Оптимизация прокси ES2015 в V8
Прокси являются неотъемлемой частью JavaScript с момента появления ES2015. Они позволяют перехватывать основные операции с объектами и настраивать их поведение. Прокси являются ключевой частью таких проектов, как jsdom и библиотека Comlink RPC. Недавно мы приложили немало усилий для улучшения производительности прокси в V8. Эта статья проливает свет на общие шаблоны улучшения производительности в V8, а также на прокси в частности.
Прокси — это «объекты, которые используются для определения пользовательского поведения для основных операций (например, поиска свойства, присваивания значения, перечисления, вызова функции и т.д.)» (определение по MDN). Дополнительную информацию можно найти в полной спецификации. Например, следующий код добавляет логирование для каждого доступа к свойству объекта:
const target = {};
const callTracer = new Proxy(target, {
get: (target, name, receiver) => {
console.log(`get был вызван для: ${name}`);
return target[name];
}
});
callTracer.property = 'value';
console.log(callTracer.property);
// get был вызван для: property
// value
Создание прокси
Первая функция, на которой мы сосредоточимся, — это создание прокси. Наша оригинальная реализация на C++ следовала шаг за шагом спецификации ECMAScript, что приводило к как минимум 4 переходам между C++ и JS рантаймами, как показано на следующем рисунке. Мы хотели перенести эту реализацию на платформо-независимый CodeStubAssembler (CSA), который выполняется в JS рантайме вместо C++ рантайма. Такое перенесение минимизировало количество переходов между языковыми рантаймами. CEntryStub и JSEntryStub представляют рантаймы на рисунке ниже. Пунктирные линии обозначают границы между JS и C++ рантаймами. К счастью, многие вспомогательные предикаты уже были реализованы в ассемблере, что сделало начальную версию краткой и понятной.
На рисунке ниже показано выполнение вызова прокси с любой ловушкой прокси (в данном примере apply, который вызывается, когда прокси используется как функция), созданной следующим примером кода:
function foo(…) { … }
const g = new Proxy({ … }, {
apply: foo,
});
g(1, 2);
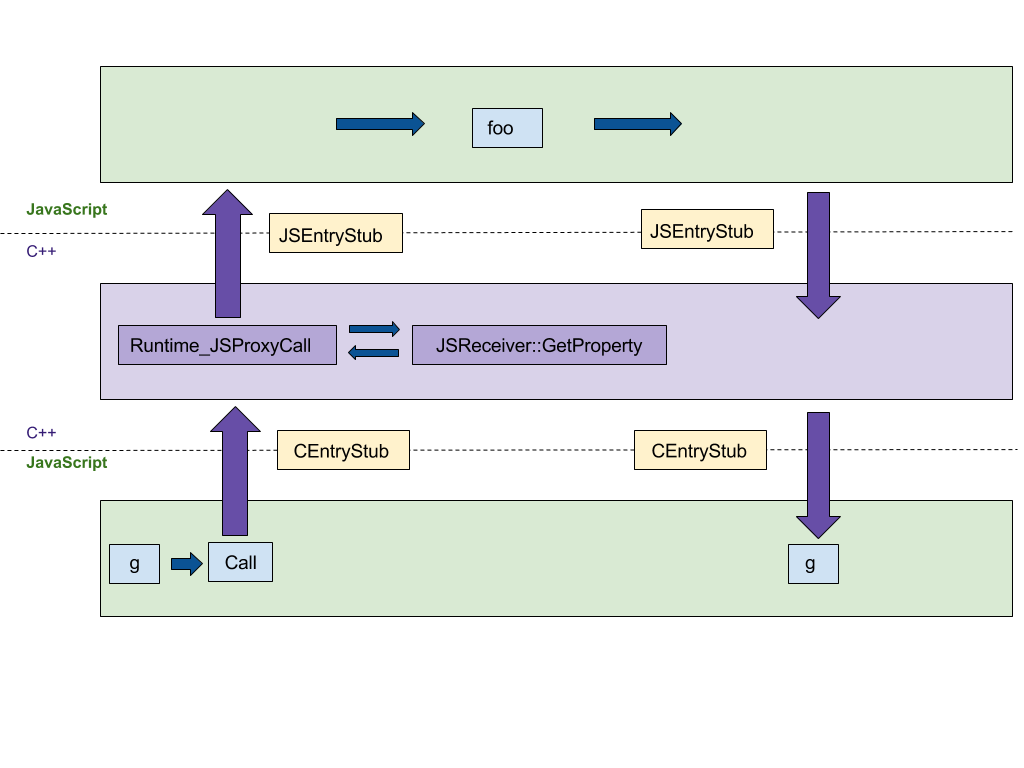
После переноса выполнения ловушки в CSA вся обработка происходит в JS рантайме, снижая количество переходов между языками с 4 до 0.
