JavaScript開発者向けコードキャッシュ
コードキャッシュ(_バイトコードキャッシュ_とも呼ばれる)は、ブラウザにおける重要な最適化です。解析とコンパイル結果をキャッシュすることで、頻繁に訪問されるウェブサイトの起動時間を短縮します。多くの人気のある ブラウザが何らかのコードキャッシング機能を実装しており、Chromeも例外ではありません。実際、過去に書かれたことがありますし話すこともありました。また、ChromeとV8がどのようにコンパイル済みコードをキャッシュするかについて説明しています。
このブログ記事では、コードキャッシングを最大限に活用して、ウェブサイトの起動を改善したいJS開発者向けにいくつかのアドバイスを提供します。このアドバイスはChrome/V8のキャッシュ実装に焦点を当てていますが、そのほとんどは他のブラウザのコードキャッシュ実装にも適用可能です。
コードキャッシングの概要復習
他のブログ記事やプレゼンテーションでは、私たちのコードキャッシング実装についてより詳細に説明していますが、ここでは仕組みを簡単に復習する価値があります。ChromeにはV8コンパイル済みコード(従来のスクリプトとモジュールスクリプトの両方)に対して2層のキャッシングがあります。低コストの「ベストエフォート」メモリ内キャッシュ(Isolate キャッシュ)と、完全に直列化されたオンディスクキャッシュです。
Isolate キャッシュは、同じV8 Isolate(つまり、同じプロセス、ざっくり言うと「同じウェブサイトのページを同じタブでナビゲートしている状態」)内でコンパイルされたスクリプトに対して動作します。これは、「ベストエフォート」という点で可能な限り高速かつ最小限になろうとし、既に利用可能なデータを使用し、プロセス間のキャッシングが欠落する可能性があるヒット率の低下を犠牲にすることを意味します。
- V8がスクリプトをコンパイルするとき、そのコンパイルされたバイトコードはスクリプトのソースコードをキーとしてハッシュテーブル(V8ヒープ上)に保存されます。
- ChromeがV8に別のスクリプトをコンパイルするよう求めると、V8は最初にそのスクリプトのソースコードがこのハッシュテーブル内の何かと一致するかどうかを確認します。一致する場合は、既存のバイトコードを単に返します。
このキャッシュは高速で実質的に無料ですが、実際に80%の高ヒット率を観察しています。
オンディスクコードキャッシュはChrome(具体的にはBlink)が管理しており、Isolate キャッシュが埋められないギャップを埋めます:プロセス間、および複数のChromeセッション間でコードキャッシュを共有する機能です。これは、ウェブから受信したデータのキャッシュと期限切れ管理を行う既存のHTTPリソースキャッシュを利用します。
- JSファイルが最初に要求されたとき(つまり、コールドラン)、ChromeはそれをダウンロードしてV8にコンパイルさせます。また、そのファイルをブラウザのオンディスクキャッシュに保存します。
- JSファイルが2回目に要求された場合(つまり、ウォームラン)、Chromeはブラウザのキャッシュからそのファイルを取り出し、再びV8にコンパイルさせます。ただし今回は、コンパイルされたコードが直列化され、キャッシュされたスクリプトファイルにメタデータとして添付されます。
- 3回目(つまり、ホットラン)には、Chromeはキャッシュからファイルとそのメタデータを取り出し、両方をV8に渡します。V8がメタデータを逆直列化し、コンパイルをスキップできます。
まとめ:

