怠惰に関するインターンシップ:非最適化された関数の怠惰な解除
約3か月前、私はインターンとしてV8チーム(Googleミュンヘン)に参加し、それ以来VMの_Deoptimizer_に取り組んできました。このプロジェクトは完全に新しいものであり、興味深く挑戦的なものでした。インターンシップの最初の部分ではVMのセキュリティ面の改善に焦点を当てました。そして2つ目の部分ではパフォーマンス改善、具体的には非最適化された関数の解除に使われるデータ構造の削除に取り組みました。このデータ構造はガベージコレクション中にパフォーマンスボトルネックとなっていました。このブログ投稿ではこのインターンシップの2番目の部分について説明します。V8が以前どのように非最適化された関数を解除していたか、どのように変更したか、そしてどのようなパフォーマンス改善が得られたかを説明します。
JavaScript関数に対するV8パイプラインを簡単に(非常に簡単に)振り返ってみましょう:V8のインタプリタであるIgnitionはその関数についてのプロファイリング情報を収集しながら解析します。その関数がホットになると、この情報はV8コンパイラであるTurboFanに渡され、最適化された機械コードが生成されます。プロファイリング情報が有効でなくなった場合—例えば、プロファイリング対象のオブジェクトがランタイム中に異なる型になる場合—最適化された機械コードが無効になります。その場合、V8はコードを非最適化する必要があります。
最適化の際にTurboFanはコードオブジェクト、つまり最適化された機械コードをその関数のために生成します。その関数が次回呼び出されるとき、V8はその関数の最適化コードへのリンクをたどり、それを実行します。その関数が非最適化されるとき、コードオブジェクトを解除して再度実行されることがないようにする必要があります。それはどのように行われるのでしょうか?
例えば、以下のコードでは、関数f1が何度も呼び出される(常に引数として整数を渡す)。そのケースのためにTurboFanは機械コードを生成します。
function g() {
return (i) => i;
}
// クロージャを作成。
const f1 = g();
// f1を最適化。
for (var i = 0; i < 1000; i++) f1(0);
各関数にもインタプリタへのトランポリンがあります—さらに詳しい内容はこちらのスライドをご覧ください—そしてそのトランポリンへのポインタをその関数のSharedFunctionInfo(SFI)に保持します。このトランポリンはV8が非最適化コードに戻る必要があるときに使われます。したがって、例えば異なる型の引数を渡すことでトリガーされる非最適化時には、Deoptimizerは単にJavaScript関数のコードフィールドをこのトランポリンに設定することができます。
これが簡単に見えるにもかかわらず、V8が最適化されたJavaScript関数の弱いリストを保持する必要があります。その理由は、同じ最適化コードオブジェクトを指す異なる関数が存在する可能性があるからです。例を以下のように拡張でき、関数f1とf2が同じ最適化コードを指します。
