Ускорение V8 с помощью изменяемых чисел в куче
В V8 мы постоянно стремимся улучшать производительность JavaScript. В рамках этих усилий мы недавно пересмотрели набор бенчмарков JetStream2, чтобы устранить узкие места производительности. В этом посте описывается конкретная оптимизация, которую мы внедрили, что привело к значительному улучшению результата async-fs в 2.5x, способствуя заметному улучшению общего счета. Оптимизация была вдохновлена этим бенчмарком, но подобные шаблоны действительно встречаются в реальном коде.
Бенчмарк async-fs, как следует из названия, представляет собой реализацию файловой системы на JavaScript, сфокусированную на асинхронных операциях. Однако существует неожиданное узкое место производительности: реализация Math.random. Для обеспечения консистентных результатов за несколько прогонов используется собственная, детерминированная реализация Math.random. Вот как она выглядит:
let seed;
Math.random = (function() {
return function () {
seed = ((seed + 0x7ed55d16) + (seed << 12)) & 0xffffffff;
seed = ((seed ^ 0xc761c23c) ^ (seed >>> 19)) & 0xffffffff;
seed = ((seed + 0x165667b1) + (seed << 5)) & 0xffffffff;
seed = ((seed + 0xd3a2646c) ^ (seed << 9)) & 0xffffffff;
seed = ((seed + 0xfd7046c5) + (seed << 3)) & 0xffffffff;
seed = ((seed ^ 0xb55a4f09) ^ (seed >>> 16)) & 0xffffffff;
return (seed & 0xfffffff) / 0x10000000;
};
})();
Ключевой переменной здесь является seed. Она обновляется при каждом вызове Math.random, генерируя псевдослучайную последовательность. Важно, что seed хранится в ScriptContext.
ScriptContext служит местом хранения значений, доступных в определенном скрипте. Внутренне этот контекст представлен как массив тегированных значений V8. По умолчанию в конфигурации 64-битных систем V8 каждое из этих значений занимает 32 бита. Младший значащий бит каждого значения действует как тег. Значение 0 указывает на 31-битное малое целое число (SMI). Само целое значение хранится прямо, сдвинутое влево на один бит. Значение 1 указывает на сжатый указатель на объект в куче, где значение сжатого указателя увеличивается на единицу.

Это маркирование определяет, как хранятся числа. SMI находятся непосредственно в ScriptContext. Более крупные числа или числа с десятичными частями хранятся косвенно как неизменяемые объекты HeapNumber в куче (64-битный double), а в ScriptContext хранится сжатый указатель на них. Такой подход эффективно обрабатывает различные типы чисел, оптимизируя общий случай SMI.
Узкое место
Профилирование Math.random выявило два основных узких места производительности:
-
Выделение
HeapNumber: Слот, выделенный для переменнойseedв контексте скрипта, указывает на стандартное неизменяемое значениеHeapNumber. Каждый раз, когда функцияMath.randomобновляетseed, в куче должен выделяться новый объектHeapNumber, что приводит к значительной нагрузке на выделение памяти и сборку мусора. -
Вычисления с плавающей запятой: Хотя вычисления внутри
Math.randomв основном являются целочисленными операциями (с использованием побитовых сдвигов и сложений), компилятор не может в полной мере использовать это. Посколькуseedхранится как общийHeapNumber, сгенерированный код использует более медленные инструкции для чисел с плавающей запятой. Компилятор не может доказать, чтоseedвсегда будет содержать значение, представимое как целое число. Хотя компилятор мог бы потенциально предположить 32-битные целочисленные диапазоны, V8 в основном фокусируется наSMI. Даже при предположении 32-битного целого числа потребовалась бы потенциально дорогая конверсия из 64-битного числа с плавающей запятой в 32-битное целое число, а также проверка на отсутствие потерь.