この説明に基づいて、コードキャッシュの利用を改善するための最良のヒントを提供できます。
ヒント1: 何もしない
理想的には、コードキャッシングを改善するためにJS開発者としてできる最善のことは「何もしない」ことです。これは実際には、受動的に何もしないことと積極的に何もしないことの2つの意味を持ちます。
コードキャッシングは、最終的にはブラウザの実装上の詳細です。ヘリスティックベースのデータ/空間トレードオフ性能最適化であり、その実装とヘリスティックは定期的に(そして実際に)変更されます。私たちV8エンジニアは、進化するウェブ上でこれらのヘリスティックをすべての人に機能するように最善を尽くしており、現在のコードキャッシングの実装詳細に過度に最適化すると、それらの詳細が変更された後の数回リリースで失望する可能性があります。さらに、他のJavaScriptエンジンは異なるコードキャッシング実装のヘリスティックを持っている可能性があります。したがって、コードキャッシュを取得するための最善のアドバイスはJSを書くアドバイスに似ています:クリーンで慣用的なコードを書くことです。そして私たちはそれをキャッシュする方法を最善を尽くして最適化します。
何もしないという受動的な行為に加えて、積極的に何も行わないことを心がけるべきです。キャッシュは本質的に状態が変わらないことに依存しているため、何もしないことがキャッシュされたデータを維持する最善の方法です。積極的に何もしないためのいくつかの方法があります。
コードを変更しない
これは当然のことかもしれませんが、はっきりと述べておく価値があります。新しいコードを公開するたびに、そのコードはまだキャッシュされていません。ブラウザがスクリプトURLへのHTTPリクエストを送信する際、前回そのURLを取得した日付を含めることができ、サーバーがファイルが変更されていないことを認識していれば、304 Not Modifiedレスポンスを返すことでコードキャッシュを維持できます。それ以外の場合は、200 OKレスポンスがキャッシュリソースを更新し、コードキャッシュをクリアして冷状態に戻します。

最新のコード変更をすぐにプッシュしたいという誘惑に駆られがちですが、特定の変更の影響を測定したい場合でも、キャッシュを考慮するとコードをそのままにしておくか、少なくとも可能な限り更新を少なくする方が良いです。たとえば、週に≤ x回のデプロイメント制限を設けることを検討してください。ここでxはキャッシュの維持と新鮮性のトレードオフを調整するスライダーです。
URLを変更しない
コードキャッシュは(現在のところ)スクリプトのURLに関連付けられており、スクリプトの内容を読み込まずに簡単に検索できるようになっています。つまり、スクリプトのURL(クエリパラメータを含む)を変更すると、リソースキャッシュに新しいリソースエントリが作成され、それに伴い新しい冷キャッシュエントリが作成されます。
もちろん、これによりキャッシュを強制的にクリアすることもできますが、それは実装の詳細です。将来的にキャッシュをソーステキストではなくソースURLに関連付けるように変更する可能性があるため、これらのアドバイスが有効でなくなる場合があります。
実行動作を変更しない
コードキャッシュ実装に最近行われた最適化の1つは、コードが実行された後にコンパイル済みコードをシリアル化することです。これは遅延コンパイルされた関数を捕捉するためであり、これらの関数は初期コンパイル時ではなく実行時にのみコンパイルされます。
この最適化は、スクリプトの各実行が同じコード、または少なくとも同じ関数を実行する場合に最も効果的です。例えば、実行時の決定に依存するA/Bテストを行う場合、問題が発生する可能性があります:
