Земля на горизонте: покидаем Море узлов
Финальный уровень оптимизирующего компилятора V8 — Turbofan — известен тем, что является одним из немногих крупномасштабных компиляторов, использующих Море узлов (SoN). Однако, почти три года назад мы начали избавляться от Моря узлов и вернулись к более традиционному графу управления потоком (CFG) промежуточному представлению (IR), который мы назвали Turboshaft. На данный момент весь бэкенд JavaScript в Turbofan использует Turboshaft, и WebAssembly использует Turboshaft на протяжении всего своего конвейера. Две части Turbofan все еще используют некоторые элементы Моря узлов: встроенный конвейер, который мы постепенно заменяем на Turboshaft, и фронтенд JavaScript конвейера, который мы заменяем на Maglev, другое промежуточное представление на основе CFG. В этом посте объясняются причины, которые привели нас к отказу от Моря узлов.
12 лет назад, в 2013 году, в V8 был только один оптимизирующий компилятор: Crankshaft. Он использовал промежуточное представление на основе графа управления потоком. Первоначальная версия Crankshaft обеспечивала значительные улучшения производительности, несмотря на то, что все еще была довольно ограниченной в поддерживаемых функциях. В течение следующих нескольких лет команда продолжала улучшать его, чтобы генерировать еще более быстрый код в большем количестве ситуаций. Однако технический долг начинал накапливаться, и с Crankshaft начали возникать ряд проблем:
-
Он содержал слишком много вручную написанного машинного кода. Каждый раз, когда новый оператор добавлялся в промежуточное представление, его перевод в машинный код приходилось вручную писать для четырех архитектур, официально поддерживаемых V8 (x64, ia32, arm, arm64).
-
Он испытывал сложности с оптимизацией asm.js, который тогда рассматривался как важный шаг к высокопроизводительному JavaScript.
-
Он не позволял вводить управление потоком на этапе понижения. Иначе говоря, управление потоком создавалось на этапе построения графа и затем было окончательным. Это было серьезным ограничением, учитывая, что распространенной практикой при написании компиляторов является начало с операций высокого уровня, а затем их снижение до операций низкого уровня, часто с введением дополнительного управления потоком. Например, операция высокого уровня
JSAdd(x,y)могла бы быть уменьшена до чего-то вродеif (x is String and y is String) { StringAdd(x, y } else { … }. Однако это было невозможно в Crankshaft. -
Try-catch выражения не поддерживались, а их поддержка была чрезвычайно сложной: несколько инженеров потратили месяцы, пытаясь их реализовать, но безуспешно.
-
Он страдал от множества проблем с производительностью и откатов. Использование определенной функции или инструкции, либо столкновение с краевым случаем функции могло снизить производительность в 100 раз. Это затрудняло написание эффективного кода для разработчиков JavaScript и предсказание производительности их приложений.
-
Он содержал много циклов деоптимизации: Crankshaft оптимизировал функцию, используя некоторые предположения, затем функция деоптимизировалась, когда предположения не оправдывались, но слишком часто Crankshaft повторно оптимизировал функцию с теми же предположениями, вызывая бесконечные циклы оптимизации-деоптимизации.
Каждая из этих проблем могла бы быть, вероятно, решена индивидуально. Однако в совокупности они выглядели слишком масштабными. Поэтому было принято решение заменить Crankshaft новым компилятором, написанным с нуля: Turbofan. И вместо использования традиционного промежуточного представления на основе CFG, Turbofan использовал более мощное промежуточное представление: Море узлов. На тот момент это представление уже более 10 лет использовалось в C2, JIT-компиляторе Java HotSpot Virtual Machine.
Но что же такое Море узлов?
Сначала небольшой напоминание о графе управления потоком (CFG): CFG — это представление программы в виде графа, где узлы графа представляют базовые блоки программы (последовательность инструкций без входящих или исходящих ветвлений или прыжков), а ребра представляют управление потоком программы. Вот простой пример:

Инструкции внутри базового блока неявно упорядочены: первая инструкция должна быть выполнена перед второй, а вторая — перед третьей и так далее. В приведенном выше небольшом примере это ощущается вполне естественно: v1 == 0 в любом случае нельзя вычислить до того, как было вычислено x % 2. Однако рассмотрим

Здесь CFG явно навязывает выполнение a * 2 до b * 2, хотя мы вполне могли бы выполнить их в обратном порядке.
Именно в этом помогает Sea of Nodes: Sea of Nodes не представляет базовые блоки, а только истинные зависимости между инструкциями. Узлы в Sea of Nodes представляют собой отдельные инструкции (вместо базовых блоков), а ребра представляют использование значений (то есть: ребро от a к b представляет факт, что a использует b). Вот как последний пример был бы представлен с помощью Sea of Nodes:

В конечном итоге компилятору потребуется сгенерировать ассемблерный код, а затем последовательно выполнить эти два умножения, но до этого момента между ними больше не будет зависимости.
