Terra à vista: deixando o Mar de Nós
O compilador otimizador de última etapa do V8, o Turbofan, é conhecido como um dos poucos compiladores de produção em larga escala que utilizam Mar de Nós (SoN). No entanto, há quase três anos, começamos a nos livrar do Mar de Nós e a retornar para uma Representação Intermediária (IR) Gráfico de Fluxo de Controle (CFG) mais tradicional, que chamamos de Turboshaft. Até agora, todo o backend de JavaScript do Turbofan utiliza Turboshaft e o WebAssembly usa Turboshaft ao longo de todo o seu pipeline. Duas partes do Turbofan ainda usam algum Mar de Nós: o pipeline embutido, que estamos substituindo gradualmente pelo Turboshaft, e o frontend do pipeline de JavaScript, que estamos substituindo pelo Maglev, outro IR baseado em CFG. Este post no blog explica as razões que nos levaram a abandonar o Mar de Nós.
Há 12 anos, em 2013, o V8 tinha um único compilador otimizador: Crankshaft. Ele utilizava uma Representação Intermediária baseada em Gráfico de Fluxo de Controle. A versão inicial do Crankshaft proporcionava melhorias de desempenho significativas, apesar de ainda ser bastante limitada no que suportava. Nos anos seguintes, a equipe continuou melhorando-o para gerar código ainda mais rápido em situações cada vez mais diversas. No entanto, a dívida técnica começou a se acumular e uma série de problemas surgiu com o Crankshaft:
-
Ele continha muito código assembly escrito manualmente. Toda vez que um novo operador era adicionado ao IR, sua tradução para o assembly precisava ser escrita manualmente para as quatro arquiteturas oficialmente suportadas pelo V8 (x64, ia32, arm, arm64).
-
Ele tinha dificuldade de otimizar asm.js, que na época era visto como um passo importante em direção a um JavaScript de alto desempenho.
-
Ele não permitia a introdução de fluxo de controle em rebaixamentos. Em outras palavras, o fluxo de controle era criado no momento da construção do gráfico, e era então final. Isso era uma grande limitação, dado que uma prática comum ao escrever compiladores é começar com operações de alto nível e depois reduzi-las a operações de baixo nível, muitas vezes introduzindo fluxo de controle adicional. Considere, por exemplo, uma operação de alto nível
JSAdd(x,y), poderia fazer sentido depois rebaixá-la para algo comoif (x é String e y é String) { StringAdd(x, y) } else { … }. Bem, isso não era possível no Crankshaft. -
Try-catches não eram suportados, e apoiá-los era muito desafiador: vários engenheiros tentaram por meses implementar suporte sem sucesso.
-
Ele sofria de muitos declínios de desempenho e abandonos. Usar um recurso ou instrução específica, ou encontrar um caso extremo específico de um recurso, podia fazer o desempenho cair por um fator 100. Isso dificultava para os desenvolvedores de JavaScript escreverem código eficiente e preverem o desempenho de suas aplicações.
-
Ele continha muitos loops de desotimização: o Crankshaft otimizava uma função usando algumas suposições especulativas, depois a função era desotimizada quando essas suposições não se confirmavam, mas muitas vezes o Crankshaft reotimizava a função com as mesmas suposições, levando a loops infinitos de otimização-desotimização.
Individualmente, cada um desses problemas poderia provavelmente ter sido superado. No entanto, juntos, eles pareciam ser demais. Então, a decisão foi tomada de substituir o Crankshaft por um novo compilador escrito do zero: Turbofan. E, em vez de usar um IR tradicional baseado em CFG, o Turbofan usaria um IR supostamente mais poderoso: o Mar de Nós. Na época, esse IR já era usado há mais de 10 anos no C2, o compilador JIT da Máquina Virtual Java HotSpot.
Mas o que é o Mar de Nós, exatamente?
Primeiro, um pequeno lembrete sobre o Gráfico de Fluxo de Controle (CFG): um CFG é uma representação de um programa como um gráfico onde os nós do gráfico representam blocos básicos do programa (ou seja, uma sequência de instruções sem ramificações ou saltos de entrada ou saída) e as arestas representam o fluxo de controle do programa. Aqui está um exemplo simples:

As instruções dentro de um bloco básico são implicitamente ordenadas: a primeira instrução deve ser executada antes da segunda, e a segunda antes da terceira, etc. No pequeno exemplo acima, isso parece muito natural: v1 == 0 não pode ser calculado antes de x % 2 ter sido calculado de qualquer maneira. No entanto, considere

Aqui, o CFG aparentemente impõe que a * 2 seja calculado antes de b * 2, embora pudéssemos muito bem calcular na ordem inversa.
É aqui que o Sea of Nodes entra: o Sea of Nodes não representa blocos básicos, mas sim apenas dependências verdadeiras entre as instruções. Os nós no Sea of Nodes são instruções individuais (em vez de blocos básicos), e as arestas representam usos de valores (significando: uma aresta de a para b representa o fato de que a usa b). Assim, aqui está como este último exemplo seria representado com Sea of Nodes:

Eventualmente, o compilador precisará gerar assembly e, portanto, agendará sequencialmente essas duas multiplicações, mas até lá, não há mais dependência entre elas.
