Terre en vue : quitter la mer des nœuds
Le compilateur optimisant de V8, Turbofan, est renommé pour être l’un des rares compilateurs de production à grande échelle à utiliser Sea of Nodes (SoN). Cependant, depuis près de 3 ans, nous avons commencé à nous débarrasser de Sea of Nodes et à revenir à une représentation intermédiaire (IR) plus traditionnelle avec le Control-Flow Graph (CFG), que nous avons nommé Turboshaft. Aujourd’hui, tout le backend JavaScript de Turbofan utilise Turboshaft, et WebAssembly utilise Turboshaft tout au long de son pipeline. Deux parties de Turbofan utilisent encore la mer des nœuds : le pipeline intégré, que nous remplaçons progressivement par Turboshaft, et le frontend du pipeline JavaScript, que nous remplaçons par Maglev, une autre IR basée sur CFG. Ce post explique les raisons qui nous ont poussés à abandonner la mer des nœuds.
Il y a 12 ans, en 2013, V8 avait un seul compilateur optimisant : Crankshaft. Il utilisait une représentation intermédiaire basée sur un graphe de flux de contrôle. La première version de Crankshaft offrait des améliorations significatives au niveau des performances malgré des limitations dans ce qu’il pouvait supporter. Au cours des années suivantes, l’équipe a continué à l’améliorer pour générer un code encore plus rapide dans un nombre croissant de situations. Cependant, les dettes techniques s’accumulaient et plusieurs problèmes majeurs se posaient avec Crankshaft :
-
Il contenait trop de code assembleur écrit à la main. Chaque fois qu’un nouvel opérateur était ajouté à l’IR, sa traduction en assembleur devait être écrite manuellement pour les quatre architectures officiellement prises en charge par V8 (x64, ia32, arm, arm64).
-
Il avait du mal à optimiser asm.js, qui était alors vu comme une étape importante vers le JavaScript haute performance.
-
Il ne permettait pas d'introduire des flux de contrôle dans les réductions. En d’autres termes, le flux de contrôle était créé lors de la construction du graphe et était ensuite final. Cela constituait une limitation majeure, étant donné qu’il est courant en compilation de commencer par des opérations de haut niveau, puis de les réduire à des opérations de bas niveau, souvent en introduisant un flux de contrôle supplémentaire. Prenons par exemple une opération de haut niveau
JSAdd(x,y), cela pourrait avoir du sens de la réduire ensuite en quelque chose commeif (x is String and y is String) { StringAdd(x, y) } else { … }. Eh bien, cela n’était pas possible avec Crankshaft. -
Les blocs try-catch n’étaient pas pris en charge, et les supporter était très difficile : plusieurs ingénieurs avaient passé des mois à essayer de les intégrer, sans succès.
-
Il souffrait de nombreux goulets d’étranglement en performances et abandons. L’utilisation d’une fonctionnalité spécifique ou d’une instruction, ou le fait de tomber sur un cas limite d’une fonctionnalité, pouvait entraîner une chute de performance par un facteur de 100. Cela rendait difficile pour les développeurs JavaScript d’écrire un code efficace et d’anticiper les performances de leurs applications.
-
Il contenait de nombreuses boucles de désoptimisation : Crankshaft optimisait une fonction en utilisant certaines hypothèses spéculatives, puis la fonction était désoptimisée lorsque ces hypothèses ne tenaient pas, mais trop souvent, Crankshaft reoptimisait la fonction avec les mêmes hypothèses, entraînant des boucles infinies d’optimisation-désoptimisation.
Individuellement, chacun de ces problèmes aurait probablement pu être surmonté. Cependant, combinés ensemble, ils semblaient insurmontables. Par conséquent, la décision a été prise de remplacer Crankshaft par un nouveau compilateur entièrement réécrit : Turbofan. Et, plutôt que d’utiliser une IR CFG traditionnelle, Turbofan utiliserait une IR supposément plus puissante : la mer des nœuds. À l’époque, cette IR était déjà utilisée depuis plus de 10 ans dans C2, le compilateur JIT de la Java HotSpot Virtual Machine.
Mais qu’est-ce que la mer des nœuds, en réalité ?
Tout d’abord, un petit rappel concernant les graphes de flux de contrôle (CFG) : un CFG est une représentation d’un programme sous forme de graphe où les nœuds du graphe représentent les blocs de base du programme (c’est-à-dire une séquence d’instructions sans branchements ou sauts entrants ou sortants), et où les arêtes représentent le flux de contrôle du programme. Voici un exemple simple :

Les instructions au sein d'un bloc de base sont implicitement ordonnées : la première instruction doit être exécutée avant la deuxième, et la deuxième avant la troisième, etc. Dans le petit exemple ci-dessus, cela semble très naturel : v1 == 0 ne peut pas être calculé avant que x % 2 ait été calculé de toute façon. Cependant, considérez

Ici, le CFG semble imposer que a * 2 soit calculé avant b * 2, bien que nous pourrions tout à fait les calculer dans l'ordre inverse.
C'est là que le Sea of Nodes intervient : le Sea of Nodes ne représente pas des blocs de base, mais uniquement les dépendances véritables entre les instructions. Les noeuds dans le Sea of Nodes sont des instructions uniques (plutôt que des blocs de base), et les arêtes représentent les utilisations des valeurs (ce qui signifie : une arête allant de a à b représente le fait que a utilise b). Voici donc comment ce dernier exemple serait représenté avec le Sea of Nodes :

Finalement, le compilateur devra générer de l'assembleur et programmer ces deux multiplications de manière séquentielle, mais jusqu'à ce moment-là, il n'y a plus de dépendance entre elles.
