ES2015プロキシのV8における最適化
プロキシは、ES2015以来JavaScriptの重要な部分を形成しています。これらはオブジェクトの基本操作をインターセプトし、その挙動をカスタマイズすることを可能にします。プロキシは、jsdomやComlink RPCライブラリのようなプロジェクトのコア部分を形成しています。最近、V8でプロキシのパフォーマンスを向上させるために多くの努力を行いました。この記事では、V8の一般的なパフォーマンス改善パターンについて、特にプロキシに関する内容を解説します。
プロキシは「基本操作(例えばプロパティ検索、代入、列挙、関数の呼び出しなど)に対してカスタム挙動を定義するためのオブジェクト」(MDNによる定義)です。詳細は完全な仕様で確認できます。例えば、次のコードスニペットは、オブジェクトのすべてのプロパティアクセスにロギングを追加します:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get was called for: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
// get was called for: property
// value
プロキシの構築
最初に重点を置く機能は、プロキシの構築です。ここでの元のC++実装は、ECMAScript仕様を逐語的に実行し、以下の図で示されているように、C++とJSランタイム間で少なくとも4回のジャンプを生じさせました。この実装をプラットフォーム非依存のCodeStubAssembler(CSA)に移植することを目指しました。この移植により、言語ランタイム間のジャンプ回数が最小化されます。以下の図では、CEntryStubとJSEntryStubがランタイムを表しています。点線はJSとC++ランタイムの境界を示しています。幸運なことに、ヘルパー述語がすでにアセンブラ内で実装されており、初期バージョンを簡潔で可読なものにしました。
以下の図は、任意のプロキシトラップ(この例ではapply)でプロキシを呼び出す際の実行フローを示しています。このコードスニペットによって生成されます:
function foo(…) { … }
const g = new Proxy({ … }, {
apply: foo,
});
g(1, 2);
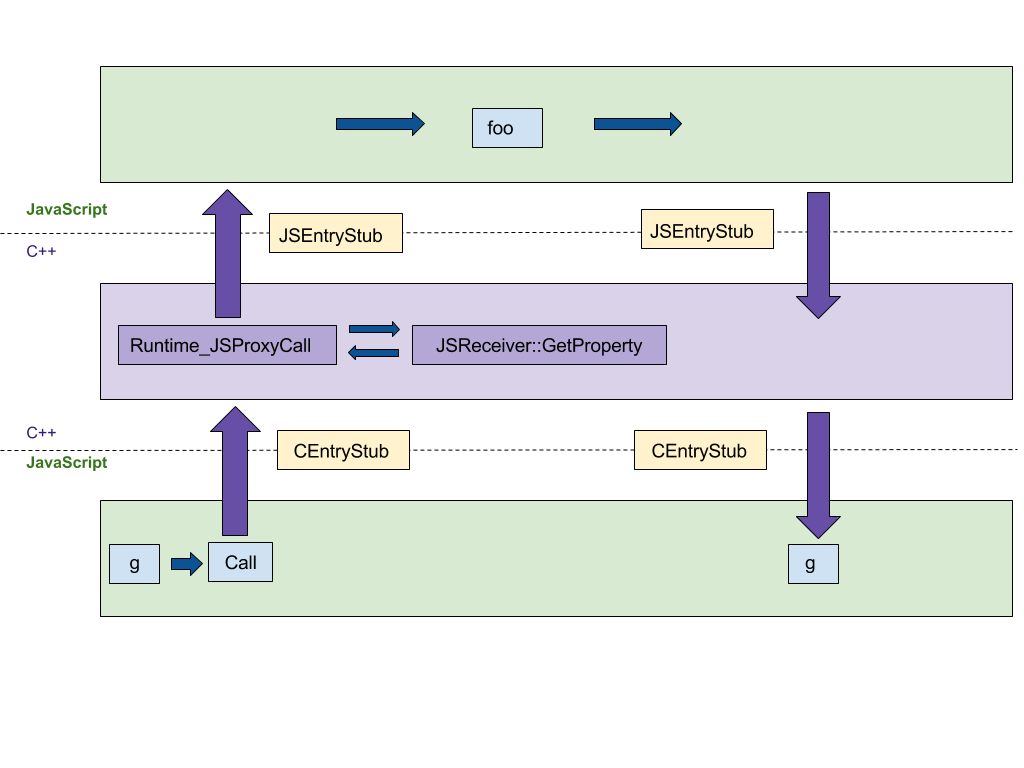
トラップ実行をCSAへの移植後、すべての実行はJSランタイム内で行われ、言語間のジャンプ回数を4回から0回に削減しました。
この変更により以下のようなパフォーマンス改善が得られました::