Теперь добавим управление потоком в сочетание. Узлы управления (например, branch, goto, return) обычно не имеют зависимостей значений между собой, которые бы заставляли устанавливать определенный порядок, даже если они однозначно должны быть упорядочены определенным образом. Таким образом, чтобы представить управление потоком, нам нужен новый тип ребра, control edges, которые накладывают определенный порядок на узлы, не имеющие зависимости значений:

В этом примере, без контрольных ребер, ничего бы не помешало выполнить returns перед branch, что, очевидно, было бы неправильно.
Ключевым моментом является то, что контрольные ребра только устанавливают порядок операций, для которых есть такие входящие или исходящие ребра, но не для других операций, таких как арифметические операции. Это основное отличие между Sea of Nodes и графиками управления потоком.
Теперь добавим операции с эффектами (например, загрузки и записи из памяти и в память) в сочетание. Аналогично узлам управления, операции с эффектами часто не имеют зависимости значений, но все же не могут выполняться в случайном порядке. Например, a[0] += 42; x = a[0] и x = a[0]; a[0] += 42 не равнозначны. Таким образом, нам нужен способ наложить порядок (= расписание) на операции с эффектами. Мы могли бы использовать управляющую цепочку для этой цели, но это было бы более строгим, чем требуется. Например, рассмотрим этот небольшой фрагмент:
let v = a[2];
if (c) {
return v;
}
Добавляя a[2] (которая считывает память) в управляющую цепочку, мы вынуждаем выполнить ее перед разветвлением по c, хотя, на практике, эту загрузку можно легко выполнить после разветвления, если ее результат используется только внутри тела then-разветвления. Имея много узлов в программе в управляющей цепочке, мы лишаем Sea of Nodes его цели, так как мы фактически обретаем промежуточное представление подобное CFG, где только чистые операции остаются.
Таким образом, чтобы насладиться большей свободой и действительно извлечь выгоду из Sea of Nodes, в Turbofan есть другой тип ребра, effect edges, которые накладывают некоторый порядок на узлы, имеющие побочные эффекты. Пока игнорируем контроль потока и рассмотрим небольшой пример:

В этом примере arr[0] = 42 и let x = arr[a] не имеют зависимости значений (т.е. первый не является входом для второго, и наоборот). Однако, поскольку a может быть равным 0, arr[0] = 42 должен быть выполнен до x = arr[a], чтобы последний всегда загружал правильное значение из массива.
Заметим, что в Turbofan есть одна единственная цепочка эффектов (которая делится на ветвлениях и сливается обратно при слиянии управления потока), которая используется для всех операций с эффектами, хотя возможно иметь несколько цепочек эффектов, где операции, не имеющие зависимостей, могли бы быть в разных цепочках эффектов, тем самым расслабляя их расписание (см. Глава 10 SeaOfNodes/Simple для более подробной информации). Однако, как мы объясним позже, поддерживать единую цепочку эффектов уже очень сложно, поэтому в Turbofan мы не пытались иметь несколько цепочек.
И, конечно, большинство реальных программ будут содержать как управление потоком, так и операции с эффектами.

Заметьте, что store и load требуют контрольных входов, так как они могут быть защищены различными проверками (такими как проверки типа или проверки границ).
Этот пример хорошо демонстрирует мощь модели «Sea of Nodes» по сравнению с CFG: y = x * c используется только в ветке else, поэтому этот узел будет свободно перемещен после ветки branch, а не вычислен до нее, как это было в оригинальном JavaScript-коде. Это также относится и к arr[0], который используется только в ветке else, и может быть перемещен после ветки branch (хотя на практике Turbofan не переместит arr[0] вниз, по причинам, которые я объясню позже).
Для сравнения, вот как будет выглядеть соответствующий CFG:

Уже сейчас мы начинаем замечать основную проблему с SoN: она гораздо сильнее отдалена как от исходного кода, так и от выходного (ассемблерного) представления компилятора, чем CFG, что делает её менее интуитивной для понимания. Более того, необходимость всегда явно указывать зависимости по эффектам и управлению затрудняет быстрое осмысление графа и создание понижений (так как понижения всегда должны явно поддерживать цепочки управления и эффектов, которые в CFG неявны).
И начинаются проблемы…
После более чем десятилетнего опыта работы с моделью Sea of Nodes, мы пришли к выводу, что у нее больше недостатков, чем преимуществ, по крайней мере в контексте JavaScript и WebAssembly. Мы подробно рассмотрим несколько из этих проблем ниже.