if (Math.random() > 0.5) {
A();
} else {
B();
}
この場合、A()またはB()のどちらかが暖状態でコンパイルされ実行され、コードキャッシュに入力されますが、後続の実行時にどちらも実行される可能性があります。代わりに、実行を決定論的に保ち、キャッシュされたパスを維持するよう努めてください。
Tip 2: 何かをする
「何もしない」というアドバイスは、受動的であれ積極的であれ、あまり満足感を与えるものではないかもしれません。そのため、「何もしない」ことに加えて、現在のヒューリスティックと実装を踏まえてできることがいくつかあります。ただし、ヒューリスティックは変更可能であり、それに伴いこのアドバイスも変更される可能性があるため、プロファイリングに代わるものはないことを忘れないでください。

ライブラリを利用するコードから分離する
コードキャッシュはスクリプトごとに粗く行われます。スクリプトの一部が変更されるとそのスクリプト全体のキャッシュが無効になります。たとえば、出荷するコードが安定した部分と変更する部分(ライブラリとビジネスロジックを含む)が1つのスクリプトに混在している場合、ビジネスロジックの変更に伴いライブラリコードのキャッシュが無効になります。
その代わりに、安定したライブラリコードを別のスクリプトに分離し、個別にインクルードすることができます。これにより、ライブラリコードが一度キャッシュされれば、ビジネスロジックが変更されてもキャッシュを維持することができます。
さらに、ライブラリがウェブサイトの異なるページで共有される場合には追加のメリットがあります。コードキャッシュはスクリプトに付随しているため、ライブラリ用のコードキャッシュはページ間でも共有されます。
ライブラリを利用するコードに統合する
コードキャッシュは各スクリプトが実行された後に作成されます。つまり、スクリプトが実行を終了した時点でコンパイルされたそのスクリプト内の関数がコードキャッシュに含まれます。これはライブラリコードにいくつか重要な影響を与えます。
- コードキャッシュは以前のスクリプトからの関数を含めません。
- コードキャッシュは後続のスクリプトによって呼び出される遅延コンパイルされた関数を含めません。
特に、ライブラリが完全に遅延コンパイルされた関数で構成されている場合、これらの関数は後で使用されてもキャッシュされません。
この問題を解決するための一つの方法は、ライブラリとその使用方法を一つのスクリプトに統合し、コードキャッシュがライブラリのどの部分を使用しているかを「認識」できるようにすることです。残念ながら、これは上記のアドバイスとは正反対となります。というのも、万能な解決策は存在しないからです。一般的に、すべてのスクリプトを一つの大きなバンドルに統合することはお勧めしていません。複数の小さなスクリプトに分割する方が、ネットワークリクエストやストリーミングコンパイル、ページのインタラクティビティの向上など、コードキャッシュ以外の理由から全体的に有益であることが多いです。
IIFEのヒューリスティックを活用する
スクリプトの実行が終了するまでにコンパイルされた関数だけがコードキャッシュを行う対象となるため、後で実行される関数の多くがキャッシュされません。イベントハンドラ(onloadも含む)、プロミスチェーン、未使用のライブラリ関数、および</script>が認識される時点までに呼び出されない怠惰にコンパイルされた関数などは、すべて怠惰なままでキャッシュされません。