const f2 = g();
f2(0);
関数f1が非最適化される(例えば異なる型のオブジェクト{x: 0}で呼び出されることで)の場合、無効化されたコードが関数f2を呼び出すことで再度実行されないことを確認する必要があります。
したがって、非最適化時に、V8はすべての最適化されたJavaScript関数を反復処理し、非最適化されるコードオブジェクトを指しているものを解除していました。これは、多くの最適化されたJavaScript関数を含むアプリケーションにおいてパフォーマンスのボトルネックになりました。さらに、非最適化を遅くするだけでなく、V8はガベージコレクションのストップ・ザ・ワールドサイクルの際にこれらのリストを反復処理しており、さらに状況を悪化させていました。
V8のパフォーマンスにおけるこのデータ構造の影響を把握するために、多くのJavaScript関数を作成した後に多くのスカベンジサイクルをトリガーしてその使用を強調するマイクロベンチマークを書きました。
function g() {
return (i) => i + 1;
}
// 最初のクロージャを作成して最適化。
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// 200万個のクロージャを作成します; これらは以前に最適化されたコードを取得します。
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// 次にスカベンジを引き起こします; すべてが遅いです。
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
このベンチマークを実行すると、V8が実行時間の約98%をガベージコレクションに費やしたことが観察されました。その後、このデータ構造を削除し、代わりに遅延的アンリンク方法を使用したところ、x64で以下の結果を観察しました:

これは多くのJavaScript関数を作成し、多くのガベージコレクションサイクルをトリガーするマイクロベンチマークに過ぎませんが、このデータ構造によって導入されたオーバーヘッドのアイデアを得ることができます。オーバーヘッドが確認された現実的なアプリケーションには、Node.jsで実装されたrouter benchmarkやARES-6 benchmark suiteがあります。
遅延的アンリンク
最適化されたコードをJavaScript関数から非最適化時にアンリンクする代わりに、V8はそのような関数の次の呼び出し時にそれを延期します。これらの関数が呼び出された場合、V8はそれらが非最適化されているかを確認し、それをアンリンクしてから遅延コンパイルを続行します。これらの関数が再び呼び出されることがない場合、それらはアンリンクされず、非最適化されたコードオブジェクトは収集されません。ただし、非最適化時にはコードオブジェクトの埋め込まれたすべてのフィールドが無効化されるため、そのコードオブジェクトだけが生き残ります。