Вручную/визуально инспектировать и понимать граф Sea of Nodes – сложно
Мы уже видели, что на маленьких программах CFG легче читается, так как он ближе к исходному коду, к которому привыкли разработчики (включая инженеров компиляторов!). Для сомневающихся читателей я приведу немного больший пример, чтобы вы лучше поняли проблему. Рассмотрим следующую JavaScript-функцию, которая объединяет массив строк:
function concat(arr) {
let res = "";
for (let i = 0; i < arr.length; i++) {
res += arr[i];
}
return res;
}
Вот соответствующий граф Sea of Nodes на середине этапа компиляции в Turbofan (что означает, что некоторые понижения уже произошли):
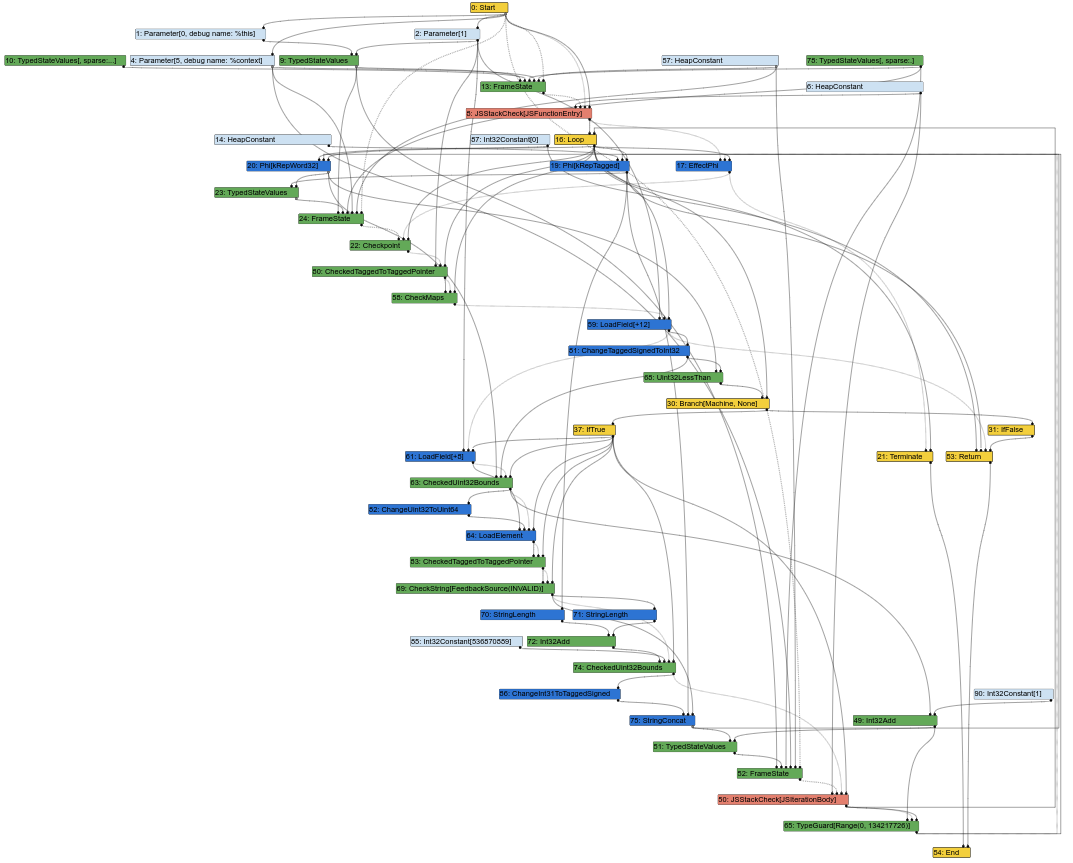
Уже сейчас граф начинает напоминать беспорядочную кучу узлов. И, как инженер компилятора, большая часть моей работы заключается в анализе графов Turbofan для понимания багов или поиска возможностей для оптимизации. Ну, это не так просто, когда граф выглядит так. В конце концов, вход компилятора — это исходный код, который имеет структуру, похожую на CFG (инструкции имеют фиксированное положение в заданном блоке), а выход компилятора — это ассемблер, который также имеет структуру, похожую на CFG (инструкции также имеют фиксированное положение в заданном блоке). Таким образом, наличие IR, похожей на CFG, упрощает задачу инженерам компиляторов сопоставлять элементы IR с исходным кодом или сгенерированным ассемблером.
Для сравнения, вот соответствующий граф CFG (который у нас есть, так как мы уже начали процесс замены Sea of Nodes на CFG):
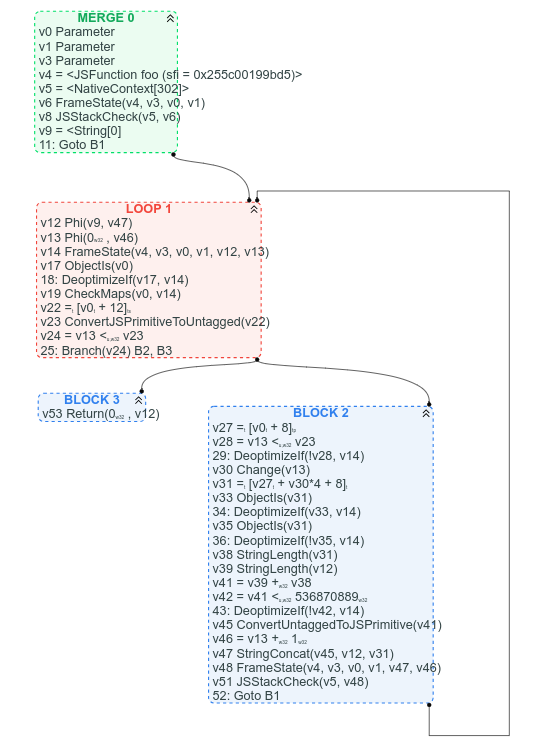
Среди прочего, с CFG ясно, где находится цикл, ясно, каково условие выхода из цикла, и легко найти инструкции в CFG, основываясь на том, где мы ожидаем их увидеть: например arr.length можно найти в заголовке цикла (это v22 = [v0 + 12]), а объединение строк можно найти ближе к концу цикла (v47 StringConcat(...)).
