陸地が見えた:Sea of Nodesを離れて
V8の最上位最適化コンパイラTurbofanは、Sea of Nodes (SoN)を使用する数少ない大規模プロダクションコンパイラの1つとして知られています。しかし、約3年前からSea of Nodesを廃止し、より伝統的な制御フローグラフ (CFG) 中間表現 (IR)に戻りました。それをTurboshaftと名付けました。現在では、TurbofanのJavaScriptバックエンド全体がTurboshaftを使用しており、WebAssemblyはその全パイプラインを通じてTurboshaftを使用しています。Turbofanの2つの部分ではまだSea of Nodesが一部使用されています。1つは組み込みパイプラインで、これをTurboshaftに置き換えつつあります。もう1つはJavaScriptパイプラインのフロントエンドで、これをMaglevという別のCFGベースのIRに置き換えています。このブログ記事では、Sea of Nodesを廃止することになった理由を説明します。
12年前の2013年、V8には単一の最適化コンパイラであるCrankshaftがありました。これは制御フローグラフベースの中間表現を使用していました。Crankshaftの最初のバージョンは、サポートする機能がまだ制限されていたにもかかわらず、大幅なパフォーマンスの向上を提供しました。その後数年間、チームはそれを改良し、ますます多くの状況でさらに高速なコードを生成できるようにしました。しかし、技術的負債が蓄積し、いくつかの問題が発生してきました:
-
手書きのアセンブリコードが多すぎました。新しいオペレーターがIRに追加されるたびに、そのアセンブリへの翻訳をV8が公式にサポートする4つのアーキテクチャ(x64、ia32、arm、arm64)向けに手動で書く必要がありました。
-
asm.js の最適化に苦労していました。当時、asm.jsは高性能なJavaScriptへの重要なステップと見なされていました。
-
ローリングで制御フローを導入することができませんでした。つまり、制御フローはグラフ作成時に生成され、それが確定していました。コンパイラを作る際によく行われるのは、高レベルの操作から始め、それを制御フローを追加することで低レベルの操作に変換(ローリング)することです。例えば、高レベルの操作
JSAdd(x,y)を考えてみてください。後にこれをif (x is String and y is String) { StringAdd(x, y) } else { … }のように低レベルに落とし込むのは意味があります。しかし、Crankshaftではこれは不可能でした。 -
Try-catch構文がサポートされておらず、それをサポートするのは非常に困難でした。複数のエンジニアが何ヶ月もの間Try-catchのサポートに取り組みましたが、成功しませんでした。
-
多くのパフォーマンスの急激な低下や脱落が発生しました。特定の機能や命令を使用したり、機能の特定のエッジケースに遭遇したりすると、パフォーマンスが100倍低下する場合がありました。これにより、JavaScript開発者が効率的なコードを書くのが難しくなり、アプリケーションのパフォーマンスを予測するのも困難になりました。
-
多くの再最適化ループが含まれていました:Crankshaftは投機的な仮定を使用して関数を最適化し、その仮定が成り立たないと関数が非最適化されましたが、あまりにも頻繁に同じ仮定で再最適化され、無限の最適化と非最適化のループが発生していました。
これらの問題を個別に見れば、それぞれを克服することはおそらく可能だったでしょう。しかし、これらの問題が組み合わさると、負担が大きすぎるように思われました。そこで、Crankshaftをスクラッチから書き直した新しいコンパイラTurbofanに置き換えるという決定が下されました。そして、従来のCFG IRではなく、当時C2(Java HotSpot Virtual MachineのJITコンパイラ)で10年以上使われていたとされる、より強力なIRであるSea of Nodesを使用することにしました。
さて、Sea of Nodesとは何か?