Agora vamos adicionar fluxo de controle à mistura. Nós de controle (por exemplo, branch, goto, return) normalmente não têm dependências de valor entre si que forçariam um agendamento específico, embora definitivamente precisem ser agendados em uma ordem específica. Assim, para representar o fluxo de controle, precisamos de um novo tipo de aresta, arestas de controle, que impõem alguma ordem nos nós que não têm dependência de valor:

Neste exemplo, sem arestas de controle, nada impediria que os returns fossem executados antes do branch, o que obviamente estaria errado.
O ponto crucial aqui é que as arestas de controle só impõem uma ordem das operações que têm tais arestas de entrada ou saída, mas não em outras operações, como as operações aritméticas. Esta é a principal diferença entre Sea of Nodes e grafos de fluxo de controle.
Agora vamos adicionar operações com efeitos colaterais (por exemplo, leituras e gravações de e para a memória) à mistura. Assim como os nós de controle, operações com efeitos colaterais frequentemente não têm dependências de valor, mas ainda assim não podem ser executadas em uma ordem aleatória. Por exemplo, a[0] += 42; x = a[0] e x = a[0]; a[0] += 42 não são equivalentes. Assim, precisamos de uma forma de impor uma ordem (= um agendamento) em operações com efeitos colaterais. Poderíamos reutilizar a cadeia de controle para esse propósito, mas isso seria mais estrito do que o necessário. Por exemplo, considere este pequeno trecho:
let v = a[2];
if (c) {
return v;
}
Colocando a[2] (que lê da memória) na cadeia de controle, forçaríamos que ela ocorresse antes do branch em c, embora, na prática, essa leitura pudesse facilmente ocorrer após o branch se seu resultado for usado apenas dentro do corpo do ramo então. Ter muitos nós no programa na cadeia de controle prejudicaria o objetivo do Sea of Nodes, já que acabaríamos basicamente com um IR semelhante ao CFG onde apenas operações puras flutuam.
Assim, para desfrutar de mais liberdade e realmente beneficiar do Sea of Nodes, o Turbofan tem outro tipo de aresta, arestas de efeito, que impõem alguma ordem nos nós que têm efeitos colaterais. Vamos ignorar o fluxo de controle por agora e olhar para um pequeno exemplo:

Neste exemplo, arr[0] = 42 e let x = arr[a] não têm dependência de valor (ou seja, o primeiro não é uma entrada do segundo, e vice-versa). No entanto, porque a poderia ser 0, arr[0] = 42 deve ser executado antes de x = arr[a] para que o último sempre carregue o valor correto do array.
Note que, enquanto o Turbofan tem uma única cadeia de efeito (que se divide em branches, e se junta novamente quando o fluxo de controle se une) que é usada para todas as operações com efeitos colaterais, é possível ter múltiplas cadeias de efeito, onde operações que não têm dependências poderiam estar em cadeias de efeito diferentes, relaxando assim como podem ser agendadas (veja Capítulo 10 de SeaOfNodes/Simple para mais detalhes). No entanto, como explicaremos mais adiante, manter uma única cadeia de efeito já é muito propenso a erros, então não tentamos no Turbofan ter múltiplas cadeias.
E, claro, a maioria dos programas reais conterá tanto fluxo de controle quanto operações com efeitos colaterais.

Observe que store e load precisam de entradas de controle, já que poderiam ser protegidas por várias verificações (como verificações de tipo ou verificações de limites).
Este exemplo é uma boa demonstração do poder do Sea of Nodes comparado ao CFG: y = x * c é usado apenas no ramo else, portanto, flutuará livremente para após o branch, em vez de ser calculado antes, como estava escrito no código JavaScript original. Isso é similar ao arr[0], que é usado apenas no ramo else e poderia então flutuar após o branch (embora, na prática, o Turbofan não moverá arr[0] para baixo, por razões que explicarei mais tarde).
Para comparação, aqui está como o correspondente CFG seria:

Já começamos a ver o principal problema com o SoN: ele está muito mais distante tanto da entrada (código fonte) quanto da saída (assembly) do compilador do que o CFG, o que o torna menos intuitivo de entender. Além disso, ter dependências de efeito e controle sempre explícitas dificulta raciocinar rapidamente sobre o gráfico e escrever rebaixamentos (já que os rebaixamentos sempre têm que manter explicitamente a cadeia de controle e efeito, que são implícitas em um CFG).
E os problemas começam...
Depois de mais de uma década lidando com o Sea of Nodes, acreditamos que ele tem mais desvantagens do que vantagens, pelo menos no que diz respeito ao JavaScript e WebAssembly. Entraremos em detalhes em alguns dos problemas abaixo.