Ajoutons maintenant un flux de contrôle dans le mixage. Les noeuds de contrôle (par exemple, branch, goto, return) n'ont généralement pas de dépendances de valeurs entre eux qui imposeraient un programme particulier, bien qu'ils doivent assurément être programmés dans un ordre spécifique. Ainsi, pour représenter le flux de contrôle, nous avons besoin d'un nouveau type d'arête, les arêtes de contrôle, qui imposent un certain ordre sur les noeuds qui n'ont pas de dépendance de valeurs :

Dans cet exemple, sans arêtes de contrôle, rien n'empêcherait les return d'être exécutés avant le branch, ce qui serait évidemment incorrect.
L'élément crucial ici est que les arêtes de contrôle imposent un ordre uniquement sur les opérations qui ont de telles arêtes entrantes ou sortantes, mais pas sur d'autres opérations telles que les opérations arithmétiques. C'est la principale différence entre le Sea of Nodes et les graphes de flux de contrôle.
Ajoutons maintenant dans le mixage des opérations avec effets (par exemple, des chargements et des stockages en mémoire). Similairement aux noeuds de contrôle, les opérations avec effets n'ont souvent pas de dépendances de valeurs, mais elles ne peuvent être exécutées dans un ordre aléatoire. Par exemple, a[0] += 42; x = a[0] et x = a[0]; a[0] += 42 ne sont pas équivalents. Nous avons donc besoin d'un moyen d'imposer un ordre (= un programme) sur les opérations avec effets. Nous pourrions réutiliser la chaîne de contrôle à cet effet, mais cela serait trop strict. Par exemple, considérez ce petit extrait :
let v = a[2];
if (c) {
return v;
}
En mettant a[2] (qui lit la mémoire) sur la chaîne de contrôle, nous forcerions son exécution avant la branche sur c, bien que, en pratique, ce chargement pourrait facilement se produire après la branche si son résultat est utilisé uniquement dans le corps de la branche alors. Avoir beaucoup de noeuds dans le programme sur la chaîne de contrôle vaincrait le but du Sea of Nodes, car nous finirions essentiellement avec un IR de type CFG où seules les opérations pures flottent.
Ainsi, pour profiter de plus de liberté et réellement bénéficier du Sea of Nodes, Turbofan a un autre type d'arête, les arêtes d'effet, qui imposent un certain ordre sur les noeuds ayant des effets secondaires. Ignorons le flux de contrôle pour l'instant et examinons un petit exemple :

Dans cet exemple, arr[0] = 42 et let x = arr[a] n'ont pas de dépendance de valeurs (c'est-à-dire que le premier n'est pas une entrée du second, et vice versa). Cependant, parce que a pourrait être 0, arr[0] = 42 devrait être exécuté avant x = arr[a] afin que ce dernier charge toujours la bonne valeur du tableau.
Notez que bien que Turbofan ait une seule chaîne d'effet (qui se divise sur les branches et fusionne lorsque le flux de contrôle se fusionne) qui est utilisée pour toutes les opérations avec effets, il est possible d'avoir plusieurs chaînes d'effet, où les opérations sans dépendances pourraient être sur des chaînes d'effet différentes, ce qui détendrait la façon dont elles peuvent être programmées (voir Chapitre 10 de SeaOfNodes/Simple pour plus de détails). Cependant, comme nous l'expliquerons plus loin, maintenir une seule chaîne d'effet est déjà très sujet aux erreurs, donc nous n'avons pas tenté dans Turbofan d'en avoir plusieurs.
Et, bien sûr, la plupart des programmes réels contiendront à la fois du flux de contrôle et des opérations avec effets.

Notez que store et load ont besoin d'entrées de contrôle, car elles pourraient être protégées par divers contrôles (comme des contrôles de type ou des contrôles de limites).
Cet exemple illustre bien la puissance de Sea of Nodes par rapport au CFG : y = x * c n'est utilisé que dans la branche else et peut donc flotter librement après le branche, au lieu d'être calculé avant comme dans le code JavaScript original. Il en va de même pour arr[0], qui n'est utilisé que dans la branche else et pourrait flotter après le branche (bien qu'en pratique, Turbofan ne descende pas arr[0], pour des raisons que j'expliquerai plus tard).
Pour comparaison, voici à quoi ressemblerait le CFG correspondant :

Déjà, nous commençons à voir le problème principal du SoN : il est beaucoup plus éloigné à la fois de l’entrée (le code source) et de la sortie (l’assemblage) du compilateur que le CFG, ce qui le rend moins intuitif à comprendre. De plus, avoir des dépendances d'effet et de contrôle toujours explicites rend difficile la compréhension rapide du graphique et la rédaction des abaissements (puisque les abaissements doivent toujours explicitement maintenir la chaîne de contrôle et la chaîne d’effet, qui sont implicites dans un CFG).
Et les problèmes commencent…
Après plus d’une décennie à traiter Sea of Nodes, nous pensons qu’il présente plus d’inconvénients que d’avantages, du moins en ce qui concerne JavaScript et WebAssembly. Nous entrerons dans les détails de certains des problèmes ci-dessous.
