica, todavía es necesario que esté en la cadena de efectos porque protege los nodos siguientes.2(CheckMaps): ahora que sabemos que la primera entrada es un puntero, este nodo carga su “mapa” (ver Mapas (Clases Ocultas) en V8), y verifica que coincida con lo que el feedback registró para este objeto.3(LoadField): ahora que sabemos que el primer objeto es un puntero con el mapa correcto, podemos cargar su campo.str.4,5y6: se repiten para la segunda entrada.7(CheckString): ahora que hemos cargadoa.str, este nodo verifica que realmente sea una cadena.8: repetido para la segunda entrada.9: verifica que la longitud combinada dea.stryb.strsea menor que el tamaño máximo de una cadena en V8.10(StringConcat): finalmente concatena las dos cadenas.
Este gráfico es muy típico de los gráficos de Turbofan para programas JavaScript: verificar mapas, cargar valores, verificar los mapas de los valores cargados, y así sucesivamente, y eventualmente realizar algunos cálculos sobre esos valores. Y como en este ejemplo, en muchos casos, la mayoría de las instrucciones terminan estando en la cadena de efectos o de control, lo que impone un orden estricto en las operaciones y derrota por completo el propósito de Sea of Nodes.
Las operaciones de memoria no fluyen fácilmente
Consideremos el siguiente programa de JavaScript:
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
Dado que x y y se usan cada uno solo en un lado del if-else, podríamos esperar que SoN les permitiera flotar libremente dentro de las ramas “then” y “else”. Sin embargo, en la práctica, hacer que esto suceda en SoN no sería más fácil que en un CFG. Veamos el gráfico de SoN para entender por qué:

Cuando construimos el gráfico de SoN, creamos la cadena de efectos a medida que avanzamos, y por lo tanto, la segunda Load termina justo después de la primera, tras lo cual la cadena de efectos debe dividirse para alcanzar ambos returns (si te preguntas por qué los returns están incluso en la cadena de efectos, es porque podría haber operaciones con efectos secundarios antes, como Store, que deben ejecutarse antes de regresar de la función). Dado que la segunda Load es un predecesor de ambos returns, debe programarse antes del branch, y por lo tanto, SoN no permite que cualquiera de las dos Loads flote libremente.
Para mover las Loads hacia abajo dentro de las ramas “then” y “else”, tendríamos que calcular que no hay efectos secundarios entre ellas y que no hay efectos secundarios entre la segunda Load y los returns, entonces podríamos dividir la cadena de efectos al principio en lugar de después de la segunda Load. Hacer este análisis en un gráfico de SoN o en un CFG es extremadamente similar.
Ahora que hemos mencionado que muchos nodos terminan en la cadena de efectos y que los nodos con efectos suelen no flotar libremente muy lejos, es un buen momento para darse cuenta de que, de alguna manera, SoN es simplemente un CFG donde los nodos puros flotan. De hecho, en la práctica, los nodos de control y la cadena de control siempre reflejan la estructura del CFG equivalente. Y, cuando ambos destinos de un branch tienen efectos secundarios (lo cual es frecuente en JavaScript), la cadena de efectos se divide y se fusiona exactamente donde lo hace la cadena de control (como en el caso del ejemplo anterior: la cadena de control se divide en el branch y la cadena de efectos refleja esto dividiéndose en Load; y si el programa continuara después del if-else, ambas cadenas se fusionarían en el mismo lugar). Los nodos con efectos típicamente terminan siendo restringidos para que se programen entre dos nodos de control, es decir, en un bloque básico. Y dentro de este bloque básico, la cadena de efectos restringirá los nodos con efectos para que estén en el mismo orden que estaban en el código fuente. Al final, solo los nodos puros flotan realmente libremente.
Una forma de obtener más nodos flotantes es usar múltiples cadenas de efectos, como se mencionó anteriormente, pero esto tiene un precio: primero, gestionar una sola cadena de efectos ya es difícil; gestionar múltiples será mucho más difícil. Segundo, en un lenguaje dinámico como JavaScript, terminamos con muchas accesos de memoria que podrían aliasarse, lo que significa que las múltiples cadenas de efectos tendrían que fusionarse muy a menudo, negando así parte de las ventajas de tener múltiples cadenas de efectos.
