V8ヒープスナップショットの高速化
このブログ投稿はJosé Dapena Paz (Igalia) によって執筆され、Jason Williams (Bloomberg)、Ashley Claymore (Bloomberg)、Rob Palmer (Bloomberg)、Joyee Cheung (Igalia)、およびShu-yu Guo (Google) の貢献を受けています。
この投稿では、V8ヒープスナップショットに関して、Bloombergのエンジニアが発見したいくつかのパフォーマンスの問題と、それを解決してJavaScriptメモリ分析をこれまで以上に高速化する方法について話します。
問題
Bloombergのエンジニアは、JavaScriptアプリケーションのメモリリークを診断する作業を行っていました。アプリはOut-Of-Memoryエラーで失敗していました。テストされたアプリケーションでは、V8ヒープの上限が約1400 MBに設定されていました。通常、V8のガベージコレクターはヒープ使用量をその制限内に保つことができるはずであるため、この失敗はリークがある可能性を示していました。
このような通常のメモリリークシナリオをデバッグする一般的な手法は、まずヒープスナップショットをキャプチャし、それをDevToolsの「メモリ」タブでロードして、さまざまな要約やオブジェクト属性を調査することで最もメモリを消費しているものを見つけることです。DevTools UIでは、「メモリ」タブでヒープスナップショットを取得できます。Node.jsアプリケーションの場合、ヒープスナップショットはこのAPIを使用してプログラムでトリガーできます:
require('v8').writeHeapSnapshot();
彼らはアプリケーションのライフサイクルのさまざまなポイントで複数のスナップショットをキャプチャし、DevToolsメモリビューアを使用して異なる時点でのヒープの違いを表示したいと考えていました。しかし、500 MBのフルサイズのスナップショットを1つキャプチャするのに30分以上かかっていました!
メモリ分析のワークフローのこの遅さを解決する必要がありました。
問題の絞り込み
次に、BloombergのエンジニアはいくつかのV8パラメータを使用して問題を調査し始めました。この投稿で説明されているように、Node.jsとV8にはそれを助けるための便利なコマンドラインパラメータがあります。これらのオプションは、ヒープスナップショットを作成し、再現を簡素化し、観測性を向上させるために使用されました:
--max-old-space-size=100: これによりヒープが100 MBに制限され、問題の再現がはるかに早くなります。--heapsnapshot-near-heap-limit=10: これはNode.jsの特定のコマンドラインパラメータで、メモリ不足に近づいた場合にスナップショットを生成するようにNode.jsに指示します。これは合計で最大10個のスナップショットを生成するよう設定されています。これにより、メモリ不足のプログラムが必要以上のスナップショットを作成することに時間を費やすスラッシングを防止します。--enable-etw-stack-walking: ETW、WPA、xperfなどのツールがV8で呼び出されたJSスタックを見ることができるようにします。(Node.js v20+で利用可能)--interpreted-frames-native-stack: このフラグは、ETW、WPA、xperfなどのツールと組み合わせて使用され、プロファイリング時にネイティブスタックを見るために使用されます。(Node.js v20+で利用可能)
V8ヒープのサイズが制限に近づくと、V8はガベージコレクションを強制してメモリ使用量を削減します。また、エンベッダーにこのことを通知します。Node.jsの--heapsnapshot-near-heap-limitフラグは、通知ごとに新しいヒープスナップショットを生成します。テストケースでは、メモリ使用量が減少しますが、いくつかの反復後にはガベージコレクションが十分なスペースを解放できず、アプリケーションはOut-Of-Memoryエラーで終了します。
彼らはWindows Performance Analyzerを使用して記録を取り、問題を絞り込みました。これにより、ほとんどのCPU時間がV8ヒープエクスプローラー内で費やされていることが明らかになりました。具体的には、ヒープ内を移動して各ノードを訪問し名前を収集するのに約30分かかりました。このようなプロパティの名前を記録するだけでなぜこれほどの時間がかかるのかは明確ではありませんでした。
ここで私に調査依頼が来ました。
問題を定量化する
最初のステップは、ヒープスナップショットのキャプチャ中にどこで時間が費やされるかをよりよく理解するために、V8にサポートを追加することでした。キャプチャプロセス自体は、生成とシリアル化の2つの段階に分けられます。私たちはこのパッチをアップストリームに導入し、新しいコマンドラインフラグ--profile_heap_snapshotをV8に追加しました。これにより、生成時間とシリアル化時間の両方のログが有効になります。
このフラグを使用して、いくつか興味深いことを学びました!