まず、制御フローグラフ(CFG)について簡単におさらいしましょう。CFGは、プログラムをグラフとして表現するもので、グラフのノードはプログラムの基本ブロック(すなわち、分岐やジャンプのない命令のシーケンス)を表し、エッジはプログラムの制御フローを表します。以下は簡単な例です:

基本ブロック内の命令は暗黙的に順序付けされています:最初の命令は2番目の命令の前に実行されるべきであり、2番目の命令は3番目の命令の前に実行されるべきです。上記の小さな例では、非常に自然に感じられます:v1 == 0 は、x % 2 が計算される前に計算することは不可能です。しかし、

ここでは、CFGは一見するとa * 2がb * 2よりも先に計算されることを課しているように見えますが、逆の順序で計算することも可能です。
ここでSea of Nodesが登場します:Sea of Nodesは基本ブロックを表現するのではなく、命令間の真の依存関係のみを表します。Sea of Nodesのノードは基本ブロックではなく単一の命令であり、エッジは値の使用を表します(意味:aからbへのエッジは、aがbを使用する事実を表します)。したがって、この最後の例はSea of Nodesで以下のように表現されます:

最終的に、コンパイラはアセンブリを生成し、これら2つの乗算を順序付けてスケジュールする必要がありますが、それまではそれらの間に依存関係はありません。
では、制御フローを追加してみましょう。制御ノード(例:branch、goto、return)には、特定のスケジュールを強制する値依存関係が通常ありませんが、特定の順序でスケジュールされる必要があります。そのため、制御フローを表すためには、新しい種類のエッジ、制御エッジが必要です。これは、値の依存関係を持たないノードに順序を課します:

この例では、制御エッジがなければ、branchの前にreturnが実行されるのを防ぐものは何もないため、明らかにこれは間違いです。
ここで重要な点は、制御エッジは、それらの入出力エッジを持つ操作の順序を強制するだけであり、算術操作のような他の操作には順序を強制しないということです。これがSea of Nodesと制御フローグラフの主な違いです。
次に、副作用のある操作(例えば、メモリからのロードとストア)を追加してみましょう。制御ノードと同様に、副作用のある操作は値依存関係を持たないことがよくありますが、ランダムな順序で実行することはできません。例えば、a[0] += 42; x = a[0]とx = a[0]; a[0] += 42は同等ではありません。そのため、副作用のある操作に順序(=スケジュール)を課す方法が必要です。この目的のために制御チェーンを再利用することもできますが、これは必要以上に厳密になります。例えば、以下の小さなスニペットを考えてみましょう:
let v = a[2];
if (c) {
return v;
}
a[2](メモリを読み込む)が制御チェーン上に載ると、cの分岐より前に実行されることを強制されますが、実際には、このロードがthen分岐の内部でのみ使用される場合、その結果を後で実行することも簡単に可能です。制御チェーン上にプログラムのノードを大量に置くと、Sea of Nodesの目的を損なうことになり、基本的にCFG風のIRが得られ、純粋な操作だけが浮遊することになります。
そのため、より自由度を享受し、実際にSea of Nodesの恩恵を受けるために、Turbofanにはもう一つの種類のエッジ、効果エッジがあります。これは副作用のあるノードに順序を課します。制御フローは一旦無視して、小さな例を見てみましょう:

この例では、arr[0] = 42とlet x = arr[a]には値依存関係がありません(つまり、前者は後者の入力ではなく、その逆も同様です)。しかし、aが0である可能性があるため、常に正しい値を配列からロードするためには、arr[0] = 42をx = arr[a]の前に実行する必要があります。
注:Turbofanでは効果操作に対して単一の効果チェーン(分岐で分割され、制御フローが統合されると再び統合される)が使用されますが、複数の効果チェーンを持つことも可能です。依存関係のない操作が異なる効果チェーンに存在し、スケジュールの緩和が可能になるためです(詳細はSeaOfNodes/Simpleの第10章を参照してください)。ただし、後述するように、単一の効果チェーンを維持すること自体が非常にエラープロンであるため、Turbofanでは複数の効果チェーンを試みていません。