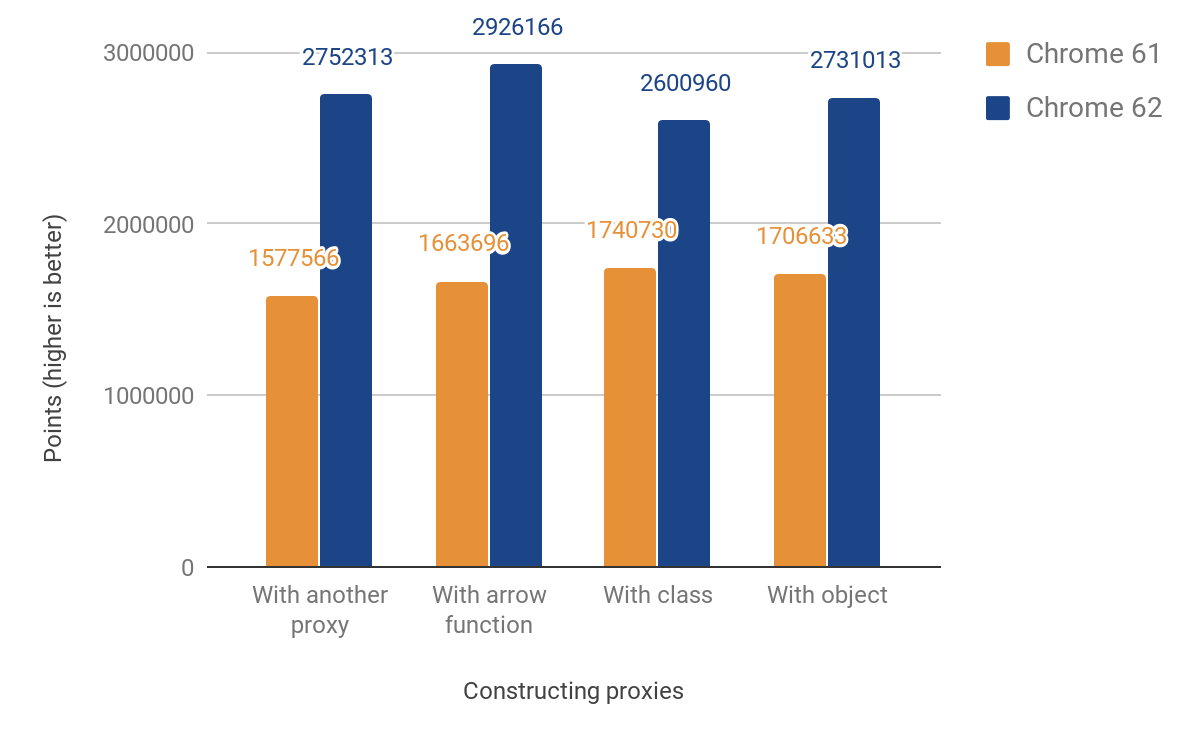
JSパフォーマンススコアは**49%から74%**の改善を示しています。このスコアは、特定のマイクロベンチマークが1000ms以内に何回実行できるかをおおよそ測定するものです。一部のテストでは、タイマーの精度を考慮してコードを複数回実行して正確な測定を行っています。以下のベンチマークのコードはこちらにあります。
CallおよびConstructトラップ
次のセクションでは、CallおよびConstructトラップ(別名"apply""および"construct")の最適化結果を示します。
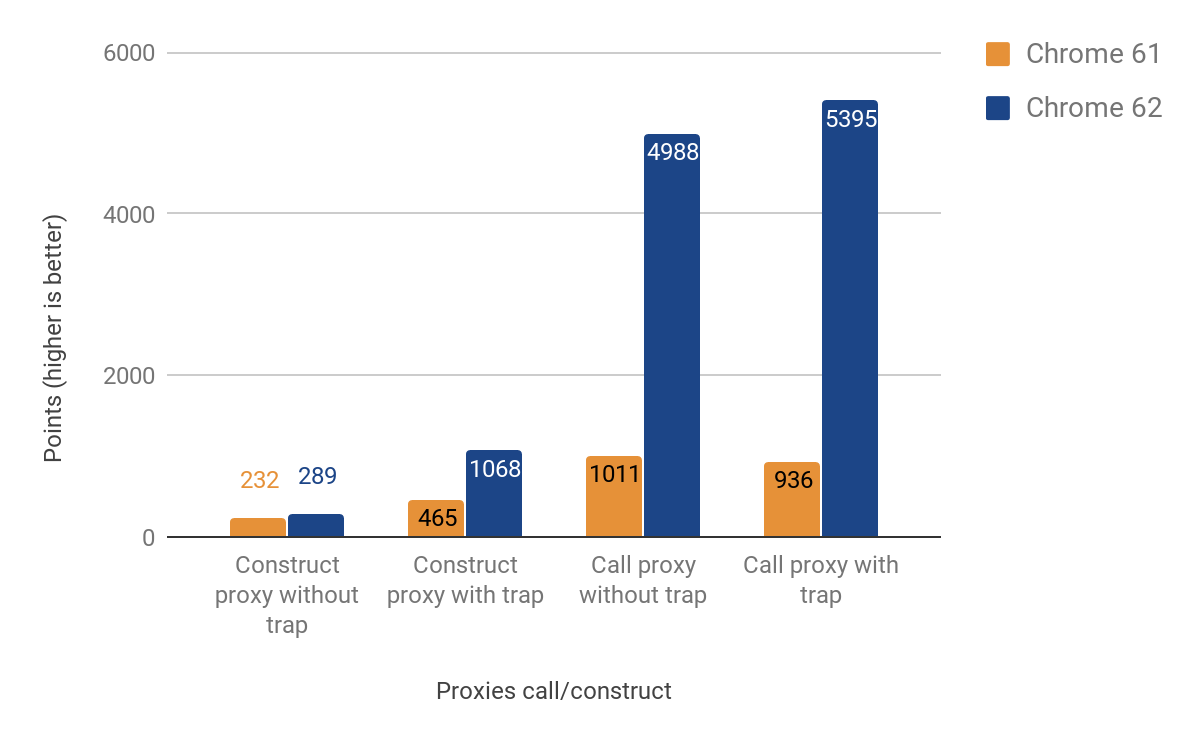
プロキシを_呼び出す_場合のパフォーマンス改善は顕著で、最大**500%高速化されています!ただし、プロキシ構築の改善はかなり控えめで、特に実際にトラップが定義されていない場合には約25%**の向上しか見られませんでした。これを調査するために以下のコマンドをd8シェルで実行しました:
$ out/x64.release/d8 --runtime-call-stats test.js
> run: 120.104000
Runtime Function/C++ Builtin Time Count