これらの関数をキャッシュに強制的に含める方法の一つは、コンパイルを強制することです。そのための一般的な方法として、IIFEヒューリスティックを使用する方法があります。IIFE(Immediately-Invoked Function Expressions)は、作成後すぐに呼び出される関数のパターンです。
(function foo() {
// …
})();
IIFEはすぐに呼び出されるため、ほとんどのJavaScriptエンジンはそれを検出して直ちにコンパイルし、怠惰なコンパイルとその後の完全なコンパイルのコストを回避しようとします。IIFEを早期に検出するためのさまざまなヒューリスティックがあり、その最も一般的なものがfunctionキーワードの前に(があることです。
このヒューリスティックが早期に適用されるため、関数が実際にすぐに呼び出されない場合でもコンパイルをトリガーします。
const foo = function() {
// 怠惰にスキップされる
};
const bar = (function() {
// 積極的にコンパイルされる
});
つまり、コードキャッシュに含めるべき関数は、括弧で囲むことで含めることが可能になります。しかし、ヒントが誤って適用された場合、起動時間が悪化する可能性があり、全般的にヒューリスティックを濫用することになるため、必要でない場合はこの方法を避けるのが賢明です。
小さなファイルをまとめる
Chromeにはコードキャッシュの最小サイズがあり、現在は1 KiBのソースコードに設定されています。つまり、小さなスクリプトは全くキャッシュされません。なぜなら、オーバーヘッドの方が利点よりも大きいと判断されるからです。
もしウェブサイトにそのような小さなスクリプトが多数含まれている場合、このオーバーヘッド計算が異なる形で適用される可能性があります。これらをまとめて最小コードサイズを超えるようにし、一般的にスクリプトのオーバーヘッドを削減することで利点を得ることを検討する価値があります。
インラインスクリプトを避ける
HTML内にインラインで記述されたソースを持つスクリプトタグは、それに関連付けられた外部ソースファイルを持たないため、上記のメカニズムによるキャッシュができません。Chromeはインラインスクリプトをキャッシュしようと試みますが、そのキャッシュはHTMLドキュメントのリソースに添付されるため、これらのキャッシュはHTMLドキュメント全体が変化しない場合にのみ機能し、ページ間で共有されません。
したがって、コードキャッシュの利点を得られる可能性のある非トリビアルなスクリプトについては、HTMLにインラインで記述することを避け、外部ファイルとして含めることをお勧めします。
サービスワーカーキャッシュを利用する
サービスワーカーは、ページ内のリソースに対するネットワークリクエストをコードがインターセプトするためのメカニズムです。特に、いくつかのリソースのローカルキャッシュを作成し、このキャッシュからリソースを提供することができます。これは、PWAなど、オフラインでも動作し続けたいページにとって非常に便利です。
サービスワーカーを使用しているサイトの典型的な例として、メインスクリプトファイル内でサービスワーカーを登録します。
// main.mjs
navigator.serviceWorker.register('/sw.js');
そして、サービスワーカーはインストール(キャッシュを作成)やフェッチ(リソースを提供し、必要に応じてキャッシュから提供)のためのイベントハンドラを追加します。
// sw.js