Inspecionar e entender manualmente/visualizar um gráfico Sea of Nodes é difícil
Já vimos que, em pequenos programas, o CFG é mais fácil de ler, pois ele está mais próximo do código-fonte original, que é o que os desenvolvedores (incluindo engenheiros de compiladores!) estão acostumados a escrever. Para os leitores não convencidos, deixe-me oferecer um exemplo um pouco maior, para que você entenda melhor o problema. Considere a seguinte função JavaScript, que concatena um array de strings:
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
Aqui está o gráfico Sea of Nodes correspondente, no meio do pipeline de compilação do Turbofan (o que significa que alguns rebaixamentos já ocorreram):
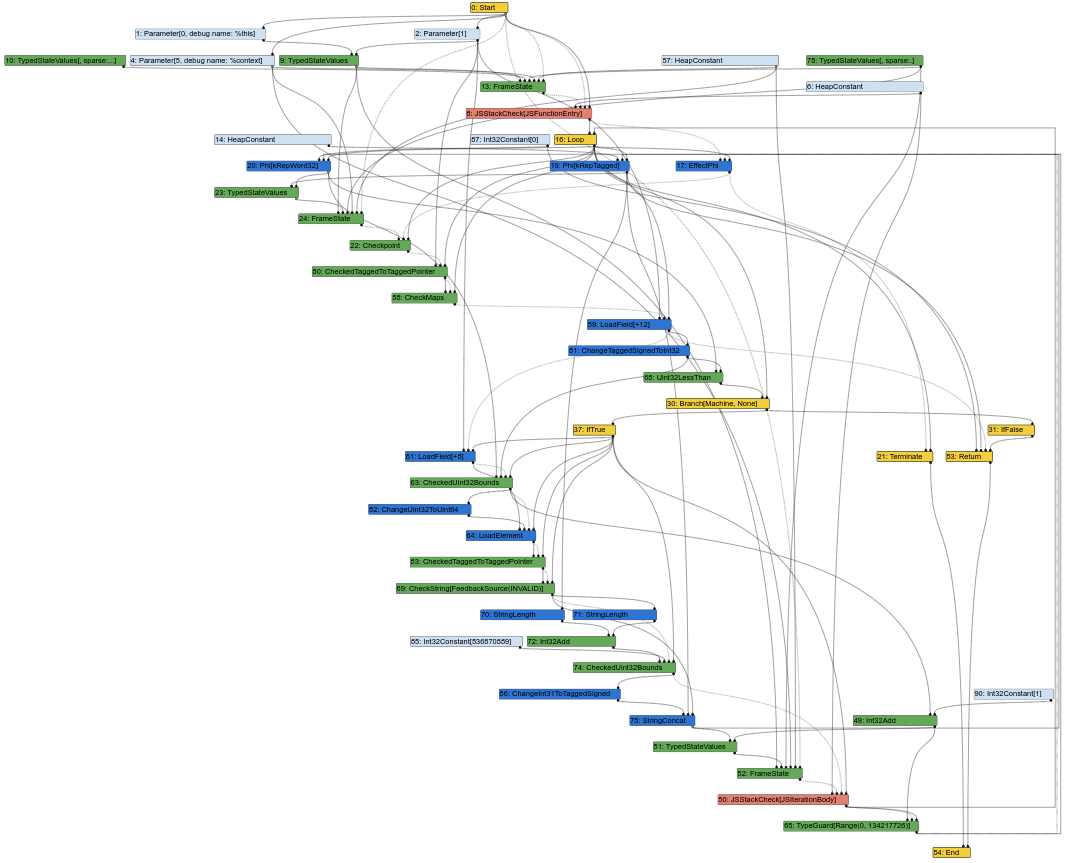
Já começa a parecer uma sopa confusa de nós. E, como engenheiro de compiladores, uma grande parte do meu trabalho é olhar os gráficos do Turbofan para entender bugs ou encontrar oportunidades de otimização. Bem, não é fácil fazer isso quando o gráfico parece assim. Afinal, a entrada de um compilador é o código-fonte, que é semelhante ao CFG (as instruções têm uma posição fixa em um determinado bloco), e a saída do compilador é o assembly, que também é semelhante ao CFG (as instruções também têm uma posição fixa em um determinado bloco). Ter um IR semelhante ao CFG facilita para os engenheiros de compiladores alinharem os elementos do IR ao código-fonte ou ao assembly gerado.
Para comparação, aqui está o gráfico CFG correspondente (que temos disponível porque já começamos o processo de substituir o Sea of Nodes pelo CFG):
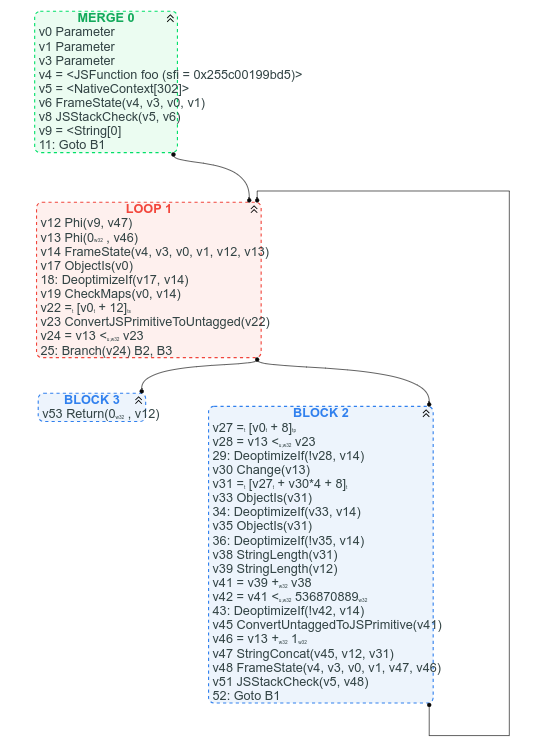
Entre outras coisas, com o CFG, é claro onde está o loop, é claro qual é a condição de saída do loop e é fácil encontrar algumas instruções no CFG com base em onde esperamos que elas estejam: por exemplo, arr.length pode ser encontrado no cabeçalho do loop (é v22 = [v0 + 12]), a concatenação de strings pode ser encontrada próximo ao final do loop (v47 StringConcat(...)).
