Liftoff: WebAssemblyのためのV8における新しいベースラインコンパイラ
V8 v6.9には、WebAssemblyのための新しいベースラインコンパイラであるLiftoffが含まれています。Liftoffは現在デスクトップシステムでデフォルトで有効になっています。この記事では新しいコンパイルレベルを導入する動機と、Liftoffの実装とパフォーマンスについて詳しく説明します。

WebAssemblyが公開されてから1年以上が経過し、ウェブでの採用が着実に増加しています。WebAssemblyをターゲットとした大規模なアプリケーションが登場し始めています。例えば、EpicのZenGardenベンチマークは39.5 MBのWebAssemblyバイナリで構成され、AutoDeskは36.8 MBのバイナリとして提供されています。コンパイル時間はバイナリサイズにほぼ線形に比例するため、これらのアプリケーションは起動にかなりの時間を要します。多くの機械では30秒以上かかり、優れたユーザー体験を提供するとは言えません。
では、同じようなJSアプリがもっと速く起動するのに、なぜWebAssemblyアプリの起動がこれほど遅いのでしょうか?その理由は、WebAssemblyが予測可能なパフォーマンスを提供することを約束しているためです。一度アプリが動作し始めると、パフォーマンス目標(例:60fpsの描画、音声の遅れやアーティファクトなし)を安定して達成できることが保証されます。このために、WebAssemblyコードはV8で事前コンパイルされ、Just-In-Timeコンパイラによるコンパイルの停止がアプリに目立つジャンクを引き起こすのを回避します。
既存のコンパイルパイプライン(TurboFan)
V8のWebAssemblyコンパイルアプローチは、JavaScriptとasm.js向けに設計されたTurboFan、最適化コンパイラに依存してきました。TurboFanは、強力なコンパイラであり、強度削減、インライン化、コード移動、命令の結合、高度なレジスタ割り当てなどの高度な最適化に適したグラフベースの*中間表現(IR)*を持っています。TurboFanの設計は、JavaScriptコンパイルをサポートするための多くのステージをバイパスし、パイプラインに非常に遅く入ることをサポートしています。その設計により、WebAssemblyコードをTurboFanのIRに変換する(SSA構築を含む)シンプルな単一のパスが非常に効率的であり、部分的にはWebAssemblyの構造化された制御フローが寄与しています。しかし、コンパイルプロセスのバックエンドは依然としてかなりの時間とメモリを消費します。
新しいコンパイルパイプライン(Liftoff)
Liftoffの目標は、WebAssemblyベースのアプリケーションの起動時間を可能な限り速く短縮することです。コード品質は二次的な問題であり、ホットコードは結局TurboFanで再コンパイルされるからです。LiftoffはIRの構築に伴う時間とメモリのオーバーヘッドを避け、WebAssembly関数のバイトコードを1回通過するだけで機械コードを生成します。

上記の図から明らかなように、Liftoffはパイプラインが2つのステージしかないため、TurboFanよりもはるかに速くコードを生成できるはずです。実際、関数ボディデコーダは生のWebAssemblyバイトを1回の通過で処理し、後続のステージにコールバックを通じて対話するため、コード生成は関数ボディのデコードと検証中に行われます。WebAssemblyの*ストリーミングAPI*と組み合わせることで、V8はネットワークからのダウンロード中にWebAssemblyコードを機械コードにコンパイルすることが可能です。
Liftoffにおけるコード生成
