V8での高速なプロパティ
この記事では、V8が内部的にJavaScriptプロパティをどのように扱うかを説明したいと思います。JavaScriptの観点からは、プロパティに必要な区別はわずかです。JavaScriptオブジェクトは主に辞書のように振る舞い、キーは文字列であり、値には任意のオブジェクトを使用できます。ただし仕様では、整数インデックス付きのプロパティとその他のプロパティを反復中に異なる扱いをしています。それ以外では、異なるプロパティは、整数インデックス付きであるかどうかに関係なくほぼ同じ動作をします。
しかし、内部的にはV8はいくつかのプロパティ表現法を使用して、性能とメモリ効率を改善しています。この記事では、V8が動的に追加されたプロパティを処理しながら高速なプロパティアクセスを実現する方法を説明します。プロパティの動作を理解することは、V8におけるインラインキャッシュのような最適化を説明する上で不可欠です。
この記事では、まず整数インデックス付きプロパティと名前付きプロパティの処理の違いを説明します。その後、名前付きプロパティを追加する際にオブジェクト形状を特定するための高速な方法を提供するHiddenClass(非表示クラス)について説明します。次に、名前付きプロパティが使用パターンに応じて高速なアクセスまたは高速な修正のために最適化される方法について詳説します。最後に、V8が整数インデックス付きプロパティまたは配列インデックスをどのように処理するかについて説明します。
名前付きプロパティ vs. 要素
まず、{a: "foo", b: "bar"}のような非常にシンプルなオブジェクトを分析してみましょう。このオブジェクトには2つの名前付きプロパティ、"a" と "b"があります。プロパティ名にはいかなる整数インデックスもありません。配列インデックス付きプロパティ(要素として一般的に知られる)は、配列上で最も顕著に見られます。たとえば配列 ["foo", "bar"]には2つの配列インデックス付きプロパティがあります:0(値は"foo")と1(値は"bar")。これはV8がプロパティを全般的に処理する重要な区別の第一歩です。
以下の図は、基本的なJavaScriptオブジェクトがメモリ内でどのように見えるかを示しています。
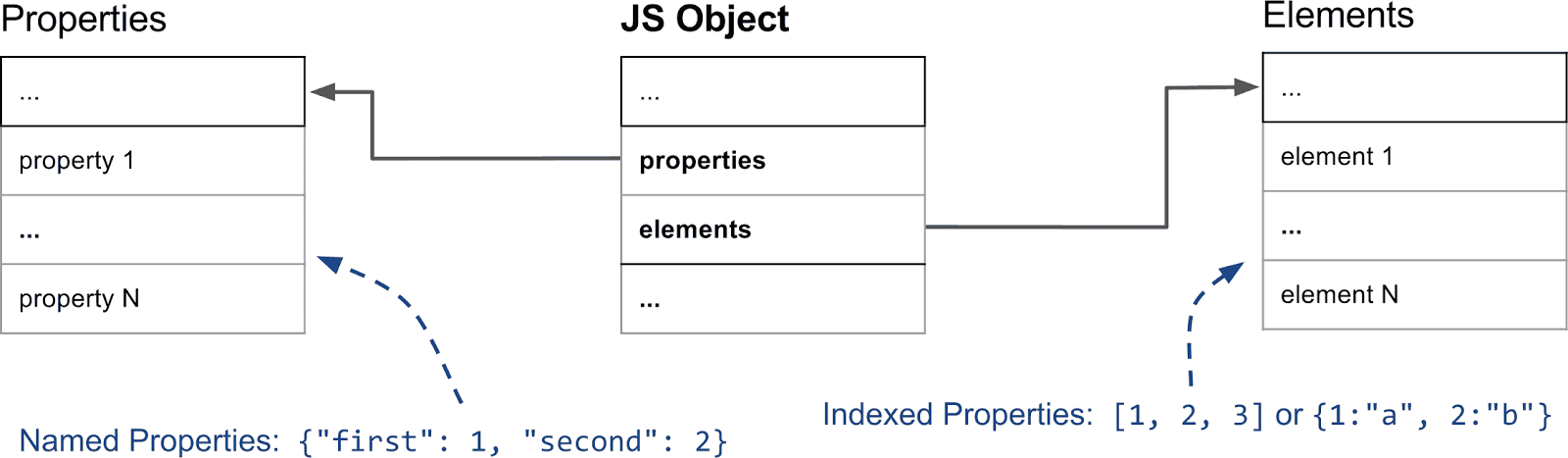
要素とプロパティは別々のデータ構造に格納されており、異なる使用パターンにおいてプロパティや要素の追加およびアクセスを効率化しています。