Inspecter et comprendre manuellement/visuellement un graphique Sea of Nodes est difficile
Nous avons déjà vu que pour les petits programmes, le CFG est plus facile à lire, car il est plus proche du code source original, ce que les développeurs (y compris les ingénieurs compilateurs!) sont habitués à écrire. Pour les lecteurs non convaincus, permettez-moi de proposer un exemple légèrement plus grand, afin que vous compreniez mieux le problème. Considérez la fonction JavaScript suivante, qui concatène un tableau de chaînes :
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
Voici le graphique Sea of Nodes correspondant, au milieu du pipeline de compilation Turbofan (ce qui signifie que certains abaissements ont déjà eu lieu) :
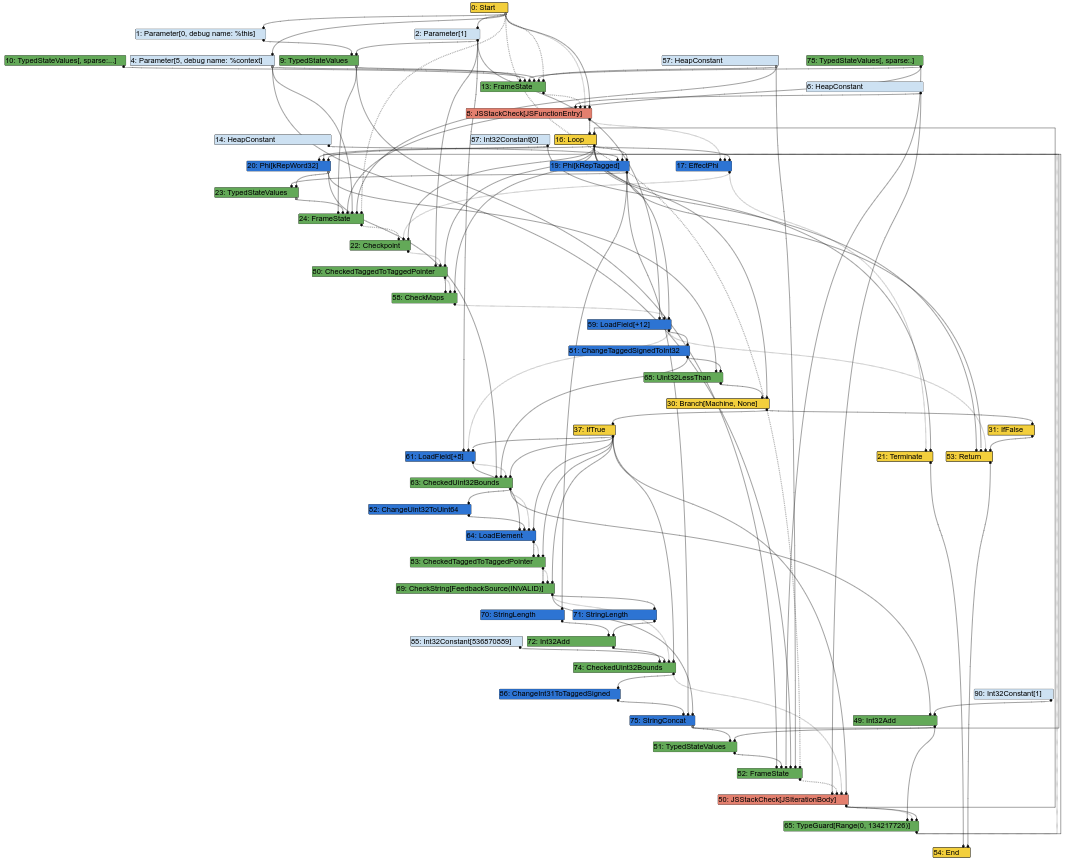
Déjà, cela commence à ressembler à une soupe désordonnée de nœuds. Et, en tant qu’ingénieur compilateur, une grande partie de mon travail consiste à examiner les graphiques Turbofan pour comprendre les bugs ou trouver des opportunités d’optimisation. Eh bien, ce n’est pas facile à faire lorsque le graphique ressemble à cela. Après tout, l’entrée d’un compilateur est le code source, qui ressemble au CFG (les instructions ont toutes une position fixe dans un bloc donné), et la sortie du compilateur est l’assemblage, qui ressemble également au CFG (les instructions ont également une position fixe dans un bloc donné). Avoir un IR similaire au CFG facilite donc aux ingénieurs compilateurs l’association des éléments de l’IR soit avec le source, soit avec l’assemblage généré.
Pour comparaison, voici le graphique CFG correspondant (que nous avons disponible car nous avons déjà commencé le processus de remplacement de Sea of Nodes par CFG) :
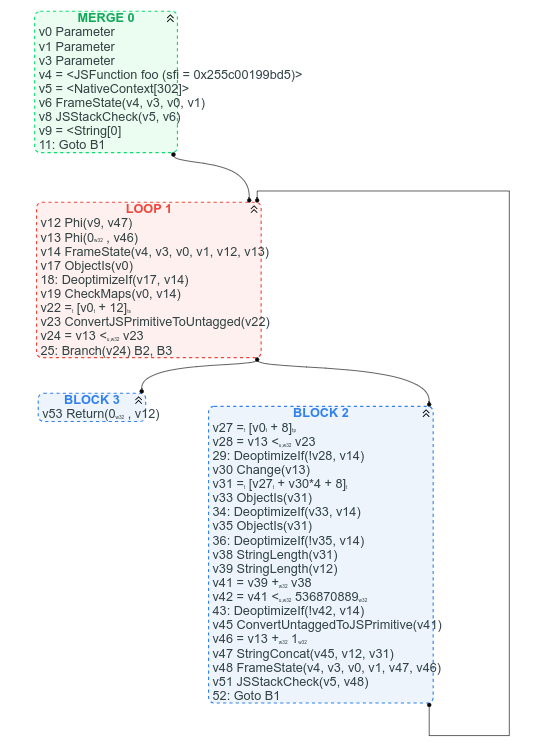
Entre autres choses, avec le CFG, il est clair où se trouve la boucle, il est clair quelle est la condition de sortie de la boucle, et il est facile de trouver certaines instructions dans le CFG en fonction de l’endroit où nous nous attendons à les trouver : par exemple arr.length peut être trouvé dans l’en-tête de boucle (c’est v22 = [v0 + 12]), la concaténation de chaînes peut être trouvée vers la fin de la boucle (v47 StringConcat(...)).