もちろん、ほとんどの実際のプログラムは、制御フローと副作用のある操作の両方を含みます。

storeとloadには制御入力が必要です。これらは型チェックや境界チェックなど、さまざまなチェックによって保護される可能性があるためです。
Sea of Nodesの力がCFGと比べていかに強力であるかを示す良い例です:y = x * cはelse分岐でのみ使用されるため、元のJavaScriptコードで記述された前に計算されるのではなく、branch後に自由に移動することができます。同様に、arr[0]もelse分岐でのみ使用されるため、branch後に移動することが可能です(ただし、実際にはTurbofanはある理由によりarr[0]を下に移動させることはありません。それについては後で説明します)。
比較のため、対応するCFGの外観を以下に示します。

すでに、SoNの主な問題が見え始めています:CFGよりもコンパイラの入力(ソースコード)や出力(アセンブリ)からはるかに遠く、直感的に理解するのが難しくなっています。さらに、効果と制御の依存関係が常に明示的に表示されるため、グラフについて迅速に推論したり、降下処理を書いたりするのが難しくなります(降下処理では、CFGでは暗黙的である制御と効果のチェーンを明示的に維持する必要があります)。
問題はここから始まります…
Sea of Nodesを10年以上扱った後で分かったのは、JavaScriptやWebAssemblyに関しては、利点よりも欠点のほうが多いということです。以下にその問題点の詳細を説明します。
Sea of Nodesグラフを手動/視覚的に検査して理解するのが困難
小規模なプログラムにおいて、CFGのほうが読みやすいことはすでに述べました。なぜなら、それがオリジナルのソースコードに近いからです。そして、それは開発者(コンパイラエンジニアを含む!)が普段書いているものです。まだ納得していない読者のために、もう少し大きな例を示します。それによって問題をより深く理解できるでしょう。以下のJavaScript関数を考えてみてください。これは文字列の配列を連結します:
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
以下はTurbofanコンパイラのパイプライン中間段階での対応するSea of Nodeグラフです(一部の降下処理がすでに実行されています):
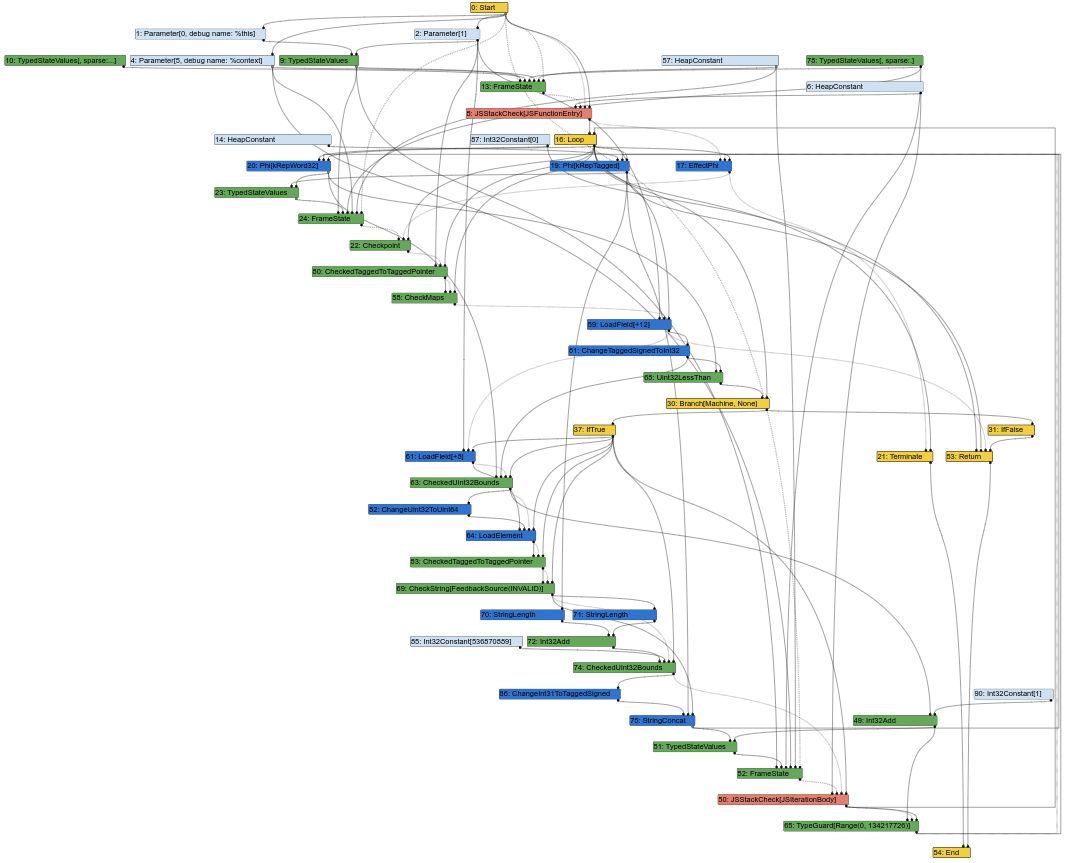
すでにノードの乱雑なスープのように見え始めています。そして、コンパイラエンジニアとしての私の仕事の大部分は、Turbofanのグラフを調べてバグを理解したり、最適化の可能性を見つけたりすることです。このようなグラフではそれを行うのは簡単ではありません。結局、コンパイラの入力はソースコードであり、それはCFGのよう(命令はブロック内の特定の位置に固定されている)であり、コンパイラの出力はアセンブリであり、これもまたCFGのよう(命令はブロック内の特定の位置に固定されている)です。CFGに似たIRを持つことで、コンパイラエンジニアがIRの要素をソースコードや生成されたアセンブリのいずれかに照合するのが容易になります。
比較対象として、対応するCFGグラフを示します(Sea of NodesをCFGに置き換えるプロセスをすでに開始しているため、利用可能です):
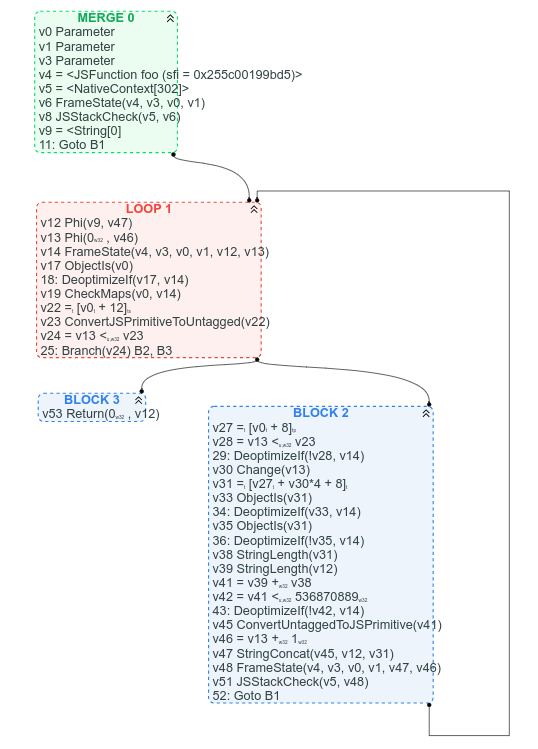
他のことはともかく、このCFGではループがどこにあるかはっきりと分かり、ループの終了条件が明確であり、期待される位置に基づいてCFG内で特定の命令を簡単に見つけられます:例えばarr.lengthはループヘッダで見つけられます(v22 = [v0 + 12])、文字列連結はループの終わり付近で見つけられます(v47 StringConcat(...))。
反論として、CFGバージョンでは値使用チェーンが追跡しにくいという意見があるかもしれません。しかし、私はほとんどの場合、値ノードのスープよりもグラフの制御フロー構造が明確に見えるほうが良いと主張します。