まず、V8が各スナップショットの生成に費やしている正確な時間を観察することができました。簡略化したテストケースでは、最初のスナップショットに5分、2番目に8分かかり、その後のスナップショットはさらに時間がかかるようになりました。この時間のほとんどは生成フェーズで費やされていました。
これにより、スナップショット生成に費やされた時間をわずかなオーバーヘッドで定量化でき、その結果、他の広く使用されているJavaScriptアプリケーション、特にTypeScriptのESLintで類似の遅延を特定する手助けとなりました。この問題が特定のアプリ固有ではないことがわかりました。
さらに、この問題はWindowsとLinuxの両方で発生していることが判明しました。プラットフォーム固有の問題ではないことがわかりました。
最初の最適化: 改良されたStringsStorageのハッシュ化
過剰な遅延を引き起こしていた原因を特定するために、Windows Performance Toolkitを使用してスクリプトをプロファイルしました。
Windows Performance Analyzerで記録を開くと、以下のような結果が得られました。
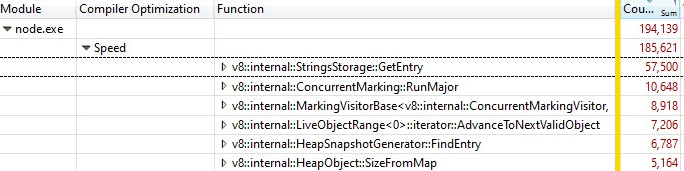
サンプルの3分の1がv8::internal::StringsStorage::GetEntryで費やされていました。
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
リリースビルドで実行されたため、インライン化された関数呼び出しの情報はStringsStorage::GetEntry()に折りたたまれていました。インライン化された関数呼び出しの正確な時間を測定するため、「Source Line Number」列を内訳に追加したところ、ほとんどの時間が182行目、つまりComputeStringHash()への呼び出しに費やされていることがわかりました。
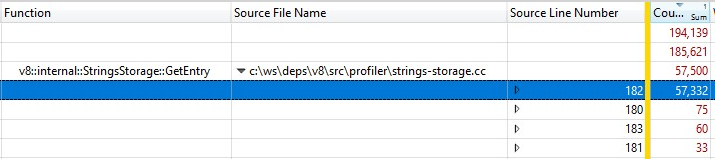
つまり、スナップショット生成時間の30%以上がComputeStringHash()に費やされていたのですが、なぜでしょうか?
StringsStorageについて説明します。このクラスの目的は、ヒープスナップショットで使用されるすべての文字列のユニークなコピーを保存することです。高速なアクセスと重複を回避するために、このクラスは配列をバックエンドとしたハッシュマップを使用しており、衝突時には配列内の次の空き場所に要素を格納します。
衝突が原因で配列内で長い検索が発生しているのではないかと疑い、生成されたハッシュキーを確認するための詳細なログを追加しました。挿入時には、ハッシュキーから計算された期待位置と衝突によって実際に格納された位置とのオフセットを記録しました。
ログでは、状況は…正常ではありませんでした。多くのアイテムのオフセットが20を超えており、最悪の場合は数千単位にもなっていました!