Gestionar manualmente las cadenas de efectos y control es difícil
Como se mencionó en la sección anterior, aunque la cadena de efectos y de control son algo distintas, en la práctica, la cadena de efectos típicamente tiene la misma “forma” que la cadena de control: si los destinos de un branch contienen operaciones con efectos secundarios (y esto suele ser el caso), entonces la cadena de efectos se dividirá en el branch y se fusionará nuevamente cuando el flujo de control se fusione de nuevo.
Debido a que estamos tratando con JavaScript, muchos nodos tienen efectos secundarios y tenemos muchas bifurcaciones (generalmente bifurcando según el tipo de algunos objetos), lo que nos lleva a tener que rastrear tanto la cadena de efectos como la cadena de control en paralelo, mientras que con un CFG, solo tendríamos que rastrear la cadena de control.
La historia ha demostrado que gestionar manualmente tanto las cadenas de efectos como las de control es propenso a errores, difícil de leer y difícil de mantener. Tome esta muestra de código de la fase JSNativeContextSpecialization:
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effect effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effect this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
Debido a las diversas bifurcaciones y casos que deben manejarse aquí, terminamos gestionando 3 cadenas de efectos diferentes. Es fácil equivocarse y usar una cadena de efectos en lugar de otra. Tan fácil que, de hecho, inicialmente nos equivocamos y solo nos dimos cuenta de nuestro error después de unos meses:

En este caso, culparía tanto a Turbofan como a Sea of Nodes, en lugar de solo a este último. Mejores ayudantes en Turbofan podrían haber simplificado la gestión de las cadenas de efectos y control, pero esto no habría sido un problema en un CFG.
El programador es demasiado complejo
Eventualmente, todas las instrucciones deben ser programadas para generar código ensamblador. La teoría para programar instrucciones es bastante simple: cada instrucción debe programarse después de sus valores, controles y entradas de efectos (ignorando los bucles).
Veamos un ejemplo interesante:

Notarás que, mientras el programa JavaScript fuente tiene dos divisiones idénticas, el gráfico de Sea of Nodes solo tiene una. En realidad, Sea of Nodes comenzaría con dos divisiones, pero dado que esta es una operación pura (asumiendo entradas dobles), la eliminación de redundancia las deduplicaría fácilmente en una sola.
Luego, al llegar a la fase de programación, tendríamos que encontrar un lugar para programar esta división. Claramente, no puede ir después de case 1 o case 2, ya que se utiliza en el otro. En cambio, tendría que programarse antes del switch. La desventaja es que, ahora, a / b se calculará incluso cuando c sea 3, donde realmente no necesita calcularse. Este es un problema real que puede llevar a que muchas instrucciones deduplicadas floten hacia el dominador común de sus usuarios, ralentizando muchos caminos que no los necesitan.
Sin embargo, hay una solución: el programador de Turbofan intentará identificar estos casos y duplicar las instrucciones para que solo se calculen en los caminos que las necesitan. La desventaja es que esto hace que el programador sea más complejo, requiriendo lógica adicional para averiguar qué nodos podrían y deberían duplicarse y cómo duplicarlos.
Entonces, básicamente, comenzamos con 2 divisiones, luego 'optimizamos' a una sola división, y luego optimizamos aún más a 2 divisiones nuevamente. Y esto no ocurre solo con divisiones: muchas otras operaciones pasarán por ciclos similares.
Encontrar un buen orden para visitar el gráfico es difícil
Todas las fases de un compilador necesitan visitar el gráfico, ya sea para bajar los nodos, aplicar optimizaciones locales o realizar análisis sobre todo el gráfico. En un CFG, el orden en el que visitar los nodos es generalmente directo: comienza desde el primer bloque (asumiendo una función de entrada única), e itera a través de cada nodo del bloque, y luego pasa a los sucesores y así sucesivamente. En una fase de optimización por ventana (como reducción de fuerza), una propiedad agradable de procesar el gráfico en este orden es que las entradas siempre se optimizan antes de que se procese un nodo, y visitar cada nodo exactamente una vez es suficiente para aplicar la mayoría de las optimizaciones por ventana. Considere, por ejemplo, la siguiente secuencia de reducciones:

En total, tomó tres pasos optimizar toda la secuencia, y cada paso hizo un trabajo útil. Después de lo cual, la eliminación de código muerto eliminaría v1 y v2, resultando en una instrucción menos que en la secuencia inicial.