On peut prétendre que les chaînes d’utilisation des valeurs sont plus difficiles à suivre dans la version CFG, mais je dirais que, le plus souvent, il vaut mieux voir clairement la structure de contrôle du graphique plutôt qu’une soupe de nœuds de valeurs.
Trop de nœuds sont sur la chaîne d'effet et/ou ont une entrée de contrôle
Afin de bénéficier de Sea of Nodes, la plupart des nœuds du graphique devraient flotter librement, sans chaîne de contrôle ni effet. Malheureusement, ce n’est pas vraiment le cas dans le graphique JavaScript typique, car presque toutes les opérations JS génériques peuvent avoir des effets secondaires arbitraires. Elles devraient être rares dans Turbofan cependant, puisque nous avons feedback qui devrait permettre de les abaisser à des opérations plus spécifiques.
Néanmoins, chaque opération de mémoire nécessite à la fois une entrée d’effet (puisqu’un Load ne doit pas flotter au-delà des Stores et vice-versa) et une entrée de contrôle (puisqu’il peut y avoir une vérification de type ou une vérification de limite préalable à l’opération). Et même certaines opérations pures comme la division nécessitent des entrées de contrôle parce qu’elles peuvent avoir des cas particuliers protégés par des vérifications.
Prenons un exemple concret et partons de la fonction JavaScript suivante :
function foo(a, b) {
// en supposant que `a.str` et `b.str` sont des chaînes
return a.str + b.str;
}
Voici le graphique Turbofan correspondant. Pour plus de clarté, j’ai mis en évidence une partie de la chaîne d’effet avec des lignes rouges en pointillés et annoté quelques nœuds avec des numéros afin de pouvoir en discuter ci-dessous.
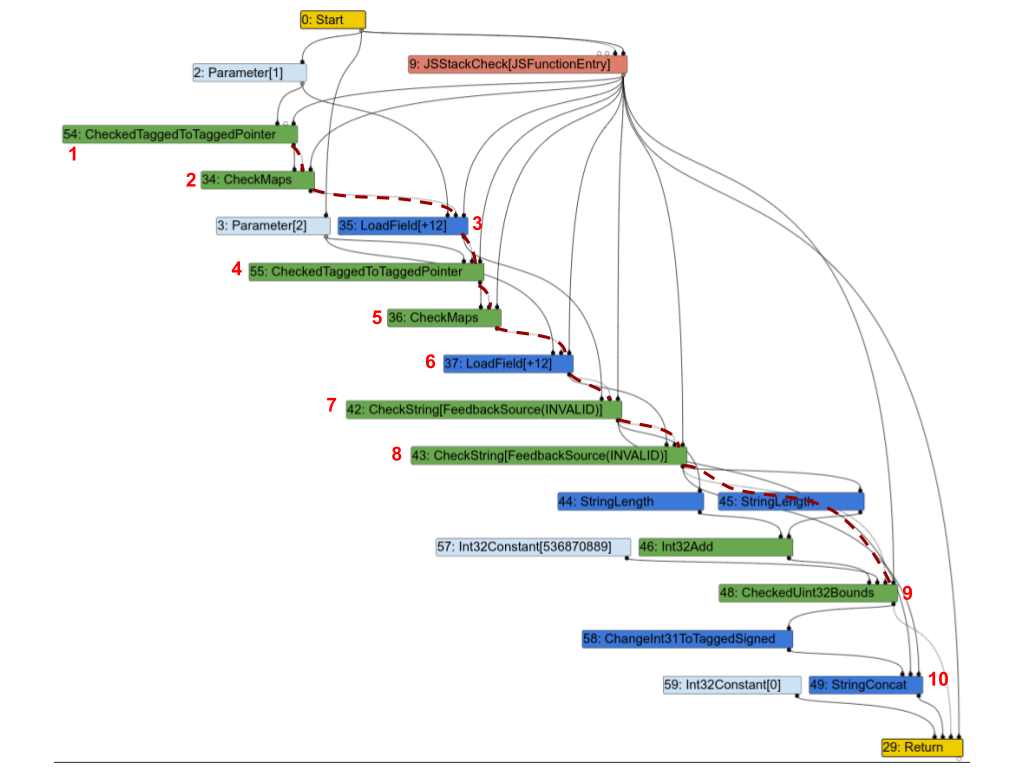
La première observation est que presque tous les nœuds sont sur la chaîne d'effet. Passons en revue quelques-uns d’entre eux et examinons s’ils en ont vraiment besoin :
1(CheckedTaggedToTaggedPointer): ceci vérifie que le premier argument de la fonction est un pointeur et non un “petit entier” (voir Compression des pointeurs dans V8). À lui tout seul, il n'aurait pas vraiment besoin d'une entrée d'effet, mais en pratique, il doit tout de même être dans la chaîne d'effet car il protège les nœuds suivants.2(CheckMaps): maintenant que nous savons que le premier argument est un pointeur, ce nœud charge sa “map” (voir Maps (Hidden Classes) dans V8), et vérifie qu'elle correspond aux informations enregistrées pour cet objet.3(LoadField): maintenant que nous savons que le premier objet est un pointeur avec la map correcte, nous pouvons charger son champ.str.4,5et6: répétition pour le second argument.7(CheckString): maintenant que nous avons chargéa.str, ce nœud vérifie que c'est bien une chaîne de caractères.8: répétition pour le second argument.9: vérifie que la longueur combinée dea.stretb.strest inférieure à la taille maximale d'une chaîne en V8.10(StringConcat): concatène enfin les 2 chaînes.
