埋め込み組み込み機能
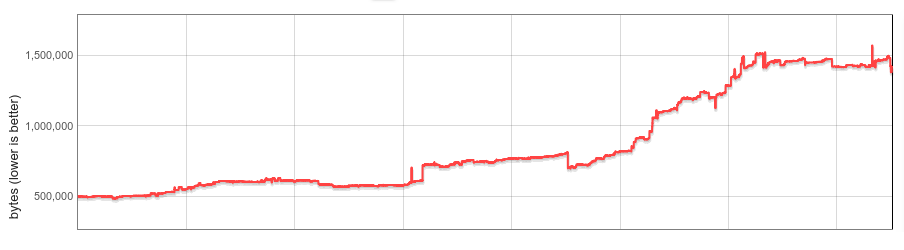
V8の組み込み関数(組み込み機能)は、V8のすべてのインスタンスでメモリを消費します。組み込み機能の数、平均サイズ、およびChromeブラウザータブごとのV8インスタンス数は大幅に増加しています。本ブログ記事では、過去1年間でウェブサイトごとのV8ヒープサイズの中央値を19%削減した方法について説明します。
背景
V8には、豊富なJavaScript(JS)の組み込み関数ライブラリが付属しています。多くの組み込み機能は、RegExp.prototype.execやArray.prototype.sortのように、JS組み込みオブジェクトにインストールされた関数として直接JS開発者に公開されています。他の組み込み機能はさまざまな内部機能を実現します。組み込み機能の機械コードはV8独自のコンパイラによって生成され、初期化時にV8のIsolateごとに管理ヒープ状態にロードされます。IsolateはV8エンジンの隔離されたインスタンスを表し、Chromeの各ブラウザタブには少なくとも1つのIsolateが含まれます。各Isolateには独自の管理ヒープがあり、すべての組み込み機能の独自コピーがあります。
2015年の時点では、組み込み機能のほとんどは自己ホスト型JS、ネイティブアセンブリ、またはC++で実装されていました。それらは比較的小さく、各Isolateにコピーを作成することはそれほど問題ではありませんでした。
しかし、この分野では過去数年間で多くの変化がありました。
2016年にV8は、CodeStubAssembler(CSA)で実装された組み込み機能の試験運用を開始しました。これにより、プラットフォームに依存せず読みやすい便利なコードが生成されることが判明し、CSAの組み込み機能が普及しました。さまざまな理由により、CSAの組み込み機能は大きなコードを生成する傾向があり、多くの機能がCSAに移行されるにつれて、V8の組み込み機能のサイズは概ね3倍になりました。2017年半ばまでに、各Isolateのオーバーヘッドが大幅に増加し、体系的な解決策を考え始めました。
2017年後半には、遅延組み込み機能(およびバイトコードハンドラー)のデシリアライズを初めて実装しました。初期分析では、ほとんどのサイトがすべての組み込み機能の半分未満しか使用していないことが示されました。遅延デシリアライズでは、組み込み機能がオンデマンドでロードされ、未使用の組み込み機能はIsolateにロードされることはありません。遅延デシリアライズはChrome 64で有望なメモリ節約とともに出荷されました。しかし、組み込み機能のメモリオーバーヘッドは依然としてIsolateの数に比例していました。