Pode-se argumentar que as cadeias de uso de valores são mais difíceis de seguir na versão CFG, mas eu argumentaria que, na maioria das vezes, é melhor ver claramente a estrutura de fluxo de controle do gráfico em vez de uma sopa de nós de valores.
Muitos nós estão na cadeia de efeitos e/ou têm uma entrada de controle
Para se beneficiar do Sea of Nodes, a maioria dos nós no gráfico deveria flutuar livremente, sem controle ou cadeia de efeitos. Infelizmente, esse não é realmente o caso no gráfico típico do JavaScript, porque quase todas as operações genéricas de JS podem ter efeitos colaterais arbitrários. Eles deveriam ser raros no Turbofan, já que temos feedback que deveria permitir reduzi-los a operações mais específicas.
Mesmo assim, toda operação de memória precisa de uma entrada de efeito (já que um Load não deve flutuar após Stores e vice-versa) e uma entrada de controle (já que pode haver uma verificação de tipo ou verificação de limite antes da operação). E até algumas operações puras, como divisão, precisam de entradas de controle porque podem ter casos especiais protegidos por verificações.
Vamos dar uma olhada em um exemplo concreto e começar pela seguinte função JavaScript:
function foo(a, b) {
// assumindo que `a.str` e `b.str` são strings
return a.str + b.str;
}
Aqui está o gráfico Turbofan correspondente. Para tornar as coisas mais claras, destaquei parte da cadeia de efeitos com linhas vermelhas tracejadas e anotei alguns nós com números para que eu possa discuti-los abaixo.
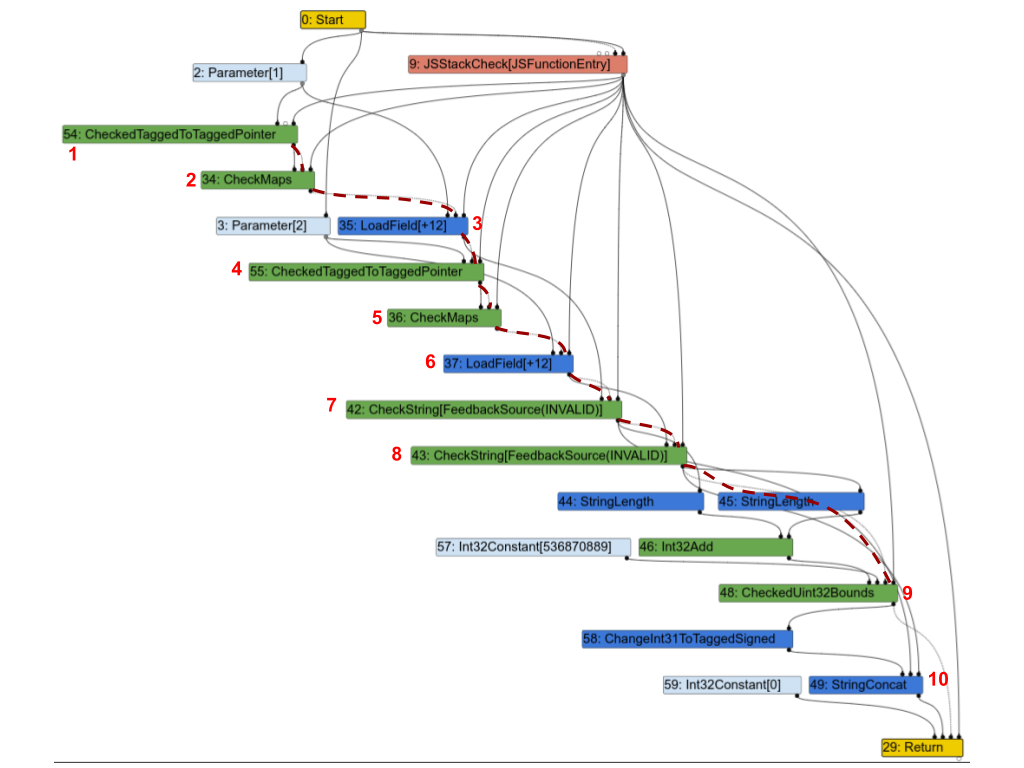
A primeira observação é que quase todos os nós estão na cadeia de efeitos. Vamos examinar alguns deles e ver se realmente precisam estar:
1(CheckedTaggedToTaggedPointer): isto verifica se a 1ª entrada da função é um ponteiro e não um “pequeno inteiro” (consulte Pointer Compression in V8). Por si só, não necessitaria realmente de uma entrada de efeito, mas na prática, ainda precisa estar na cadeia de efeito, porque protege os nós seguintes.2(CheckMaps): agora que sabemos que a 1ª entrada é um ponteiro, este nó carrega seu “mapa” (consulte Maps (Hidden Classes) in V8) e verifica se ele corresponde ao que o feedback registrou para esse objeto.3(LoadField): agora que sabemos que o 1º objeto é um ponteiro com o mapa correto, podemos carregar seu campo.str.4,5e6são uma repetição para a segunda entrada.7(CheckString): agora que carregamosa.str, este nó verifica se ele é, de fato, uma string.8: repetição para a segunda entrada.9: verifica se o comprimento combinado dea.streb.stré menor que o tamanho máximo de uma String no V8.10(StringConcat): finalmente concatena as 2 strings.