Ce graphe est très caractéristique des graphes Turbofan pour les programmes JavaScript : vérification des maps, chargement des valeurs, vérification des maps des valeurs chargées, et ainsi de suite, pour finalement effectuer quelques calculs sur ces valeurs. Et comme dans cet exemple, dans de nombreux cas, la majorité des instructions se retrouvent dans la chaîne d'effet ou de contrôle, ce qui impose un ordre strict sur les opérations et va à l'encontre de l'objectif du Sea of Nodes.
Les opérations mémoire ne flottent pas facilement
Considérons le programme JavaScript suivant :
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
Étant donné que x et y sont chacun utilisés uniquement dans un seul côté du if-else, on pourrait espérer que le SoN leur permette de se déplacer librement à l’intérieur du “then” et du “else”. Cependant, en pratique, réaliser cela dans SoN ne serait pas plus simple que dans un CFG. Observons le graphe SoN pour comprendre pourquoi :

Lorsque nous construisons le graphe SoN, nous créons la chaîne d'effet au fur et à mesure, et ainsi le deuxième Load finit par se retrouver juste après le premier, après quoi la chaîne d'effet doit se diviser pour atteindre les deux return (si vous vous demandez pourquoi les return sont même sur la chaîne d'effet, c'est parce qu'il pourrait y avoir des opérations avec effets de bord avant, comme des Store, qui doivent être exécutés avant de retourner de la fonction). Étant donné que le deuxième Load est un prédécesseur de deux return, il doit être planifié avant le branch, et SoN ne permet donc pas à l'un des deux Load de descendre librement.
Pour déplacer les Load vers les branches “then” et “else”, il faudrait calculer qu'il n'y a aucun effet de bord entre eux et qu'il n'y en a pas non plus entre le deuxième Load et les return, ensuite nous pourrions scinder la chaîne d'effet au début au lieu de le faire après le deuxième Load. Faire cette analyse sur un graphe SoN ou un CFG est extrêmement similaire.
Maintenant que nous avons mentionné qu’un grand nombre de nœuds finissent sur la chaîne d’effet, et que les nœuds à effets ne flottent souvent pas très loin, il est temps de réaliser que d’une certaine manière, SoN n’est qu’un CFG où les nœuds purs flottent. En effet, en pratique, les nœuds de contrôle et la chaîne de contrôle reflètent toujours la structure du CFG équivalent. Et, lorsque les deux destinations d’un branchement ont des effets (ce qui est fréquent en JavaScript), la chaîne d’effet se divise et fusionne exactement là où la chaîne de contrôle le fait (comme dans l’exemple ci-dessus : la chaîne de contrôle se divise sur le branch, et la chaîne d’effet reflète cela en se divisant sur le Load ; et si le programme continuait après le if-else, les deux chaînes fusionneraient approximativement au même endroit). Les nœuds à effets sont donc généralement contraints d’être planifiés entre deux nœuds de contrôle, c’est-à-dire dans un bloc basique. Et à l’intérieur de ce bloc basique, la chaîne d’effet contraindra les nœuds à effets à être dans le même ordre que dans le code source. En fin de compte, seuls les nœuds purs flottent réellement librement.
Une manière d’obtenir plus de nœuds flottants est d’utiliser plusieurs chaînes d’effet, comme mentionné précédemment, mais cela a un coût : d’abord, gérer une seule chaîne d’effet est déjà difficile ; en gérer plusieurs sera beaucoup plus complexe. Ensuite, dans un langage dynamique comme JavaScript, nous finissons avec de nombreux accès mémoire qui pourraient être en conflit, ce qui signifie que les multiples chaînes d’effet devraient toutes fusionner très fréquemment, annulant ainsi en partie les avantages d’avoir plusieurs chaînes d’effet.
Gérer manuellement les chaînes d’effet et de contrôle est difficile
Comme mentionné dans la section précédente, bien que la chaîne d’effet et la chaîne de contrôle soient quelque peu distinctes, en pratique, la chaîne d’effet a généralement la même “forme” que la chaîne de contrôle : si les destinations d’un branchement contiennent des opérations à effets (ce qui est souvent le cas), alors la chaîne d’effet se divisera sur le branchement et fusionnera une fois que le flux de contrôle sera de retour. Parce que nous traitons avec JavaScript, de nombreux nœuds ont des effets de bord, et nous avons de nombreuses branches (généralement en bifurquant sur le type de certains objets), ce qui nous oblige à suivre à la fois la chaîne des effets et celle du contrôle en parallèle, alors qu'avec un CFG, nous n'aurions qu'à suivre la chaîne de contrôle.