self.addEventListener('install', (event) => {
async function buildCache() {
const cache = await caches.open(cacheName);
return cache.addAll([
'/main.css',
'/main.mjs',
'/offline.html',
]);
}
event.waitUntil(buildCache());
});
self.addEventListener('fetch', (event) => {
async function cachedFetch(event) {
const cache = await caches.open(cacheName);
let response = await cache.match(event.request);
if (response) return response;
response = await fetch(event.request);
cache.put(event.request, response.clone());
return response;
}
event.respondWith(cachedFetch(event));
});
これらのキャッシュには、キャッシュされたJSリソースを含めることができます。ただし、これらの場合には異なる前提を行えるため、少し異なるヒューリスティックが適用されます。サービスワーカーキャッシュはクォータ管理ストレージルールに従うため、より長期間保持される可能性があり、キャッシュの利点がより大きくなります。加えて、事前にキャッシュされたリソースはロード前に追加の重要性を推測することができます。
リソースがサービスワーカーのインストールイベント中にサービスワーカーキャッシュに追加されたとき、最も大きなヒューリスティックの違いが発生します。上記の例はそのようなユースケースを示しています。この場合、リソースがサービスワーカーキャッシュに追加された時点でコードキャッシュが即座に作成されます。さらに、これらのスクリプトに対して「フル」コードキャッシュを生成します。つまり、関数を遅延コンパイルするのではなく、すべてを事前にコンパイルしてキャッシュに格納します。これによりメモリ使用量が増加する代わりに、高速で予測可能なパフォーマンスを提供し、実行順序の依存関係がなくなります。
JSリソースがサービスワーカーのインストールイベント外でCache APIを介して保存される場合、コードキャッシュはすぐには生成されません。代わりに、サービスワーカーがそのキャッシュからレスポンスを返す場合、「通常の」コードキャッシュは最初の読み込み時に生成されます。このコードキャッシュは、次回の読み込み時に使用可能となり、通常のコードキャッシュシナリオよりも1回分読み込みが高速化されます。リソースは、fetchイベントでリソースを段階的にキャッシュする場合や、Cache APIがサービスワーカーではなくメインウィンドウから更新された場合など、インストールイベント外で保存されることがあります。
なお、事前キャッシュされた「フル」コードキャッシュは、スクリプトが実行されるページがUTF-8エンコーディングを使用することを前提としています。ページが異なるエンコーディングを使用する場合、コードキャッシュは破棄され、「通常の」コードキャッシュに置き換えられます。
加えて、事前キャッシュされた「フル」コードキャッシュは、ページがスクリプトをクラシックJSスクリプトとして読み込むことを前提としています。ページがこれをESモジュールとして読み込む場合も、コードキャッシュは破棄され、「通常の」コードキャッシュに置き換えられます。