要素は主にArray.prototypeメソッド(例:popやslice)に使用されます。これらの関数は連続範囲内でプロパティにアクセスするため、V8は内部的にはそれらを簡単な配列として表現します—多くの場合。その後、この投稿でメモリを節約するためにまれに疎な辞書ベースの表現法に切り替える方法も説明します。
名前付きプロパティも別の配列に類似した方法で保存されます。しかし、要素とは異なり、キーを使用してプロパティ配列内の位置を直接推論することはできません。いくつかの追加メタデータが必要です。V8では各JavaScriptオブジェクトにHiddenClass(非表示クラス)が関連付けられています。HiddenClassはオブジェクトの形状に関する情報を保存し、それに加えてプロパティ名からプロパティのインデックスへのマッピングを保持します。なお、シンプルな配列ではなくプロパティに辞書を使用する場合もあります。この問題については専用のセクションで詳述します。
このセクションのまとめ:
- 配列インデックス付きプロパティは要素ストアに格納されます。
- 名前付きプロパティはプロパティストアに格納されます。
- 要素とプロパティは配列または辞書のいずれかで保存されます。
- 各JavaScriptオブジェクトにはオブジェクト形状に関する情報を保持するHiddenClassが関連付けられています。
HiddenClassesとDescriptorArrays
要素とプロパティの一般的な区別を説明した後、V8におけるHiddenClassesの仕組みを見ていく必要があります。このHiddenClassはオブジェクトに関するメタ情報を格納し、オブジェクト上のプロパティの数やオブジェクトのプロトタイプへの参照を含みます。HiddenClassは、典型的なオブジェクト指向プログラミング言語におけるクラスに概念的に似ています。ただし、JavaScriptのようなプロトタイプベースの言語では、通常クラスを事前に知ることはできません。そのため、この場合V8では、HiddenClassesがその場で作成され、オブジェクトが変更されるたびに動的に更新されます。HiddenClassesはオブジェクトの形状を識別する役割を果たし、そのためV8の最適化コンパイラやインラインキャッシュにとって非常に重要な要素です。最適化コンパイラはたとえばHiddenClassを通じてオブジェクト構造の互換性を確保できる場合、プロパティアクセスを直接インライン化できます。
HiddenClassの重要な部分を見てみましょう。
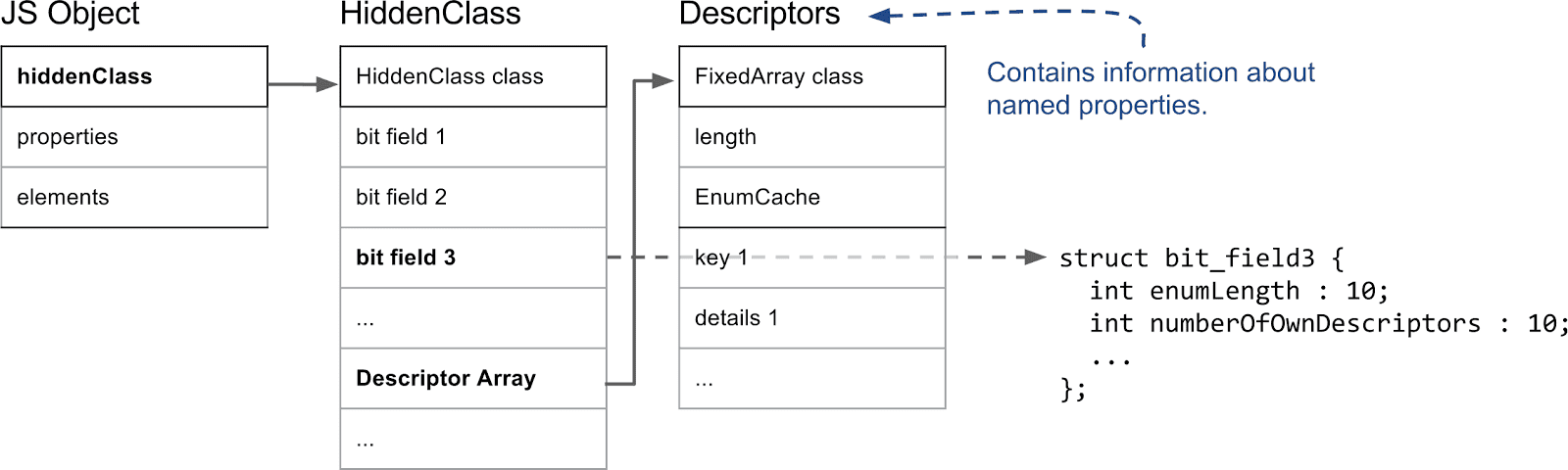
