V8のメモリ消費を最適化
メモリ消費は、JavaScript仮想マシンのパフォーマンストレードオフ空間において重要な次元となります。過去数か月間、V8チームは近代的なウェブ開発パターンの代表とされる複数のウェブサイトのメモリフットプリントを分析し、大幅に削減しました。このブログ記事では、分析に使用したワークロードとツールを紹介し、ガーベッジコレクタにおけるメモリ最適化の概要を述べ、さらにV8のパーサーとコンパイラーで使用されるメモリの削減方法を示します。
ベンチマーク
V8をプロファイリングし、最も多くのユーザーに影響を与える最適化を見つけるには、再現性があり意味があり、一般的な実世界のJavaScript使用シナリオをシミュレーションするワークロードを定義する必要があります。このタスクに最適なツールは、Telemetryという、Chromeでスクリプト化されたウェブサイトの操作を実行し、すべてのサーバーレスポンスを記録して、予測可能な再生がテスト環境で可能になるパフォーマンステストフレームワークです。私たちは人気のニュース、ソーシャル、メディアウェブサイトを選定し、以下の一般的なユーザー操作を定義しました:
ニュースやソーシャルウェブサイトを閲覧するためのワークロード:
- 人気のニュースまたはソーシャルウェブサイトを開く(例: Hacker News)。
- 最初のリンクをクリックする。
- 新しいウェブサイトが読み込まれるのを待機する。
- 数ページスクロールする。
- 戻るボタンをクリックする。
- 元のウェブサイトで次のリンクをクリックし、ステップ3-6を数回繰り返す。
メディアウェブサイトを閲覧するためのワークロード:
- 人気のメディアウェブサイトで項目(例: YouTubeの動画)を開く。
- その項目を数秒間消費する。
- 次の項目をクリックし、ステップ2-3を数回繰り返す。
ワークフローがキャプチャされたら、Chromeの開発版で必要に応じて何度でも再生できます。たとえば、V8の新しいバージョンが出るたびに再生できます。再生中、V8のメモリ使用量は一定時間間隔でサンプリングされて意味のある平均を取得します。ベンチマークはこちらから確認できます。
メモリの可視化