その後、Spectreが公開され、その影響を軽減するためにChromeは最終的にサイトアイソレーションを有効にしました。サイトアイソレーションでは、Chromeレンダラープロセスを単一のオリジンのドキュメントに制限します。したがって、サイトアイソレーションでは、多くのブラウジングタブがより多くのレンダラープロセスとV8のIsolateを作成します。各Isolateのオーバーヘッドを管理することは常に重要でしたが、サイトアイソレーションによってさらに重要になりました。
埋め込み組み込み機能
このプロジェクトの目標は、Isolateごとの組み込み機能オーバーヘッドを完全に排除することでした。
その背後にあるアイデアはシンプルです。概念的には、組み込み機能はIsolate間で同一であり、実装上の詳細によりIsolateに結び付けられているだけです。もし組み込み機能を真にIsolate非依存にすることができれば、メモリ内に単一コピーを保持し、すべてのIsolate間で共有できるようになります。そしてそれらがプロセス非依存であるならば、プロセス間でも共有可能です。
実際にはいくつかの課題に直面しました。生成された組み込みコードは、Isolateやプロセス固有のデータへの埋め込みポインタのために、Isolate-またはプロセス非依存ではありませんでした。V8は管理ヒープ外に配置された生成コードを実行する概念を持っていませんでした。組み込み機能は既存のOSメカニズムを再利用することでプロセス間で共有される必要がありました。そして最後に(これは最終的に長期的な課題であることが判明しました)、性能がわずかでも目立って低下することはあってはなりません。
以下のセクションでは、私たちの解決策を詳細に説明します。
Isolate-およびプロセス非依存コード
組み込み機能はV8のコンパイラ内部パイプラインによって生成されますが、これにはヒープ定数(Isolateの管理ヒープ上に配置)、呼び出しターゲット(Codeオブジェクト、同様に管理ヒープ上)、およびIsolateやプロセス固有のアドレス(例: Cランタイム関数またはIsolateへのポインタ、'外部参照'とも呼ばれる)への参照をコードに直接埋め込んでいます。x64アセンブリでは、これらのオブジェクトのロードは次のように見える場合があります:
// 埋め込まれたアドレスをレジスタrbxにロードする。
REX.W movq rbx,0x56526afd0f70
V8には動的ガーベッジコレクタがあり、対象オブジェクトの位置が時間の経過とともに変わる可能性があります。収集中に対象オブジェクトが移動された場合、GCは生成されたコードを更新して新しい位置を指すようにします。