Решение
Для решения этих проблем мы внедрили двухчастную оптимизацию:
-
Отслеживание типов слотов / изменяемые слоты для
HeapNumber: Мы расширили отслеживание неизменяемых значений в контексте скрипта (переменные 'let', которые были инициализированы, но никогда не изменялись), включив информацию о типах. Мы отслеживаем, является ли значение слота константным,SMI,HeapNumberили общим тегированным значением. Также мы ввели концепцию изменяемых слотов дляHeapNumberв контексте скриптов, аналогично изменяемым полямHeapNumberдляJSObjects. Вместо указывания на неизменяемыйHeapNumber, слот контекста скрипта владеетHeapNumber, и его адрес не должен быть утечкой. Это устраняет необходимость выделять новыйHeapNumberпри каждом обновлении для оптимизированного кода. СамHeapNumberизменяется на месте. -
Изменяемый 'Heap Int32': Мы улучшаем типы слотов в контексте скрипта, чтобы отслеживать, находится ли числовое значение в диапазоне
Int32. Если да, изменяемыйHeapNumberхранит значение как необработанныйInt32. При необходимости переход наdoubleимеет дополнительное преимущество – отсутствует необходимость в перераспределенииHeapNumber. В случаеMath.randomкомпилятор теперь может наблюдать, чтоseedпостоянно обновляется с помощью операций с целыми числами, и маркировать слот как содержащий изменяемыйInt32.

Важно отметить, что эти оптимизации создают зависимость кода от типа значения, хранимого в слоте контекста. Оптимизированный код, созданный JIT-компилятором, зависит от наличия в слоте определенного типа (здесь - Int32). Если какой-либо код пишет значение в слот seed, изменяющий его тип (например, число с плавающей точкой или строку), оптимизированный код должен будет деоптимизироваться. Эта деоптимизация необходима для обеспечения правильности выполнения. Таким образом, стабильность типа, хранимого в слоте, является ключом к поддержанию максимальной производительности. В случае Math.random побитовая маскировка в алгоритме гарантирует, что переменная seed всегда содержит значение Int32.
Результаты
Эти изменения значительно ускоряют работу функции Math.random:
-
Отсутствие аллокации / быстрые обновления на месте: Значение
seedобновляется непосредственно в своем изменяемом слоте в контексте скрипта. Новые объекты не создаются во время выполненияMath.random. -
Операции с целыми числами: Компилятор, зная, что слот содержит
Int32, может генерировать высокооптимизированные инструкции для работы с целыми числами (сдвиги, сложения и т. д.). Это исключает издержки арифметики с плавающей точкой.
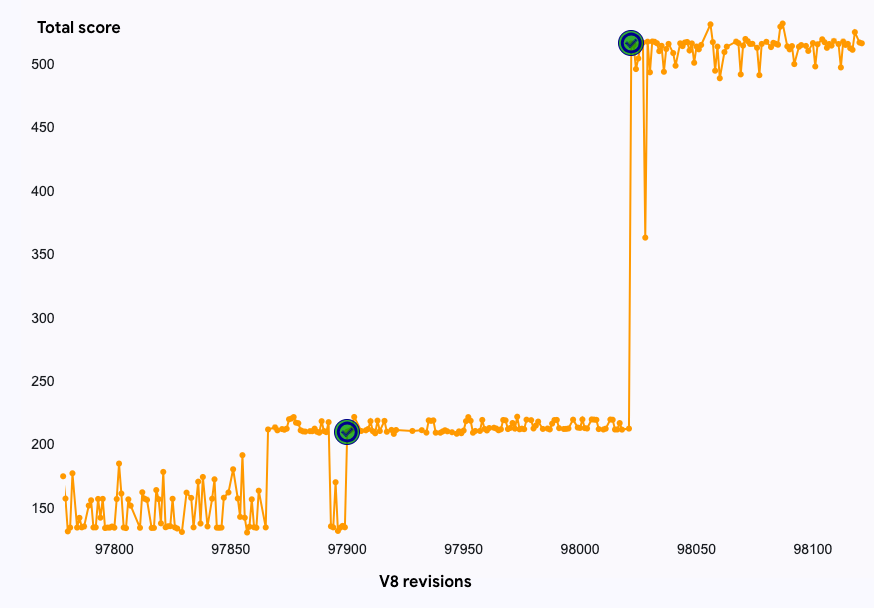
Совокупный эффект этих оптимизаций приводит к впечатляющему ускорению примерно в 2.5x на бенчмарке async-fs. В свою очередь, это улучшает общий результат теста JetStream2 на ~1.6%. Это демонстрирует, что кажущийся простым код может создавать неожиданно значительные узкие места производительности и что маленькие, целевые оптимизации могут оказывать большое влияние не только на тест.