Liftoff はシンプルなコード生成器であり、高速です。それは関数のオペコードを1回だけ通過し、各オペコードに対して1つずつコードを生成します。算術のような単純なオペコードの場合、通常これが単一の機械命令になりますが、呼び出しのような他の場合はもっと多くなり得ます。Liftoff はオペランドスタックに関するメタデータを維持し、各操作の入力が現在どこに保存されているかを認識します。この「仮想スタック」はコンパイル中にのみ存在します。WebAssemblyの構造化制御フローと検証ルールは、これらの入力の位置が静的に決定できることを保証します。したがって、オペランドがプッシュおよびポップされる実際のランタイムスタックは必要ありません。実行中には、仮想スタック上の各値は、レジスタ内で保持されるか、関数の物理スタックフレームに溢れるかのどちらかです。小さい整数定数(例えば i32.const で生成されるもの)の場合、Liftoff は仮想スタックに定数の値を記録するだけで、コードを生成しません。定数が後続の操作で使用される場合にのみ、それが放出されるか、操作と組み合わされます。例えば、直接 x64で addl <reg>, <const> 命令を放出することなどです。これにより、定数をレジスタに読み込むことが回避され、より優れたコードが得られます。
非常にシンプルな関数を取り上げて、Liftoff がそのコードを生成する際のプロセスを見てみましょう。

この例の関数は2つのパラメータを取得し、それらの合計値を返します。Liftoff がこの関数のバイトをデコードすると、まず内部状態を初期化し、WebAssembly関数の呼び出し規約に従ってローカル変数を設定します。x64の場合、V8 の呼び出し規約は2つのパラメータをレジスタ rax と rdx に渡します。
get_local 命令の場合、Liftoff はコードを生成せず、これらのレジスタ値が仮想スタックにプッシュされていることを反映するように内部状態を更新するだけです。次に i32.add 命令が2つのレジスタをポップし、結果値のためのレジスタを選びます。入力レジスタを結果に使用することはできません、なぜならこれらのレジスタは依然としてローカル変数を保持するためにスタック上にあるからです。それらを上書きすると後の get_local 命令によって返される値が変わってしまいます。そこで、Liftoff は空いているレジスタを選びます。この場合は rcx を選び、rax と rdx の合計をそのレジスタに生成します。そして rcx が仮想スタックにプッシュされます。
i32.add 命令の後、関数本体が終了するため、Liftoff は関数の戻りを組み立てる必要があります。例の関数が1つの戻り値を持っているため、検証は関数本体の終わりに仮想スタックに正確に1つの値がある必要があると求めます。そのため、Liftoff は rcx に保持されている戻り値を正しい戻り値レジスタ rax に移動させ、その後関数から戻るコードを生成します。
簡潔さを考慮して、上記の例にはブロック(if、loop など)や分岐は含まれていません。WebAssembly のブロックは制御の統合を導入します、つまりコードが任意の親ブロックに分岐することができるため、また、if ブロックはスキップできるからです。これらの統合ポイントは異なるスタック状態から到達することができます。しかし、後続のコードは特定のスタック状態を仮定してコードを生成する必要があります。そのため、Liftoff は現在の仮想スタックの状態を新しいブロックの後続コードが仮定する状態としてスナップショットを取ります(つまり、現在いる 制御レベル に戻る時点です)。新しいブロックは現在アクティブな状態で続行し、スタック値やローカルがどこに保存されるかを変更する可能性があります。一部はスタックに溢れるか、他のレジスタに保持されるかもしれないからです。別のブロックに分岐する際やブロックが終了する際(親ブロックへの分岐と同じこと)、Liftoff は現在の状態をその時点で想定される状態に適応するコードを生成する必要があります。これにより、分岐対象のターゲットで生成されたコードが期待される場所で正しい値を見つけられます。検証により現在の仮想スタックの高さが期待される状態の高さと一致することが保証されるため、Liftoff はレジスタ間または物理スタックフレーム間で値をシャッフルするコードを生成するだけで済みます。次の例を見てみましょう。