一般的にパフォーマンスを最適化する際の主要な課題の1つは、内部VM状態を明確に把握し、進捗を追跡したり潜在的なトレードオフを評価したりすることです。メモリ消費を最適化する場合、実行中のV8のメモリ消費を正確に追跡することが重要です。追跡すべきメモリは2つのカテゴリがあります: V8の管理ヒープに割り当てられたメモリと、C++ヒープに割り当てられたメモリです。V8ヒープ統計機能は、V8内部を扱う開発者がこれらを深く洞察するために使用するメカニズムです。Chrome(バージョン54以上)またはd8コマンドラインインターフェースを実行する際に--trace-gc-object-statsフラグを指定すると、V8がメモリ関連の統計をコンソールに出力します。この出力を視覚化するために、カスタムツール「V8ヒープビジュアライザー」を作成しました。このツールは、管理ヒープとC++ヒープの両方について、タイムラインベースのビューを表示します。また、特定の内部データタイプのメモリ使用状況の詳細な内訳と、それらのタイプごとのサイズベースのヒストグラムも提供します。
最適化の取り組みでは、タイムラインビューでヒープ内の大部分を占めるインスタンスタイプを選択することが一般的なワークフローです。図1のようにインスタンスタイプが選択されると、このツールはそのタイプの使用分布を示します。この例では、V8内部のFixedArrayデータ構造を選択しました。FixedArrayは型なしのベクトル状のコンテナで、VM内のさまざまな場所で広く使用されています。図2は典型的なFixedArrayの分布を示していて、特定のFixedArray使用シナリオにメモリの大部分が割り当てられていることが分かります。この例では、FixedArrayは疎JavaScript配列(「DICTIONARY_ELEMENTS」と呼ばれる)のバックストアとして使用されています。この情報を基に、実際のコードに遡り、この分布が期待される挙動か、それとも最適化の機会が存在するかどうかを確認することができます。私たちはこのツールを使用して、いくつかの内部タイプの非効率性を特定しました。
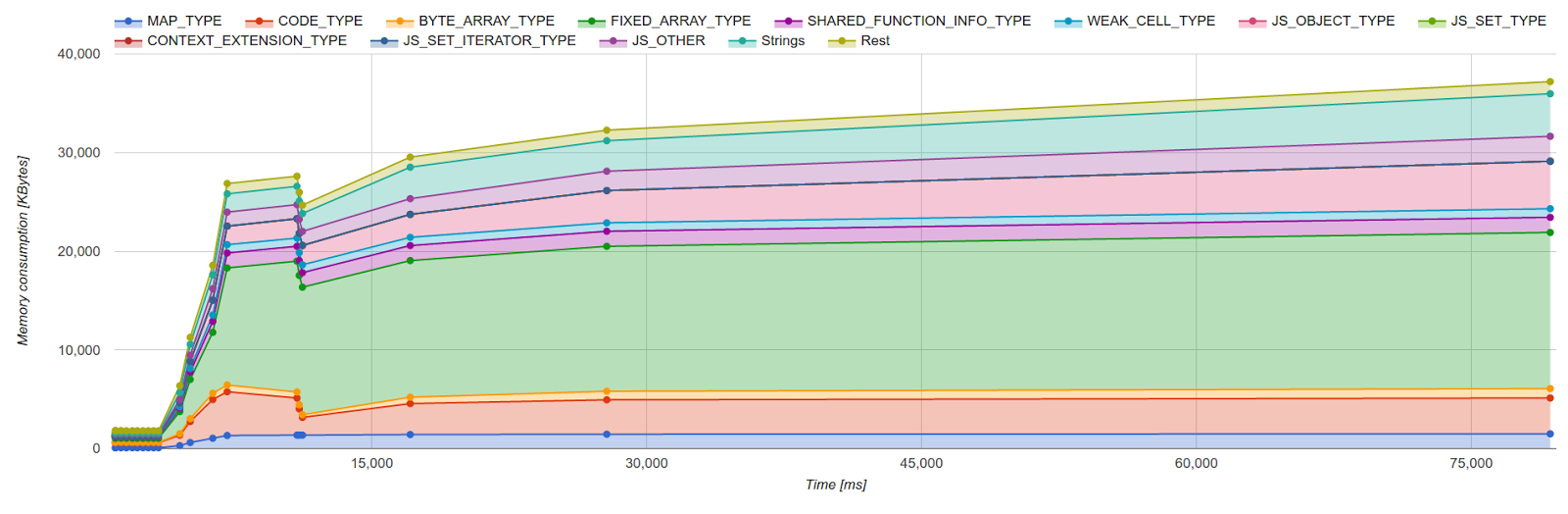

図3はC++ヒープメモリ消費量を示しています。これは主にゾーンメモリ(V8で短期間使用される一時的なメモリ領域で、以下で詳しく説明します)で構成されています。ゾーンメモリは主にV8のパーサーとコンパイラーによって大量に使用されるため、スパイクは解析およびコンパイルイベントに対応します。正常に動作している実行ではスパイクだけが発生し、不要になったメモリが即座に解放されることを示しています。一方で、プラトー状態(すなわち、高いメモリ消費量での長時間の持続)は最適化の余地があることを示しています。
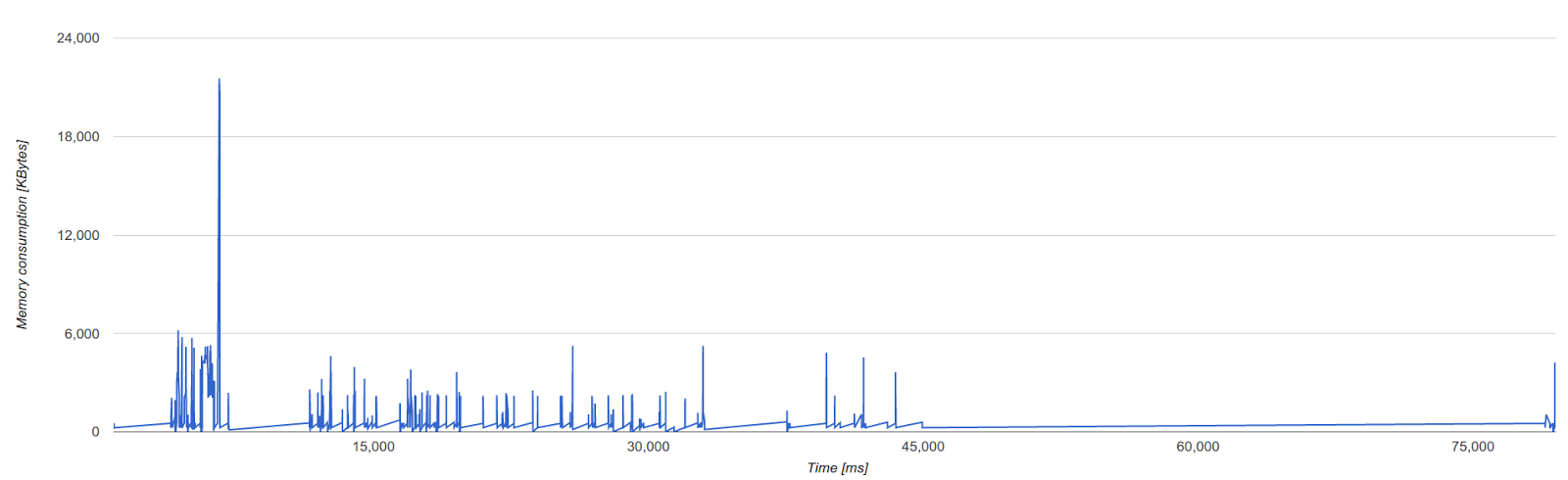