Это изменение привело к следующим улучшениям производительности::
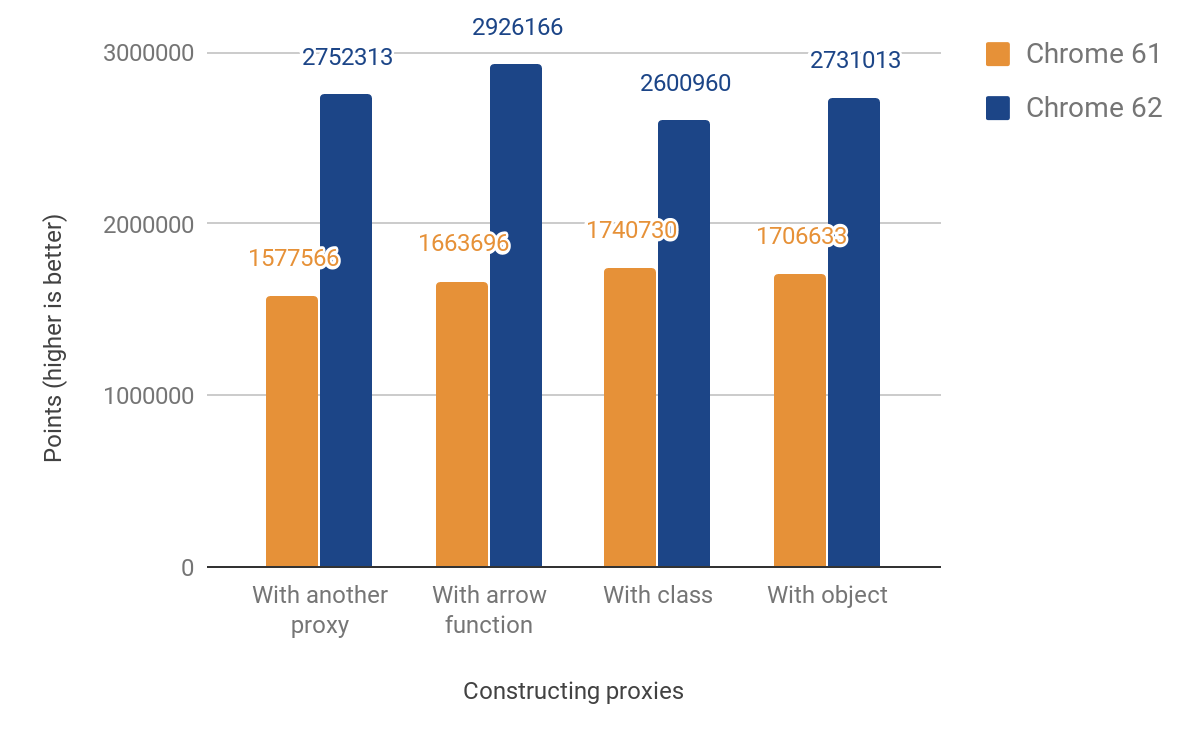
Наш показатель производительности JS показывает улучшение от 49% до 74%. Этот показатель примерно измеряет, сколько раз данный микробенчмарк может быть выполнен за 1000 мс. Для некоторых тестов код выполняется несколько раз, чтобы получить достаточно точное измерение при данном разрешении таймера. Код для всех последующих тестов производительности можно найти в директории js-perf-test.
Ловушки вызова и создания
В следующем разделе показаны результаты оптимизации ловушек вызова и создания (т.н. "apply"" и "construct").