最適化されたJavaScript関数のリストを削除したコミットは、VMのいくつかの部分に変更を必要としましたが、基本的なアイデアは以下の通りです。最適化されたコードオブジェクトをアセンブルする際に、これがJavaScript関数のコードであるかどうかを確認します。その場合、コードオブジェクトが非最適化されている場合には脱出するマシンコードをプロローグで組み立てます。非最適化時には、非最適化されたコードは変更しません—コードパッチングは不要です。そのため、関数を再び呼び出す際には、そのビット marked_for_deoptimization が依然としてセットされています。TurboFanはそれをチェックし、それがセットされている場合、V8は新しい組み込みCompileLazyDeoptimizedCodeにジャンプし、JavaScript関数から非最適化されたコードをアンリンクして遅延コンパイルを続行します。
詳細には、最初のステップは現在アセンブルされているコードのアドレスをロードする命令を生成することです。x64では、以下のコードでそれが可能です:
Label current;
// 現在の命令の有効アドレスをrcxにロードします。
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
その後、コードオブジェクト内で marked_for_deoptimization ビットがどこにあるかを取得する必要があります。
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
その後、ビットをテストして、セットされている場合はCompileLazyDeoptimizedCode組み込みにジャンプします。
// ビットがセットされている、つまりコードが非最適化にマークされている場合かをテストします。
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// そうである場合、組み込みコードへジャンプします。
__ j(not_zero, /* handle to builtin code here */, RelocInfo::CODE_TARGET);
CompileLazyDeoptimizedCode 組み込み側では、残っているのはJavaScript関数からコードフィールドをアンリンクし、それをインタープリターエントリーのトランポリンに設定するだけです。JavaScript関数のアドレスがrdiレジスタにあると仮定すると、次のコードでSharedFunctionInfoへのポインタを取得できます:
// `SharedFunctionInfo` を取得するためのフィールドリード。
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
同様に、トランポリンも以下のように取得できます:
// コードオブジェクトを取得するためのフィールドリード。
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
その後、それを使用してコードポインタの関数スロットを更新することができます:
// トランポリンで関数のコードフィールドを更新します。
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// フィールドを保護するためのライトバリア。