効果チェーン上にあるノードや制御入力を持つノードが多すぎる
Sea of Nodesの恩恵を受けるためには、グラフ内のほとんどのノードが自由に浮遊し、制御や効果チェーンを持たない状態である必要があります。残念ながら、典型的なJavaScriptグラフではそれはあまり当てはまりません。というのも、ほとんどすべての汎用JS操作が任意の副作用を持ちうるからです。ただし、フィードバックのおかげで、より具体的な操作に降下できるため、Turbofanではそれらは稀であるべきです。
それでも、すべてのメモリ操作は効果入力が必要です(LoadがStoreを越えて浮遊することを防ぐためやその逆の場合も)し、制御入力も必要です(操作の前に型チェックや境界チェックがある場合があるため)。さらに、除算のような純粋な操作でさえ、特殊ケースがチェックによって保護されている場合、制御入力が必要です。
具体的な例を見てみましょう。次のJavaScript関数から始めます:
function foo(a, b) {
// `a.str`と`b.str`が文字列だと仮定
return a.str + b.str;
}
以下は対応するTurbofanグラフです。分かりやすくするため、効果チェーンの一部を赤い破線で強調し、いくつかのノードに番号を付けて、以下で議論できるようにしました。
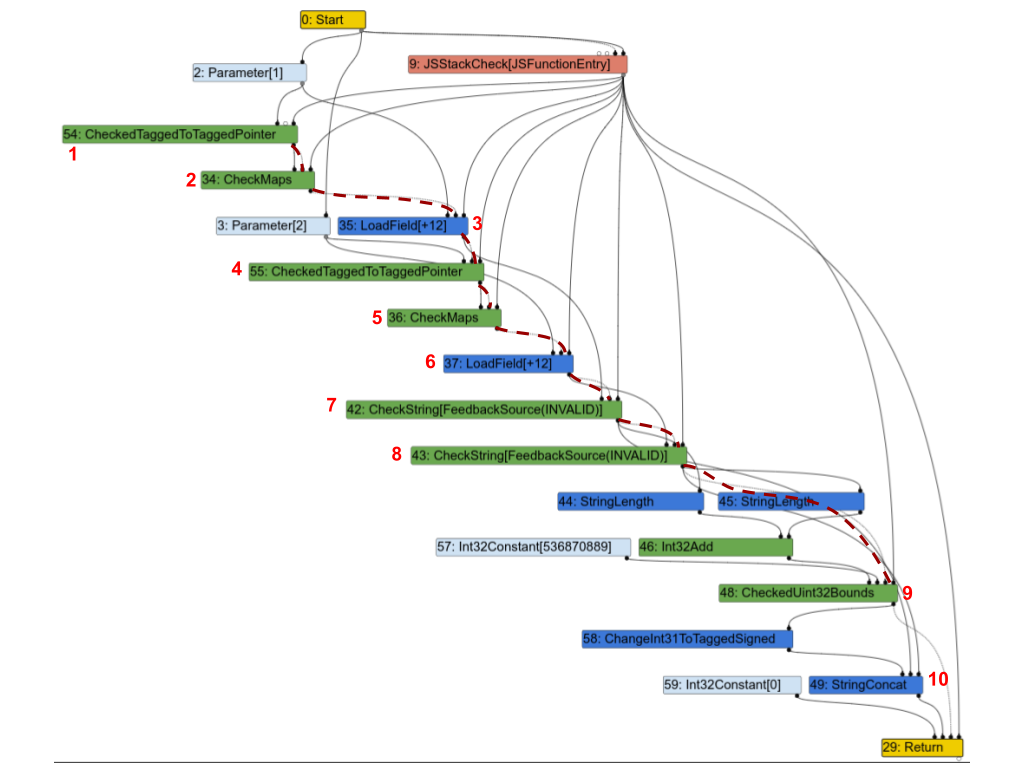
最初の観察結果は、ほぼすべてのノードが効果チェーン上にあるということです。それらに関していくつかを検討し、それらが本当に必要かどうかを見てみましょう:
1(CheckedTaggedToTaggedPointer): このノードは関数の第1入力がポインタであり、「小さな整数」ではないことを確認します(詳細は V8 のポインタ圧縮 を参照)。単独では効果入力を特に必要としないはずですが、実際には次に続くノードを保護するために効果チェインに含める必要があります。2(CheckMaps): 第1入力がポインタであることが分かったので、このノードはその「マップ」(詳細は V8 のマップ(隠れクラス) を参照)を読み取り、フィードバックがこのオブジェクトに対して記録した内容と一致するかを確認します。3(LoadField): 第1オブジェクトが適切なマップを持つポインタであることが分かったので、その.strフィールドを読み込みます。4,5および6は、第2入力についての繰り返しです。7(CheckString):a.strを読み込んだ後、このノードはそれが正真正銘の文字列であることを確認します。8: 第2入力について同様の処理を行います。9:a.strとb.strの結合した長さが、V8 の文字列の最大サイズを超えないことを確認します。10(StringConcat): 最後に2つの文字列を結合します。
このグラフは、JavaScriptプログラムにおけるTurbofanグラフの典型的な例です:マップ確認、値の読み込み、読み込んだ値のマップ確認などを行い、最終的にそれらの値に対して計算を行います。この例のように、多くのケースでほとんどの命令が効果または制御チェイン上に結局置かれ、それによって演算に厳密な順序が課され、Sea of Nodes の目的が完全に打ち消されてしまいます。
メモリ操作は容易には浮かない
次の JavaScript プログラムを考えてみましょう:
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
x と y がそれぞれ if-else の片側でしか使用されていないため、SoN がそれらを自由に「then」および「else」のブランチ内に下げることを期待するかもしれません。しかし実際には、これを SoN 上で実現するのは CFG 上で実現するのと同じくらい容易ではありません。以下の SoN グラフを見て、その理由を理解しましょう:

SoN グラフを構築する際に、効果チェインを順次作成します。その結果、2番目の Load は最初の Load の直後に配置され、その後、効果チェインは両方の return に到達するために分岐しなければなりません(return が効果チェインに含まれる理由が疑問の場合は、それ以前に Store などの副作用を持つ操作が存在し、それらが関数からの返却前に実行される必要があるためです)。2番目の Load が両方の return の前の節であるため、branch の前にスケジュールする必要があり、その結果、SoN はどちらの Load も自由に下に浮かばせることを許しません。
