加速 V8 堆快照
這篇博客由 José Dapena Paz (Igalia) 撰寫,Jason Williams (Bloomberg), Ashley Claymore (Bloomberg), Rob Palmer (Bloomberg), Joyee Cheung (Igalia), 和 Shu-yu Guo (Google) 共同參與。
在這篇文章中,我將討論 Bloomberg 工程師發現的 V8 堆快照中的一些性能問題,以及我們如何修復這些問題以使 JavaScript 記憶體分析比以往更快。
問題
Bloomberg 工程師正在診斷一個 JavaScript 應用程式中的記憶體洩漏問題。該應用報錯 Out-Of-Memory。對於所測試的應用程式,V8 堆限制被設置大約為 1400 MB。通常情況下,V8 的垃圾回收器應該可以使堆使用量保持在這個限制以下,因此該錯誤表明可能存在記憶體洩漏。
調試這類常見記憶體洩漏情景的常用技術是首先捕獲堆快照,然後將其載入 DevTools 的“記憶體”標籤中,通過檢查各種摘要和物件屬性來找出佔用記憶體最多的部分。在 DevTools 的 UI 中,可以在“記憶體”標籤中拍攝堆快照。對於 Node.js 應用,堆快照可以通過以下 API 以程式化方式觸發:
require('v8').writeHeapSnapshot();
他們希望在應用程式生命週期的不同時間點拍攝多個快照,以便使用 DevTools 記憶體檢視器顯示不同時間點堆之間的差異。問題是,拍攝一個完整的大型(500 MB)的快照需要耗時 超過 30 分鐘!
我們需要解決的正是記憶體分析工作流程中的這種緩慢情況。
縮小問題範圍
接著,Bloomberg 工程師開始使用一些 V8 參數調查問題。如本文所述,Node.js 和 V8 提供了一些不錯的命令列參數,可以幫助調查問題。這些選項被用來創建堆快照、簡化複現過程以及提高可觀察性:
--max-old-space-size=100:此選項將堆限制到 100 兆位元組,並幫助更快地複現問題。--heapsnapshot-near-heap-limit=10:這是一個 Node.js 特定的命令列參數,用於告知 Node.js 每次接近記憶體不足時生成快照。它配置為最多生成 10 個快照。這可防止記憶體匱乏的程式花費大量時間生成不必要的快照。--enable-etw-stack-walking:允許像 ETW、WPA 和 xperf 這樣的工具查看 V8 中的 JavaScript 堆疊。(適用於 Node.js v20+)--interpreted-frames-native-stack:此標誌與工具如 ETW、WPA 和 xperf 配合使用,可在分析時查看原生堆疊。(適用於 Node.js v20+)
當 V8 堆大小接近限制時,V8 會強制執行垃圾回收以減少記憶體使用量,並通知嵌入者。Node.js 的 --heapsnapshot-near-heap-limit 標誌在接到通知時生成新的堆快照。在測試案例中,記憶體使用量下降,但經過數次迭代後,垃圾回收最終無法釋放出足夠的空間,因此應用程式因 Out-Of-Memory 錯誤而終止。
他們使用 Windows Performance Analyzer(見下文)錄製了一些記錄以縮小問題範圍。結果顯示,大部分 CPU 時間都耗費在 V8 堆探索器中。具體來說,只是遍歷堆中的每個節點並收集名稱就花了大約 30 分鐘。這似乎不合常理——為什麼記錄每個屬性的名稱會耗費如此長的時間?
這就是我被請來查看的原因。
定量分析問題
第一步是添加對 V8 的支援,以更好地了解捕獲堆快照過程中耗費時間的部分。捕獲過程本身分為兩個階段:生成和序列化。我們在上游提交了這個補丁,向 V8 引入了一個新的命令列標誌 --profile_heap_snapshot,該標誌能夠記錄生成和序列化時間。
使用這個標誌,我們得到了些有趣的發現!
首先,我們觀察到 V8 在生成每個快照時所花費的確切時間。在我們的簡化測試案例中,第一個快照花了 5 分鐘,第二個花了 8 分鐘,而每個後續的快照花費的時間越來越長。幾乎所有的時間都花費在生成階段。
這也讓我們能夠量化生成快照時所花費的時間,而這些時間的大部分為微不足道的額外開銷,這幫助我們隔離並識別其他廣泛使用的 JavaScript 應用上類似的性能瓶頸——特別是 TypeScript 上的 ESLint。因此我們知道這個問題不是特定於某個應用程序。
此外,我們發現問題同時出現在 Windows 和 Linux 系統上。這個問題也不是特定於某個平台的。
第一個優化:改進 StringsStorage 的哈希算法
為了確定造成超長延遲的原因,我使用 Windows 性能工具包 對失敗的腳本進行性能分析。
當我使用 Windows 性能分析器 打開記錄時,我找到如下的結果:
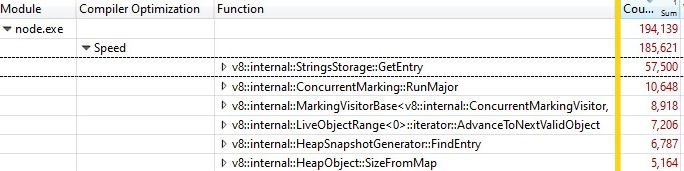
三分之一的樣本時間花費在 v8::internal::StringsStorage::GetEntry:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
由於這是使用發布版本運行的,內聯函數調用的信息被折疊到 StringsStorage::GetEntry() 中。為了確定內聯函數調用確切花費的時間,我在拆解結果中添加了“源行號”列,並發現大部分時間花費在第 182 行,即調用 ComputeStringHash():
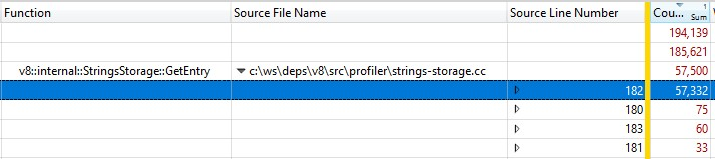
因此超過 30% 的快照生成時間花費在 ComputeStringHash() 上,那為什麼?
