一個關於懶惰的實習:去優化函數的惰性取消連結
大約三個月前,我作為實習生加入了 V8 團隊(Google 慕尼黑),自那時起,我一直在研究 VM 的 Deoptimizer —— 這對我來說是一個全新的領域,既有趣又充滿挑戰。我實習的第一部分專注於提升 VM 的安全性,第二部分則聚焦於性能改進,具體來說,是移除用於取消連結先前去優化函數的數據結構,這在垃圾回收期間曾是性能瓶頸。本文將描述我實習的第二部分。我將解釋 V8 從前如何取消連結去優化的函數,我們如何改變了這一過程,以及由此獲得的性能提升。
讓我們(非常)簡要地回顧一下 V8 對 JavaScript 函數的處理流程:V8 的解釋器 Ignition 在解釋函數時收集該函數的剖析信息。一旦函數變得熱絡,這些信息就會被傳遞給 V8 的編譯器 TurboFan,後者會生成優化的機器碼。如果剖析信息不再有效(例如,因為某個剖析的對象在運行時獲得了不同的類型),那麼優化的機器碼可能會變得無效。在這種情況下,V8 需要去優化它。
在優化過程中,TurboFan 為正在優化的函數生成了一個代碼物件,即優化的機器碼。當該函數下一次被調用時,V8 會跟隨連結到這段優化代碼並執行它。當函數被去優化時,我們需要取消連結該代碼物件,以確保它不會再被執行。這是如何發生的?
例如,在下面的代碼中,函數 f1 將被多次調用(每次都傳遞一個整數作為參數)。TurboFan 將會為這個特定情況生成機器碼。
function g() {
return (i) => i;
}
// 創建一個閉包。
const f1 = g();
// 優化 f1。
for (var i = 0; i < 1000; i++) f1(0);
每個函數也有一個跳板到解釋器——更多詳情見這些幻燈片——並在其 SharedFunctionInfo (SFI) 中保留指向這個跳板的指針。每當 V8 需要回到未優化的代碼時,就會使用這個跳板。因此,當觸發去優化(例如傳遞一個不同類型的參數時),去優化器可以簡單地將 JavaScript 函數的代碼欄位設置為這個跳板。
儘管這看起來很簡單,但它迫使 V8 維持指向優化 JavaScript 函數的弱列表。這是因為不同的函數可能指向同一個優化代碼物件。我們可以擴展我們的例子,如下所示,函數 f1 和 f2 都指向相同的優化代碼。
const f2 = g();
f2(0);
如果函數 f1 被去優化(比如通過用一個不同類型的對象 {x: 0} 調用它),我們需要確保無效的代碼不會在調用 f2 時再次執行。