Разумеется, цепочки использования значений труднее отслеживать в версии CFG, но я бы сказал, что чаще всего лучше четко видеть структуру управления графом, чем неупорядоченную кучу узлов значений.
Слишком много узлов находятся в цепочке эффектов и/или имеют вход управления
Чтобы извлечь выгоду из Sea of Nodes, большинство узлов в графе должны свободно перемещаться, не принадлежать цепочке управления или эффектов. К сожалению, в типичном JavaScript-графе это не так, потому что почти все универсальные операции JS могут иметь произвольные побочные эффекты. Тем не менее, они должны быть редкостью в Turbofan, так как у нас есть обратная связь, которая должна позволить оптимизировать их в более специфичные операции.
Тем не менее, каждая операция с памятью требует как входа для эффектов (поскольку загрузка не должна перемещаться перед сохранением, и наоборот), так и управляющего входа (поскольку перед операцией может потребоваться проверка типа или границы). И даже некоторые чистые операции, такие как деление, требуют управляющих входов, так как у них могут быть особые случаи, защищенные проверками.
Посмотрим на конкретный пример и начнем с следующей JavaScript-функции:
function foo(a, b) {
// предположим, что `a.str` и `b.str` — это строки
return a.str + b.str;
}
Вот соответствующий граф Turbofan. Чтобы прояснить ситуацию, я выделил часть цепочки эффектов пунктирными красными линиями и отметил несколько узлов номерами, чтобы я мог обсудить их ниже.
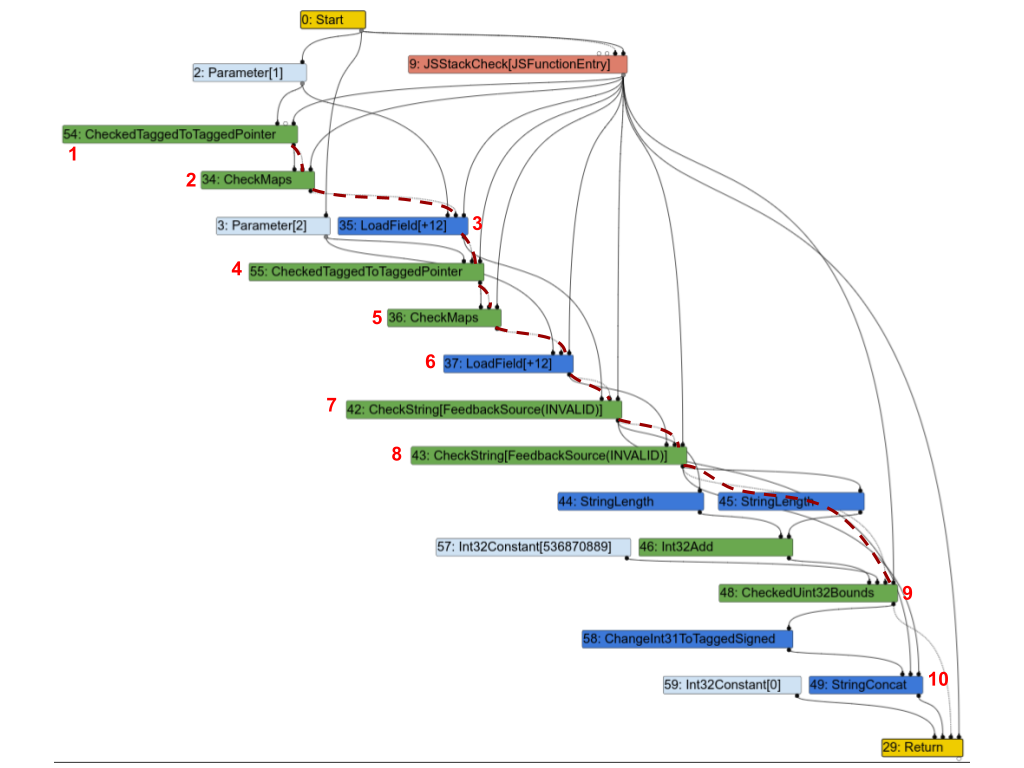
Первое наблюдение: почти все узлы находятся в цепочке эффектов. Рассмотрим некоторые из них и посмотрим, действительно ли они должны там находиться:
1(CheckedTaggedToTaggedPointer): это проверяет, что первый вход функции является указателем, а не “маленьким целым числом” (см. Сжатие указателей в V8). Само по себе, этому узлу не нужен вход эффекта, но на практике он все же должен находиться в цепочке эффектов, поскольку он защищает последующие узлы.2(CheckMaps): теперь, когда мы знаем, что первый вход является указателем, этот узел загружает его “карту” (см. Карты (Скрытые классы) в V8) и проверяет, что она совпадает с тем, что записано в фидбеке для этого объекта.3(LoadField): теперь, когда мы знаем, что первый объект является указателем с правильной картой, мы можем загрузить его поле.str.4,5и6повторяют процесс для второго входа.7(CheckString): теперь, когда мы загрузилиa.str, этот узел проверяет, что это действительно строка.8: повторяет процесс для второго входа.9: проверяет, что объединенная длинаa.strиb.strменьше максимального размера строки в V8.10(StringConcat): наконец объединяет две строки.