Con Sea of Nodes, no es posible procesar instrucciones puras de principio a fin, ya que no están en ninguna cadena de control o de efectos, y por lo tanto no hay un puntero a raíces puras ni nada parecido. En cambio, la forma habitual de procesar un gráfico de Sea of Nodes para optimizaciones de peephole es comenzar desde el final (por ejemplo, instrucciones return) e ir hacia arriba por las entradas de valor, efecto y control. Esto tiene la ventaja de que no visitaremos ninguna instrucción no utilizada, pero las ventajas terminan ahí, porque para la optimización de peephole, este es el peor orden de visita que podrías obtener. En el ejemplo anterior, aquí están los pasos que tomaríamos:
- Comenzar visitando
v3, pero no se puede reducir en este punto, luego pasar a sus entradas- Visitar
v1, reducirlo aa << 3, luego pasar a sus usos, en caso de que la reducción dev1permita que se optimicen.- Visitar
v3nuevamente, pero no se puede reducir todavía (esta vez, no visitaríamos sus entradas nuevamente).
- Visitar
- Visitar
v2, reducirlo ab << 3, luego pasar a sus usos, en caso de que esta reducción permita que se optimicen.- Visitar
v3nuevamente, reducirlo a(a & b) << 3.
- Visitar
- Visitar
Entonces, en total, v3 fue visitado 3 veces pero solo reducido una vez.
Medimos este efecto en programas típicos de JavaScript hace un tiempo y nos dimos cuenta de que, en promedio, los nodos cambian solo una vez cada 20 visitas!
Otra consecuencia de la dificultad para encontrar un buen orden de visita del gráfico es que el seguimiento de estado es difícil y costoso. Muchas optimizaciones requieren rastrear algún estado a lo largo del gráfico, como la eliminación de cargas o el análisis de escape. Sin embargo, esto es difícil de hacer con Sea of Nodes, porque en un momento dado, es difícil saber si un estado determinado necesita mantenerse activo o no, porque es difícil averiguar si los nodos no procesados necesitarían este estado para ser procesados. Como consecuencia de esto, la fase de eliminación de cargas de Turbofan tiene un escape en gráficos grandes para evitar tardar demasiado en terminar y consumir demasiada memoria. En comparación, escribimos una nueva fase de eliminación de cargas para nuestro nuevo compilador CFG, que hemos probado que es hasta 190 veces más rápida (tiene una mejor complejidad en el peor caso, por lo que este tipo de aceleración es fácil de lograr en gráficos grandes), mientras usa mucho menos memoria.
Desafavorabilidad para la caché
Casi todas las fases en Turbofan mutan el gráfico en su lugar. Dado que los nodos ocupan un espacio considerable en memoria (principalmente porque cada nodo tiene punteros tanto a sus entradas como a sus usos), intentamos reutilizar nodos tanto como sea posible. Sin embargo, inevitablemente, cuando reducimos nodos a secuencias de múltiples nodos, tenemos que introducir nuevos nodos, que necesariamente no estarán asignados cerca del nodo original en la memoria. Como resultado, cuanto más profundizamos en el pipeline de Turbofan y más fases ejecutamos, menos amigable para la caché se vuelve el gráfico. Aquí hay una ilustración de este fenómeno:

Es difícil estimar el impacto exacto de esta desfavorabilidad para la caché en la memoria. Aun así, ahora que tenemos nuestro nuevo compilador CFG, podemos comparar el número de fallos de caché entre los dos: Sea of Nodes sufre en promedio aproximadamente 3 veces más fallos de caché L1 dcache en comparación con nuestra nueva IR CFG, y hasta 7 veces más en algunas fases. Estimamos que esto cuesta hasta un 5% del tiempo de compilación, aunque este número no es muy preciso. Aun así, ten en cuenta que en un compilador JIT, compilar rápido es esencial.