x64(および他のほとんどのアーキテクチャ)では、他のCodeオブジェクトへの呼び出しは効率的な呼び出し命令を使用しており、この命令は現在のプログラムカウンターからのオフセットによって呼び出しターゲットを指定します(興味深い詳細として、V8は起動時にマネージドヒープ上の全CODE_SPACEを予約し、すべての可能なコードオブジェクトが互いにアドレス可能なオフセット内に収まるようにしています)。呼び出しシーケンスの関連部分は以下の通りです。
// 呼び出し命令は[pc + <オフセット>]に配置されています。
call <offset>
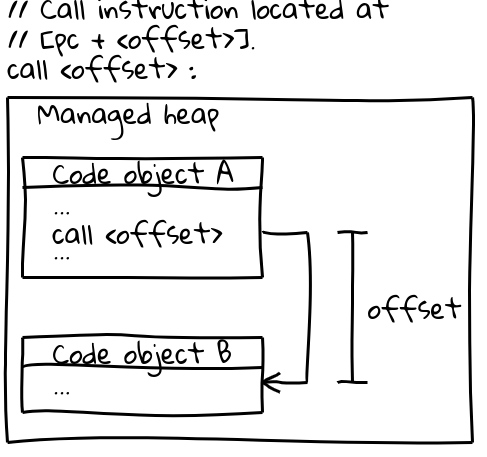
コードオブジェクト自体はマネージドヒープ上に存在しており、移動可能です。それらが移動されると、GCはすべての関連する呼び出し箇所でオフセットを更新します。
生成されたコードをプロセス間で共有するためには、コードを不変かつアイソレートとプロセスに依存しないものにする必要があります。上記のどちらの命令シーケンスもその要件を満たしていません。これらはコード内にアドレスを直接埋め込み、GCによって実行時に修正されます。
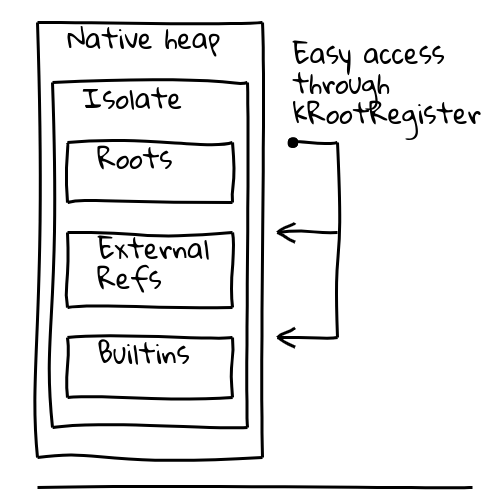
これらの問題に対処するため、現在のアイソレート内の既知の場所へのポインターを保持する専用の「ルート登録」と呼ばれる間接参照を導入しました。
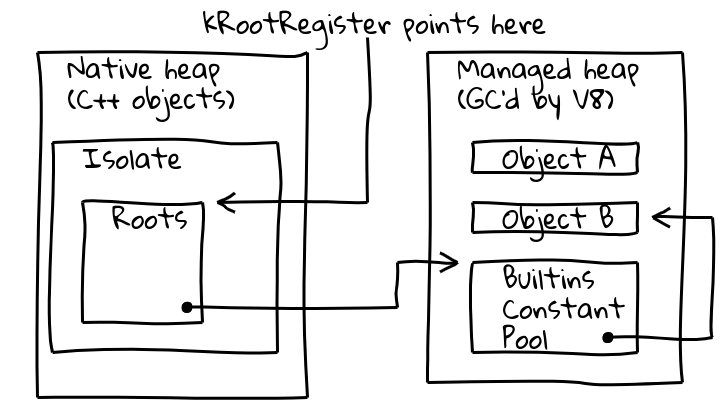
V8のIsolateクラスにはルートテーブルが含まれており、これにはマネージドヒープ上のルートオブジェクトへのポインターが格納されています。ルート登録はルートテーブルのアドレスを永久的に保持します。
したがって、ルートオブジェクトを読み込む新しい方法は、アイソレートおよびプロセスに依存しない次のような方法になります。
// 定数アドレスをルートから与えられたオフセットで読み込む。
REX.W movq rax,[kRootRegister + <offset>]
ルートヒープ定数は上記で示したようにルートリストから直接読み込むことができます。その他のヒープ定数は、ルートリストに格納されているグローバルビルトイン定数プールを介してさらに間接参照します。
// ビルトイン定数プールを読み込み、それから必要な定数を読み込む。
REX.W movq rax,[kRootRegister + <offset>]
REX.W movq rax,[rax + 0x1d7]