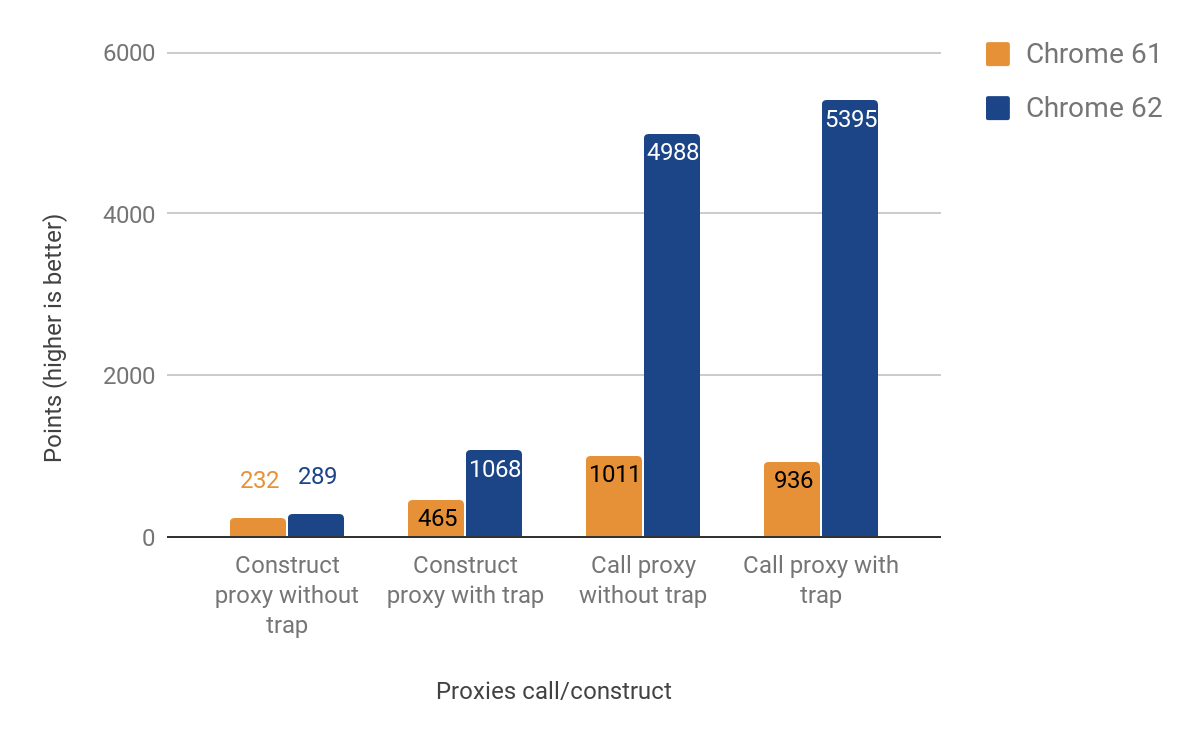
Улучшения производительности при вызове прокси значительны — до 500% быстрее! Тем не менее, прирост производительности при создании прокси довольно скромен, особенно в случаях, когда нет фактической определенной ловушки — всего около 25% прироста. Мы исследовали это, запустив следующую команду с использованием оболочки d8:
$ out/x64.release/d8 --runtime-call-stats test.js
> run: 120.104000
Функция Runtime/C++ Builtin Время Количество
========================================================================================
NewObject 59.16ms 48.47% 100000 24.94%
JS_Execution 23.83ms 19.53% 1 0.00%
RecompileSynchronous 11.68ms 9.57% 20 0.00%
AccessorNameGetterCallback 10.86ms 8.90% 100000 24.94%
AccessorNameGetterCallback_FunctionPrototype 5.79ms 4.74% 100000 24.94%
Map_SetPrototype 4.46ms 3.65% 100203 25.00%
… ФРАГМЕНТ …
Где исходный код test.js:
function MyClass() {}
MyClass.prototype = {};
const P = new Proxy(MyClass, {});
function run() {
return new P();
}
const N = 1e5;
console.time('run');
for (let i = 0; i < N; ++i) {
run();
}
console.timeEnd('run');
Оказалось, что большая часть времени тратится на NewObject и функции, вызываемые им, поэтому мы начали планировать, как ускорить этот процесс в будущих релизах.