========================================================================================
NewObject 59.16ms 48.47% 100000 24.94%
JS_実行 23.83ms 19.53% 1 0.00%
同期的な再コンパイル 11.68ms 9.57% 20 0.00%
アクセサ名取得コールバック 10.86ms 8.90% 100000 24.94%
アクセサ名取得コールバック_関数プロトタイプ 5.79ms 4.74% 100000 24.94%
Map_SetPrototype 4.46ms 3.65% 100203 25.00%
… SNIPPET …
test.jsのソースコードは以下の通りです:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('run');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('run');
ほとんどの時間がNewObjectおよびその呼び出し先関数に費やされることが判明したため、将来のリリースでこれを高速化する方法を計画し始めました。
Getトラップ
次のセクションでは、プロキシを介してプロパティを取得および設定する最も一般的な操作を最適化する方法について説明します。getトラップは、前のケースよりも複雑で、V8のインラインキャッシュの特定の動作によるものです。インラインキャッシュの詳細な説明については、この講演をご覧ください。
最終的に、以下の結果とともにCSAへの移植に成功しました:
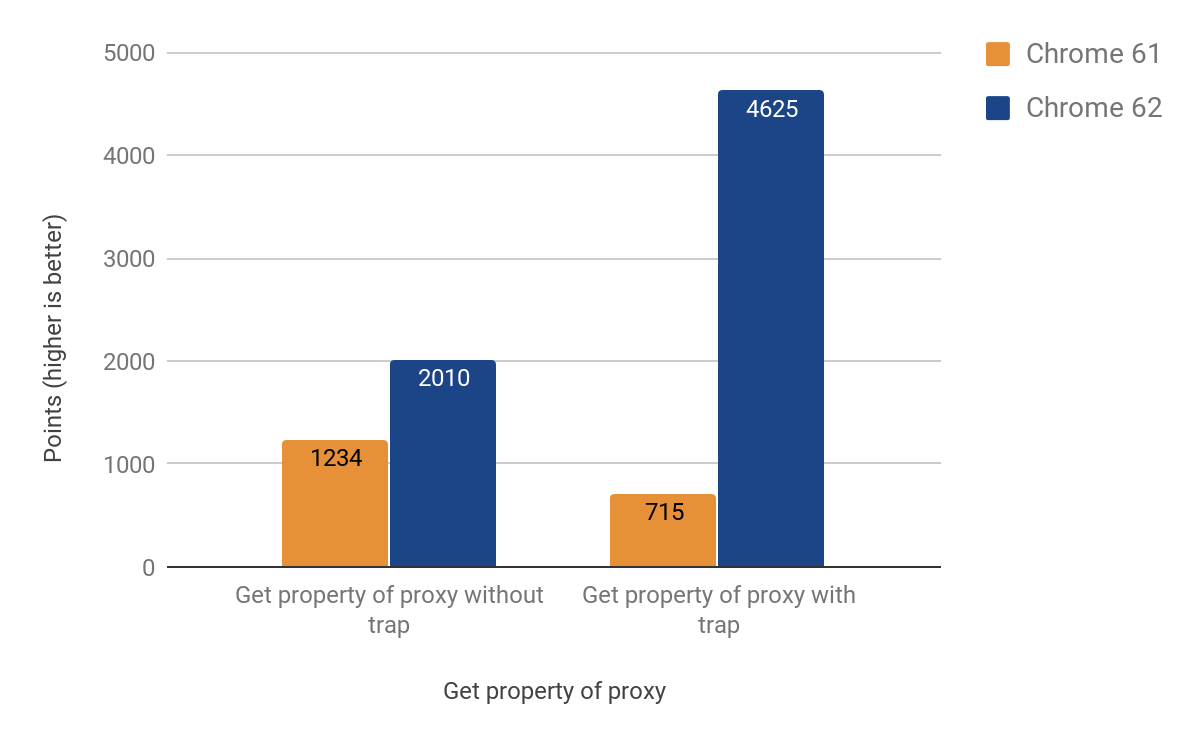
変更を適用した後、ChromeのAndroid用.apkサイズが約160KB増加したことに気付きました。約20行のヘルパー関数にしては予想以上でしたが、幸いにもそのような統計を追跡しています。この関数が別の関数から2回呼び出され、その関数がさらに別の関数から3回呼び出されることから問題の原因は過度のインライン化であることが判明しました。最終的に、インライン関数を個別のコードスタブに変換することで問題を解決し、重要なKBを節約しました。最終バージョンでは.apkサイズが約19KB増加するだけになりました。
Hasトラップ
次のセクションでは、hasトラップの最適化結果を示します。当初はgetトラップのコードの大部分を再利用して簡単にできると考えましたが、独自の特異性があることが判明しました。