V8では、JavaScriptオブジェクトの最初のフィールドがHiddenClassを指しています。(実際には、これはV8ヒープ上にありガベージコレクタによって管理されるすべてのオブジェクトに当てはまります。)プロパティに関しては、最も重要な情報は3番目のビットフィールドで、ここにはプロパティの数とディスクリプタ配列へのポインタが格納されます。ディスクリプタ配列には、プロパティ名自体や値が格納されている位置など、名前付きプロパティに関する情報が含まれます。ここでは整数インデックス付きプロパティは追跡されないため、ディスクリプタ配列にエントリはありません。
HiddenClassesの基本的な前提は、同じ構造を持つオブジェクト、例えば同じ名前付きプロパティが同じ順序であるものは同じHiddenClassを共有するというものです。そのため、プロパティがオブジェクトに追加されるたびに異なるHiddenClassを使用します。以下の例では、空のオブジェクトから開始し、名前付きプロパティを3つ追加していきます。
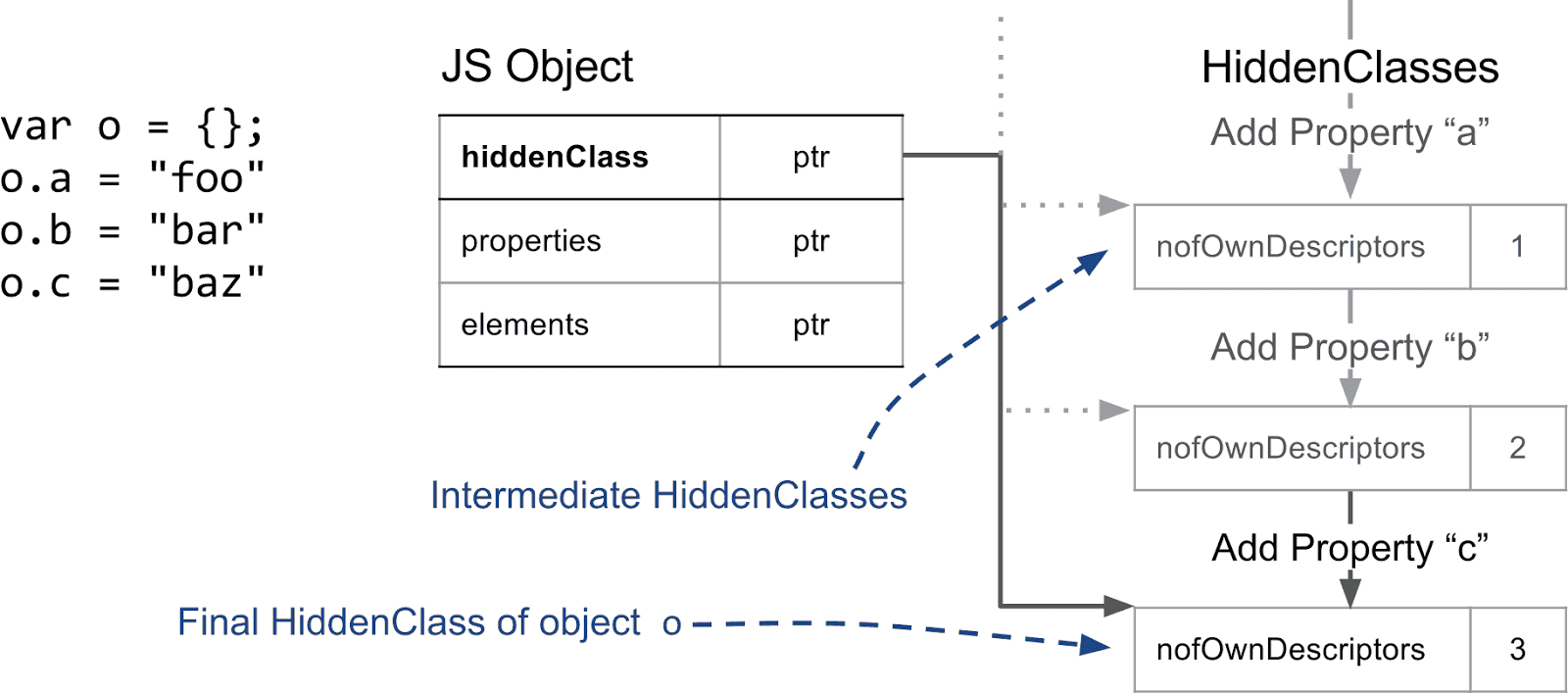
新しいプロパティが追加されるたびに、オブジェクトのHiddenClassが変更されます。バックグラウンドでは、V8はHiddenClassesをリンクする遷移ツリーを作成します。例えば空のオブジェクトにプロパティ「a」を追加するとき、どのHiddenClassを使用するかはV8によって認識されます。この遷移ツリーにより、同じ順序で同じプロパティを追加すると、同じ最終HiddenClassに到達することが保証されます。次の例では、間にシンプルなインデックス付きプロパティを追加しても、同じ遷移ツリーをたどることを示しています。
![]()
ただし、ここで異なるプロパティ(この場合はプロパティ"d")が追加される新しいオブジェクトを作成すると、V8は新しいHiddenClassesのための別のブランチを作成します。
![]()
このセクションでのまとめ:
- 同じ構造を持つオブジェクト(同じ順序で同じプロパティ)が同じHiddenClassを持つ。
- デフォルトでは、新しい名前付きプロパティが追加されるたびに新しいHiddenClassが作成される。
- 配列インデックス付きプロパティを追加しても新しいHiddenClassesは作成されない。
3種類の名前付きプロパティ