「then」および「else」ブランチに Load を移動させるためには、それらの間に副作用がないことを計算し、2番目の Load と return の間にも副作用がないことを計算する必要があります。その後、効果チェインを2番目の Load の後ではなく最初に分割できます。この解析を SoN グラフ上で行うことと、CFG 上で行うことは非常に類似しています。
多くのノードが効果チェインに含まれること、また効果ノードが自由に遠くまで浮かないことについて述べたことから、実際には SoN は純粋なノードが浮遊している CFG に過ぎない と認識するのに良いタイミングです。実際、制御ノードおよび制御チェインは常に対応する CFG の構造を模倣します。そして、分岐の両方の目的地が副作用を含む場合(JavaScriptで頻繁に発生します)、効果チェインは分岐で分割され、制御フローが再結合するタイミングで再結合します(上の例では、制御チェインが branch で分岐し、効果チェインがこれを鏡像的に模倣して Load で分割します。プログラムが if-else の後に続く場合、両方のチェインは同じ場所付近で再結合します)。効果ノードは通常、2つの制御ノードの間、つまり基本ブロック内にスケジュールを制約されることになります。また、この基本ブロック内では、効果チェインによって効果ノードがソースコード内と同じ順序で制約されます。結果的に、実際に自由に浮遊できるのは純粋なノードだけです。
より多くの浮遊ノードを得る方法の1つとして、前述のように複数の効果チェインを使用することがありますが、これは代償を伴います。まず、単一の効果チェインを管理するだけでもすでに困難であり、複数のチェインを管理するのはさらに困難になります。次に、JavaScriptのような動的型付け言語では、エイリアスする可能性のある多くのメモリアクセスが発生し、それにより複数の効果チェインが頻繁に統合されなければならず、複数の効果チェインを使用する利点の一部が失われます。
効果および制御チェインを手動で管理するのは難しい
前のセクションで述べたように、効果チェインと制御チェインは多少異なるものの、実際には効果チェインは通常制御チェインと同じ「形」をしています: 分岐の目的地が効果操作を含む場合(これが頻繁に発生します)、効果チェインは分岐時に分割され、制御フローが戻るときに再結合します。 JavaScriptを扱う際、多くのノードが副作用を持ち、多くの分岐があります(通常、いくつかのオブジェクトのタイプに基づいて分岐する)、そのため、効果と制御のチェーンの両方を並行して追跡する必要があります。一方、CFGを使用した場合、制御チェーンのみを追跡すれば十分です。
過去の経験から、効果と制御のチェーンを手動で管理することはエラーが発生しやすく、読みづらく、維持が難しいことが示されています。このサンプルコードはJSNativeContextSpecializationフェーズからの一例です:
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effect effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effect this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
ここで処理すべきさまざまな分岐やケースのために、最終的に3つの異なる効果チェーンを管理する羽目になります。簡単に間違えて、別の効果チェーンを使用してしまう可能性があります。実際、当初は間違っていましたし、数か月後にミスに気づきました:

この問題については、TurbofanとSea of Nodesの両方に責任があると考えます。後者だけの責任ではありません。Turbofan内のより良い補助ツールがあれば、効果と制御チェーンを管理する作業が簡単になったかもしれませんが、CFGではそもそも問題にならなかったはずです。
スケジューラが複雑すぎる