L'histoire a montré que gérer à la fois les chaînes d'effets et de contrôle manuellement est sujet à des erreurs, difficile à lire et à maintenir. Voici un exemple de code de la phase JSNativeContextSpecialization :
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effect effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effect this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
En raison des diverses branches et cas à gérer ici, nous nous retrouvons à gérer 3 chaînes d'effets différentes. Il est facile de se tromper et d'utiliser une chaîne d'effets au lieu d'une autre. C'est tellement facile que nous nous sommes effectivement trompés initialement, et nous nous en sommes rendu compte seulement après quelques mois :

Pour ce problème, je blâmerais à la fois Turbofan et Sea of Nodes, plutôt que seulement ce dernier. De meilleurs outils dans Turbofan auraient pu simplifier la gestion des chaînes d'effets et de contrôle, mais cela n'aurait pas été un problème dans un CFG.
Le planificateur est trop complexe
Finalement, toutes les instructions doivent être planifiées afin de générer du code d'assemblage. La théorie pour planifier les instructions est assez simple : chaque instruction doit être programmée après ses entrées de valeur, de contrôle et d'effet (en ignorant les boucles).
Prenons un exemple intéressant :

Vous remarquerez que, bien que le programme JavaScript source contienne deux divisions identiques, le graphe Sea of Nodes n'en a qu'une. En réalité, Sea of Nodes commencerait avec deux divisions, mais comme cette opération est pure (en supposant des entrées de type double), l'élimination des redondances les dédupliquerait facilement en une seule.
Puis, lorsque l'on atteint la phase de planification, il faudrait trouver un endroit pour planifier cette division. Clairement, elle ne peut pas être placée après case 1 ou case 2, car elle est utilisée dans l'autre. Au lieu de cela, elle devrait être planifiée avant le switch. L'inconvénient est que, maintenant, a / b sera calculé même lorsque c vaut 3, où il n'est pas nécessaire qu'il soit calculé. C'est un véritable problème qui peut entraîner de nombreuses instructions dédupliquées flottant jusqu'au dominateur commun de leurs utilisateurs, ralentissant de nombreux chemins où elles ne sont pas nécessaires.
Il existe toutefois une solution : le planificateur de Turbofan tentera d'identifier ces cas et de dupliquer les instructions afin qu'elles ne soient calculées que sur les chemins qui en ont besoin. L'inconvénient est que cela rend le planificateur plus complexe, nécessitant une logique supplémentaire pour déterminer quels nœuds pourraient et devraient être dupliqués, et comment les dupliquer.
Ainsi, en gros, nous avons commencé avec 2 divisions, puis "optimisé" à une seule division, puis davantage optimisé à nouveau à 2 divisions. Et cela ne se limite pas aux divisions : beaucoup d'autres opérations passent par des cycles similaires.
Trouver un bon ordre pour visiter le graphe est difficile
Tous les passages d'un compilateur doivent visiter le graphe, que ce soit pour abaisser les nœuds, appliquer des optimisations locales ou effectuer une analyse sur l'ensemble du graphe. Dans un CFG, l'ordre dans lequel il faut visiter les nœuds est généralement simple : commencer par le premier bloc (en supposant une fonction à entrée unique), et itérer à travers chaque nœud du bloc, puis passer aux successeurs et ainsi de suite. Dans une phase d'optimisation de fenêtre (comme la réduction de force), une propriété intéressante du traitement du graphe dans cet ordre est que les entrées sont toujours optimisées avant qu'un nœud ne soit traité, et visiter chaque nœud une seule fois est donc suffisant pour appliquer la plupart des optimisations de fenêtre. Prenons par exemple la séquence de réductions suivante :

Au total, il a fallu trois étapes pour optimiser toute la séquence, et chaque étape a fait un travail utile. Après quoi, l'élimination du code mort supprimerait v1 et v2, aboutissant à une instruction de moins que dans la séquence initiale.
Avec Sea of Nodes, il n'est pas possible de traiter les instructions pures de bout en bout, car elles ne font partie d'aucune chaîne de contrôle ou d'effet, et il n'y a donc pas de pointeur vers des racines pures ou quelque chose de ce genre. Au lieu de cela, la manière habituelle de traiter un graphe Sea of Nodes pour les optimisations de type peephole est de commencer par la fin (par exemple, les instructions return) et de remonter les entrées de valeur, d'effet et de contrôle. Cela a la propriété intéressante de ne visiter aucune instruction inutilisée, mais les avantages s'arrêtent là, car pour les optimisations de type peephole, c'est à peu près le pire ordre de visite possible. Dans l'exemple ci-dessus, voici les étapes que nous prendrions :
- Commencer par visiter
v3, mais ne peut pas le réduire à ce stade, puis passer à ses entrées- Visiter
v1, le réduire àa << 3, puis passer à ses utilisations, au cas où la réduction dev1permettrait de les optimiser.- Visiter
v3à nouveau, mais ne peut pas le réduire encore (cette fois, nous ne visiterions pas ses entrées à nouveau cependant)
- Visiter
- Visiter
v2, le réduire àb << 3, puis passer à ses utilisations, au cas où cette réduction permettrait de les optimiser.- Visiter
v3à nouveau, le réduire à(a & b) << 3.
- Visiter
- Visiter
Donc, au total, v3 a été visité 3 fois mais n'a été réduit qu'une seule fois.
Nous avons mesuré cet effet sur des programmes JavaScript typiques il y a quelque temps et réalisé qu'en moyenne, les nœuds sont modifiés seulement une fois toutes les 20 visites!