Этот график является весьма типичным для графиков Turbofan для программ на JavaScript: проверка карт, загрузка значений, проверка карт загруженных значений и так далее, и в итоге выполнение нескольких вычислений с этими значениями. И как в этом примере, во многих случаях большинство инструкций оказываются в цепочке эффектов или контроля, которые налагают строгую последовательность операций и полностью лишают смысл существования Sea of Nodes.
Операции с памятью не «плавают» легко
Рассмотрим следующую программу на JavaScript:
let x = arr[0];
let y = arr[1];
if (c) {
return x;
} else {
return y;
}
Учитывая, что x и y используются только в одной стороне блока if-else, мы могли бы надеяться, что SoN позволит им свободно перемещаться вниз в ветви “then” и “else”. Однако на практике сделать это в SoN не легче, чем в CFG. Рассмотрим график SoN, чтобы понять, почему:

Когда мы строим график SoN, мы создаем цепочку эффектов по мере прохождения, и таким образом второй Load оказывается сразу после первого, затем цепочка эффектов должна разделиться, чтобы достичь обеих инструкций return (если вы спрашиваете, почему return находятся в цепочке эффектов, это потому, что перед возвратом из функции могут быть операции с побочными эффектами, такие как Store, которые должны быть выполнены перед возвратом). Учитывая, что второй Load является предшественником для обеих инструкций return, он должен быть запланирован перед branch, и SoN таким образом не позволяет любому из двух Load свободно перемещаться вниз.
Чтобы переместить Load вниз в ветви “then” и “else”, нам пришлось бы вычислить, что между ними нет побочных эффектов, и что между вторым Load и return также нет побочных эффектов, тогда мы могли бы разделить цепочку эффектов в начале, а не после второго Load. Проведение такого анализа на графике SoN или на CFG крайне схоже.
Теперь, когда мы упомянули, что многие узлы оказываются в цепочке эффектов, и что узлы с эффектами обычно не перемещаются далеко, это хорошее время, чтобы осознать, что в некотором смысле SoN — это просто CFG, где чистые узлы плавают. В действительности, управляемые узлы и цепочка управления всегда отражают структуру эквивалентного CFG. И, когда обе цели ветвления имеют побочные эффекты (что часто бывает в JavaScript), цепочка эффектов разделяется и объединяется точно там, где цепочка управления (как и в приведенном примере: цепочка управления разделяется на branch, а цепочка эффектов это зеркально отображает, разделяясь на Load; и если программа продолжится после блока if-else, обе цепочки объединятся в том же месте). Узлы с эффектами обычно оказываются ограничены и запланированы между двумя узлами управления, то есть в базовом блоке. А внутри этого базового блока цепочка эффектов будет ограничивать узлы с эффектами в том порядке, в котором они были в исходном коде. В итоге только чистые узлы действительно перемещаются свободно.
Один из способов добиться большего числа узлов, которые могут плавать, — это использование нескольких цепочек эффектов, упомянутых ранее, но это имеет свою цену: во-первых, управление одной цепочкой эффектов уже сложно; управление несколькими будет намного сложнее. Во-вторых, в динамическом языке, таком как JavaScript, мы сталкиваемся с множеством доступов к памяти, которые могут перекрываться, что означает, что множественные цепочки эффектов придется часто объединять, тем самым нивелируя часть преимуществ наличия нескольких цепочек эффектов.
Ручное управление цепочками эффектов и управления — это сложно
Как упомянуто в предыдущем разделе, хотя цепочки эффектов и управления несколько различны, на практике цепочка эффектов обычно имеет ту же “форму”, что и цепочка управления: если в целях ветвления содержатся операции с эффектами (а это часто бывает), то цепочка эффектов будет разделена на ветвлении и объединится обратно, когда поток управления объединится. Поскольку мы имеем дело с JavaScript, многие узлы имеют побочные эффекты, и у нас есть множество ветвлений (как правило, ветвление по типу некоторых объектов), что приводит к необходимости отслеживать как цепочку эффектов, так и цепочку управления параллельно, тогда как в CFG нам нужно было бы отслеживать только цепочку управления.
История показала, что управление как цепочками эффектов, так и цепочками управления вручную склонно к ошибкам, трудно читаемо и трудно поддерживаемо. Возьмем этот пример кода из фазы JSNativeContextSpecialization:
JSNativeContextSpecialization::ReduceNamedAccess(...) {
Effect effect{...};
[...]