最終的には、すべての命令をスケジュールしてアセンブリコードを生成する必要があります。命令をスケジュールする理論は十分単純です:各命令はその値、制御、および効果入力の後にスケジュールされるべきです(ループを無視すると)。
興味深い例を見てみましょう:

ソースJavaScriptプログラムには同一の除算が2つ含まれていますが、Sea of Nodesグラフには1つしか含まれていないことに気付くでしょう。実際には、Sea of Nodesは最初に2つの除算を持っていますが、これは純粋な操作(ダブル入力を仮定)であるため、冗長性を排除して簡単に1つに重複排除されます。
その後、スケジューリングフェーズに到達すると、この除算をスケジュールする場所を見つける必要があります。明らかに、case 1やcase 2の後に配置することはできません。他のケースで使用されるからです。その代わり、switchの前にスケジュールする必要があります。この欠点は、cが3の場合、計算する必要のないa / bが計算されることです。これにより、デデュプリケートされた命令の多くが利用者の共通支配者に浮遊し、それを必要としない多くのパスを遅くする可能性があります。
ただし、解決策があります: Turbofanのスケジューラはこれらのケースを識別し、特定のパスでのみ計算されるように命令を複製しようとします。この欠点は、スケジューラがより複雑になり、どのノードを複製すべきか、それをどのように複製するかを判断するための追加のロジックを必要とすることです。
つまり、最初は除算が2つあり、それを1つに「最適化」し、その後さらに最適化して再び2つに戻します。これは除算だけでなく、他の多くの操作でも同様のサイクルが発生します。
グラフを訪問する良い順序を見つけるのは難しい
コンパイラのすべてのパスは、ノードを下位に変更したり、ローカル最適化を適用したり、グラフ全体を分析したりするためにグラフを訪問する必要があります。CFGでは、ノードを訪問する順序は通常明確です: 最初のブロックから開始(単一エントリの関数を仮定)し、ブロック内の各ノードを順に反復し、その後、継続的に後続のノードへと進んでいきます。peephole最適化フェーズ(例えば強度削減)では、この順序でグラフを処理する特性として、入力が常にノードを処理する前に最適化され、ノードを一度だけ訪問すればほとんどのpeephole最適化を適用するのに十分であることがあります。以下の還元シーケンスを考えてみてください:

合計で、シーケンス全体を最適化するのに3ステップを要し、各ステップで有用な作業が行われました。その後、デッドコード消去によってv1とv2が削除され、初期のシーケンスより1つ少ない命令が生成されます。
Sea of Nodesでは、純粋な命令を開始から終了まで処理することは不可能です。これらはコントロールやエフェクトチェーンに属していないため、純粋なルートやそのようなものへのポインタはありません。その代わりに、ピープホール最適化のためにSea of Nodesグラフを処理する一般的な方法は、終わり(例: return命令)から始め、値、エフェクト、コントロールの入力を上に遡ることです。この方法は、未使用の命令を訪れることがないという良い性質がありますが、それ以上の利点はほとんどありません。ピープホール最適化では、これは最悪の訪問順序の一つです。上記の例では、以下の手順を実行する必要があります。
v3を訪問し始めますが、現時点では変換できないため、その入力に進みますv1を訪問し、これをa << 3に変換します。その後、v1の変換が使用に対する最適化を可能にするかどうかを確認するために使用に進みます。- 再び
v3を訪問しますが、まだ変換することはできません(この回では入力を再び訪問することはありません)。
- 再び
v2を訪問し、これをb << 3に変換します。その後、この変換が使用に対する最適化を可能にするかどうかを確認するために使用に進みます。- 再び
v3を訪問し、これを(a & b) << 3に変換します。
- 再び
その結果として、v3 は3回訪問されましたが、変換されたのは1回だけでした。
私たちは以前、典型的なJavaScriptプログラムでこの現象を測定し、平均して20回訪問するごとにノードが1回しか変更されないことを確認しました!