Codeターゲットの場合、最初は上記のようにグローバルビルトイン定数プールからターゲットCodeオブジェクトをロードし、ターゲットアドレスをレジスタにロードして間接的に呼び出すというより複雑な呼び出しシーケンスに切り替えました。
これらの変更により、生成されたコードはアイソレートおよびプロセスに依存しなくなり、プロセス間で共有する作業を開始することができました。
プロセス間の共有
最初に2つの代替案を評価しました。ビルトインをデータブロブファイルをメモリにmmapすることで共有するか、バイナリに直接埋め込むかです。後者の方法を選択しました。このアプローチでは、OS標準のメモリ共有メカニズムを自動的に再利用できるという利点があり、ChromeのようなV8埋め込む側の追加ロジックが必要ないからです。このアプローチに自信を持っていた理由として、DartのAOTコンパイルがすでに生成されたコードのバイナリ埋め込みに成功していたことがあります。
実行可能バイナリファイルはいくつかのセクションに分割されています。例えば、ELFバイナリにはデータが.data(初期化済みデータ)、.ro_data(初期化済み読み取り専用データ)、および.bss(未初期化データ)セクションに含まれています。一方、ネイティブ実行コードは.textに配置されます。我々の目標は、ビルトインコードをネイティブコードと一緒に.textセクションに詰め込むことでした。
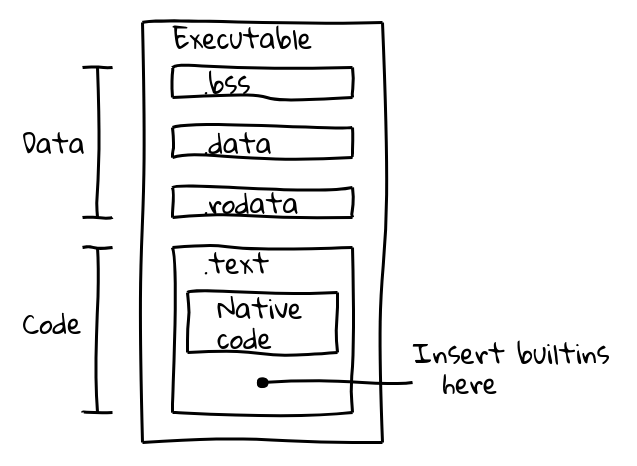
これを実現するために、新しいビルドステップを導入しました。これにより、V8の内部コンパイラパイプラインを使用してすべてのビルトインのネイティブコードを生成し、その内容をembedded.ccに出力します。このファイルは最終的なV8バイナリにコンパイルされます。
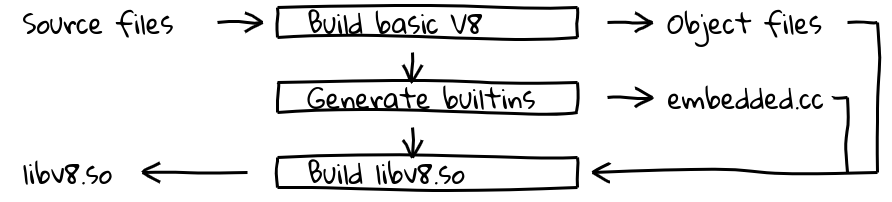
embedded.ccファイル自体には、メタデータと生成されたビルトインマシンコードが含まれており、これはC++コンパイラ(この場合はclangまたはgcc)に指定されたバイトシーケンスを直接出力オブジェクトファイル(後には実行可能ファイル)に配置するよう指示する.byteディレクティブの一連として記述されています。
// 埋め込まれたビルトインの情報はメタデータテーブルに含まれています。
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[メタデータ省略]
// 続いて生成されたマシンコード。
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[ビルトインコード省略]