早期導入者は、Chromeのトレースインフラストラクチャへの統合を試すこともできます。そのためには、--track-gc-object-stats を付けた最新のChrome Canaryを実行し、カテゴリー v8.gc_stats を含むトレースをキャプチャする必要があります。そのデータは V8.GC_Object_Stats イベントの下に表示されます。
JavaScriptヒープサイズの削減
ガベージコレクションのスループット、待ち時間、メモリ消費量の間には、本質的にトレードオフがあります。たとえば、ガベージコレクションの待ち時間(ユーザーに見えるカクつきの原因)を減らすには、頻繁なガベージコレクションを回避するためにより多くのメモリを使用することができます。ただし、メモリ容量が512MB未満の低メモリモバイルデバイスでは、待ち時間やスループットを優先するとAndroidでメモリ不足によるクラッシュやタブの一時停止が発生する可能性があります。
これらの低メモリモバイルデバイス向けに適切なトレードオフをより良くバランスさせるため、JavaScriptのガベージコレクトされたヒープのメモリ使用量を下げるようにいくつかのガベージコレクションのヒューリスティクスを調整した特別なメモリ削減モードを導入しました。
- フルガベージコレクションの終了時に、V8のヒープ成長戦略は、若干の余裕を伴った実メモリ量に基づき次のガベージコレクションがいつ発生するかを決定します。メモリ削減モードでは、余裕を減らして、より頻繁なガベージコレクションによるメモリ使用量の減少を実現します。
- さらに、この推定値を厳格な制限値として扱い、未完了のインクリメントマーク作業をメインガベージコレクションの一時停止中に最終化することを強制します。通常、メモリ削減モードではない場合、未完了のインクリメントマーク作業がこの制限値を超えてメインガベージコレクションの一時停止をマーク終了時まで引き延ばすことがあります。
- メモリ断片化をさらに減らすために、より攻撃的なメモリ圧縮を実行します。
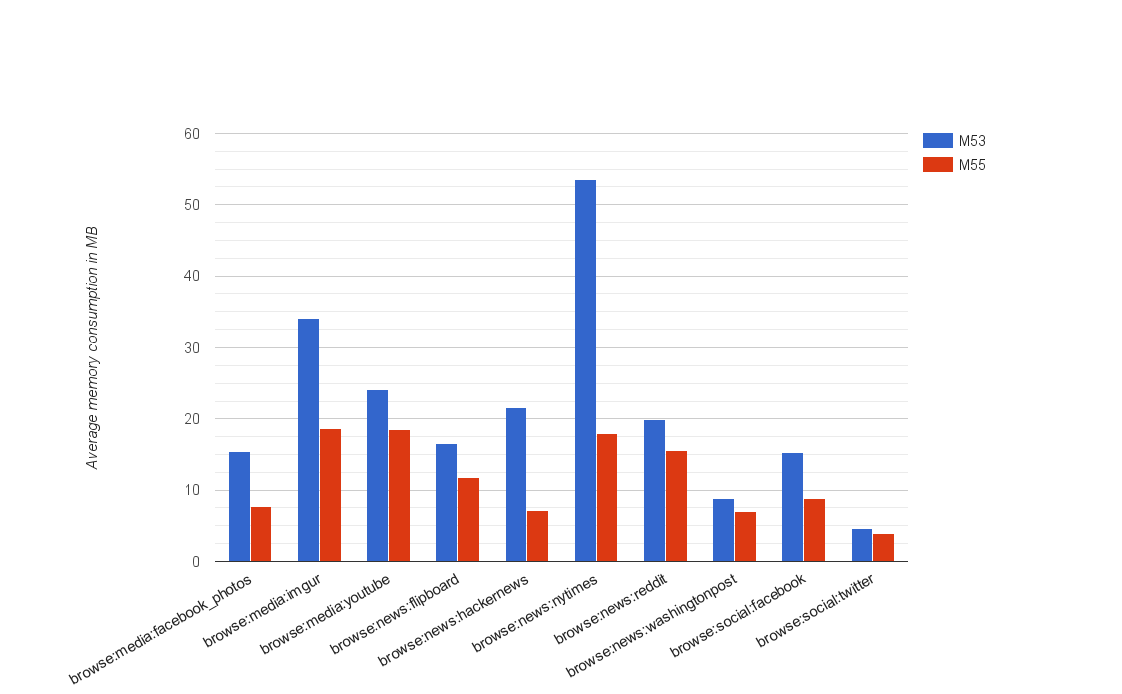
図4は、Chrome 53以降に低メモリデバイスでの改善の一部を示しています。特に注目すべきは、モバイル版ニューヨークタイムズベンチマークの平均V8ヒープメモリ消費量が約66%減少したことです。全体として、このベンチマークセットで50%の平均V8ヒープサイズ削減を観測しました。
