スプレッド要素の高速化
Hai DangはV8チームでの3か月間のインターンシップ中に、[...array], [...string], [...set], [...map.keys()], および [...map.values()](配列リテラルの最初にスプレッド要素がある場合)のパフォーマンスを改善しました。さらに、Array.from(iterable) の速度も大幅に向上させました。この記事では、彼の変更の詳細について説明します。これらの変更はv7.2以降のV8に含まれています。
スプレッド要素
スプレッド要素は、...iterable という形式の配列リテラルの構成要素です。これらはES2015で導入され、イテラブルオブジェクトから配列を作成する方法として使用されます。例えば、配列リテラル [1, ...arr, 4, ...b] は、最初の要素が 1 で、その後に配列 arr の要素、次に 4、最後に配列 b の要素で構成される配列を作成します。
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
別の例として、任意の文字列はスプレッドされることでその文字(Unicodeコードポイント)の配列を作成できます。
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
同様に、任意のセットは挿入順序でソートされたその要素の配列を作成するためにスプレッドできます。
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
一般に、配列リテラル内でのスプレッド要素の構文 ...x は、x がイテレーターを提供することを期待しています(x[Symbol.iterator]() を通じてアクセス可能です)。このイテレーターを使用して、結果の配列に挿入される要素を取得します。
[...arr] のように配列 arr を新しい配列にスプレッドし、前後にさらに要素を追加しない単純な利用ケースは、ES2015における arr を浅く複製する簡潔かつ慣用的な方法とみなされています。残念ながら、V8ではこの方法のパフォーマンスがES5相当の方法と比べて大幅に遅れていました。Haiのインターンシップの目標はこれを改善することでした。
スプレッド要素が遅い理由(または遅かった理由)
配列 arr を浅く複製する方法は多くあります。例えば、arr.slice() を使用したり、arr.concat() を使用したり、[...arr] を使用したりできます。また、標準的な for ループを使う clone 関数を書くこともできます。
function clone(arr) {
// 正しい数の要素を事前に確保して、配列を拡張する必要がないようにします。
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
理想的には、これらのオプションはすべて同じようなパフォーマンス特性を持つべきです。残念ながら、V8で [...arr] を選択すると、clone よりも遅くなる可能性が高いです!その理由は、V8が [...arr] を以下のようなイテレーションに基本的にトランスパイルするからです。
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
このコードは以下のいくつかの理由で clone よりも一般的に遅くなります。
- 最初に
Symbol.iteratorプロパティをロードして評価することでiteratorを作成する必要があります。 - 各ステップで
iteratorResultオブジェクトを作成して問い合わせる必要があります。 pushを呼び出すことでイテレーションの各ステップでresult配列を拡張し、そのためにバックストアを繰り返し再割り当てします。
そのような実装を使用する理由は、前述したように、スプレッドは配列だけでなく、実際には任意の イテラブル オブジェクトに対して行うことができ、イテレーションプロトコル に従う必要があるからです。それにもかかわらず、V8はスプレッドされているオブジェクトが配列であることを認識できるほど賢くなるべきです。その場合、低レベルでの要素抽出を実行し、次のようにする必要があります。
- イテレーターオブジェクトの作成を回避する。
- イテレーター結果オブジェクトの作成を回避する。
- 結果の配列を継続的に拡張して再割り当てするのを回避する(事前に要素数がわかっています)。
この単純なアイデアを、高速 配列、つまり6つの最も一般的な エレメントの種類 のいずれかを持つ配列に対して CSA を使用して実装しました。この最適化は、配列リテラルの最初にスプレッドが発生する 一般的な実世界のシナリオ に適用されます。例えば、[...foo] のようです。以下のグラフに示されているように、この新しい高速パスは長さ100,000の配列をスプレッドする場合、約3倍のパフォーマンス改善をもたらし、手書きの clone ループより約25%高速になります。
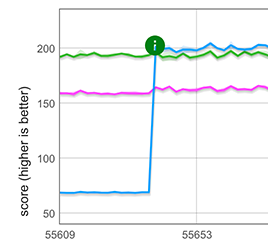
メモ: ここでは示されていませんが、高速パスは展開要素の後に他の要素(例: [...arr, 1, 2, 3])が続く場合にも適用されます。ただし、展開要素の前に他の要素(例: [1, 2, 3, ...arr])がある場合には適用されません。
高速パスを慎重に利用する
これは明らかに印象的な速度向上ですが、この高速パスを利用するのが適切な場合には非常に慎重でなければなりません。JavaScriptでは、プログラマーがオブジェクト(配列も含む)のイテレーション動作をさまざまな方法で変更することができます。展開要素はイテレーションプロトコルを使用するように仕様で定められているため、そのような変更が尊重されるようにする必要があります。元のイテレーション機構が変更された場合は、高速パスを完全に回避することでこれを実現しています。例えば、次のような状況が含まれます。
独自のSymbol.iteratorプロパティ