首先來談談 StringsStorage。它的目的是存儲將用於堆快照的所有字符串的唯一副本。為了實現快速訪問並避免重複,這個類使用了一個基於數組的哈希映射,其中通過在數組中的下一個空閒位置存儲元素來處理碰撞。
我開始懷疑問題可能是由於碰撞引起的,這可能導致數組中的長搜索。因此我添加了詳細的日誌來查看生成的哈希鍵,並在插入時查看從哈希鍵計算的預期位置到由碰撞導致的實際位置的距離。
在日誌中,情況...並不正常:許多項目偏移超過 20,而在最壞的情況下,是數千的量級!
部分問題是由數字字符串造成的——尤其是廣泛連續數字範圍的字符串。哈希鍵算法有兩個實現,一個是針對數字字符串,另一個是針對其他字符串的。雖然字符串的哈希函數是非常經典的,針對數字字符串的實現基本上會返回數字的值並在其前面加上數字的位數:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
這個函數存在問題。該哈希函數的問題示例包括:
- 一旦插入了一個哈希鍵值為小數字的字符串,在嘗試將另一個數字存入相同位置時就會碰到碰撞,並且在連續存入後續數字時也會有類似的碰撞。
- 更糟糕的是:如果哈希映射中已經存儲了大量連續的數字,當我們試圖插入一個哈希鍵值包含該範圍的字符串時,我們需要沿著所有佔用的位置移動條目,直到找到一個空閒位置。
我如何修復它呢?由於問題主要來自表示為字符串的數字會落在連續位置,我修改了哈希函數,使我們將結果哈希值向左旋轉 2 位。
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
因此,每對連續數字,我們會在之間引入 3 個空閒位置。這個修改是根據對多個工作集的實驗性測試選擇的,這些測試表明它在最小化碰撞方面效果最佳。
此雜湊修正已經在 V8 中實現。
第二次優化:快取來源位置
在修復了雜湊問題後,我們重新進行了分析,發現了進一步的優化機會,可以大幅減少開銷。
在生成堆快照時,V8 會嘗試為堆中的每個函數記錄其起始位置,並用行號和列號表示。這些資訊可供 DevTools 顯示一個連結以指向該函數的原始碼。然而,在通常的編譯過程中,V8 僅以從腳本開頭的線性偏移形式儲存每個函數的起始位置。若要根據線性偏移計算行號和列號,V8 需要遍歷整個腳本並記錄行分隔符的位置。這種計算非常耗費資源。
通常,在 V8 計算完腳本中行分隔符的偏移後,會將其快取到附加在腳本上的新分配陣列中。不幸的是,快照實現無法在遍歷堆時修改堆,因此新計算的行資訊無法被快取。
解決方案是什麼?在生成堆快照之前,我們現在會遍歷 V8 上下文中的所有腳本,計算並快取行分隔符的偏移。由於這不是在遍歷堆以生成堆快照時完成的,因此仍可修改堆並將來源行位置儲存為快取。
用於快取行分隔符偏移的修正也已經在 V8 中實現。
我們是否讓其變快了?
啟用了兩個修正之後,我們重新進行了分析。這兩個修正僅影響快照生成時間,因此,正如預料的那樣,快照序列化時間未受影響。
在處理包含以下內容的 JS 程式時……
- 開發環境的 JS,生成時間快了50% 👍
- 生產環境的 JS,生成時間快了90% 😮
為什麼生產代碼和開發代碼之間會有巨大差異?生產代碼經過了打包和縮小優化,因此 JS 文件減少了,而這些文件往往較大。對於這些大型文件,計算來源行位置所需的時間較長,因此快取來源位置並避免重複計算帶來了最大的收益。
這些優化已在 Windows 和 Linux 目標環境中驗證過。
針對 Bloomberg 工程師最初面臨的特別棘手問題,捕獲 100MB 快照的總端到端時間從令人痛苦的 10 分鐘減少到令人愉快的 6 秒。這是一個100 倍的提升! 🔥
這些優化是通用的成果,我們預期它們能廣泛適用於任何在 V8、Node.js 和 Chromium 上進行記憶體調試的人員。這些優化已在 V8 v11.5.130 中推出,這意味著它們已包含在 Chromium 115.0.5576.0 中。我們期待著 Node.js 在下一次版本重大改進時獲得這些優化。
接下來是什麼?
首先,讓 Node.js 接受 NODE_OPTIONS 中的新 --profile-heap-snapshot 標誌會很有用。在某些使用情況下,使用者無法直接控制傳遞給 Node.js 的命令列選項,必須通過環境變數 NODE_OPTIONS 來配置它們。目前,Node.js 過濾環境變數中設定的 V8 命令列選項,僅允許某個已知的子集,這可能使得在 Node.js 中測試新 V8 標誌變得更加困難,就像我們遇到的情況一樣。
快照中的資訊準確性可以進一步提高。目前,每個腳本的原始碼行資訊以 V8 堆中自己的表示形式儲存。而這是個問題,因為我們希望在不影響觀測對象的效能測量的情況下,精確地測量堆。理想情況下,我們會將行資訊的快取儲存在 V8 堆之外,以使堆快照資訊更加準確。
最後,現在我們改進了生成階段,最大的成本現在是序列化階段。進一步的分析可能會揭示在序列化中新的優化機會。