La tipificación dependiente del flujo de control es limitada
Consideremos la siguiente función de JavaScript:
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
Si hasta ahora solo hemos visto números enteros pequeños para x y para el resultado de x+1 (donde los "números enteros pequeños" son números enteros de 31 bits, cf. Etiquetado de valores en V8), entonces especularemos que esto seguirá siendo el caso. Si alguna vez vemos que x es mayor que un entero de 31 bits, entonces desoptimizaremos. Del mismo modo, si x+1 produce un resultado mayor de 31 bits, también desoptimizaremos. Esto significa que necesitamos verificar si x+1 es menor o mayor que el valor máximo que cabe en 31 bits. Veamos los gráficos CFG y SoN correspondientes:

(asumiendo una operación CheckedAdd que suma sus entradas y desoptimiza si el resultado sobrepasa los 31 bits)
Con un CFG, es fácil darse cuenta de que cuando se ejecuta CheckedAdd(v1, 1), se garantiza que v1 es menor que 42, y por lo tanto no hay necesidad de verificar el desbordamiento de 31 bits. Así, reemplazaríamos fácilmente el CheckedAdd por un Add regular, que se ejecutaría más rápido y no requeriría un estado de desoptimización (que de otro modo se requiere para saber cómo reanudar la ejecución después de desoptimizar).
Sin embargo, con un gráfico SoN, CheckedAdd, al ser una operación pura, fluirá libremente en el gráfico, y por lo tanto no hay manera de eliminar la verificación hasta que hayamos calculado un programa y decidido que lo calcularemos después de la bifurcación (y en este punto, estamos de vuelta a un CFG, por lo que esto ya no es una optimización de SoN).
Estas operaciones verificadas son frecuentes en V8 debido a esta optimización de enteros pequeños de 31 bits, y la capacidad de reemplazar operaciones verificadas por operaciones no verificadas puede tener un impacto significativo en la calidad del código generado por Turbofan. Entonces, el SoN de Turbofan coloca una entrada de control en CheckedAdd, lo que puede habilitar esta optimización, pero también significa introducir una restricción de programación en un nodo puro, es decir, volver a un CFG.
Y muchos otros problemas…
Propagar la inactividad es difícil. Frecuentemente, durante una reducción, nos damos cuenta de que el nodo actual es realmente inalcanzable. En un CFG, podríamos simplemente cortar el bloque básico actual aquí, y los bloques siguientes se volverían obviamente inalcanzables automáticamente, ya que ya no tendrían predecesores. En el Sea of Nodes, es más difícil, porque uno tiene que parchear tanto la cadena de control como la de efecto. Entonces, cuando un nodo en la cadena de efecto está inactivo, tenemos que avanzar por la cadena de efecto hasta la siguiente fusión, eliminando todo en el camino y manejando cuidadosamente los nodos que están en la cadena de control.
Es difícil introducir un nuevo flujo de control. Debido a que los nodos de flujo de control tienen que estar en la cadena de control, no es posible introducir un nuevo flujo de control durante reducciones regulares. Por lo tanto, si hay un nodo puro en el gráfico, como Int32Max, que devuelve el máximo de 2 enteros y que eventualmente nos gustaría reducir a if (x > y) { x } else { y }, esto no es fácilmente realizable en Sea of Nodes, porque necesitaríamos una manera de averiguar dónde en la cadena de control conectar este subgrafo. Una forma de implementar esto sería poner Int32Max en la cadena de control desde el principio, pero esto parece un desperdicio: el nodo es puro y debería poder moverse libremente. Entonces, la forma canónica de Sea of Nodes para resolver esto, utilizada tanto en Turbofan como por Cliff Click (el inventor de Sea of Nodes), como se menciona en este chat del Coffee Compiler Club, es retrasar este tipo de reducciones hasta que tengamos un cronograma (y por lo tanto un CFG). Como resultado, tenemos una fase alrededor del medio del pipeline que calcula un cronograma y reduce el gráfico, donde se agrupan muchas optimizaciones aleatorias porque todas requieren un cronograma. En comparación, con un CFG, seríamos libres de hacer estas optimizaciones antes o después en el pipeline.
Además, recordemos de la introducción que uno de los problemas de Crankshaft (el predecesor de Turbofan) era que era virtualmente imposible introducir flujo de control después de haber construido el gráfico. Turbofan es una ligera mejora respecto a esto, ya que la reducción de nodos en la cadena de control puede introducir un nuevo flujo de control, pero esto sigue siendo limitado.