V8がHiddenClassesを使用してオブジェクトの形状を追跡する概要を説明した後は、これらのプロパティが実際にどのように格納されているかを掘り下げていきましょう。上記の導入で説明したように、プロパティには名前付きとインデックス付きの2種類の基本的な種類があります。以下のセクションでは名前付きプロパティを取り上げます。
{a: 1, b: 2}のようなシンプルなオブジェクトは、V8内でさまざまな内部表現を持つことができます。JavaScriptオブジェクトは外部から見れば単純な辞書のような動作をするものの、V8は辞書を避けようとします。辞書は特定の最適化(インラインキャッシュなど)を妨げるためです。この最適化については別の記事で説明します。
In-objectプロパティと通常プロパティ: V8はin-objectプロパティと呼ばれるプロパティをサポートしており、これらはオブジェクト自身に直接格納されます。これらはV8内で最速のプロパティであり、間接アクセスなしで取得できます。in-objectプロパティの数はオブジェクトの初期サイズによって事前に決定されます。オブジェクトにスペースを超えるプロパティが追加された場合、それらはプロパティストアに格納されます。プロパティストアは間接アクセスを1段階追加しますが、独立して拡張可能です。
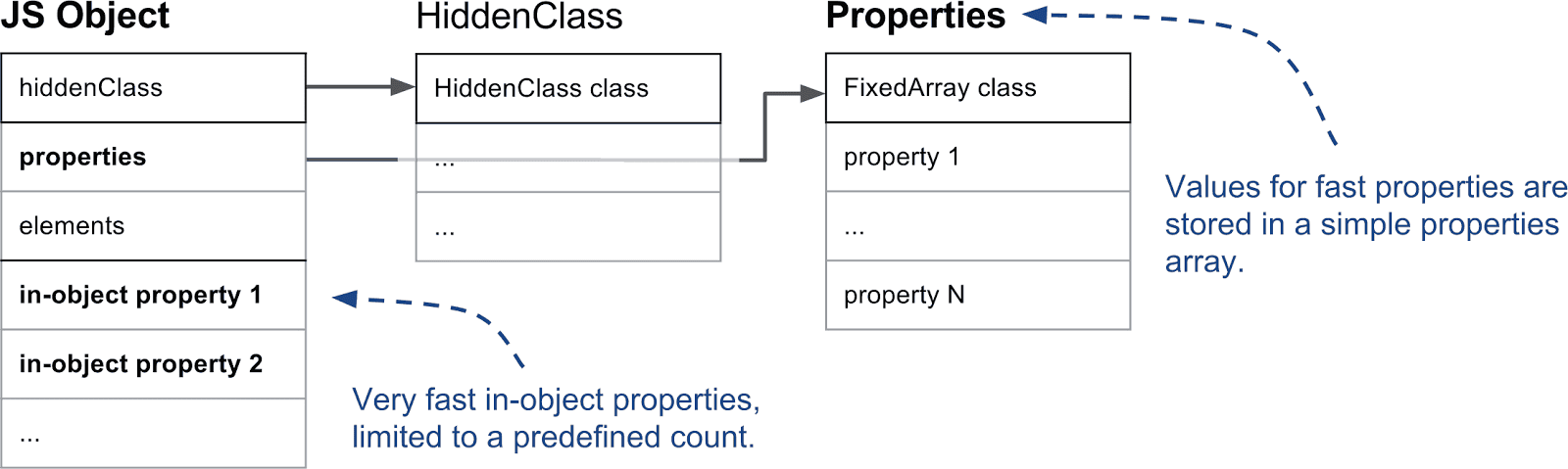
高速プロパティと低速プロパティ: 次に重要な区別は、高速プロパティと低速プロパティです。通常、プロパティストア内で線形に格納されるプロパティは「高速」と定義されます。高速プロパティはプロパティストア内のインデックスで単純にアクセスできます。プロパティ名からプロパティストア内の実際の位置を得るには、前述のようにHiddenClass上のディスクリプタ配列を参照する必要があります。
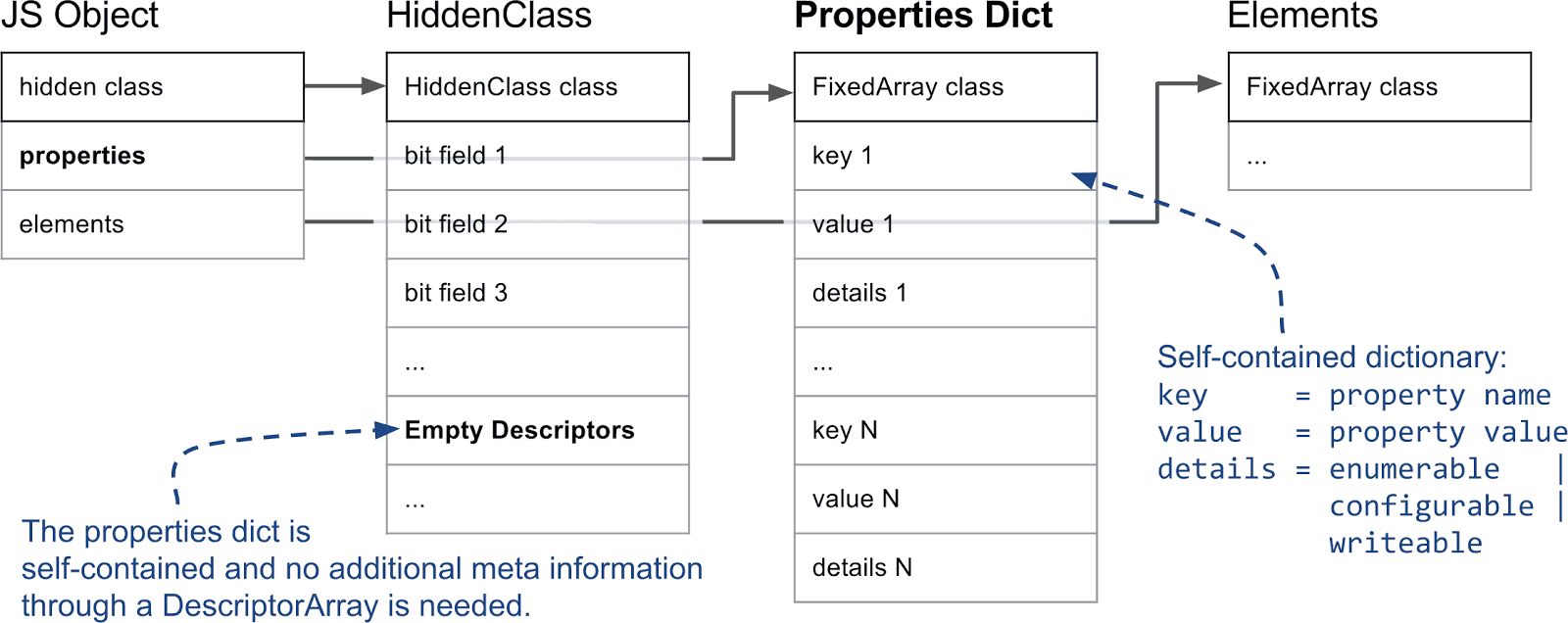
ただし、多くのプロパティがオブジェクトから追加・削除されると、ディスクリプタ配列やHiddenClassesを維持するために多くの時間とメモリのオーバーヘッドが発生する可能性があります。そのため、V8は低速プロパティと呼ばれるものもサポートしています。低速プロパティを持つオブジェクトは自己完結型の辞書をプロパティストアとして持っています。すべてのプロパティのメタ情報は、もはやHiddenClass上のディスクリプタ配列に格納されることなく、プロパティ辞書に直接保存されます。そのため、プロパティを追加・削除してもHiddenClassを更新する必要はありません。辞書プロパティはインラインキャッシュと連携しないため、通常は高速プロパティよりも遅くなります。
このセクションでのまとめ:
- 名前付きプロパティには3種類ある: in-object、高速、低速/辞書。
- In-objectプロパティはオブジェクト自体に直接格納され、最速のアクセスを提供する。
- 高速プロパティはプロパティストアに存在しており、すべてのメタ情報はHiddenClass上のディスクリプタ配列に保存されています。
- 低速プロパティは自己完結型のプロパティ辞書に存在しており、メタ情報はもはやHiddenClassを通じて共有されていません。
- 低速プロパティはプロパティの削除と追加を効率的に行うことができますが、他の2つのタイプよりアクセスは遅くなります。
要素または配列インデックス付きプロパティ
これまでは名前付きプロパティについて見てきましたが、配列でよく使用される整数インデックス付きプロパティについては無視してきました。整数インデックス付きプロパティの処理は、名前付きプロパティよりも複雑ではありません。同じ要素ストアで管理されるにもかかわらず、20 種類もの異なる要素があります!
詰まった要素または穴あき要素: V8が行う主要な区別の1つは、バックアップストアが詰まっているか(packed)穴があるか(holey)です。インデックス付き要素を削除したり、例えば定義しなかったりする場合、バックアップストアに穴ができます。簡単な例は [1,,3] で、2番目のエントリが穴です。以下の例でこの問題が示されています:
const o = ['a', 'b', 'c'];
console.log(o[1]); // 'b' と出力。
delete o[1]; // 要素ストアに穴ができます。
console.log(o[1]); // 'undefined' と出力。プロパティ1は存在しません。
o.__proto__ = {1: 'B'}; // プロトタイプ上にプロパティ1を定義。
console.log(o[0]); // 'a' と出力。
console.log(o[1]); // 'B' と出力。
console.log(o[2]); // 'c' と出力。
console.log(o[3]); // undefinedと出力。

簡単に言うと、受信側にプロパティが存在しない場合、プロトタイプチェーンを引き続き探す必要があります。要素は自己完結型であり、例えばHiddenClassに存在するインデックス付きプロパティの情報を保持しないため、特別な値(hole)を使用してプロパティが存在しないことをマークする必要があります。これは配列関数のパフォーマンスにとって重要です。穴がない、つまり要素ストアが詰まっている(packed)ことがわかっていれば、プロトタイプチェーンでの高価な検索を行わずにローカル操作を実行できます。