特に把握しづらかった問題は、in演算子を使用した際のプロトタイプチェーンの探索でした。達成した改善結果は**71%から428%**の範囲で、トラップが存在する場合には改善が顕著です。
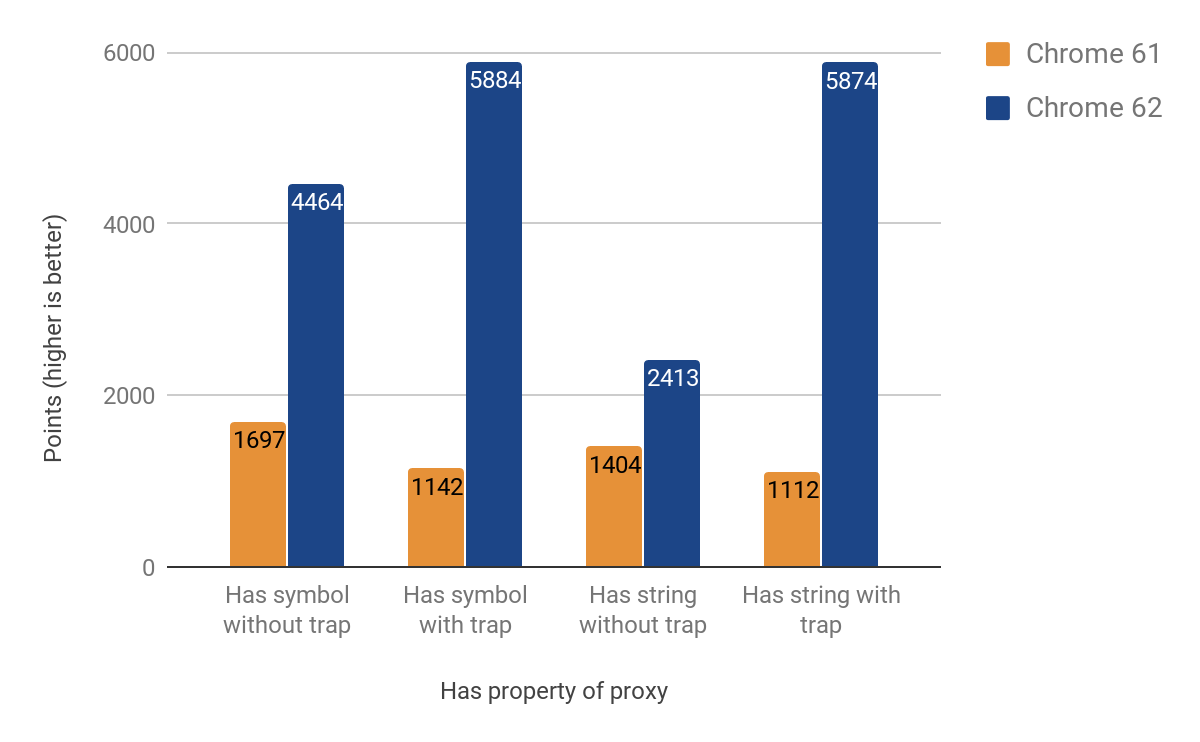
Setトラップ
次のセクションでは、setトラップの移植について説明します。今回は名前付きとインデックス付きプロパティ(要素)を区別する必要がありました。この2つの主要タイプはJS言語には含まれていませんが、V8の効率的なプロパティストレージには不可欠です。初期実装では依然として要素に対してランタイムにフォールバックし、言語の境界を再度越えることになります。それにもかかわらず、トラップが設定された場合には**27%から438%の改善を達成しましたが、最大23%**の性能低下が発生しました。これは名前付きプロパティとインデックス付きプロパティを区別するための追加チェックのオーバーヘッドに起因します。インデックス付きプロパティでは改善はまだありません。以下は完全な結果です:
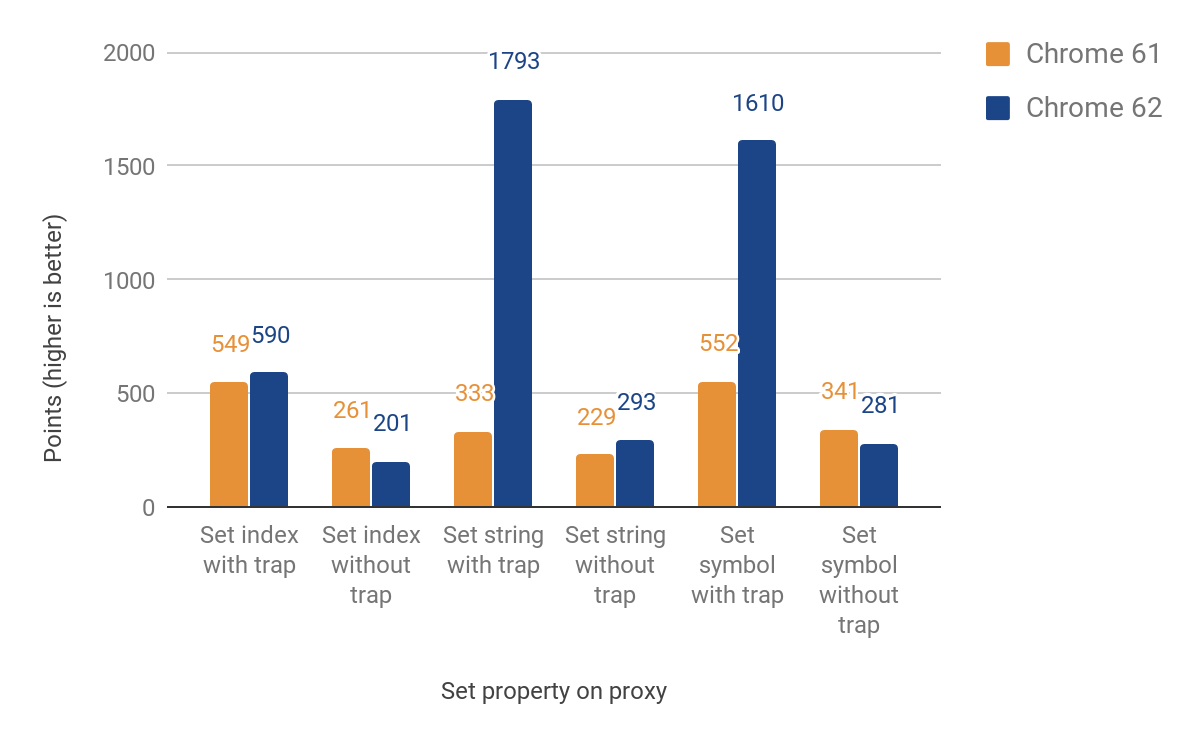
実際の使用状況
jsdom-proxy-benchmarkからの結果
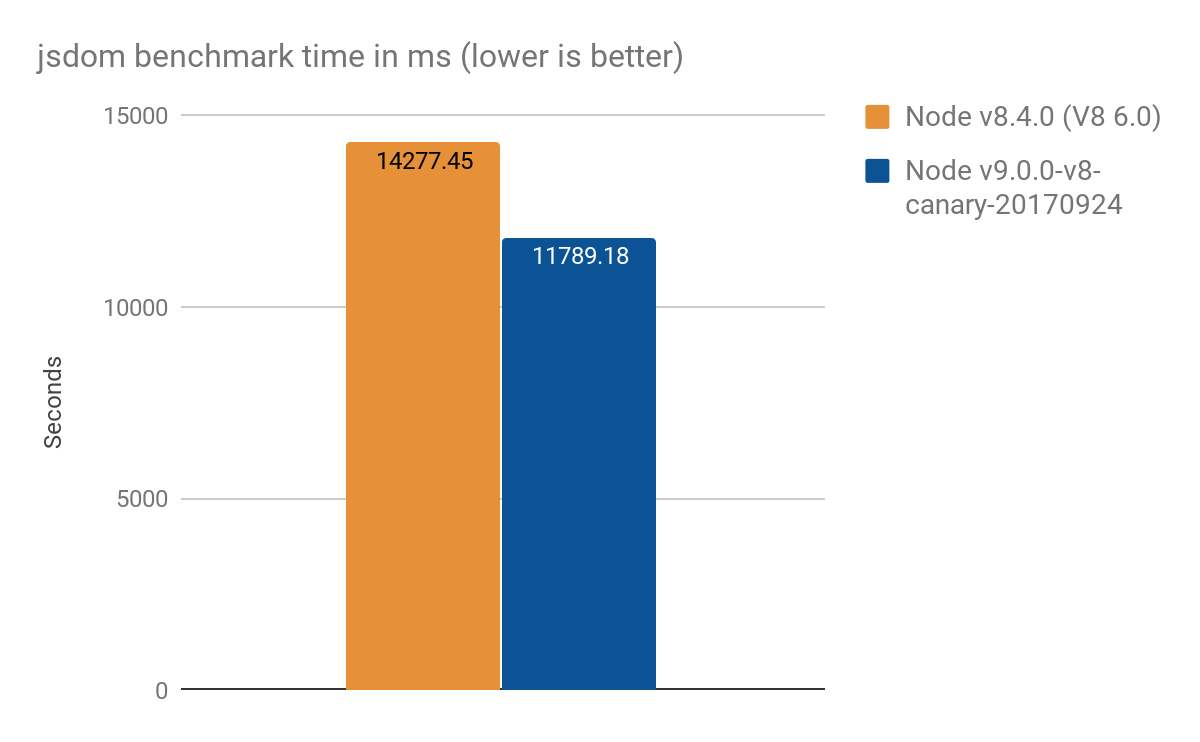