Es difícil determinar qué está dentro de un bucle. Debido a que muchos nodos están flotando fuera de la cadena de control, es difícil determinar qué está dentro de cada bucle. Como resultado, optimizaciones básicas como el desdoblamiento y desenrollado de bucles son difíciles de implementar.
Compilar es lento. Esto es una consecuencia directa de múltiples problemas que ya he mencionado: es difícil encontrar un buen orden de visita para los nodos, lo que lleva a muchas revisitas inútiles, el seguimiento de estado es costoso, el uso de memoria es malo, la localidad de caché es mala… Esto podría no ser un gran problema para un compilador adelantado en el tiempo, pero en un compilador JIT, compilar lentamente significa que seguimos ejecutando código lento no optimizado hasta que el código optimizado esté listo, mientras se quitan recursos de otras tareas (por ejemplo, otros trabajos de compilación o el recolector de basura). Una consecuencia de esto es que estamos obligados a pensar muy cuidadosamente sobre la compensación entre el tiempo de compilación y la velocidad de nuevas optimizaciones, frecuentemente inclinándonos hacia el lado de optimizar menos para mantener la rapidez en la optimización.
Sea of Nodes destruye cualquier programación previa, por construcción. El código fuente de JavaScript típicamente no está optimizado manualmente pensando en la microarquitectura de la CPU. Sin embargo, el código WebAssembly puede estarlo, ya sea a nivel de fuente (C++, por ejemplo) o a través de una cadena de herramientas de compilación adelantada en el tiempo (AOT) (como Binaryen/Emscripten). Como resultado, un código WebAssembly podría programarse de manera que debería ser buena en la mayoría de las arquitecturas (por ejemplo, reduciendo la necesidad de volcado, asumiendo 16 registros). Sin embargo, SoN siempre descarta el cronograma inicial y necesita depender únicamente de su propio programador, que, debido a las limitaciones de tiempo de la compilación JIT, puede ser fácilmente peor que lo que un compilador AOT (o un desarrollador de C++ pensando cuidadosamente en la programación de su código) podría hacer. Hemos visto casos donde WebAssembly sufría por esto. Y, desafortunadamente, usar un compilador CFG para WebAssembly y un compilador SoN para JavaScript en Turbofan tampoco era una opción, ya que usar el mismo compilador para ambos habilita la inserción cruzada entre ambos lenguajes.
Sea of Nodes: elegante pero poco práctico para JavaScript
Entonces, para recapitular, aquí están los principales problemas que tenemos con Sea of Nodes y Turbofan:
-
Es demasiado complejo. Las cadenas de efecto y control son difíciles de entender, lo que lleva a muchos errores sutiles. Los gráficos son difíciles de leer y analizar, lo que hace difícil implementar y refinar nuevas optimizaciones.
-
Es demasiado limitado. Demasiados nodos están en la cadena de efecto y control (porque estamos compilando código JavaScript), y por lo tanto no proporciona muchos beneficios en comparación con un CFG tradicional. Además, debido a que es difícil introducir nuevos flujos de control en las reducciones, incluso las optimizaciones básicas terminan siendo difíciles de implementar.
-
La compilación es demasiado lenta. El seguimiento del estado es costoso, porque es difícil encontrar un buen orden para visitar los gráficos. La localidad de caché es mala. Y alcanzar puntos fijos durante las fases de reducción lleva demasiado tiempo.
Entonces, después de diez años lidiando con Turbofan y luchando con Sea of Nodes, finalmente hemos decidido deshacernos de él y volver a un IR CFG más tradicional. Nuestra experiencia con el nuevo IR ha sido extremadamente positiva hasta ahora, y estamos muy contentos de haber vuelto a un CFG: el tiempo de compilación se ha reducido a la mitad en comparación con SoN, el código del compilador es mucho más simple y corto, investigar errores suele ser mucho más fácil, etc. Aun así, esta publicación ya es bastante larga, así que me detendré aquí. Manténganse atentos a un próximo post en el blog que explicará el diseño de nuestro nuevo IR CFG, Turboshaft.