グラフの良い訪問順序を見つけることの難しさのもう一つの結果として、状態追跡が困難で高コストであるということがあります。多くの最適化は、Load EliminationやEscape Analysisのように、グラフに沿って状態を追跡することを必要とします。しかし、Sea of Nodesでは、特定の状態を維持する必要があるのかどうかを確認するのが難しいため、未処理のノードがその状態を必要とするかどうかを判断するのが困難です。 その結果として、TurbofanのLoad Eliminationフェーズは、大きなグラフでは処理が長引きすぎたりメモリを過剰に使用したりするのを避けるための救済措置を持っています。一方で、私たちは新しいCFGコンパイラ用の新しいLoad eliminationフェーズを作成しました。このフェーズはベンチマークで最大190倍高速であることが確認されました(最悪の場合の複雑性が改善されているため、大きなグラフではこのような高速化が容易に達成されます)し、メモリ使用量も大幅に削減されています。
キャッシュの非親和性
Turbofanのほとんどのフェーズでは、グラフがインプレースで変異します。ノードがメモリ内でかなり大きい(主に各ノードが入力と使用へのポインタを持っているため)ので、可能な限りノードを再利用しようとします。しかし、ノードが複数のノードの連鎖に変換される場合、新しいノードを導入する必要があり、これらはメモリ内の元のノードの近くに割り当てられることはありません。その結果として、Turbofanパイプラインを深く進むほど、実行するフェーズが増えるほど、グラフのキャッシュ親和性は低下します。この現象を示す図を以下に示します。

このキャッシュの非親和性がメモリに与える正確な影響を見積もるのは難しいですが、いま私たちは新しいCFGコンパイラを持っているので、それらの間のキャッシュミスの数を比較することができます。Sea of Nodesは、新しいCFG IRと比較して平均で約3倍多くのL1データキャッシュミスに苦しみ、一部のフェーズでは最大7倍多くなります。これがコンパイル時間の最大5%に影響する可能性があると推測していますが、この数字は少々曖昧です。それでも、JITコンパイラでは高速コンパイルが重要であることを忘れないでください。
制御フロー依存型の型付けは制限されています
以下のJavaScript関数を考えてみましょう。
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
これまでに x や x+1 の結果が小さな整数(「小さな整数」は31ビット整数を指します。参考:V8のValueタグ付け)である場合、これが今後も続くと推測されます。もし x が31ビット以上になる場合、私たちはデオプティマイズします。同様に、x+1 の結果が31ビットを超える場合、それでもデオプティマイズします。つまり、x+1 が31ビットに収まる最大値より大きいかどうかを確認する必要があります。対応するCFGとSoNグラフを見てみましょう。

(入力を加え、結果が31ビットを超えた場合にデオプティマイズする CheckedAdd 操作を仮定します)
CFGを使用すると、CheckedAdd(v1, 1) が実行されるとき、v1 が 42 未満であることが保証され、したがって31ビットのオーバーフローをチェックする必要がないことに気付きます。これにより、CheckedAdd を通常の Add に置き換えることが容易になり、これが高速に実行され、デオプティマイズ状態を必要としません(これはデオプティマイズ後の実行再開方法を知るために必要です)。
しかし、SoNグラフでは、CheckedAdd は純粋な操作であるため、グラフ内で自由に流れ、分岐後に計算することを決定してスケジュールを計算するまでチェックを削除する方法がありません(この時点で、再びCFGに戻るため、これはもはやSoNの最適化ではありません)。
この31ビット小整数最適化のため、V8ではこのようなチェック付き操作が頻繁に行われており、チェック付き操作をチェックなし操作に置き換える機能は、Turbofanが生成するコードの品質に大きな影響を与える可能性があります。そのため、TurbofanのSoNでは、CheckedAddに制御入力を与える仕組みを取り入れています。これによりこの最適化を可能にすると同時に、純粋なノードに対してスケジューリング制約を導入する、いわばCFGに戻ることになります。
そして他にも多くの問題…
死活情報を伝播させるのが難しい。 降下処理中に現在のノードが実際には到達不能であることがわかることは頻繁にあります。CFGでは、この時点で現在の基本ブロックを切断することが可能で、その後のブロックは自動的に到達不能であることが明らかになります(前のノードが存在しなくなるため)。Sea of Nodesでは、制御チェーンと効果チェーンの両方を修正する必要があるため、これがより困難です。そのため、効果チェーン上のノードが無効になった場合、次のマージポイントまで効果チェーンを進みながら途中のすべてを削除し、制御チェーン上のノードを慎重に扱う必要があります。