Este gráfico é muito típico dos gráficos do Turbofan para programas JavaScript: verificando mapas, carregando valores, verificando os mapas dos valores carregados e assim por diante, e eventualmente realizando alguns cálculos sobre esses valores. E como neste exemplo, em muitos casos, a maioria das instruções acaba estando na cadeia de efeito ou controle, o que impõe uma ordem estrita nas operações e anula completamente o propósito do Sea of Nodes.
Operações de memória não flutuam facilmente
Vamos considerar o seguinte programa JavaScript:
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
Dado que x e y são usados apenas em um lado do if-else, podemos esperar que o SoN permita que eles flutuem livremente para dentro dos ramos “then” e “else”. No entanto, na prática, fazer isso acontecer no SoN não seria mais fácil do que em um CFG. Vamos olhar o gráfico do SoN para entender o porquê:

Quando construímos o gráfico do SoN, criamos a cadeia de efeito à medida que avançamos, e, portanto, o segundo Load acaba exatamente após o primeiro, depois do qual a cadeia de efeito precisa se dividir para alcançar ambos os returns (se você está se perguntando por que os returns estão na cadeia de efeito, é porque pode haver operações com efeitos colaterais antes, como Stores, que precisam ser executados antes de retornar da função). Dado que o segundo Load é um antecessor de ambos os returns, ele precisa ser agendado antes da branch, e o SoN, assim, não permite que nenhum dos dois Loads flutue livremente.
Para mover os Loads pelos ramos “then” e “else”, precisaríamos calcular que não há efeitos colaterais entre eles, e que não há efeitos colaterais entre o segundo Load e os returns, então poderíamos dividir a cadeia de efeito no início, em vez de após o segundo Load. Realizar essa análise em um gráfico SoN ou em um CFG é extremamente semelhante.
Agora que mencionamos que muitos nós acabam na cadeia de efeito e que nós com efeito geralmente não flutuam muito longe, é um bom momento para perceber que, de certo modo, SoN é apenas CFG em que nós puros flutuam. De fato, na prática, os nós de controle e a cadeia de controle sempre espelham a estrutura do CFG equivalente. E, quando ambos os destinos de um desvio têm efeitos colaterais (o que é frequente em JavaScript), a cadeia de efeito se divide e se funde exatamente onde a cadeia de controle faz (como no caso do exemplo acima: a cadeia de controle se divide no branch e a cadeia de efeito espelha isso dividindo-se no Load; e se o programa continuasse após o if-else, ambas as cadeias se fundiriam no mesmo local). Os nós com efeito, portanto, geralmente acabam sendo limitados a serem agendados entre dois nós de controle, ou seja, em um bloco básico. E dentro desse bloco básico, a cadeia de efeito limitará os nós com efeito a estarem na mesma ordem em que estavam no código-fonte. No final, apenas nós puros flutuam realmente livremente.
Uma maneira de obter mais nós flutuantes é usar múltiplas cadeias de efeito, como mencionado anteriormente, mas isso tem um custo: primeiro, gerenciar uma única cadeia de efeito já é difícil; gerenciar múltiplas será muito mais difícil. Em segundo lugar, em uma linguagem dinâmica como JavaScript, acabamos com muitos acessos à memória que podem ser aliases, o que significa que as múltiplas cadeias de efeito teriam que se fundir com muita frequência, anulando assim parte das vantagens de ter múltiplas cadeias de efeito.
Gerenciar manualmente as cadeias de efeito e controle é difícil
Conforme mencionado na seção anterior, embora a cadeia de efeito e a cadeia de controle sejam um tanto distintas, na prática, a cadeia de efeito geralmente tem o mesmo “formato” da cadeia de controle: se os destinos de um desvio contêm operações com efeito (e isso é frequentemente o caso), então a cadeia de efeito se dividirá no desvio e se fundirá de volta quando o fluxo de controle se fundir novamente. Como estamos lidando com JavaScript, muitos nós têm efeitos colaterais, e temos muitos ramos (tipicamente ramificando com base no tipo de alguns objetos), o que leva à necessidade de acompanhar tanto a cadeia de efeitos quanto a cadeia de controle em paralelo, enquanto que com um CFG, só precisaríamos acompanhar a cadeia de controle.