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
これにより、以前と同じ結果が得られます。しかし、Deoptimizerでのアンリンク処理を行う代わりに、コード生成時にそれを考慮する必要があります。そのため、手書きのアセンブリが必要です。
上記はx64アーキテクチャでの動作です。この技術はia32、arm、arm64、mips、mips64にも実装されています。
この新しい技術はすでにV8に統合されており、後ほど解説するように性能向上を可能にします。ただし、いくつかの小さな欠点があります。以前はV8が最適化解除の際にリンク解除を考慮していましたが、現在ではすべての最適化された関数の活性化時にリンク解除を行う必要があります。さらに、marked_for_deoptimizationビットを確認する手法は、コードオブジェクトのアドレスを取得するために一定の作業を要するため、効率的とは言えません。これは最適化された関数に入るたびに発生します。この問題への可能な解決策として、コードオブジェクト内にそれ自身へのポインターを保持するという手法があります。これにより、関数が呼び出されるたびにコードオブジェクトのアドレスを探すのではなく、構築後に一度だけ行うことができます。
結果
次に、このプロジェクトによって得られた性能の向上と後退について詳しく見ていきます。
x64における一般的な改善
以下のグラフは、以前のコミットと比較して得られた改善と後退を示しています。注意してください。値が高いほど良いです。
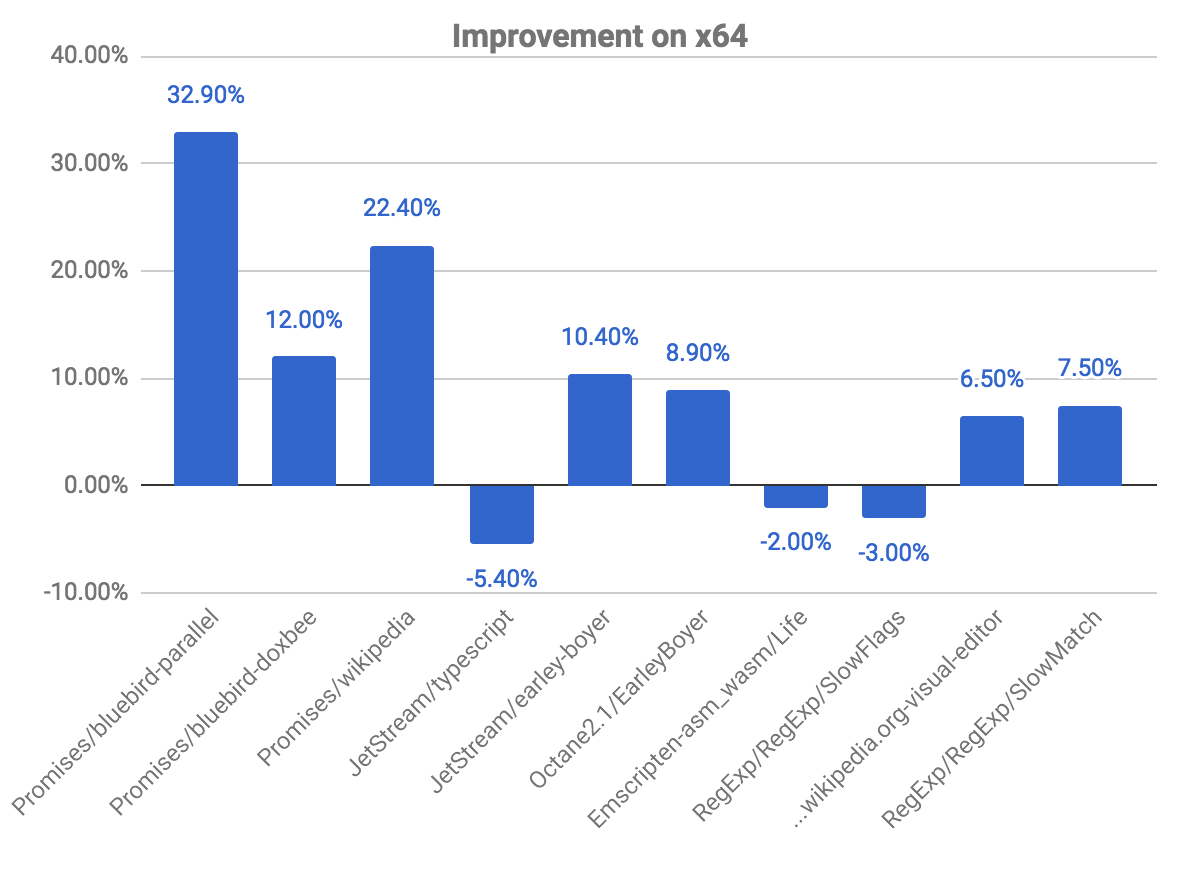
promises ベンチマークにおいて最大の改善が見られます。例えば、bluebird-parallel ベンチマークでは約33%の改善が、wikipedia では22.40%の改善が見られました。一部のベンチマークでは若干の後退も確認されました。これは前述の、コードが最適化解除マークされているかどうかを確認する問題に関連しています。
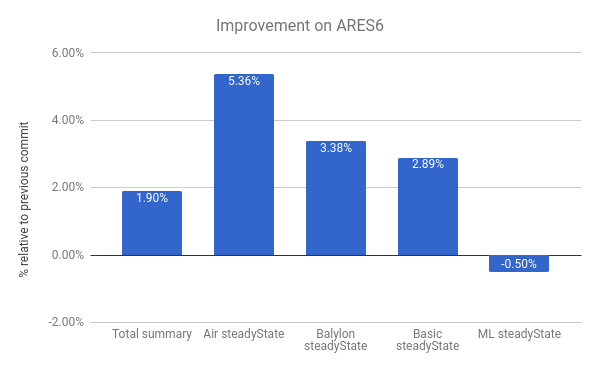
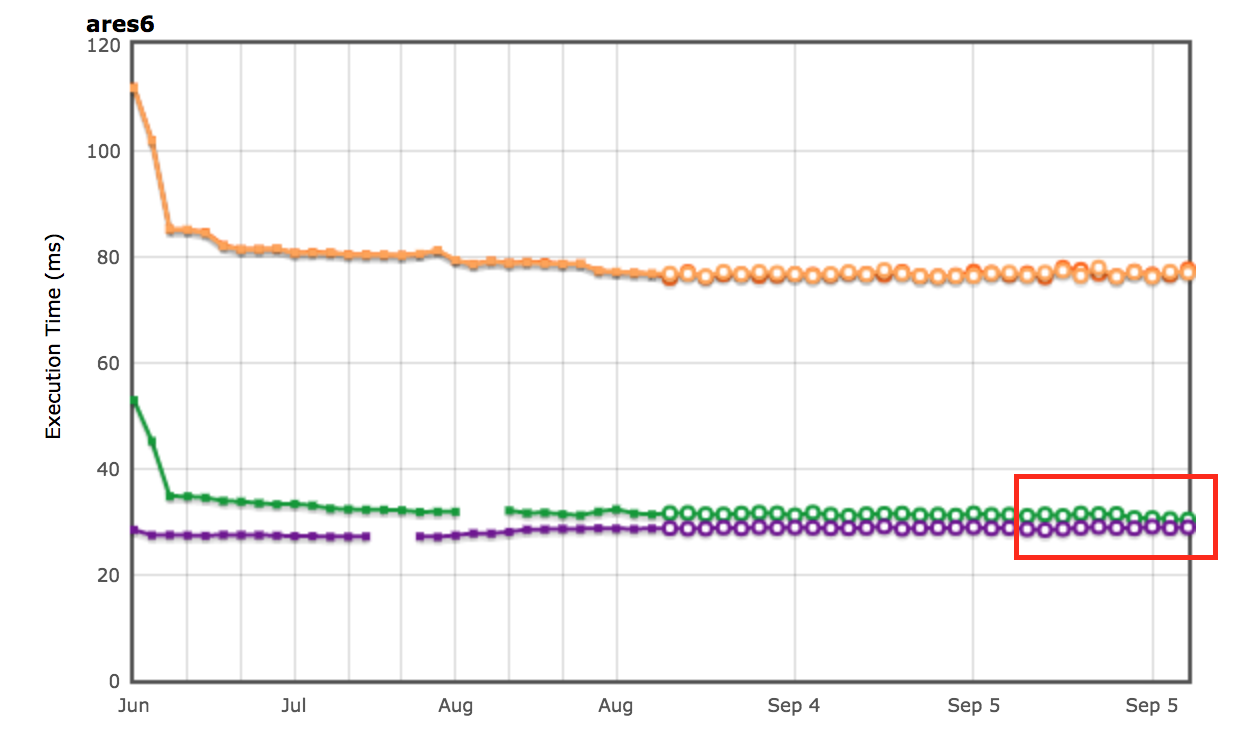
ARES-6ベンチマークスイートの改善も確認することができます。このチャートでも、値が高いほど良い結果となります。これらのプログラムは以前、GC関連の活動に多くの時間を費やしていました。怠惰なリンク解除により、全体で1.9%の性能向上が得られています。最も顕著な例は Air steadyState で、この場合約5.36%の改善が見られました。
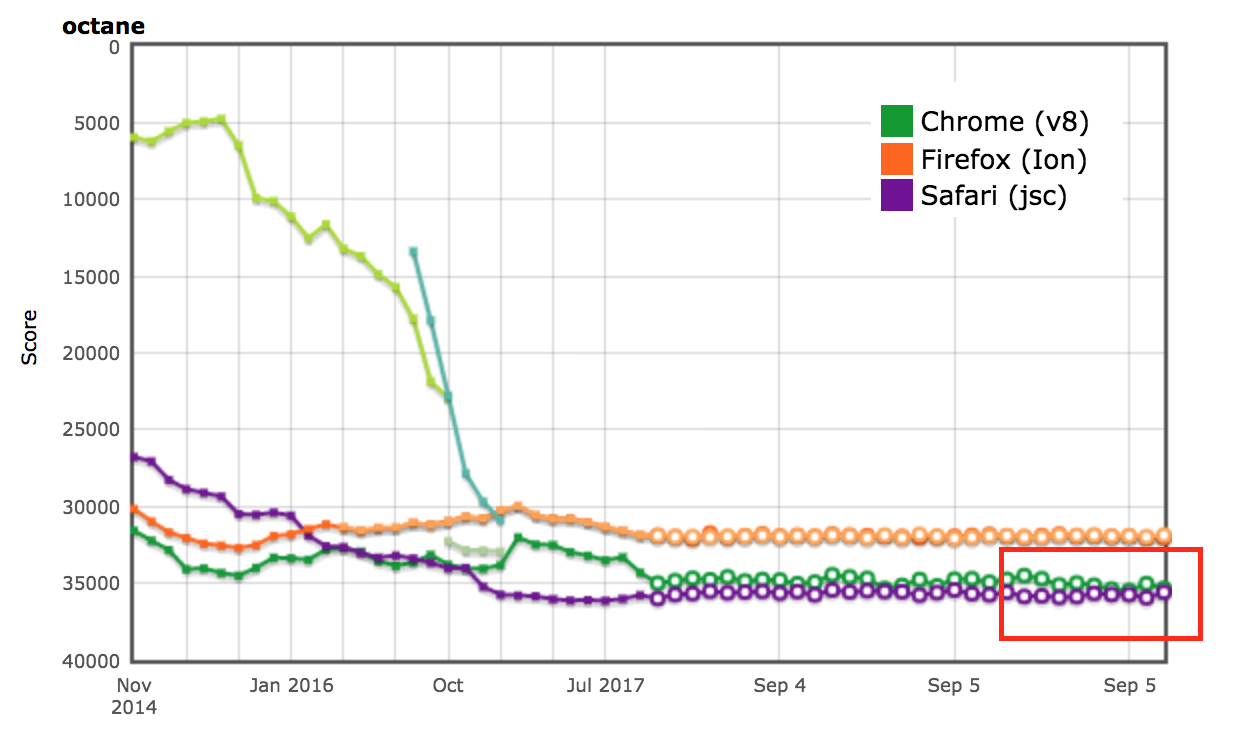
AreWeFastYetの結果
OctaneおよびARES-6ベンチマークスイートの性能結果は、AreWeFastYetトラッカー上でも確認されました。これらの性能結果は2017年9月5日に、提供されたデフォルトマシン(macOS 10.10 64-bit、Mac Pro、シェル)で分析されました。
Node.jsへの影響