新しい制御フローを導入するのが難しい。 制御フローノードは制御チェーン上に存在する必要があるため、通常の降下処理中に新しい制御フローを導入することはできません。つまり、グラフに純粋なノード(例えば2つの整数の最大値を返すInt32Max)が存在していて、そのノードを最終的にはif (x > y) { x } else { y }の形に降下させたい場合、Sea of Nodesではこれを実現するのが難しいのです。このサブグラフを制御チェーンのどこに接続するかを決定する方法が必要です。その1つの方法は、開始時点からInt32Maxを制御チェーン上に配置することですが、これは無駄に感じられます。ノードは純粋であり、自由に移動できるはずです。したがって、この問題を解決するSea of Nodesの標準的な方法は、Turbofanや、Coffee Compiler Clubで言及された通りSea of Nodesの発明者Cliff Clickが使用した方法にもあるように、この種の降下をスケジュール(つまりCFG)を取得するまで遅延させることです。その結果、パイプラインの途中でスケジュールを計算しグラフを降下させるフェーズがあり、多くのランダムな最適化が一緒に行われます。これらすべてがスケジュールを必要とするからです。一方で、CFGを使用すれば、この最適化はパイプラインの早い段階でも遅い段階でも自由に行うことができます。
また、導入部でも述べたように、Crankshaft(Turbofanの前身)の問題点の1つは、グラフを構築した後に制御フローを導入することが事実上不可能であった点です。Turbofanはこれを若干改善しています。制御チェーン上のノードの降下では新しい制御フローを導入することができますが、それでも制限があります。
ループ内の内容を把握するのが難しい。 多くのノードが制御チェーンの外に浮遊しているため、各ループ内の内容を把握するのが難しいのです。その結果、ループの外し込みやループの展開のような基本的な最適化を実装するのが困難です。
コンパイルが遅い。 これは、既に述べた複数の問題の直接的な結果です。ノードの良好な訪問順序を見つけるのが困難であり、それが多くの無駄な再訪問を引き起こします。状態追跡が高コストで、メモリ使用量が悪く、キャッシュの局所性も悪いです。この問題は、事前コンパイル型コンパイラでは大きな問題ではないかもしれませんが、JITコンパイラでは、コンパイルが遅いと最適化されたコードが準備されるまで遅い非最適化コードを実行し続けなければならないため、他のタスク(例:他のコンパイルジョブやガベージコレクタ)からリソースを奪ってしまいます。これにより、新しい最適化のコンパイル時間とスピードアップのトレードオフについて非常に慎重に考えざるを得なくなり、しばしば高速化を優先するために最適化を控えめにする傾向があります。
Sea of Nodesは構造上、事前のスケジューリングをすべて破棄する。 JavaScriptのソースコードは通常、CPUマイクロアーキテクチャを考慮して手動で最適化されることはありません。しかし、WebAssemblyコードはソースレベル(例えばC++)やAOT(事前コンパイル)コンパイルツールチェーン(Binaryen/Emscriptenのような)によって最適化される可能性があります。その結果、WebAssemblyコードはたとえばレジスタスピリングを減らす(16レジスタを想定)ことを目指して、多くのアーキテクチャでうまくいくようにスケジュールされる場合があります。しかし、Sea of Nodesは常に初期のスケジュールを破棄し、独自のスケジューラーのみに依存します。このため、JITコンパイルの時間的制約のもとで、AOTコンパイラ(またはスケジューリングを慎重に考えたC++開発者)が行える最適化よりも悪い結果になることがあります。WebAssemblyがこれに苦しむケースを目撃しました。残念ながら、Turbofanでは、WebAssemblyにはCFGコンパイラ、JavaScriptにはSoNコンパイラを使用するという選択肢もありません。同じコンパイラを使用することで、両言語間のインライン化が可能になるからです。
Sea of Nodes: JavaScriptには優雅だが非現実的
それでは、要約すると、Sea of NodesとTurbofanに関連する主要な問題点は次のとおりです。
-
複雑すぎる。影響と制御のチェーンが理解しにくいため、多くの微妙なバグが発生します。グラフは読み取りや分析が難しいため、新しい最適化を実装し改善するのが困難です。
-
制限が多すぎる。影響と制御のチェーンに多くのノードが存在するため(JavaScriptコードをコンパイルしているため)、従来のCFGに比べて多くの利点を提供するわけではありません。さらに、下位化で新しい制御フローを導入するのが難しいため、基本的な最適化でさえ実装が難しくなります。
-
コンパイルが遅すぎる。状態追跡はコストが高く、グラフを訪れる順序を見つけるのが困難です。キャッシュの局所性が悪く、削減フェーズ中にフィックスポイントに達するのに時間がかかります。
そのため、Turbofanを10年間扱い、Sea of Nodesと戦った末に、ついにこれを廃止して、より伝統的なCFG IRに戻ることを決定しました。新しいIRの経験はこれまで非常に良好で、CFGに戻って正解だったと感じています。コンパイル時間はSoNと比べて半減し、コンパイラのコードもはるかにシンプルで短く、バグの調査も通常ははるかに簡単です。 とはいえ、この投稿は既に十分に長いので、ここで終わりにします。新しいCFG IRであるTurboshaftの設計について説明する次回のブログ投稿をお楽しみに。