Node* receiverissmi_effect = effect;
[...]
Effect this_effect = effect;
[...]
this_effect = graph()->NewNode(common()->EffectPhi(2), this_effect,
receiverissmi_effect, this_control);
receiverissmi_effect = receiverissmi_control = nullptr;
[...]
effect = graph()->NewNode(common()->EffectPhi(control_count), ...);
[...]
}
Из-за различных ветвлений и случаев, которые нужно обработать, мы в итоге управляем тремя различными цепочками эффектов. Легко ошибиться и использовать одну цепочку эффектов вместо другой. Настолько легко, что мы действительно ошиблись изначально, и только осознали нашу ошибку через несколько месяцев:

В этом вопросе я бы обвинил как Turbofan, так и Sea of Nodes, а не только последний. Лучшие помощники в Turbofan могли бы упростить управление цепочками эффектов и управления, но это не было бы проблемой в CFG.
Планировщик слишком сложен
В конце концов, все инструкции должны быть запланированы для генерации ассемблерного кода. Теория для планирования инструкций достаточно проста: каждую инструкцию нужно запланировать после её значений, входов управления и эффектов (игнорируя циклы).
Давайте рассмотрим интересный пример:

Вы заметите, что хотя исходная программа на JavaScript имеет два идентичных деления, граф Sea of Nodes имеет только одно. На самом деле Sea of Nodes начнет с двух делений, но поскольку это чистая операция (при условии, что входы — числа с плавающей точкой), устранение избыточности легко объединит их в одно.
Затем, достигнув этапа планирования, нам придется найти место, чтобы запланировать это деление. Очевидно, оно не может быть после case 1 или case 2, так как используется в другом. Вместо этого оно должно быть запланировано перед switch. Недостаток состоит в том, что теперь операция a / b будет выполняться даже когда c равно 3, где она не требуется. Это настоящая проблема, которая может привести к тому, что многие устраненные инструкции всплывут к общему доминатору своих пользователей, замедляя многие пути, которые их не требуют.
Однако есть решение: планировщик Turbofan постарается идентифицировать эти случаи и дублировать инструкции, чтобы они выполнялись только на путях, которые их требуют. Недостаток состоит в том, что это делает планировщик более сложным, требуя дополнительной логики для определения, какие узлы можно и нужно дублировать, а также как их дублировать.
Итак, фактически, мы начали с двух делений, затем "оптимизировали" до одного, и затем ещё раз оптимизировали до двух. И это происходит не только с операцией деления: множество других операций проходит через подобные циклы.
Сложно найти хороший порядок для обхода графа
Все проходы компилятора должны обходить граф, будь то для снижения узлов, применения локальных оптимизаций или проведения анализа всего графа. В CFG порядок обхода узлов обычно прост: начните с первого блока (с учетом функции с одним входом), затем итеративно проходите каждый узел блока, после чего переходите к преемникам и так далее. В фазе peephole оптимизации (например, снижение мощности операций) приятным свойством обработки графа в таком порядке является то, что входы всегда оптимизируются перед обработкой узла, и посещение каждого узла ровно один раз достаточно для применения большинства peephole оптимизаций. Рассмотрим, например, следующую последовательность сокращений:

В сумме потребовалось три шага для оптимизации всей последовательности, и каждый шаг был полезен. После этого удаление мертвого кода устранило v1 и v2, что привело к одному инструктажу меньше, чем в начальной последовательности.
С системой Sea of Nodes невозможно обработать чистые инструкции от начала до конца, так как они не принадлежат никакой цепочке управления или эффектов, и, следовательно, нет указателя на чистые корни или что-либо подобное. Вместо этого, стандартный способ обработки графа Sea of Nodes для peephole-оптимизаций заключается в начальной обработке конца (например, инструкций return) и продвижении вверх по значениям, эффектам и входам управления. Это имеет важное свойство: мы не будем посещать никакую неиспользуемую инструкцию. Но преимущества этого подхода заканчиваются на этом, потому что для peephole-оптимизаций это примерно худший порядок посещения, который можно получить. В примере выше шаги следующие:
- Начать посещение с
v3, но невозможно оптимизировать его на этом этапе, затем перейти к его входам- Посетить
v1, оптимизировать его доa << 3, затем перейти к его использованиям, чтобы проверить, позволяет ли оптимизацияv1улучшить их.- Снова посетить
v3, но пока не удается оптимизировать его (в этот раз мы больше не будем посещать его входы)
- Снова посетить
- Посетить
v2, оптимизировать его доb << 3, затем перейти к его использованиям, чтобы проверить, позволяет ли эта оптимизация улучшить их.- Снова посетить
v3, оптимизировать его до(a & b) << 3.
- Снова посетить
- Посетить
Таким образом, в общей сложности v3 был посещен 3 раза, но только один раз оптимизирован.
Мы измерили этот эффект на типичных JavaScript-программах некоторое время назад и выяснили, что, в среднем, узлы изменяются только один раз на каждые 20 посещений!