因此,在去優化時,V8 從前會遍歷所有優化的 JavaScript 函數,並取消連結指向被去優化代碼的那些函數。在包含許多優化 JavaScript 函數的應用中,這樣的遍歷成為了性能瓶頸。此外,除了使去優化變慢外,V8 在垃圾回收的停止世界周期中也會遍歷這些列表,情況變得更加糟糕。
為了了解這種數據結構對 V8 性能的影響,我們寫了一個微基準測試,通過創建許多 JavaScript 函數並觸發次數眾多的掃描周期來強調其使用。
function g() {
return (i) => i + 1;
}
// 創建一個初始閉包並優化。
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// 建立 2M 閉包;這些閉包將使用之前已優化的程式碼。
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// 現在觸發垃圾回收;所有的操作都會變慢。
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
執行該基準測試時,我們發現 V8 約花費 98% 的執行時間在垃圾回收上。接著我們移除了這個數據結構,改用一種「延遲取消鏈接」的方法,我們在 x64 上觀察到了以下結果:

儘管這只是一個建立大量 JavaScript 函數並觸發許多垃圾回收周期的微型基準測試,我們仍然能看到由這個數據結構引入的額外負擔。我們在其他更現實的應用中也看到了些許的負擔,這些應用包括用 Node.js 實現的 路由器基準測試 和 ARES-6 基準測試套件。
延遲取消鏈接
與其在反優化時取消鏈接 JavaScript 函數的優化程式碼,V8 會延遲至該函數的下一次調用進行取消鏈接。當該函數被調用時,V8 會檢查它是否已被反優化,取消鏈接並繼續執行其延遲編譯。如果這些函數不再被調用,則它們永遠不會被取消鏈接,反優化的程式碼物件不會被回收。然而,由於在反優化過程中我們使程式碼物件的所有嵌入欄位失效,我們僅保留該程式碼物件滿足這些需求。
移除此優化 JavaScript 函數列表的 提交 需要對 VM 的多個部分進行更改,但基本理念如下。在組合優化程式碼物件時,我們檢查這是否是 JavaScript 函數的程式碼。如果是,在其序幕中,我們生成機器碼,以便在程式碼物件被反優化時退出。反優化時,我們不修改反優化程式碼——程式碼修補不存在。因此,當再次調用函數時,其 marked_for_deoptimization 位仍然設置。TurboFan 生成程式碼來檢查它,並且如果設置了該位,則 V8 跳轉至新的內建函數 CompileLazyDeoptimizedCode,取消該 JavaScript 函數的反優化程式碼鏈接,然後繼續進行延遲編譯。