A história mostrou que gerenciar manualmente tanto as cadeias de efeito quanto as de controle é propenso a erros, difícil de ler e de manter. Veja este exemplo de código da fase JSNativeContextSpecialization:
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effect effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effect this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
Devido aos vários ramos e casos que precisam ser tratados aqui, acabamos gerenciando 3 cadeias de efeito diferentes. É fácil errar e usar uma cadeia de efeito em vez da outra. Tão fácil que, de fato, cometemos um erro inicialmente e só percebemos nosso engano depois de alguns meses:

Para este problema, eu culparia tanto o Turbofan quanto o Sea of Nodes, em vez de apenas o último. Melhores auxiliares no Turbofan poderiam ter simplificado o gerenciamento das cadeias de efeito e controle, mas isso não teria sido um problema em um CFG.
O agendador é muito complexo
Eventualmente, todas as instruções precisam ser agendadas para gerar código assembly. A teoria para agendar instruções é simples o suficiente: cada instrução deve ser agendada após seus valores, entradas de controle e efeitos (ignorando loops).
Vejamos um exemplo interessante:

Você notará que, enquanto o programa JavaScript de origem tem duas divisões idênticas, o gráfico Sea of Node tem apenas uma. Na realidade, o Sea of Nodes começaria com duas divisões, mas como esta é uma operação pura (assumindo entradas do tipo double), a eliminação de redundância as deduplicaria facilmente em uma.
Então, ao chegar à fase de agendamento, precisaríamos encontrar um lugar para agendar esta divisão. Claramente, ela não pode vir após case 1 ou case 2, já que é usada em ambos. Em vez disso, teria que ser agendada antes do switch. O lado negativo é que, agora, a / b será computado mesmo quando c for 3, onde não há necessidade real de ser computado. Este é um problema real que pode fazer com que muitas instruções deduplicadas flutuem para o dominador comum de seus usuários, desacelerando muitos caminhos que não precisam delas.
Há, no entanto, uma solução: o agendador do Turbofan tentará identificar esses casos e duplicar as instruções para que sejam computadas apenas nos caminhos que as necessitam. O lado negativo é que isso torna o agendador mais complexo, exigindo lógica adicional para descobrir quais nós poderiam e deveriam ser duplicados e como duplicá-los.
Então, basicamente, começamos com 2 divisões, depois “otimizamos” para uma única divisão, e então otimizamos ainda mais para 2 divisões novamente. E isso não acontece só com divisões: muitas outras operações passam por ciclos semelhantes.
Encontrar uma boa ordem para visitar o gráfico é difícil
Todas as passagens de um compilador precisam visitar o gráfico, seja para reduzir nós, aplicar otimizações locais, ou executar análises em todo o gráfico. Em um CFG, a ordem para visitar os nós geralmente é direta: comece pelo primeiro bloco (assumindo uma função de entrada única) e itere por cada nó do bloco, prosseguindo para os sucessores e assim por diante. Em uma fase de otimização peephole (como redução de força), uma propriedade interessante de processar o gráfico nessa ordem é que as entradas são sempre otimizadas antes de um nó ser processado, e visitar cada nó exatamente uma vez geralmente é suficiente para aplicar a maioria das otimizações peephole. Considere, por exemplo, a seguinte sequência de reduções:

No total, foram necessários três passos para otimizar toda a sequência, e cada passo fez um trabalho útil. Após isso, a eliminação de código morto removeria v1 e v2, resultando em uma instrução a menos do que na sequência inicial.
Com o Sea of Nodes, não é possível processar instruções puras do início ao fim, pois elas não estão em nenhuma cadeia de controle ou de efeitos, e, portanto, não há um apontador para raízes puras ou algo do tipo. Em vez disso, a maneira usual de processar um gráfico do Sea of Nodes para otimizações peephole é começar do final (por exemplo, instruções return) e subir pelas entradas de valor, efeito e controle. Isso tem a vantagem de não visitarmos nenhuma instrução não usada, mas as vantagens param por aí, porque para otimização peephole, essa é a pior ordem de visitação possível. No exemplo acima, aqui estão os passos que tomaríamos:
- Comece visitando o
v3, mas não é possível reduzi-lo neste momento, então passe para suas entradas.- Visite
v1, reduza-o paraa << 3, depois passe para seus usos, caso a redução dev1lhes permita ser otimizados.- Visite
v3novamente, mas ainda não é possível reduzi-lo (desta vez, não visitaríamos suas entradas novamente, no entanto).
- Visite
- Visite
v2, reduza-o parab << 3, depois passe para seus usos, caso essa redução lhes permita ser otimizados.- Visite
v3novamente, reduza-o para(a & b) << 3.
- Visite
- Visite
Portanto, no total, v3 foi visitado 3 vezes, mas reduzido apenas uma vez.
Medimos este efeito em programas típicos de JavaScript há um tempo, e percebemos que, em média, os nós são alterados apenas uma vez a cada 20 visitas!