Ловушка get
Следующий раздел описывает, как мы оптимизировали другие наиболее распространенные операции — получение и установку свойств через прокси. Оказалось, что get ловушка более сложна, чем предыдущие случаи, из-за специфического поведения встроенного кэша V8. Для подробного объяснения встроенных кэшей можно посмотреть эту лекцию.
В итоге нам удалось адаптировать это для CSA с следующими результатами:
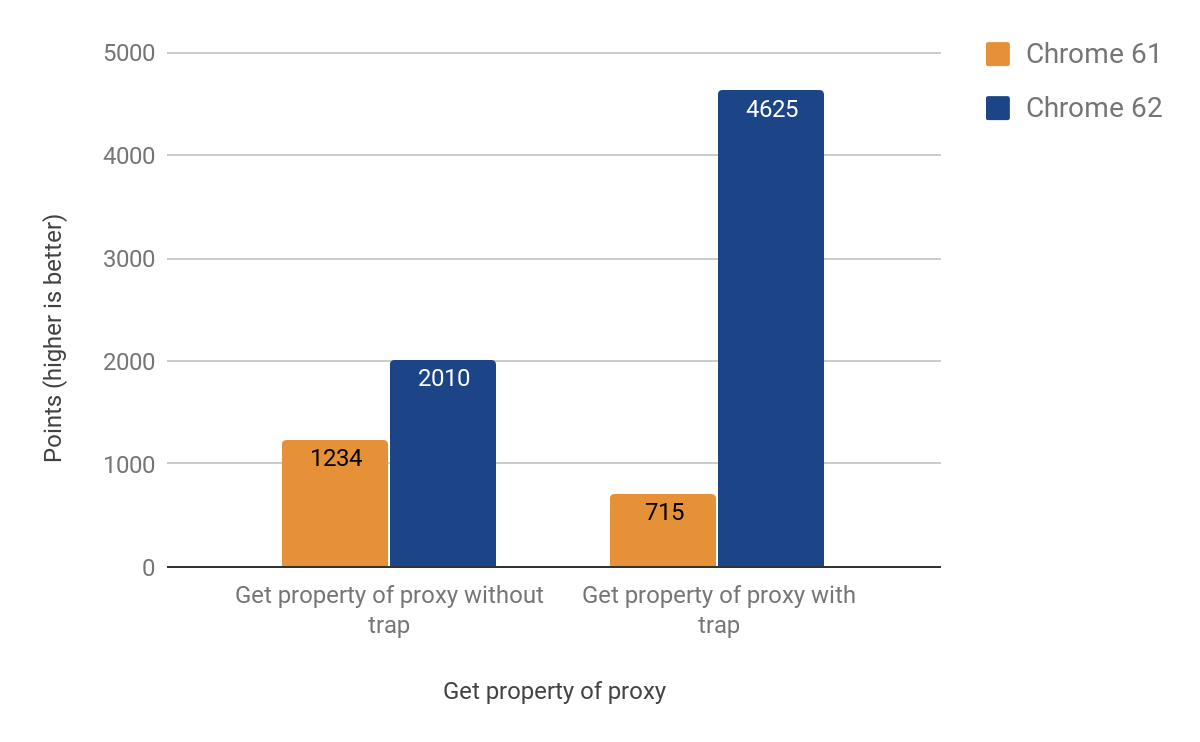
После внесения изменений мы заметили, что размер .apk для Chrome на Android увеличился на ~160КБ, что больше ожидаемого для вспомогательной функции длиной примерно 20 строк, но, к счастью, мы отслеживаем такую статистику. Оказалось, что эта функция вызывается дважды из другой функции, которая, в свою очередь, вызывается 3 раза, а затем — 4 раза. Причиной проблемы оказалось агрессивное встраивание. В конечном итоге мы решили проблему, превратив встроенную функцию в отдельный кодовый фрагмент, тем самым сохранив драгоценные килобайты — итоговая версия увеличила размер .apk только на ~19КБ.