router-benchmark における性能の改善も確認することができます。以下の2つのグラフは、各テストされたルーターの秒間操作数を示しています。よって値が高いほど良い結果となります。このベンチマークスイートで2種類の実験を行いました。最初に、各テストを個別に実行し、他のテストから独立して性能改善を確認しました。次に、VMの切り替えを行わずにすべてのテストを一度に実行し、各テストが他の機能と統合されている環境をシミュレートしました。
最初の実験では、router と express テストが同じ時間内に以前の約2倍の操作を行うことがわかりました。2つ目の実験ではさらに大きな改善が見られました。例えば、routr 、server-router 、router の場合、それぞれ約3.80倍、3倍、および2倍多くの操作が行われました。これは、V8が試験後により多くの最適化されたJavaScript関数を蓄積するためです。その結果、あるテストを実行する際にガベージコレクションサイクルが発動すると、V8は現在のテストおよび以前のテストから最適化された関数を訪問する必要があります。


さらなる最適化
V8がコンテキスト内でJavaScript関数のリンクリストを保持しなくなったことで、JSFunction クラスから next フィールドを削除することができます。この変更は単純ですが、関数ごとに1つのポインタのサイズを節約することが可能であり、いくつかのウェブページでは顕著なメモリー削減に繋がります:
| ベンチマーク | 種類 | メモリ削減 (絶対値) | メモリ削減 (相対値) |
|---|---|---|---|
| facebook.com | 平均効果的サイズ | 170 KB | 3.70% |
| twitter.com | 割り当てられたオブジェクトの平均サイズ | 284 KB | 1.20% |
| cnn.com | 割り当てられたオブジェクトの平均サイズ | 788 KB | 1.53% |
| youtube.com | 割り当てられたオブジェクトの平均サイズ | 129 KB | 0.79% |
謝辞
インターンシップ期間中、多くの方々から多大な助けをいただきました。彼らはいつも私の多くの質問に答えてくれる存在でした。この場を借りて、以下の皆様に感謝を申し上げます。コンパイラやデオプティマイザの動作について議論してくださったBenedikt Meurer、Jaroslav Sevcik、Michael Starzinger、ガベージコレクターの問題解決を助けてくださったUlan Degenbaev、そしてこの記事の校正を担当してくださったMathias Bynens、Peter Marshall、Camillo Bruni、Maya Armyanovaの皆様、本当にありがとうございました。
最後に、この記事はGoogleでのインターンとしての私の最後の貢献となります。この機会を借りて、V8チームの皆様、特に私のホストであるBenedikt Meurerに感謝を申し上げます。私を迎えていただき、非常に興味深いプロジェクトに携わる機会をくださったことに心から感謝しています。この期間で多くを学び、Googleでの時間を非常に楽しみました!