更具體地說,第一步是生成指令以載入當前組合程式碼的地址。我們可以在 x64 上通過如下程式碼完成這一點:
Label current;
// 將當前指令的有效地址加載到 rcx 中。
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
之後,我們需要獲取 marked_for_deoptimization 位在程式碼物件中的存放位置。
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
我們可以測試該位,如果它被設置,我們跳轉到內建函數 CompileLazyDeoptimizedCode。
// 測試該位是否設置,即程式碼是否標記為反優化。
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// 如果設置了該位,則跳轉到內建函數程式碼。
__ j(not_zero, /* handle to builtin code here */, RelocInfo::CODE_TARGET);
在 CompileLazyDeoptimizedCode 內建函數的一側,剩下的工作是取消 JS 函數的程式碼字段鏈接,並將其設置為指向解釋器入口的跳板。所以,考慮到 JavaScript 函數的地址在寄存器 rdi 中,我們可以通過以下方式獲取指向 SharedFunctionInfo 的指針:
// 字段讀取以獲取 SharedFunctionInfo。
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
……類似地獲取跳板程式碼:
// 字段讀取以獲取程式碼物件。
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
然後我們可使用它更新函數槽位中的程式碼指針:
// 用跳板更新函數的程式碼字段。
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// 寫屏障以保護該字段。