次の例を見てみましょう。

上記の例は、オペランドスタックに2つの値を持つ仮想スタックを想定しています。新しいブロックを開始する前に、仮想スタックの上部の値が if 命令への引数としてポップされます。残りのスタック値は別のレジスタに配置する必要があります、現在は最初のパラメータを影にしている状態ですが、この状態に戻る際にはスタック値とパラメータを2つ別々に保持する必要がある場合があるからです。この場合、Liftoff はそれを rcx レジスタに重複排除することを選びます。この状態がスナップショットされ、ブロック内でアクティブ状態が変更されます。ブロックの最後に親ブロックへの分岐が暗黙的に行われるため、現在の状態をスナップショットに統合するために rbx レジスタを rcx に移動させ、rdx レジスタをスタックフレームからリロードします。
Liftoff から TurboFan へのティアリングアップ
Liftoff と TurboFan により、V8 は現在WebAssemblyのための2つのコンパイルティアを持っています:速い起動のための基礎コンパイラである Liftoff と最大のパフォーマンスのための最適化コンパイラである TurboFan です。この2つのコンパイラをどのように組み合わせて全体として最良のユーザー体験を提供するかが課題になります。
JavaScriptの場合、V8はIgnitionインタプリタとTurboFanコンパイラを使用し、動的ティアリングアップ戦略を採用しています。各関数は最初にIgnitionで実行され、関数がホットになるとTurboFanがそれを高度に最適化された機械コードにコンパイルします。このようなアプローチはLiftoffでも使用できますが、ここではトレードオフが少し異なります:
- WebAssemblyでは高速コードを生成するために型フィードバックを必要としません。JavaScriptが型フィードバックを収集することで大いに恩恵を受けるのに対し、WebAssembly は静的に型付けされているため、エンジンは最初から最適化されたコードを生成することができます。
- WebAssemblyコードは予測可能な速さで動作し、長いウォームアップフェーズを必要としないべきです。アプリケーションがWebAssemblyをターゲットとする理由の一つは、予測可能な高性能でWeb上で実行することです。そのため、低速なコードを長時間実行することを容認することも、実行中にコンパイルの停止を受け入れることもできません。
- JavaScriptのIgnitionインタープリタの重要な設計目標は、関数を全くコンパイルしないことでメモリ使用量を削減することです。しかし、WebAssemblyインタープリタは予測可能な高速な性能を提供するにはあまりにも遅すぎることが分かりました。実際にそのようなインタープリタを構築しましたが、コンパイル済みコードよりも20倍以上遅いため、メモリを節約するにもかかわらずデバッグ用途にしか有用ではありません。このことを考慮すると、エンジンは結局コンパイル済みのコードを保持する必要があります。最終的には、最もコンパクトで効率的なコードであるTurboFanの最適化されたコードのみを保持するべきです。
これらの制約から、現在のV8のWebAssembly実装において動的ティアアップは適切なトレードオフではないと結論付けました。動的ティアアップはコードサイズを増加させ、不確定な期間性能を低下させる可能性があるためです。その代わりに、早期ティアアップ戦略を選択しました。Liftoffでモジュールのコンパイルが完了すると、WebAssemblyエンジンはモジュールの最適化されたコードを生成するバックグラウンドスレッドを即座に開始します。これにより、Liftoffの完了後にコードをすぐに実行し、高性能なTurboFanコードを可能な限り早く利用できるようになります。