Une autre conséquence de la difficulté à trouver un bon ordre de visite du graphe est que le suivi de l'état est difficile et coûteux. Beaucoup d'optimisations nécessitent de suivre un état le long du graphe, comme l'élimination de charge ou l'analyse d'échappement. Cependant, cela est difficile à faire avec Sea of Nodes, car à un moment donné, il est difficile de savoir si un état donné doit être maintenu ou non, car il est difficile de déterminer si des nœuds non traités auraient besoin de cet état pour être traités. En conséquence, la phase d'élimination de charge de Turbofan a un mécanisme de secours pour les grands graphes afin d'éviter de prendre trop de temps pour finir et de consommer trop de mémoire. En comparaison, nous avons écrit une nouvelle phase d'élimination de charge pour notre nouveau compilateur CFG, que nous avons référencée jusqu'à 190 fois plus rapide (elle a une meilleure complexité dans le pire des cas, donc ce type d'accélération est facile à atteindre sur de grands graphes), tout en utilisant beaucoup moins de mémoire.
Cache non convivial
Presque toutes les phases de Turbofan mutent le graphe en place. Étant donné que les nœuds sont assez grands en mémoire (principalement parce que chaque nœud a des pointeurs vers ses entrées et ses utilisations), nous essayons de réutiliser les nœuds autant que possible. Cependant, inévitablement, lorsque nous réduisons les nœuds en séquences de plusieurs nœuds, nous devons introduire de nouveaux nœuds, qui ne seront nécessairement pas alloués près du nœud d'origine en mémoire. En conséquence, plus nous avançons dans le pipeline de Turbofan et plus nous exécutons de phases, moins le graphe est convivial pour le cache. Voici une illustration de ce phénomène :

Il est difficile d'estimer l'impact exact de cette non-convivialité pour le cache sur la mémoire. Pourtant, maintenant que nous avons notre nouveau compilateur CFG, nous pouvons comparer le nombre de manques de cache entre les deux : Sea of Nodes souffre en moyenne de trois fois plus de manques de cache L1 dcache par rapport à notre nouvelle IR CFG, et jusqu'à sept fois plus dans certaines phases. Nous estimons que cela coûte jusqu'à 5 % du temps de compilation, bien que ce chiffre soit un peu approximatif. Cependant, gardez à l'esprit que dans un compilateur JIT, compiler rapidement est essentiel.
Typage dépendant du flux de contrôle limité
Considérons la fonction JavaScript suivante :
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
Si jusqu'à présent nous n'avons vu que de petits entiers pour x et pour le résultat de x+1 (où « petits entiers » sont des entiers de 31 bits, cf. Value tagging in V8), alors nous spéculerons que cela restera le cas. Si jamais nous voyons x être plus grand qu'un entier de 31 bits, alors nous allons déoptimiser. De même, si x+1 produit un résultat plus grand que 31 bits, nous allons également déoptimiser. Cela signifie que nous devons vérifier si x+1 est inférieur ou supérieur à la valeur maximale qui s'adapte à 31 bits. Examinons les graphes CFG et SoN correspondants :

(en supposant une opération CheckedAdd qui ajoute ses entrées et déoptimise si le résultat dépasse 31 bits)
Avec un CFG, il est facile de comprendre que lorsque CheckedAdd(v1, 1) est exécuté, v1 est garanti d'être inférieur à 42, et qu'il n'y a donc pas besoin de vérifier un dépassement de 31 bits. Nous remplacerions ainsi facilement le CheckedAdd par un Add ordinaire, qui s'exécuterait plus rapidement et ne nécessiterait pas un état de déoptimisation (qui est autrement nécessaire pour savoir comment reprendre l'exécution après une déoptimisation).
Cependant, avec un graphe SoN, CheckedAdd, étant une opération pure, circulera librement dans le graphe, et il n'est donc pas possible de supprimer la vérification jusqu'à ce que nous ayons calculé un plan et décidé qu'il sera calculé après la branche (et à ce stade, nous sommes de retour à un CFG, alors ce n'est plus une optimisation SoN).
Ces opérations vérifiées sont fréquentes dans V8 en raison de cette optimisation des petits entiers sur 31 bits, et la capacité de remplacer des opérations vérifiées par des opérations non vérifiées peut avoir un impact significatif sur la qualité du code généré par Turbofan. Ainsi, le SoN de Turbofan ajoute une entrée de contrôle sur CheckedAdd, qui peut permettre cette optimisation, mais cela implique également de réintroduire une contrainte d'ordonnancement sur un nœud pur, autrement dit, revenir à un CFG.
Et de nombreux autres problèmes…
Propager l’inaccessibilité est difficile. Fréquemment, lors de certaines transformations, nous réalisons que le nœud actuel est en réalité inaccessible. Dans un CFG, nous pourrions simplement couper ici le bloc de base actuel, et les blocs suivants deviendraient automatiquement évidemment inaccessibles puisqu'ils n’auraient plus de prédécesseurs. Dans Sea of Nodes, c’est plus difficile, car il faut patcher à la fois la chaîne de contrôle et la chaîne d’effets. Ainsi, quand un nœud sur la chaîne d’effets est mort, nous devons avancer dans la chaîne d’effets jusqu’à la prochaine fusion, en tuant tout sur le chemin et en manipulant soigneusement les nœuds qui sont sur la chaîne de contrôle.