.textセクションの内容はランタイム時に読み取り専用の実行可能メモリにマッピングされ、配置可能なシンボルを含まない位置非依存コードのみが含まれていれば、OSはプロセス間でメモリを共有します。これはまさに我々が望んでいたものです。
しかし、V8のCodeオブジェクトは命令ストリームだけで構成されているわけではなく、さまざまな(時にはアイソレート依存の)メタデータも含んでいます。通常の一般的なCodeオブジェクトは、メタデータと命令ストリームを可変サイズのCodeオブジェクトにまとめ、管理ヒープ上に配置します。
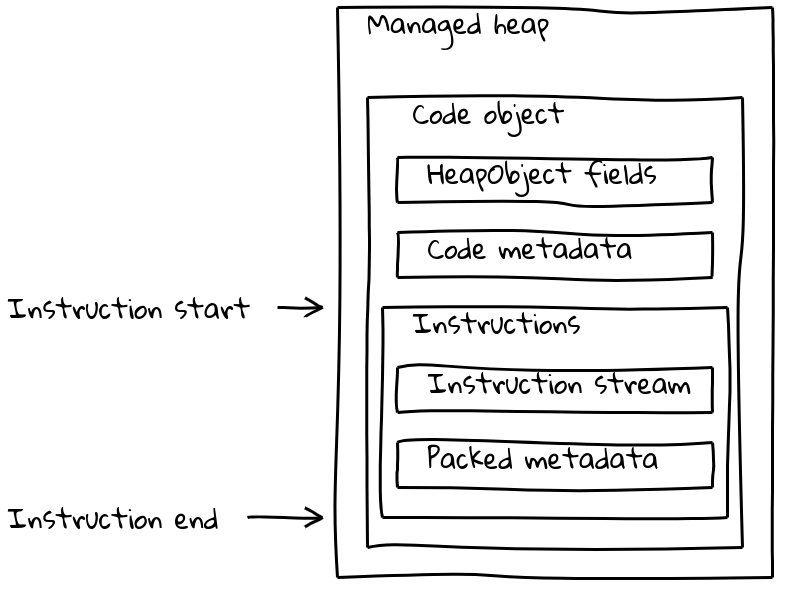
既に見たように、埋め込まれたビルトインはネイティブ命令ストリームを管理ヒープ外に配置し、.textセクションに組み込んでいます。メタデータを保持するために、埋め込まれた各ビルトインには管理ヒープ上に小さな関連付けられたCodeオブジェクト(_オフヒープトランポリン_と呼ばれる)が存在します。標準のCodeオブジェクトと同様にトランポリン上にメタデータが格納され、インライン命令ストリームには埋め込まれた命令のアドレスを読み取り、それにジャンプする短いシーケンスが含まれています。
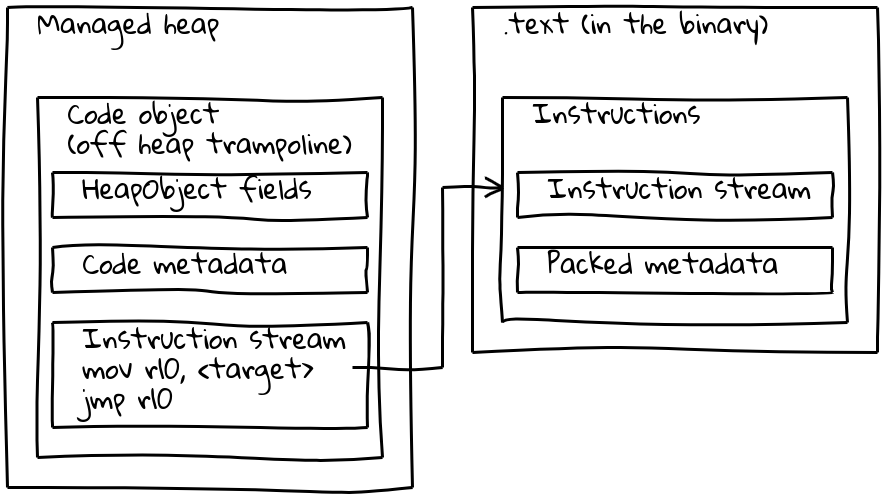
トランポリンにより、V8はすべてのCodeオブジェクトを統一的に扱うことが可能です。ほとんどの場合、与えられたCodeオブジェクトが管理ヒープ上の標準コードを参照しているのか、埋め込まれたビルトインを参照しているのかは関係ありません。
パフォーマンス向上のための最適化
前節で説明した解決策により、埋め込まれたビルトインは本質的に機能が完成していましたが、ベンチマークから大幅な遅延が確認されました。例えば、初期の解決策ではSpeedometer 2.0のパフォーマンスが全体で5%以上悪化しました。
我々は最適化の機会を探し、遅延の主要な原因を特定しました。生成されたコードが遅い理由は、アイソレートやプロセス依存のオブジェクトへのアクセスに頻繁な間接的操作が必要だったためです。ルート定数はルートリストからロードされ(1回の間接参照)、他のヒープ定数はグローバルビルトイン定数プールからロードされ(2回の間接参照)、外部参照もヒープオブジェクト内から展開する必要がありました(3回の間接参照)。最悪だったのは新しい呼び出しシーケンスで、トランポリンコードオブジェクトをロードし、それを呼び出してからターゲットアドレスにジャンプする必要がありました。さらに、管理ヒープとバイナリ埋め込みコード間の呼び出しは、CPUの分岐予測を妨げる可能性がある長いジャンプ距離のため、根本的に遅いようでした。