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
這將產生與之前相同的結果。然而,不再在反優化器中處理取消鏈接,我們需要在程式碼生成期間關注此問題,因此使用了手寫彙編程式碼。
以上是x64 架構下的運作方式。我們已針對 ia32、arm、arm64、mips 和 mips64 完成了實現。
此新技術已整合至 V8 中,如稍後將討論的,該技術允許性能提升。然而,它帶來了一個小缺點:之前,V8 僅在反優化時考慮解除鏈接。現在,它需要在所有已優化函數的激活中進行。此外,檢查 marked_for_deoptimization 位的方法效率並非最佳,因為我們需要完成一些工作才能獲得代碼物件的地址。請注意,這在進入每個已優化函數時發生。解決此問題的一個可能方法是在代碼物件中保存一個指向自身的指針。這樣,V8 在函數被調用時不需要每次都找到代碼物件的地址,而是在其建構後僅需執行一次。
結果
現在我們來看看此專案獲得的性能增益和回歸。
x64 平台上的整體提升
下圖展示了相對於之前提交的一些改進和回歸。請注意,數值越高越好。
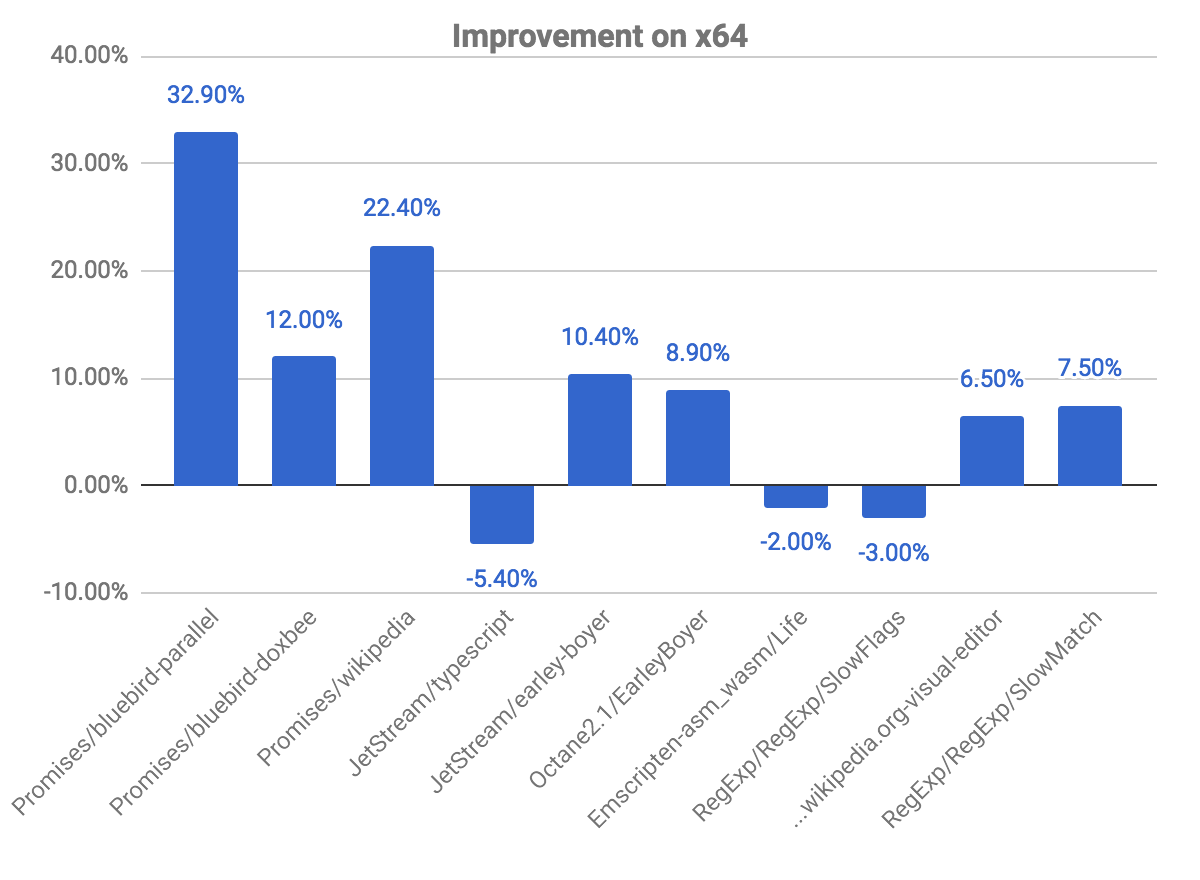
promises 基準測試中我們看到最大的提升,例如 bluebird-parallel 基準測試提高了近 33%,而 wikipedia 提高了 22.40%。但我們也在一些基準測試中觀察到少量回歸,與上述檢查代碼是否被標記為反優化的問題有關。
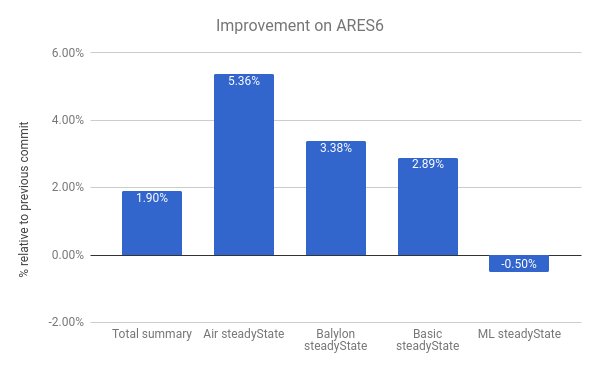
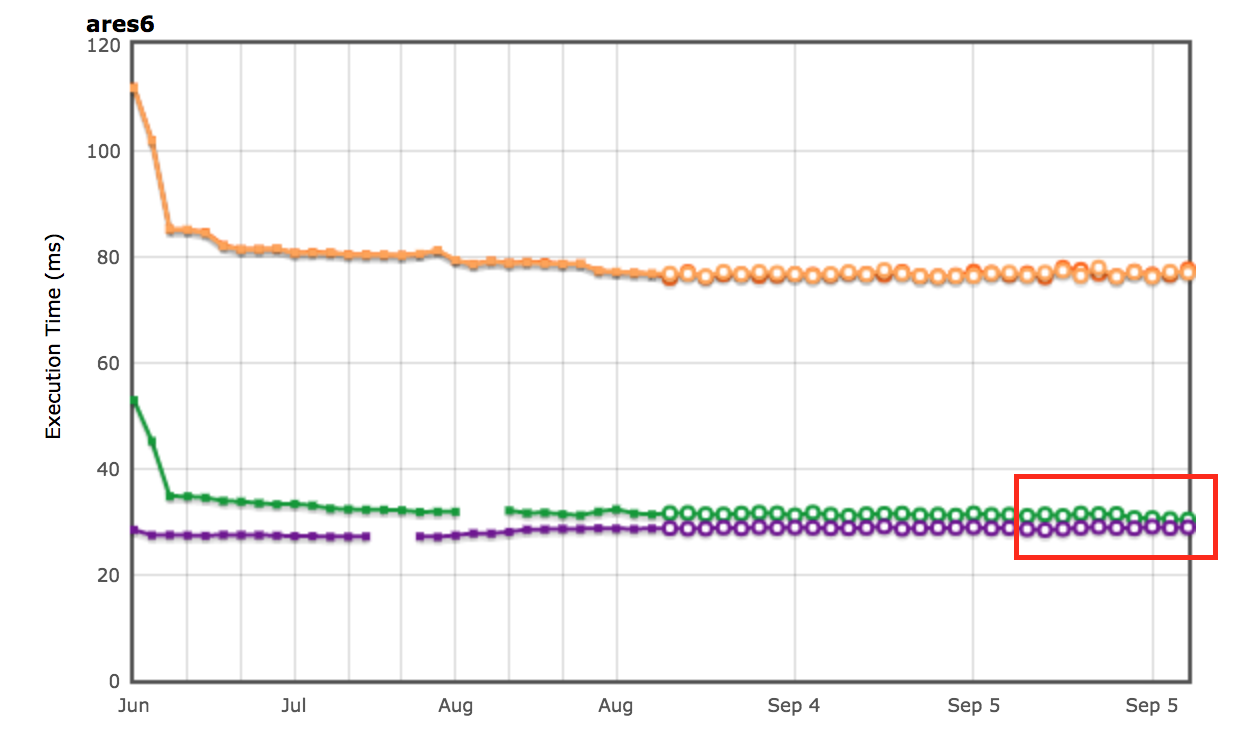
我們還在 ARES-6 基準測試套件中看到提升。注意在此圖表中,數值越高越好。這些程式過去花費了大量時間在與 GC 相關的活動中。使用惰性解除鏈接技術,我們將整體性能提升了 1.9%。其中最顯著的是 Air steadyState,提升了約 5.36%。
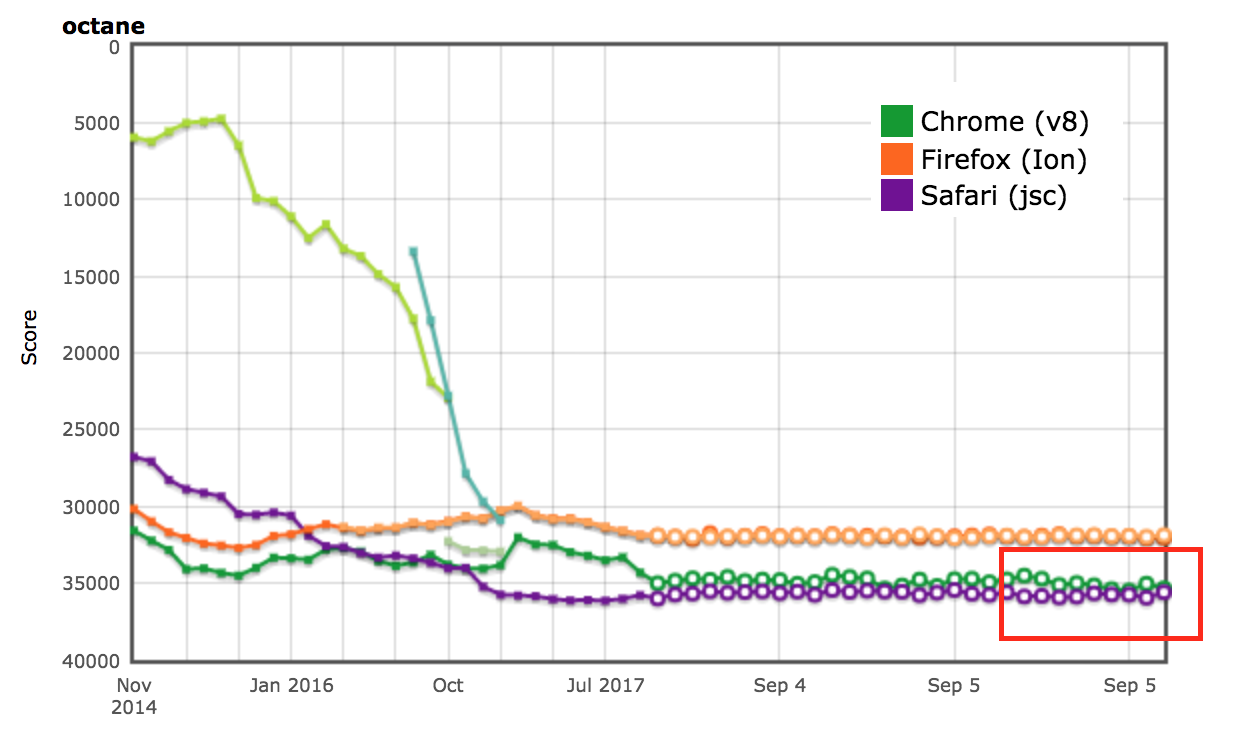
AreWeFastYet 測試結果
Octane 和 ARES-6 基準測試套件的性能結果也體現在 AreWeFastYet 追蹤器上。我們於 2017 年 9 月 5 日查看了這些性能結果,使用預設的測試機器(macOS 10.10 64-bit,Mac Pro,shell)。
對 Node.js 的影響