Outra consequência da dificuldade de encontrar uma boa ordem de visitação no gráfico é que o rastreamento de estado é difícil e caro. Muitas otimizações exigem o rastreamento de algum estado ao longo do gráfico, como a Eliminação de Carregamento ou a Análise de Escape. No entanto, isso é difícil de fazer com o Sea of Nodes, porque em um determinado ponto, é difícil saber se um estado dado precisa ser mantido vivo ou não, porque é difícil determinar se os nós não processados precisariam desse estado para serem processados. Como consequência disso, a fase de Eliminação de Carregamento do Turbofan tem um mecanismo de abandono em gráficos grandes para evitar demorar muito para terminar e consumir muita memória. Em comparação, escrevemos uma nova fase de eliminação de carregamento para nosso novo compilador CFG, que testamos ser até 190 vezes mais rápida (possui melhor complexidade no pior caso, tornando essa melhoria de velocidade fácil de atingir em gráficos grandes), enquanto usa muito menos memória.
Cache ineficiente
Quase todas as fases no Turbofan alteram o gráfico no local. Dado que os nós são relativamente grandes em memória (principalmente porque cada nó tem apontadores tanto para suas entradas quanto para seus usos), tentamos reutilizar os nós o máximo possível. No entanto, inevitavelmente, quando reduzimos nós para sequências de múltiplos nós, temos que introduzir novos nós, que necessariamente não serão alocados perto do nó original na memória. Como resultado, quanto mais avançamos pelo pipeline do Turbofan e mais fases executamos, menos amigável ao cache o gráfico se torna. Aqui está uma ilustração desse fenômeno:

É difícil estimar o impacto exato dessa ineficiência de cache na memória. Ainda assim, agora que temos nosso novo compilador CFG, podemos comparar o número de falhas de cache entre os dois: o Sea of Nodes sofre, em média, cerca de 3 vezes mais falhas de L1 dcache em comparação ao nosso novo IR CFG, e até 7 vezes mais em algumas fases. Estimamos que isso custa até 5% do tempo de compilação, embora esse número seja um pouco impreciso. Mesmo assim, tenha em mente que em um compilador JIT, compilar rápido é essencial.
A tipagem dependente do fluxo de controle é limitada
Vamos considerar a seguinte função em JavaScript:
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
Se até agora só vimos pequenos inteiros para x e para o resultado de x+1 (onde "pequenos inteiros" são inteiros de 31 bits, cf. Value tagging in V8), então especularemos que isso continuará sendo o caso. Se algum dia virmos x sendo maior que um inteiro de 31 bits, então desotimizaremos. De forma semelhante, se x+1 produzir um resultado maior que 31 bits, também desotimizaremos. Isso significa que precisamos verificar se x+1 é menor ou maior que o valor máximo que cabe em 31 bits. Vamos dar uma olhada nos gráficos CFG e SoN correspondentes:

(assumindo uma operação CheckedAdd que soma suas entradas e desotimiza se o resultado ultrapassar 31 bits)
Com um CFG, é fácil perceber que quando CheckedAdd(v1, 1) é executado, v1 está garantido a ser menor que 42, e, portanto, não há necessidade de verificar excesso de 31 bits. Assim, substituiríamos facilmente o CheckedAdd por um Add regular, que seria executado mais rapidamente e não exigiria um estado de desotimização (que é necessário para saber como retomar a execução após a desotimização).
No entanto, com um gráfico SoN, CheckedAdd, sendo uma operação pura, fluirá livremente no gráfico, e, portanto, não há como remover a verificação até que tenhamos computado um cronograma e decidido que o calcularemos após o ramo (nesse ponto, estamos de volta a um CFG, de modo que isso não é mais uma otimização SoN).
Essas operações verificadas são frequentes no V8 devido a esta otimização de inteiros pequenos de 31 bits, e a capacidade de substituir operações verificadas por operações não verificadas pode ter um impacto significativo na qualidade do código gerado pelo Turbofan. Então, o SoN do Turbofan coloca uma entrada de controle em CheckedAdd, o que pode habilitar essa otimização, mas também significa introduzir uma restrição de planejamento em um nó puro, ou seja, voltar para um CFG.
E muitos outros problemas...
Propagar inatividade é difícil. Frequentemente, durante algum rebaixamento, percebemos que o nó atual está, na verdade, inacessível. Em um CFG, poderíamos simplesmente cortar o bloco básico atual aqui, e os blocos seguintes automaticamente se tornariam obviamente inacessíveis, já que não teriam mais predecessores. No Sea of Nodes, é mais difícil, porque é necessário ajustar tanto a cadeia de controle quanto a cadeia de efeitos. Assim, quando um nó na cadeia de efeitos está inativo, precisamos percorrer a cadeia de efeitos até a próxima fusão, eliminando tudo ao longo do caminho e lidando cuidadosamente com nós que estão na cadeia de controle.