Еще один вывод из сложности нахождения хорошего порядка посещения графа заключается в том, что отслеживание состояния сложно и дорого. Многие оптимизации требуют отслеживания состояния вдоль графа, такие как Load Elimination или Escape Analysis. Однако сделать это сложно в системе Sea of Nodes, потому что на определенном этапе трудно понять, нужно ли поддерживать данное состояние, так как трудно определить, потребуют ли этого необработанные узлы. В результате этого этап Load Elimination в Turbofan имеет механизм выхода для больших графов, чтобы избежать слишком длительного процесса и чрезмерного потребления памяти. Для сравнения, мы написали новую фазу Load Elimination для нашего нового компилятора CFG, которая, по нашим тестам, работает до 190 раз быстрее (у нее лучшее сложность в худшем случае, поэтому такого рода ускорение легко достигнуть на больших графах) и требует значительно меньше памяти.
Неприветливость кэширования
Почти все этапы в Turbofan изменяют граф на месте. Учитывая, что узлы занимают довольно много памяти (в основном потому, что каждый узел имеет указатели как на свои входы, так и на свои использования), мы стараемся переиспользовать узлы как можно больше. Однако неизбежно, что при оптимизации узлов до последовательностей из нескольких узлов приходится вводить новые узлы, которые обязательно не будут выделены близко к исходному узлу в памяти. В результате, чем дальше мы продвигаемся по конвейеру Turbofan и чем больше этапов мы проходим, тем менее дружелюбным к кэшированию становится граф. Вот иллюстрация этого явления:

Трудно оценить точное воздействие этого явления на память. Тем не менее теперь, когда у нас есть новый компилятор CFG, мы можем сравнить количество пропусков кэша между ними: Sea of Nodes страдает в среднем от примерно 3 раза большего количества пропусков L1 dcache по сравнению с нашим новым CFG IR, и до 7 раз больше в некоторых этапах. Мы оцениваем, что это увеличивает время компиляции на целых 5%, хотя эта цифра несколько приблизительная. Тем не менее, важно помнить, что в JIT-компиляторе быстрая компиляция является ключевым аспектом.
Ограниченность типов, зависящих от управления потоком
Рассмотрим следующий JavaScript-функцию:
function foo(x) {
if (x < 42) {
return x + 1;
}
return x;
}
Если до сих пор мы видели только маленькие целые числа для x и для результата x+1 (где "маленькие целые числа" — это 31-битные целые числа, см. Маркировка значений в V8), то мы будем предполагать, что это останется так. Если мы когда-либо увидим x, превышающий 31-битное целое число, тогда мы деоптимизируем. Аналогично, если x+1 даст результат, который превышает 31 бит, мы также деоптимизируем. Это означает, что нам нужно проверить, является ли x+1 меньшим или большим максимального значения, которое помещается в 31 бит. Давайте посмотрим на соответствующие графы CFG и SoN:

(предполагая операцию CheckedAdd, которая прибавляет свои входы и деоптимизирует, если результат превышает 31 бит)
С помощью CFG легко понять, что при выполнении CheckedAdd(v1, 1) v1 гарантированно меньше 42, и, следовательно, нет необходимости проверять переполнение 31-битного значения. Таким образом, мы могли бы легко заменить CheckedAdd на обычное Add, которое выполнялось бы быстрее и не требовало бы состояния деоптимизации (что в противном случае требуется для восстановления выполнения после деоптимизации).
Однако с графом SoN операция CheckedAdd, будучи чистой, будет свободно перемещаться в графе, и, следовательно, невозможно удалить проверку, пока мы не вычислим расписание и не решим, что будем выполнять ее после ветвления (и в этот момент мы возвращаемся к CFG, так что это больше не оптимизация SoN).
Такие проверенные операции часто встречаются в V8 из-за этой оптимизации 31-битного малого целого числа, и возможность замены проверенных операций на непроверенные операции может значительно повлиять на качество кода, сгенерированного Turbofan. Таким образом, Turbofan’s SoN устанавливает управляющий вход на CheckedAdd, что может включить эту оптимизацию, но также означает введение ограничения на расписание в чистом узле, то есть возвращение к CFG.
И множество других вопросов...
Распространение недоступности сложно. Часто, во время некоторого понижения, мы осознаем, что текущий узел фактически недоступен. В CFG мы могли бы просто разорвать текущий базовый блок здесь, и последующие блоки автоматически становились бы очевидно недоступными, поскольку у них больше не было бы предшественников. В Sea of Nodes это сложнее, потому что нужно исправить как управляющую, так и эффектовую цепочку. Поэтому, когда узел в эффектовой цепочке недоступен, нам нужно продвигаться вперед по эффектовой цепочке до следующего объединения, уничтожая все по пути, и аккуратно обрабатывая узлы, которые находятся в управляющей цепочке.