我們也在 router-benchmark 中觀察到了性能提升。下圖展示了每個測試的路由器每秒操作次數。數值越高越好。我們針對此基準測試套件執行了兩種類型的實驗。首先,分別執行每個測試,以便看到性能提升獨立於其他測試。其次,一次執行所有測試,而不切換 VM,模擬了一個每個測試均集成其他功能的環境。
在第一個實驗中,我們看到 router 和 express 測試在相同時間內執行的操作次數大約是之前的兩倍。在第二個實驗中,我們看到更大的提升。在一些案例中,例如 routr、server-router 和 router,基準測試分別執行了大約 3.80×、3× 和 2× 的操作次數。這是因為 V8 隨測試累積了更多已優化的 JavaScript 函數。因此,當執行某個測試時,如果觸發了垃圾收集週期,V8 必須訪問當前測試以及之前的測試中的已優化函數。


進一步優化
現在 V8 不再在上下文中保存 JavaScript 函數的鏈表,我們可以從 JSFunction 類中移除 next 字段。雖然這是一個簡單的修改,但它允許我們節省每個函數的指針大小,對於多數網頁來說這意味著顯著的節省:
| 基準測試 | 類型 | 存儲節省(絕對值) | 存儲節省(相對值) |
|---|---|---|---|
| facebook.com | 平均有效大小 | 170 KB | 3.70% |
| twitter.com | 分配物件的平均大小 | 284 KB | 1.20% |
| cnn.com | 分配物件的平均大小 | 788 KB | 1.53% |
| youtube.com | 分配物件的平均大小 | 129 KB | 0.79% |
致謝
在我的實習期間,我得到了許多人的幫助,他們總是隨時解答我的許多問題。因此,我要感謝以下幾位:Benedikt Meurer、Jaroslav Sevcik 和 Michael Starzinger,感謝他們就編譯器和反優化器運作方式與我的討論;Ulan Degenbaev,感謝他在我不小心弄壞垃圾收集器時提供幫助;以及 Mathias Bynens、Peter Marshall、Camillo Bruni 和 Maya Armyanova,感謝他們對本文進行校對。
最後,本文是我的最後一篇作品,作為 Google 實習生,我想藉此機會感謝 V8 團隊的每一位,尤其是我的導師 Benedikt Meurer,感謝他接待我並讓我有機會參與如此有趣的項目——我確實學到了很多,而且非常享受在 Google 的時光!