Il est difficile d’introduire un nouveau flux de contrôle. Parce que les nœuds de flux de contrôle doivent être sur la chaîne de contrôle, il est impossible d’introduire un nouveau flux de contrôle lors des transformations régulières. Ainsi, si un nœud pur dans le graphe, tel que Int32Max, qui retourne le maximum de deux entiers et que nous aimerions éventuellement transformer en if (x > y) { x } else { y }, cela n’est pas facilement réalisable dans Sea of Nodes, car nous aurions besoin d’un moyen de déterminer où brancher ce sous-graphe sur la chaîne de contrôle. Une manière d’implémenter cela serait de placer Int32Max sur la chaîne de contrôle dès le début, mais cela semble gaspilleur : le nœud est pur et devrait être autorisé à se déplacer librement. Ainsi, la façon canonique de Sea of Nodes pour résoudre ceci, utilisée à la fois dans Turbofan et également par Cliff Click (l’inventeur de Sea of Nodes), comme mentionné dans cette discussion du Coffee Compiler Club, est de retarder ce type de transformations jusqu’à ce que nous ayons un ordonnancement (et donc un CFG). En conséquence, nous avons une phase au milieu du pipeline qui calcule un ordonnancement et modifie le graphe, où beaucoup d’optimisations aléatoires sont regroupées parce qu’elles nécessitent toutes un ordonnancement. En comparaison, avec un CFG, nous serions libres de faire ces optimisations plus tôt ou plus tard dans le pipeline.
De plus, rappelez-vous de l’introduction que l’un des problèmes de Crankshaft (le prédécesseur de Turbofan) était qu’il était pratiquement impossible d’introduire un flux de contrôle après avoir construit le graphe. Turbofan est une légère amélioration par rapport à cela, puisque les transformations des nœuds sur la chaîne de contrôle peuvent introduire un nouveau flux de contrôle, mais cela reste limité.
Il est difficile de déterminer ce qui est à l’intérieur d’une boucle. Parce que de nombreux nœuds flottent à l’extérieur de la chaîne de contrôle, il est difficile de déterminer ce qui est à l’intérieur de chaque boucle. En conséquence, des optimisations basiques telles que le dépliage et le déroulement des boucles sont difficiles à implémenter.
La compilation est lente. C’est une conséquence directe de plusieurs problèmes que j’ai déjà mentionnés : il est difficile de trouver un bon ordre de visite pour les nœuds, ce qui conduit à de nombreuses revisites inutiles, le suivi de l’état est coûteux, l’utilisation de la mémoire est mauvaise, la localité de cache est mauvaise… Cela pourrait ne pas être un gros problème pour un compilateur anticipé, mais dans un compilateur JIT, une compilation lente signifie que nous continuons à exécuter du code lent non optimisé jusqu’à ce que le code optimisé soit prêt, tout en prenant des ressources à d’autres tâches (par exemple, autres tâches de compilation ou le ramasse-miettes). Une conséquence de cela est que nous sommes obligés de réfléchir très soigneusement au compromis entre le temps de compilation et l’accélération des nouvelles optimisations, souvent en choisissant de moins optimiser pour maintenir une optimisation rapide.
Sea of Nodes détruit tout ordonnancement préalable, par construction. Le code source JavaScript n’est généralement pas optimisé manuellement en tenant compte de la microarchitecture du processeur. Cependant, le code WebAssembly peut l’être, soit au niveau source (par exemple en C++), soit par une chaîne d’outils de compilation anticipée (AOT) (comme Binaryen/Emscripten). En conséquence, un code WebAssembly pourrait être ordonnancé de manière à être bon sur la plupart des architectures (par exemple, en réduisant le besoin de spilling, en supposant 16 registres). Cependant, SoN rejette toujours l’ordonnancement initial et doit uniquement s’appuyer sur son propre ordonnanceur, qui, en raison des contraintes de temps de la compilation JIT, peut facilement être pire que ce qu’un compilateur AOT (ou un développeur C++ réfléchissant soigneusement à l’ordonnancement de leur code) pourrait produire. Nous avons vu des cas où WebAssembly souffrait de cela. Et, malheureusement, utiliser un compilateur CFG pour WebAssembly et un compilateur SoN pour JavaScript dans Turbofan n’était pas non plus une option, car utiliser le même compilateur pour les deux permet l’inlining entre les deux langages.
Sea of Nodes : élégant mais peu pratique pour JavaScript
Ainsi, pour récapituler, voici les principaux problèmes que nous rencontrons avec Sea of Nodes et Turbofan :
-
C’est trop complexe. Les chaînes d'effets et de contrôles sont difficiles à comprendre, ce qui entraîne de nombreux bugs subtils. Les graphes sont difficiles à lire et à analyser, rendant les nouvelles optimisations difficiles à mettre en œuvre et à affiner.
-
C’est trop limité. Trop de nœuds sont sur la chaîne d'effets et de contrôles (puisque nous compilons du code JavaScript), ce qui ne procure pas beaucoup d'avantages par rapport à un CFG traditionnel. De plus, comme il est difficile d'introduire un nouveau flux de contrôle dans les abaissements, même des optimisations de base deviennent difficiles à implémenter.
-
La compilation est trop lente. Le suivi de l'état est coûteux, car il est difficile de trouver un bon ordre pour parcourir les graphes. La localité du cache est mauvaise. Et atteindre des points fixes durant les phases de réduction prend trop de temps.
Ainsi, après dix ans à travailler avec Turbofan et à combattre la mer de nœuds, nous avons finalement décidé de nous en débarrasser, et de revenir à un IR CFG plus traditionnel. Notre expérience avec notre nouveau IR a été extrêmement positive jusqu'à présent, et nous sommes très heureux d'être revenus à un CFG : le temps de compilation a été divisé par 2 par rapport à SoN, le code du compilateur est beaucoup plus simple et court, enquêter sur les bugs est généralement beaucoup plus facile, etc. Cela dit, ce post est déjà assez long, donc je vais m'arrêter ici. Restez à l'écoute pour un prochain article de blog qui expliquera la conception de notre nouveau IR CFG, Turboshaft.