トレース
上述のどの提案も、Webアプリの速度を必ずしも向上させるものではありません。残念ながら、コードキャッシュ情報は現在DevToolsで公開されていないため、Webアプリのスクリプトがどれだけコードキャッシュを使用しているかを確認する最も確実な方法は、やや低レベルなchrome://tracingを使用することです。
chrome://tracingは、一定期間におけるChromeの動作を記録し、結果のトレース可視化は次のようになります:
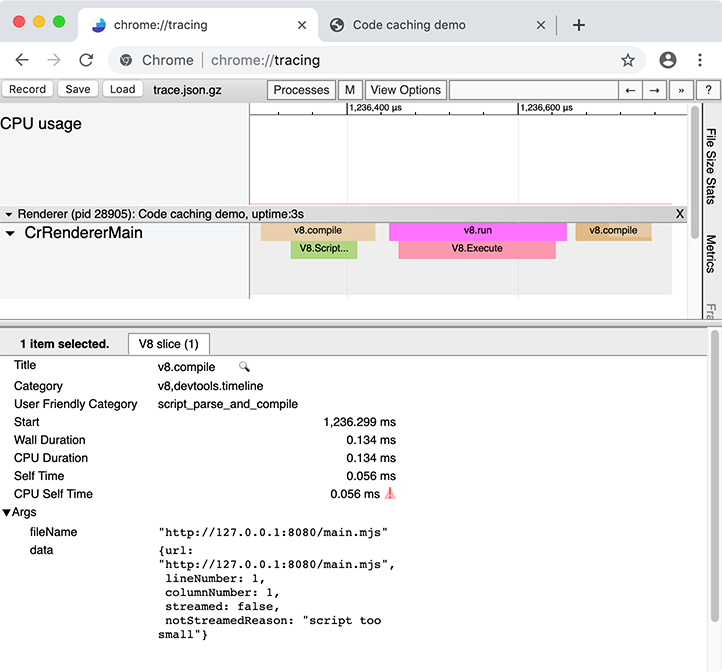
トレースは、他のタブやウィンドウ、拡張機能を含むブラウザ全体の動作を記録するため、クリーンなユーザープロファイルで拡張機能を無効にし、他のブラウザタブを閉じた状態で実施するのが最適です。
# クリーンなユーザープロファイルと拡張機能を無効化した新しいChromeブラウザセッションを開始
google-chrome --user-data-dir="$(mktemp -d)" --disable-extensions
トレースを収集する際、追跡するカテゴリを選択する必要があります。ほとんどの場合、「Web developer」のカテゴリセットを選択すればよいのですが、カテゴリを手動で選択することも可能です。コードキャッシュにとって重要なカテゴリはv8です。
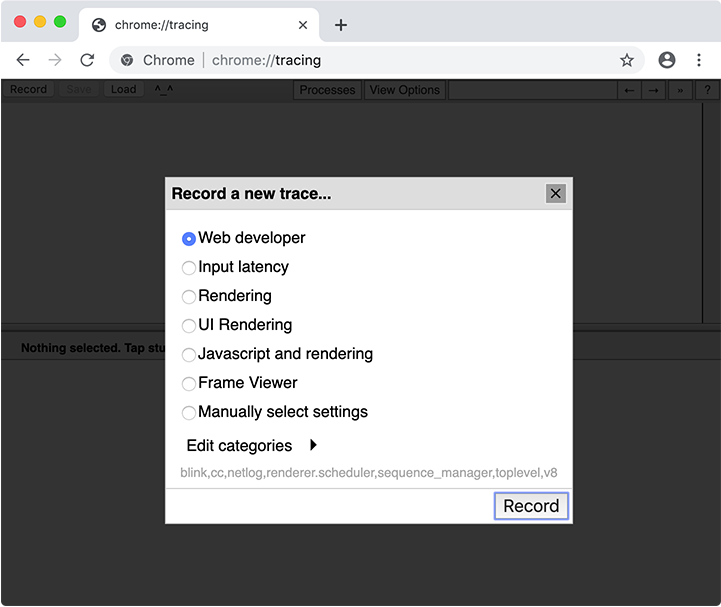
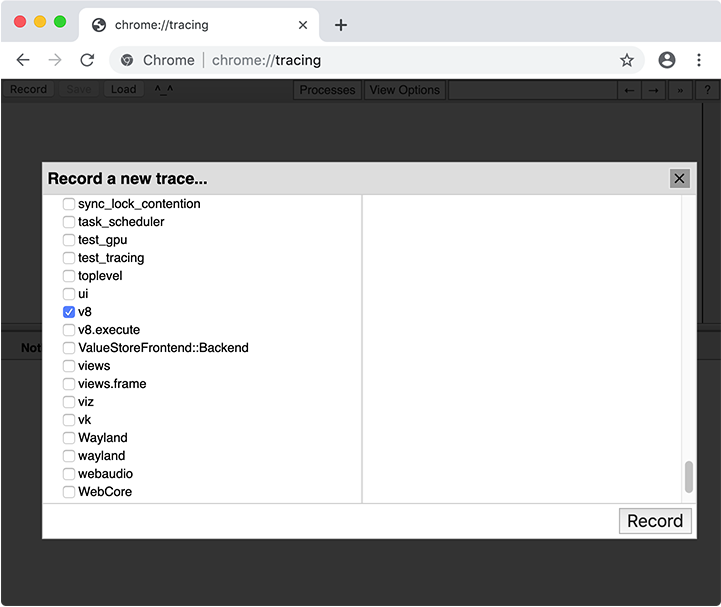
v8カテゴリでトレースを記録した後、トレース内でv8.compileスライスを探します。(または、トレースUIの検索ボックスにv8.compileと入力することも可能です。)これには、コンパイルされるファイルと、いくつかのコンパイルに関するメタデータが表示されます。
スクリプトのコールド実行時には、コードキャッシュに関する情報は表示されません。これは、そのスクリプトがキャッシュデータの生成や消費に関与していないことを意味します。
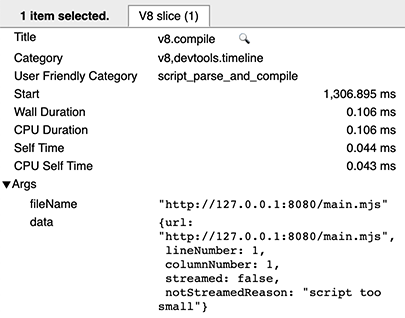
ウォーム実行時には、スクリプトごとに2つのv8.compileエントリがあります。1つは実際のコンパイルのため、もう1つ(実行後)はキャッシュを生成するためです。後者は、cacheProduceOptionsおよびproducedCacheSizeメタデータフィールドを持つことで識別できます。
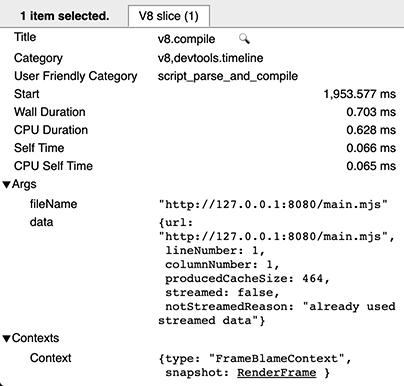
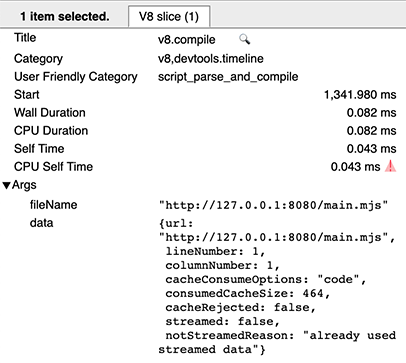
ホット実行時には、キャッシュを消費するためのv8.compileエントリが表示され、cacheConsumeOptionsおよびconsumedCacheSizeメタデータフィールドを持ちます。サイズはすべてバイト単位で表されます。
結論
ほとんどの開発者にとって、コードキャッシュは「そのまま機能する」べきものです。キャッシュが最も効果的に機能するのは、他のキャッシュと同様に、状況が変わらないときであり、バージョン間で変更されるヒューリスティックを利用します。それにもかかわらず、コードキャッシュには利用できる挙動があり、回避できる制限があり、chrome://tracingを使用した慎重な分析によって、Webアプリのキャッシュ使用を調整および最適化することができます。