高速または辞書要素: 要素に関して行われるもう1つの主要な区別は、それが高速か辞書モードかです。高速要素は単純なVM内部の配列であり、プロパティインデックスが要素ストア内のインデックスに対応しています。ただし、この単純な表現は、非常に大きくまばら/穴あきの配列の場合、多くのエントリが占有されていないため、かなり無駄です。この場合、わずかに遅いアクセスのコストでメモリを節約するために、辞書ベースの表現を使用します:
const sparseArray = [];
sparseArray[9999] = 'foo'; // 辞書要素を持つ配列を作成します。
この例では、10kエントリを持つ完全な配列を割り当てるのは非常に無駄です。代わりにV8は辞書を作成し、ここでキー-値-ディスクリプタの3つ組を保存します。この場合キーは '9999' で値は 'foo' になり、デフォルトディスクリプタが使用されます。カスタムディスクリプタでインデックス付きプロパティを定義した場合、HiddenClass上にディスクリプタの詳細を保存する方法がないため、V8は遅い要素に切り替えます:
const array = [];
Object.defineProperty(array, 0, {value: 'fixed', configurable: false});
console.log(array[0]); // 'fixed' と出力。
array[0] = 'other value'; // インデックス0を上書きできません。
console.log(array[0]); // 依然として 'fixed' と出力。
この例では、配列上に非設定可能なプロパティを追加しました。この情報は、遅い要素辞書の3つ組のディスクリプタ部分に保存されます。遅い要素を持つオブジェクト上での配列関数のパフォーマンスは大幅に低下することに注意が必要です。
SmiとDouble要素: 高速要素については、V8でさらに重要な区別があります。例えば、配列に整数のみを格納する場合、一般的なユースケースとして、GCは配列を参照する必要がありません(整数は場所に直接エンコードされ、いわゆるスモール整数(Smi)として保存されます)。別の特殊ケースは、倍精度浮動小数点数のみを含む配列です。Smiとは異なり、浮動小数点数は通常、複数のワードを占有する完全なオブジェクトとして表現されます。ただし、V8は純粋な浮動小数点配列の場合、メモリと性能のオーバーヘッドを回避するために生データの倍精度浮動数を保存します。以下の例は、SmiおよびDouble要素の4つの例を示しています:
const a1 = [1, 2, 3]; // Smi Packed
const a2 = [1, , 3]; // Smi Holey, a2[1] はプロトタイプを読み取ります
const b1 = [1.1, 2, 3]; // Double Packed
const b2 = [1.1, , 3]; // Double Holey, b2[1] はプロトタイプを読み取ります
特殊要素: これまでの情報で、20種類の要素のうち7種類をカバーしました。簡単にするために、TypedArrays用の9種類、文字列ラッパー用の2種類、最後に引数オブジェクト用の2種類の特殊な要素を除外しました。
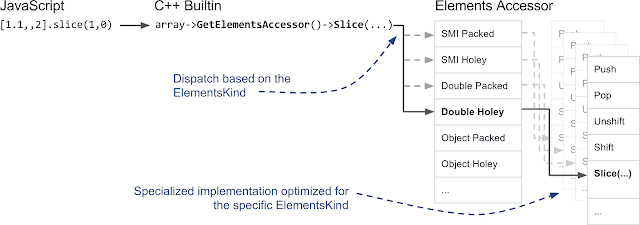
ElementsAccessor(エレメンツアクセサ): ご想像の通り、C++で要素種ごとに20回もArray関数を書くのはあまり気が進みません。ここでC++の魔法が活用されます。同じArray関数を繰り返し実装する代わりに、ElementsAccessorを構築し、主にバックストアから要素を取得するための単純な関数を実装します。ElementsAccessorはCRTPに依存して各Array関数の特殊化バージョンを作成します。例えば、配列に対してsliceのようなメソッドを呼び出すと、V8は内部的にC++で書かれたビルトインを呼び出し、ElementsAccessorを介して関数の特殊化バージョンにディスパッチします:
このセクションの重要なポイント:
- 高速モードと辞書モードのインデックス付きプロパティおよび要素があります。
- 高速プロパティはパックされている場合もあれば、インデックス付きプロパティが削除されたことを示す穴を含む場合もあります。
- 要素はその内容に基づいて特殊化され、Array関数を高速化し、GCのオーバーヘッドを削減します。
プロパティの仕組みを理解することはV8での多くの最適化の鍵となります。JavaScript開発者にはこれらの内部的な決定は直接は見えませんが、特定のコードパターンが他のパターンより速い理由を説明します。プロパティや要素のタイプを変更すると、通常V8が異なるHiddenClassを作成し、型の汚染を引き起こす可能性があります。これによりV8が最適なコードを生成できなくなることがあります。V8のVM内部構造がどのように動作するかについて、さらなる投稿をお待ちください。