É difícil introduzir um novo fluxo de controle. Como os nós de fluxo de controle devem estar na cadeia de controle, não é possível introduzir um novo fluxo de controle durante os rebaixamentos regulares. Assim, se houver um nó puro no grafo, como Int32Max, que retorna o máximo de 2 inteiros e que eventualmente gostaríamos de rebaixar para if (x > y) { x } else { y }, isso não é facilmente viável no Sea of Nodes, porque precisaríamos de uma forma de descobrir onde na cadeia de controle encaixar este subgrafo. Uma maneira de implementar isso seria colocar o Int32Max na cadeia de controle desde o início, mas isso parece ser um desperdício: o nó é puro e deveria ser permitido mover-se livremente. Então, a maneira canonica do Sea of Nodes para resolver isso, usada tanto no Turbofan quanto também por Cliff Click (o inventor do Sea of Nodes), como mencionado neste Coffee Compiler Club, é adiar esse tipo de rebaixamento até que tenhamos um cronograma (e, assim, um CFG). Como resultado, temos uma fase no meio do pipeline que calcula um cronograma e rebaixa o grafo, onde muitas otimizações aleatórias são agrupadas porque todas exigem um cronograma. Em comparação, com um CFG, estaríamos livres para realizar essas otimizações anteriormente ou posteriormente no pipeline.
Além disso, lembre-se da introdução que um dos problemas do Crankshaft (o predecessor do Turbofan) era que era virtualmente impossível introduzir fluxo de controle após construir o grafo. O Turbofan é uma leve melhoria em relação a isso, já que o rebaixamento de nós na cadeia de controle pode introduzir novo fluxo de controle, mas isso ainda é limitado.
É difícil descobrir o que está dentro de um loop. Como muitos nós estão flutuando fora da cadeia de controle, é difícil descobrir o que está dentro de cada loop. Como resultado, otimizações básicas, como peeling de loops e desdobramento de loops, são difíceis de implementar.
Compilar é lento. Esta é uma consequência direta de múltiplos problemas que já mencionei: é difícil encontrar uma boa ordem de visitação para os nós, o que leva a muitas revisitações inúteis, rastrear estado é caro, o uso de memória é ruim, a localidade de cache é ruim... Isso pode não ser um grande problema para um compilador antecipado, mas em um compilador JIT, compilar lentamente significa que continuamos executando código não otimizado até que o código otimizado esteja pronto, enquanto desviamos recursos de outras tarefas (ex: outros trabalhos de compilação, ou o coletor de lixo). Uma consequência disso é que somos forçados a pensar muito cuidadosamente sobre o trade-off entre tempo de compilação e aceleração de novas otimizações, frequentemente errando para o lado de otimizar menos para manter a otimização rápida.
Sea of Nodes destrói qualquer planejamento anterior, por definição. O código-fonte do JavaScript geralmente não é manualmente otimizado com a microarquitetura da CPU em mente. No entanto, o código WebAssembly pode ser, seja no nível do código-fonte (por exemplo, C++), seja por meio de uma cadeia de ferramentas de compilação AOT (como Binaryen/Emscripten). Como resultado, um código WebAssembly poderia ser planejado de uma forma que deveria ser boa na maioria das arquiteturas (por exemplo, reduzindo a necessidade de spilling, assumindo 16 registradores). No entanto, o SoN sempre descarta o cronograma inicial e precisa confiar apenas em seu próprio agendador, que, devido às restrições de tempo da compilação JIT, pode ser facilmente pior do que o que um compilador AOT (ou um desenvolvedor C++ pensando cuidadosamente sobre o planejamento de seu código) poderia fazer. Já vimos casos em que o WebAssembly estava sofrendo com isso. E, infelizmente, usar um compilador CFG para WebAssembly e um compilador SoN para JavaScript no Turbofan também não era uma opção, já que usar o mesmo compilador para ambos permite a inclusão de ambos os idiomas.
Sea of Nodes: elegante mas impraticável para JavaScript
Então, para recapitular, aqui estão os principais problemas que temos com Sea of Nodes e Turbofan:
-
É muito complexo. Os encadeamentos de efeitos e controles são difíceis de entender, levando a muitos bugs sutis. Os gráficos são difíceis de ler e analisar, tornando as novas otimizações difíceis de implementar e refinar.
-
É muito limitado. Muitos nós estão na cadeia de efeitos e controle (porque estamos compilando código JavaScript), não oferecendo muitos benefícios em relação a um CFG tradicional. Além disso, porque é difícil introduzir novos fluxos de controle em rebaixamentos, até mesmo otimizações básicas acabam sendo difíceis de implementar.
-
A compilação é muito lenta. O rastreamento de estado é caro, porque é difícil encontrar uma boa ordem para visitar os gráficos. A localidade do cache é ruim. E alcançar pontos fixos durante as fases de redução demora muito.
Então, após dez anos lidando com o Turbofan e batalhando com o Sea of Nodes, finalmente decidimos nos livrar dele e, em vez disso, voltar a um IR CFG mais tradicional. Nossa experiência com nosso novo IR tem sido extremamente positiva até agora, e estamos muito felizes por ter voltado a um CFG: o tempo de compilação foi reduzido pela metade em comparação ao SoN, o código do compilador é muito mais simples e curto, investigar bugs geralmente é muito mais fácil, etc. Ainda assim, este post já está bem longo, então vou parar por aqui. Fique atento a um post de blog futuro que explicará o design do nosso novo CFG IR, Turboshaft.