通常、配列arrには独自のSymbol.iteratorプロパティはありません。そのシンボルを参照すると、配列のプロトタイプ上で見つかります。以下の例では、Symbol.iteratorプロパティをarr自身の上に直接定義することで、プロトタイプをバイパスしています。この変更後、arr上でSymbol.iteratorを参照すると空のイテレーターが得られるため、arrの展開は要素なしとなり、配列リテラルは空の配列になります。
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
修正された%ArrayIteratorPrototype%
nextメソッドは、配列イテレーターのプロトタイプ(全ての配列に影響する)である%ArrayIteratorPrototype%上にも直接修正することができます。
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
不規則な配列に対処する
不規則(holey)な配列、つまり['a', , 'c']のようにいくつかの要素が欠けている配列をコピーする場合にも追加の注意が必要です。そのような配列を展開すると、イテレーションプロトコルに従うため、欠けている部分が保持されるのではなく、配列プロトタイプに存在する対応するインデックスの値で埋められます。デフォルトでは、配列プロトタイプには要素が存在しないため、欠けている部分はundefinedで埋められます。例えば、[...['a', , 'c']]は新しい配列['a', undefined, 'c']に評価されます。
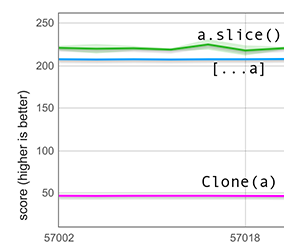
高速パスはこのデフォルトの状況での欠けを処理するほど賢明です。入力配列のバックストアを無造作にコピーする代わりに、欠けている部分を見分け、それらをundefinedの値に適切に変換します。以下のグラフは、長さ100,000の入力配列(タグ付き600個の整数—残りは欠けている部分)を対象に測定したものです。このグラフは、そのような不規則な配列を展開する方がclone関数を使用するより4倍以上速いことを示しています。(以前はほぼ同等でしたが、このグラフには表示されていません。)
なお、sliceもこのグラフに含まれていますが、不規則な配列に対するsliceのセマンティクスが異なるため比較は不公平です:sliceは全ての欠けを保持するため、する仕事がはるかに少ないのです。
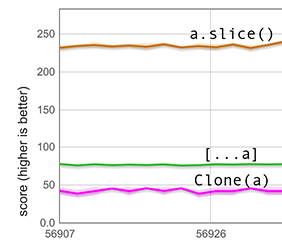
欠け部分をundefinedで埋める処理は、一見単純そうに見えますが、実際には配列全体を異なる要素種別に変換する必要がある場合もあります。次のグラフはそのような状況を測定しています。設定は先ほどと同じですが、この場合600個の配列要素はアンボックス化された浮動小数点数であり、配列はHOLEY_DOUBLE_ELEMENTS型の要素種別を持っています。この要素種別はundefinedのようなタグ付き値を保持できないため、展開はコストのかかる要素種別の遷移を伴います。そのため、[...a]のスコアは前のグラフよりも大幅に低くなっています。それでもなお、clone(a)よりはるかに速いです。
文字列、Set、Mapの展開
イテレーターオブジェクトをスキップし、結果配列の拡張を回避するという考え方は、他の標準データ型を展開する場合にも同様に適用されます。実際、プリミティブ文字列、Set、Mapに対しても類似の高速パスを実装しました。その都度、変更されたイテレーション動作がある場合にはバイパスするよう注意を払っています。
Setに関しては、高速パスはSetを直接展開するだけでなく([...set])、Setのキーイテレーター([...set.keys()])や値イテレーター([...set.values()])を展開することもサポートしています。マイクロベンチマークでは、これらの操作が以前より約18倍高速になりました。
地図の速いパスは似ていますが、地図を直接展開する([...map])ことはサポートしていません。これは珍しい操作と考えているためです。同じ理由で、どちらの速いパスもentries()イテレータをサポートしていません。我々のマイクロベンチマークでは、これらの操作は以前より約14倍高速化されています。
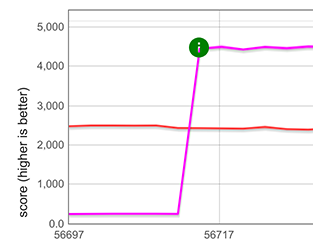
文字列の展開([...string])に関しては、約5倍の改善が測定されました。下のグラフで紫と緑の線で示されています。これは、TurboFanで最適化されたfor-ofループ(TurboFanは文字列の反復を理解し、それに対して最適化されたコードを生成できます)よりも高速です。青とピンクの線で表されています。各ケースにプロットが2つある理由は、マイクロベンチマークが2つの異なる文字列表現(一バイト文字列と二バイト文字列)で動作しているからです。
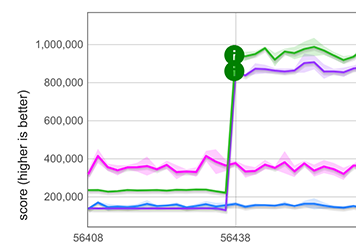
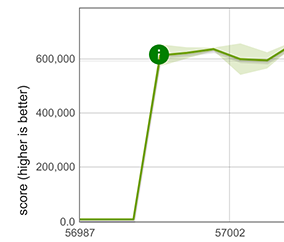
Array.fromの性能向上
幸いなことに、展開要素の速いパスは、Array.fromにも利用することができます。例えばArray.from([1, 2, 3])のように、Array.fromがイテラブルオブジェクトで呼び出され、マッピング関数が指定されていない場合です。この場合、Array.fromの動作は展開と完全に同じであるため、速いパスを再利用することが可能です。これにより、巨大な性能向上が得られます。以下のグラフは、100個の倍精度数値を含む配列の場合の性能向上を示しています。
結論
V8 v7.2 / Chrome 72は、配列リテラルの先頭で発生する展開要素(例えば[...x]や[...x, 1, 2])の性能を大幅に改善しました。この改善は配列、プリミティブ文字列、セット、地図のキー、地図の値の展開、そして拡張して言えばArray.from(x)に適用されます。