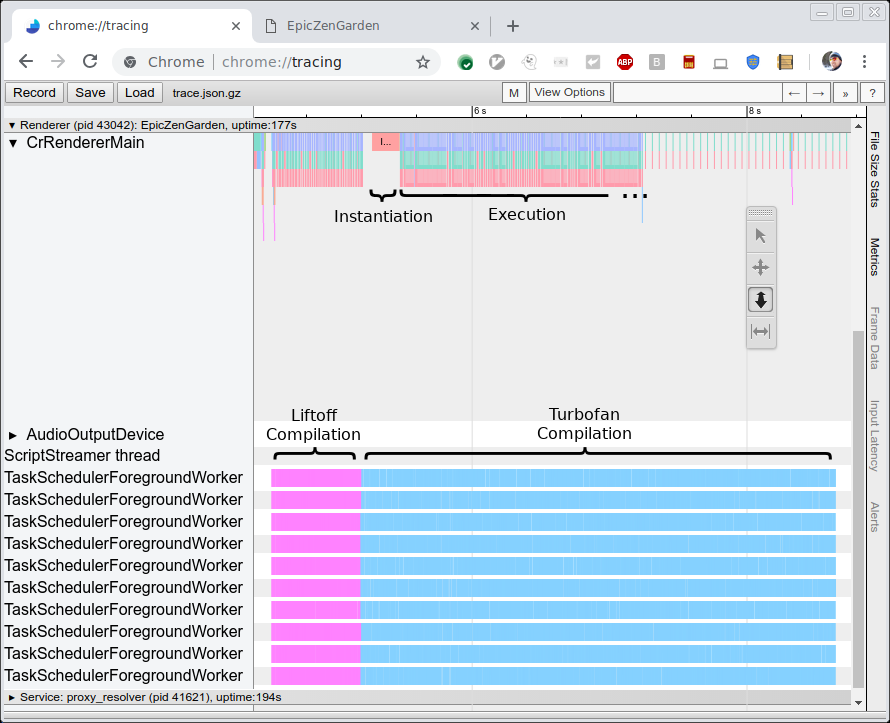
下の図は、EpicZenGardenベンチマークをコンパイルおよび実行するトレースを示しています。この図から、Liftoffコンパイルが完了するとすぐにWebAssemblyモジュールをインスタンス化して実行を開始できることが分かります。TurboFanのコンパイルにはさらに数秒かかるため、そのティアアップ期間中は個々のTurboFan関数が完了次第使用されるため、観察された実行性能が徐々に向上します。
パフォーマンス
新しいLiftoffコンパイラの性能を評価するために興味深い指標が2つあります。まず、TurboFanと比較したコンパイル速度(すなわちコード生成までの時間)を評価したいです。次に、生成されたコードの性能(すなわち実行速度)を測定します。ここではLiftoffの目的がコードを可能な限り迅速に生成することで起動時間を短縮することであるため、最初の指標がより興味深いです。一方、生成されたコードの性能も低品質なハードウェア上で数秒または数分間実行される可能性があるため、まだ十分に良好であるべきです。
コード生成性能
コンパイラの性能そのものを測定するため、いくつかのベンチマークを実行し、トレースを使用して生のコンパイル時間を測定しました(上の図を参照)。ベンチマークはHP Z840マシン(2 x Intel Xeon E5-2690 @2.6GHz、24コア、48スレッド)およびMacBook Pro(Intel Core i7-4980HQ @2.8GHz、4コア、8スレッド)で実行します。現在のChromeはバックグラウンドスレッドを10以上使用していないため、Z840マシンのほとんどのコアは使用されません。
3つのベンチマークを実行します:
- EpicZenGarden:Epicフレームワーク上で動作するZenGardenデモ
- Tanks!:Unityエンジンのデモ
- AutoDesk
- PSPDFKit
各ベンチマークについて、上記のようにトレース出力を使用して生のコンパイル時間を測定します。この数値はベンチマーク自体が報告する時間よりも安定しており、タスクがメインスレッド上でスケジュールされることに依存せず、実際のWebAssemblyインスタンスの作成のような無関係な作業を含みません。
以下のグラフはこれらのベンチマークの結果を示しています。各ベンチマークは3回実行され、平均コンパイル時間を報告します。


予想どおり、Liftoffコンパイラは高性能デスクトップワークステーションおよびMacBookの両方でコードをはるかに迅速に生成します。TurboFanに対するLiftoffの高速化は、能力の低いMacBookハードウェア上ではさらに顕著です。
生成されたコードの性能
生成されたコードの性能は副次的な目標であるにもかかわらず、LiftoffコードがTurboFanコードが完成するまでの数秒間実行される可能性があるため、起動段階で高性能なユーザー体験を保持したいです。
Liftoffコードの性能を測定するため、ティアアップを無効にして純粋なLiftoff実行を測定しました。この設定では2つのベンチマークを実行します:
-
Unityヘッドレスベンチマーク
Unityフレームワークで動作する一連のベンチマークです。これらはヘッドレスであり、したがってd8シェルで直接実行できます。各ベンチマークはスコアを報告します。このスコアは必ずしも実行性能と比例しているわけではありませんが、性能を比較するには十分です。
-
このベンチマークでは、PDFドキュメントに対して異なる操作を実行するのにかかる時間と、WebAssemblyモジュールをインスタンス化するのにかかる時間(コンパイルを含む)が報告されています。