Сложно вводить новый поток управления. Поскольку узлы потока управления должны находиться в управляющей цепочке, невозможно вводить новый поток управления во время регулярного понижения. Поэтому, если в графе есть чистый узел, такой как Int32Max, который возвращает максимум из двух целых чисел и который мы в конечном итоге хотели бы понизить к if (x > y) { x } else { y }, это сложно сделать в Sea of Nodes, потому что нам нужно найти способ подключить этот подграф в управляющую цепочку. Один из способов реализации этого заключается в том, чтобы поместить Int32Max в управляющую цепочку с самого начала, но это кажется расточительным: узел чистый и должен иметь возможность свободно перемещаться. Таким образом, каноническим способом решения этого в Sea of Nodes, используемым как в Turbofan, так и Клиффом Кликом (изобретателем Sea of Nodes), как упоминается в этой беседе Coffee Compiler Club, является откладывание такого рода понижений до тех пор, пока у нас не будет расписания (и, следовательно, CFG). В результате у нас есть стадия примерно в середине конвейера, которая вычисляет расписание и понижает граф, где множество случайных оптимизаций упакованы вместе, потому что они все требуют расписания. В сравнении, с CFG мы могли бы выполнять эти оптимизации раньше или позже в конвейере.
Также, помните из введения, что одной из проблем Crankshaft (предшественника Turbofan) было то, что практически невозможно было вводить поток управления после создания графа. Turbofan является небольшим улучшением в этом отношении, так как понижение узлов в управляющей цепочке может вводить новый поток управления, но это всё ещё ограничено.
Сложно определить, что находится внутри цикла. Поскольку множество узлов находятся вне управляющей цепочки, сложно определить, что находится внутри каждого цикла. В результате, базовые оптимизации, такие как развёртка цикла и разбиение цикла, сложно реализовать.
Скомпилировать медленно. Это прямое следствие множества проблем, которые я уже упоминал: сложно найти хороший порядок обхода узлов, что приводит к множеству бесполезных повторных обходов, отслеживание состояния дорого, использование памяти плохо, локальность кэша плохо… Это может быть не большой проблемой для компилятора с предварительным временем, но в JIT-компиляторе медленная компиляция означает, что мы продолжаем выполнять медленный неоптимизированный код до тех пор, пока оптимизированный код не будет готов, отнимая ресурсы у других задач (например, других компиляционных задач или сборщика мусора). Один из последствий этого заключается в том, что мы вынуждены очень внимательно обдумывать компромиссы между временем компиляции и ускорением новых оптимизаций, часто склоняясь к стороне меньшей оптимизации, чтобы сохранить высокую скорость оптимизации.
Sea of Nodes разрушает любое предыдущее расписание по своей конструкции. Исходный код JavaScript, как правило, не оптимизирован вручную с учётом микроархитектуры ЦП. Однако код WebAssembly может быть оптимизирован либо на уровне исходного кода (например, C++), либо инструментальной цепочкой предварительного времени (AOT) компиляции (например, Binaryen/Emscripten). В результате, код WebAssembly может быть запланирован таким образом, чтобы быть эффективным на большинстве архитектур (например, уменьшая необходимость в переполнении, предполагая наличие 16 регистров). Однако, SoN всегда отбрасывает изначальное расписание и вынуждена полагаться только на свой собственный планировщик, который из-за временных ограничений JIT-компиляции может легко оказаться хуже, чем то, что мог бы сделать компилятор AOT (или разработчик C++, внимательно продумывающий расписание своего кода). Мы видели случаи, когда WebAssembly страдал из-за этого. И, к сожалению, использование компилятора CFG для WebAssembly и компилятора SoN для JavaScript в Turbofan также не было вариантом, поскольку использование одного компилятора для обоих позволяет встроение между обоими языками.
Sea of Nodes: изящный, но непрактичный для JavaScript
Итак, чтобы подытожить, вот основные проблемы, которые у нас есть с Sea of Nodes и Turbofan:
-
Это слишком сложно. Цепочки эффектов и управления трудно понять, что приводит ко множеству тонких ошибок. Графы трудно читать и анализировать, что затрудняет внедрение и доработку новых оптимизаций.
-
Это слишком ограниченно. Слишком много узлов находятся на цепочке эффектов и управления (потому что мы компилируем код JavaScript), поэтому это не дает слишком много преимуществ перед традиционным CFG. Кроме того, из-за трудностей с введением нового управления потоком при снижении базовые оптимизации оказываются сложными в реализации.
-
Компиляция слишком медленная. Отслеживание состояния дорого, потому что трудно найти хороший порядок для посещения графов. Локальность кеша плохая. А достижение фиксированных точек во время фаз сокращения занимает слишком много времени.
Итак, после десяти лет работы с Turbofan и борьбы с Sea of Nodes мы наконец решили избавиться от него и вернуться к более традиционному представлению IR CFG. Наш опыт работы с новым IR был исключительно положительным до сих пор, и мы очень рады, что вернулись к CFG: время компиляции сократилось вдвое по сравнению с SoN, код компилятора стал гораздо проще и короче, расследование ошибок обычно гораздо легче и т.д. Тем не менее, этот пост уже довольно длинный, поэтому я здесь остановлюсь. Следите за обновлениями: в ближайшем блоге мы расскажем о дизайне нашего нового CFG IR, Turboshaft.