jsdom-proxy-benchmarkプロジェクトはECMAScript仕様をEcmarkupツールを使用してコンパイルします。v11.2.0以降、jsdomプロジェクト(Ecmarkupの基盤)はプロキシを使用して共通データ構造NodeListとHTMLCollectionを実装しています。このベンチマークを使用して、より現実的な使用状況を合成マイクロベンチマークよりも概要を把握し、以下の結果(100回の平均)を達成しました:
- Node v8.4.0 (プロキシ最適化なし): 14277 ± 159 ms
- Node v9.0.0-v8-canary-20170924 (トラップの一部のみ移植): 11789 ± 308 ms
- 約2.4秒の速度向上で、これは約17%の改善
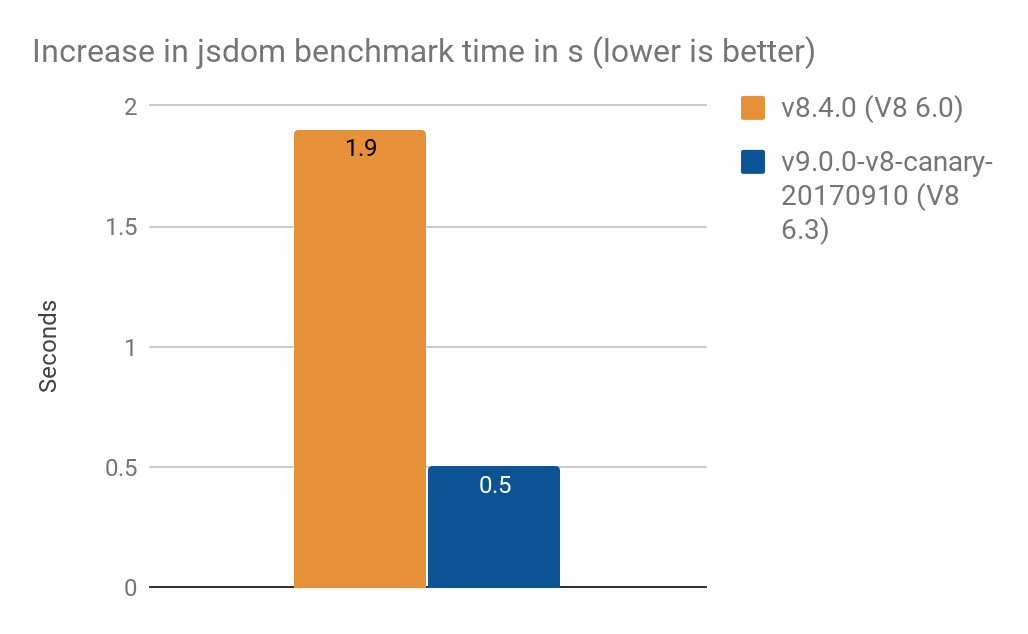
- NamedNodeMapを
Proxy利用に変更することで処理時間が増加しました:- V8 6.0 (Node v8.4.0)では1.9秒
- V8 6.3 (Node v9.0.0-v8-canary-20170910)では0.5秒
:::注記 注意: これらの結果は Timothy Gu によって提供されました。ありがとうございます! :::