以前と同様に、それぞれのベンチマークを3回実行し、3回の実行の平均を使用します。記録された数値のスケールがベンチマーク間で大きく異なるため、Liftoff対TurboFanの相対的な性能を報告します。値が*+30%*の場合、LiftoffコードはTurboFanより30%遅く実行されることを意味します。負の数値は、Liftoffのほうが高速に実行されることを示します。以下が結果です:

Unityでは、Liftoffコードはデスクトップマシンで平均的にTurboFanコードより約50%遅く、MacBookでは70%遅く実行されます。興味深いことに、1つのケース(Mandelbrot Script)ではLiftoffコードがTurboFanコードを上回る結果となっています。これは例えば、TurboFanのレジスタアロケータがホットループでパフォーマンスを発揮しない場合などの外れ値である可能性があります。このケースをより良く扱えるようにTurboFanを改善できないか調査中です。

PSPDFKitベンチマークでは、Liftoffコードは最適化されたコードより18-54%遅く実行されますが、予想通り初期化時間は大幅に改善されています。これらの数値は、JavaScript呼び出しを通じてブラウザとやり取りする実世界のコードでは、未最適化コードによる性能損失が、より計算集約的なベンチマークよりも一般的に少ないことを示しています。
そして再び、この数値は完全にティアアップをオフにした状態で得られたものであることに注意してください。このため、実行されたのは常にLiftoffコードのみです。実運用の設定では、Liftoffコードは徐々にTurboFanコードに置き換えられ、Liftoffコードの性能低下は短時間で済むようになっています。
今後の作業
Liftoffの最初のリリース後、初期化時間のさらなる改善、メモリ使用量の削減、およびLiftoffの利点をより多くのユーザーに提供する作業を進めています。特に以下の項目に取り組んでいます:
- LiftoffをARMおよびARM64に移植してモバイルデバイスでも使用可能にする。 現在のところ、LiftoffはIntelプラットフォーム(32ビットおよび64ビット)のみで実装されており、主にデスクトップの使用例をカバーしています。モバイルユーザーにも到達するために、Liftoffをより多くのアーキテクチャに移植します。
- モバイルデバイス向けの動的ティアアップを実装する。 モバイルデバイスはデスクトップシステムよりも利用可能なメモリがかなり少ない傾向があるため、これらのデバイス向けにティアリング戦略を適応させる必要があります。TurboFanですべての関数を再コンパイルすると、少なくとも一時的に(Liftoffコードが破棄されるまで)必要なコードを保持するメモリが簡単に倍増します。代わりに、Liftoffによる遅延コンパイルと、TurboFanでのホット関数の動的ティアアップの組み合わせを試みています。
- Liftoffコード生成の性能を改善する。 実装の初回のイテレーションが最良であることは稀です。Liftoffのコンパイル速度をさらに向上させるために調整できるいくつかのポイントがあります。これらは次回以降のリリースで徐々に行われます。
- Liftoffコードの性能を改善する。 コンパイラそのものに加えて、生成されたコードのサイズや速度も改善可能です。これもまた次回以降のリリースで徐々に進行します。
結論
V8には、新しいWebAssembly向けのベースラインコンパイラであるLiftoffが追加されました。Liftoffは、シンプルで高速なコード生成器により、WebAssemblyアプリケーションの起動時間を大幅に短縮します。デスクトップシステムでは、V8はバックグラウンドでの全コード再コンパイルを通じて最大のピーク性能を達成します。LiftoffはV8 v6.9(Chrome 69)でデフォルトで有効化されており、それぞれ--liftoff/--no-liftoffフラグおよびchrome://flags/#enable-webassembly-baselineフラグによって明示的に制御できます。