最近導入された別の最適化は、低メモリデバイスだけでなく、より高性能なモバイルおよびデスクトップデバイスのメモリ消費量も削減します。V8のヒープページサイズを1MBから512kBに削減することで、多くの有効オブジェクトが存在しない場合のメモリフットプリントを削減し、全体的なメモリ断片化を最大2倍削減します。また、より小さな作業単位がメモリ圧縮スレッドによる並列作業を可能にし、V8がより多くの圧縮作業を実行できるようにします。
ゾーンメモリ削減
JavaScriptヒープに加えて、V8は内部のVM操作のためにオフヒープメモリを使用します。最も大きなメモリチャンクは、_ゾーン_と呼ばれるメモリアリアを通じて割り当てられます。ゾーンは、すべてのゾーン割り当てメモリがゾーンが破棄されるときに一度に解放される、高速な割り当てと一括解放を可能にする地域ベースのメモリアロケーターの一種です。ゾーンはV8のパーサーとコンパイラー全体で使用されます。
Chrome 55での主な改善の1つは、バックグラウンド解析中のメモリ消費量の削減です。バックグラウンド解析によって、V8はページの読み込み中にスクリプトを解析できます。メモリ可視化ツールを使用して、バックグラウンドパーサーがコードがすでにコンパイルされている後でもゾーン全体を長く保持することを特定しました。コンパイル後にゾーンを直ちに解放することで、ゾーンの寿命を大幅に短縮し、平均およびピークメモリ使用量を削減しました。
もう1つの改善点は、パーサーによって生成される_抽象構文木_ノード内のフィールドのパックがより良くなったことです。以前は、C++コンパイラに可能な限りフィールドをまとめてパックさせていました。例えば、2つのブール値があれば2ビットだけ必要で、1ワード内または前のワードの未使用部分に配置されるべきです。C++コンパイラは常に最も圧縮されたパックを見つけるわけではないため、代わりに手動でビットをパックしました。これにより、ピークメモリ使用量が減少するだけでなく、パーサーとコンパイラの性能も向上しました。
図5は、Chrome 54以降のピークゾーンメモリの改善を示しており、測定されたウェブサイトでは平均で約40%減少しています。

今後数か月間、V8のメモリフットプリントを削減する作業を継続していきます。パーサーに対するさらなるゾーンメモリの最適化を計画しており、512 MBから1 GBのメモリを持つデバイスに重点を置く予定です。
更新: 上記で説明したすべての改善により、Chrome 55では_低メモリデバイス_における全体的なメモリ消費量がChrome 53と比較して最大35%削減されます。他のデバイスセグメントでは、ゾーンメモリの改善だけが利点となります。