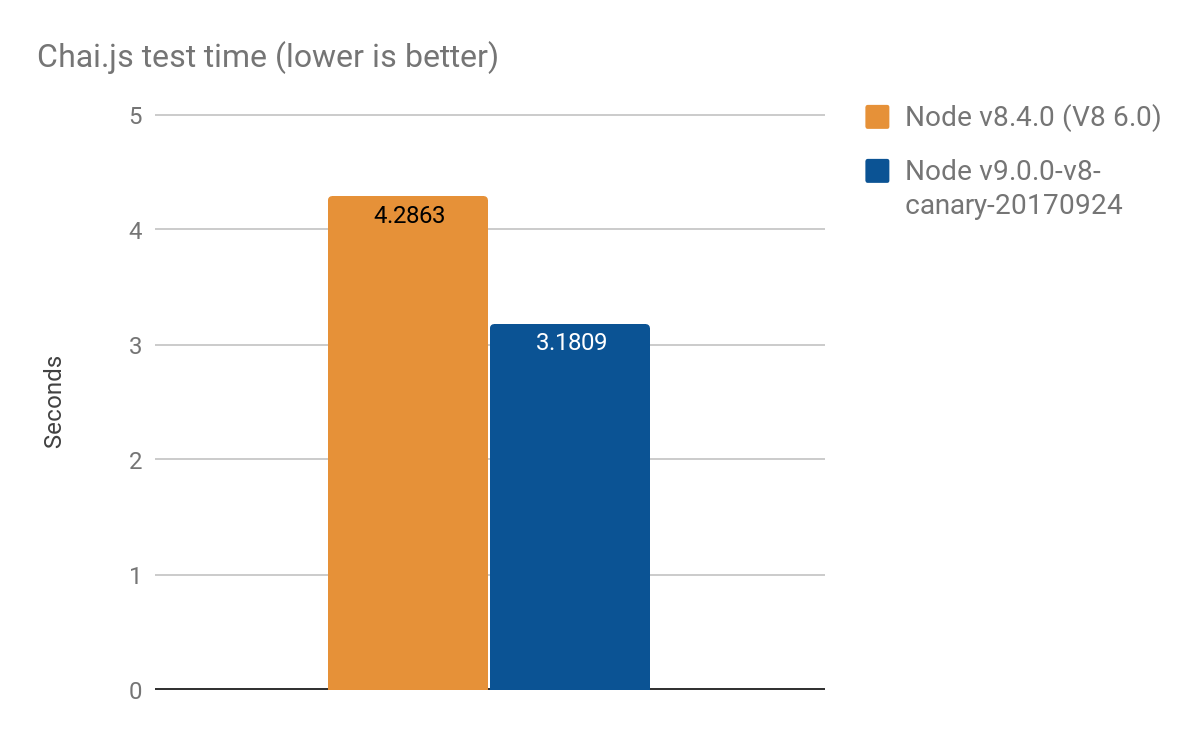
Chai.js からの結果
Chai.js は、プロキシを多用する人気のあるアサーションライブラリです。異なるバージョンの V8 を使用してそのテストを実行することで、一種の実際のベンチマークを作成しました。その結果、平均100回の実行でおよそ 4秒以上中の約1秒の改善 を達成しました:
- Node v8.4.0 (プロキシ最適化なし): 4.2863 ± 0.14 秒
- Node v9.0.0-v8-canary-20170924 (トラップの半分のみ移植): 3.1809 ± 0.17 秒
最適化アプローチ
私たちは、汎用的な最適化手法を使用してパフォーマンス問題に取り組むことがよくあります。この特定のタスクで採用した主な方法には、以下のステップが含まれています:
- 特定のサブ機能の性能テストを実装する
- 仕様準拠テストを追加する (またはゼロから作成する)
- 元のC++実装を調査する
- サブ機能をプラットフォームに依存しない CodeStubAssembler に移植する
- 手作業で TurboFan 実装を作成し、コードをさらに最適化する
- パフォーマンス改善を測定する。
この手法は、一般的な最適化タスクに適用することができます。