したがって我々の作業は、1. 間接参照の削減、2. ビルトイン呼び出しシーケンスの改善に集中しました。第1の課題に対応するため、アイソレートオブジェクトのレイアウトを変更し、ほとんどのオブジェクトロードを単一ルート相対ロードにしました。グローバルビルトイン定数プールはまだ存在しますが、頻繁にアクセスされないオブジェクトだけを含むようになりました。
呼び出しシーケンスは二方面で大幅に改善されました。ビルトイン間の呼び出しは単一のPC相対呼び出し命令に変換されました。PC相対オフセットが最大32ビット値を超える可能性があるため、ランタイム生成のJITコードではこれは不可能でした。その場合、オフヒープトランポリンをすべての呼び出しサイトにインライン化し、呼び出しシーケンスを6命令からわずか2命令に削減しました。
これらの最適化により、Speedometer 2.0でのレグレッションを約0.5%に抑えることができました。
結果
x64上で埋め込まれたビルトインの影響を上位10,000の人気ウェブサイトに対して評価し、怠惰デシリアライズおよび積極デシリアライズとの比較を行いました(上記で説明されています)。
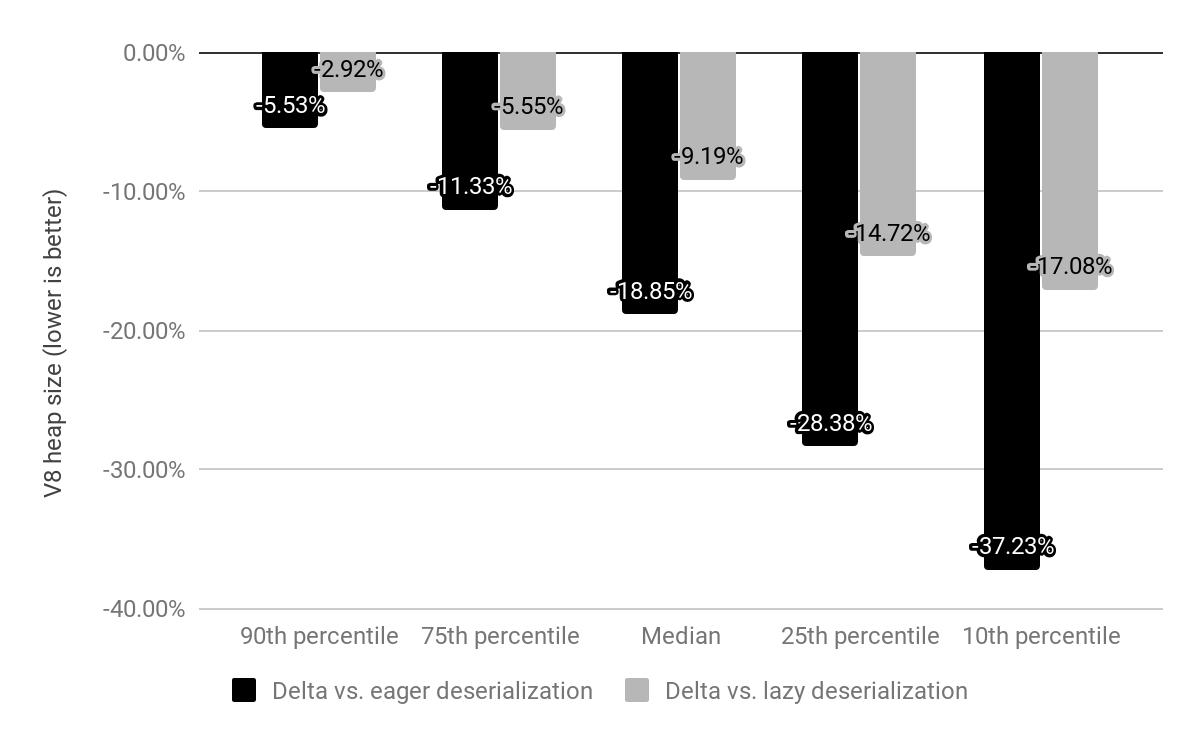
以前は、Chromeはアイソレートごとにデシリアライズされるメモリマップされたスナップショットを提供していましたが、現在ではスナップショットが埋め込まれたビルトインに置き換えられました。これらは依然としてメモリマップされていますが、デシリアライズが必要ありませんでした。ビルトインにかかるコストは、以前はc*(1 + n)(ここでnはアイソレートの数、cはすべてのビルトインのメモリコスト)でしたが、現在では単にc * 1(実際には小さいオフヒープトランポリン用のアイソレートごとのオーバーヘッドも残っています)だけです。
積極デシリアライズと比較して、中央値でV8ヒープサイズを19%削減しました。サイトごとのChromeレンダラープロセスサイズの中央値は4%減少しました。絶対値では、50番目のパーセンタイルでは1.9MBを節約し、30番目のパーセンタイルでは3.4MBを節約し、10番目のパーセンタイルではサイトごとに6.5MBを節約しました。
バイトコードハンドラーもバイナリ埋め込みされた場合、さらに大幅なメモリ削減が期待されています。
埋め込まれたビルトインはChrome 69でx64において展開され、モバイルプラットフォームはChrome 70で続く予定です。ia32のサポートは2018年末にリリースされる見込みです。
備考: すべての図は、Vyacheslav Egorovの素晴らしいShaky Diagrammingツールを使用して生成されました。