問題の一部は数値文字列、特に連続した多くの数値範囲の文字列によって引き起こされていました。ハッシュキーアルゴリズムは、数値文字列用とそれ以外の文字列用の2つの実装を持っていました。文字列のハッシュ関数はかなり一般的でしたが、数値文字列用の実装は実質的に桁数を先頭に加えた数値の値を返していました。
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
この関数には問題がありました。このハッシュ関数の問題例としては次のようなものがあります。
- 小さな数値を持つハッシュキー値の文字列を挿入すると、その位置に別の数値を格納しようとした際に衝突が発生し、連続した数値を格納しようとした場合にも同様の衝突が発生します。
- さらに悪いことに、すでに多くの連続した数値がマップに格納されている場合、その範囲内のハッシュキー値を持つ文字列を挿入しようとすると、空き場所を見つけるためにすべての占有された位置を移動しなければなりません。
解決方法は?問題の多くは連続位置に入る数値文字列によるものであるため、ハッシュ関数を変更して結果のハッシュ値を2ビット左回転させるようにしました。
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
これにより、連続する数値のペアごとに3つの空き位置が生成されるようになりました。この変更は、いくつかのワークセットでの経験的テストに基づいて衝突を最小限に抑えるために最適であると判断されました。
このハッシュ修正はV8に導入されました。
第二の最適化: ソース位置のキャッシュ
ハッシュ修正後、再プロファイリングを行い、さらにオーバーヘッドを大幅に削減できる最適化の機会を見つけました。
ヒープスナップショットを生成する際、ヒープ内の各関数について、V8はその開始位置を行番号と列番号のペアとして記録しようとします。この情報はDevToolsで関数のソースコードへのリンクを表示するのに使用されます。しかし通常のコンパイル時、V8は各関数の開始位置をスクリプトの先頭からの線形オフセットの形式でのみ保存します。この線形オフセットに基づいて行番号と列番号を計算するためには、V8はスクリプト全体を巡回して行の改行箇所を記録する必要があります。この計算は非常に高コストとなります。
通常、V8がスクリプト内の改行オフセットを計算し終えた後、それをスクリプトに付随する新たに割り当てられた配列にキャッシュします。しかしながら、スナップショット実装はヒープを巡回する際にヒープを変更することができないため、新しく計算した行の情報をキャッシュすることができません。
解決策?ヒープスナップショットを生成する前に、V8コンテキスト内のすべてのスクリプトを巡って改行オフセットを計算し、キャッシュすることです。これをヒープスナップショット生成のためにヒープを巡回する間に行うわけではないため、ヒープを変更してソース行位置をキャッシュとして保存することが可能です。
改行オフセットキャッシュの修正もV8に導入されました。
速度改善を達成したのか?
両方の修正を有効化した後、再プロファイリングしました。それらの修正はスナップショット生成時間のみに影響するため、予想通りスナップショットのシリアル化時間には影響はありませんでした。
JSプログラムを操作している際に…
- 開発用JSの場合、生成時間が50%高速化 👍
- 本番用JSの場合、生成時間が90%高速化 😮
なぜ本番コードと開発コードでこれほどの差が出たのか?本番コードはバンドリングと縮小化によって最適化されており、JSファイルの数が少なく、それらのファイルは概して大きいです。これら大型ファイルのソース行位置を計算するのに時間がかかるため、ソース位置をキャッシュし再計算を避けることで最大の恩恵を受けます。
最適化はWindowsおよびLinuxのターゲット環境で検証されました。
Bloombergエンジニアが当初直面した特に困難な問題に関して、100MBのスナップショットを取得する合計のエンドツーエンド時間は、辛い10分からとても快適な6秒に短縮されました。それは100倍の改善です! 🔥
これらの最適化は汎用的な改善であり、V8、Node.js、Chromiumでメモリデバッグを行う誰にとっても広く適用可能であると期待されています。この改善はV8 v11.5.130にて導入され、Chromium 115.0.5576.0に含まれています。次のセムバーメジャーリリースでNode.jsがこれらの最適化を採用するのを楽しみにしています。
次は何か?
まず、Node.jsがNODE_OPTIONSで新しい--profile-heap-snapshotフラグを受け入れるようになると便利でしょう。一部のユースケースでは、ユーザーがNode.jsに直接渡されるコマンドラインオプションを制御できず、環境変数NODE_OPTIONSを通じてそれらを設定する必要があります。現在、Node.jsは環境変数で設定されたV8コマンドラインオプションをフィルタリングし、既知のサブセットのみ許可しています。このため、新しいV8フラグをNode.jsでテストするのが難しい場合があります。私たちのケースでもそれが起こりました。
スナップショット内の情報精度をさらに改善できます。現在、各スクリプトソースコードの行情報はV8ヒープ内自体に表現として格納されています。これは問題です。なぜなら、計測対象に影響を与えずに性能測定オーバーヘッドなしでヒープを正確に測定したいからです。理想的には、ヒープスナップショット情報の精度を向上させるために、行情報のキャッシュをV8ヒープ外に保存するべきです。
最後に、生成フェーズを改善したことで、次に最大のコストはシリアル化フェーズとなりました。さらなる分析によってシリアル化における新しい最適化の機会が見つかるかもしれません。