Ловушка has
Следующий раздел демонстрирует результаты оптимизации has ловушки. Хотя сначала мы думали, что это будет легче (и можно будет переиспользовать большую часть кода ловушки get), оказалось, что у неё есть свои особенности. Особенно сложной для отслеживания оказалась проблема с проходом по цепочке прототипов при использовании оператора in. Достигнутые улучшения варьируются в пределах от 71% до 428%. Опять же, выгода более значительна в случаях, когда ловушка есть.
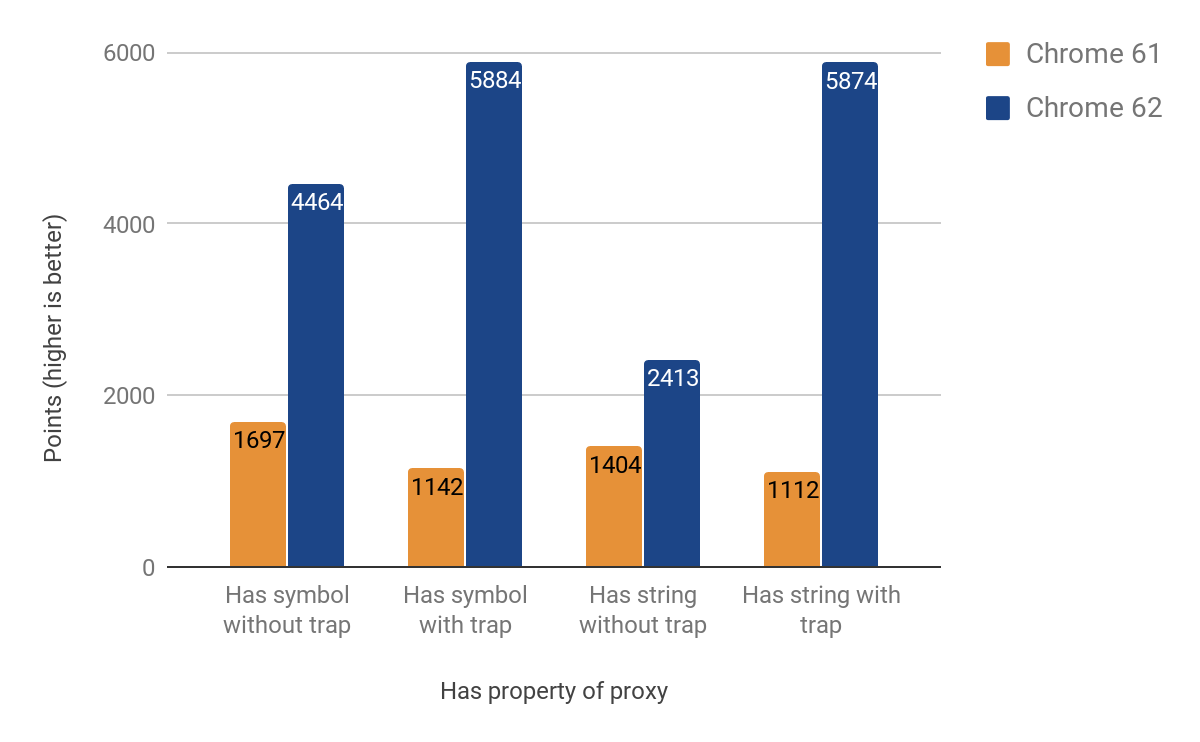
Ловушка set
Следующий раздел рассказывает о переносе set ловушки. На этот раз мы должны были различать именованные и индексируемые свойства (элементы). Эти два основных типа не являются частью языка JS, но играют ключевую роль в эффективном хранении свойств в V8. Первоначальная реализация всё ещё возвращалась к времени выполнения для элементов, что вызывает пересечение языковых границ. Тем не менее, мы достигли улучшений от 27% до 438% в случаях, когда ловушка выставлена, за счёт уменьшения производительности до 23%, когда её нет. Это снижение производительности связано с дополнительной проверкой для различения индексируемых и именованных свойств. Пока что для индексируемых свойств улучшений ещё нет. Вот полные результаты:
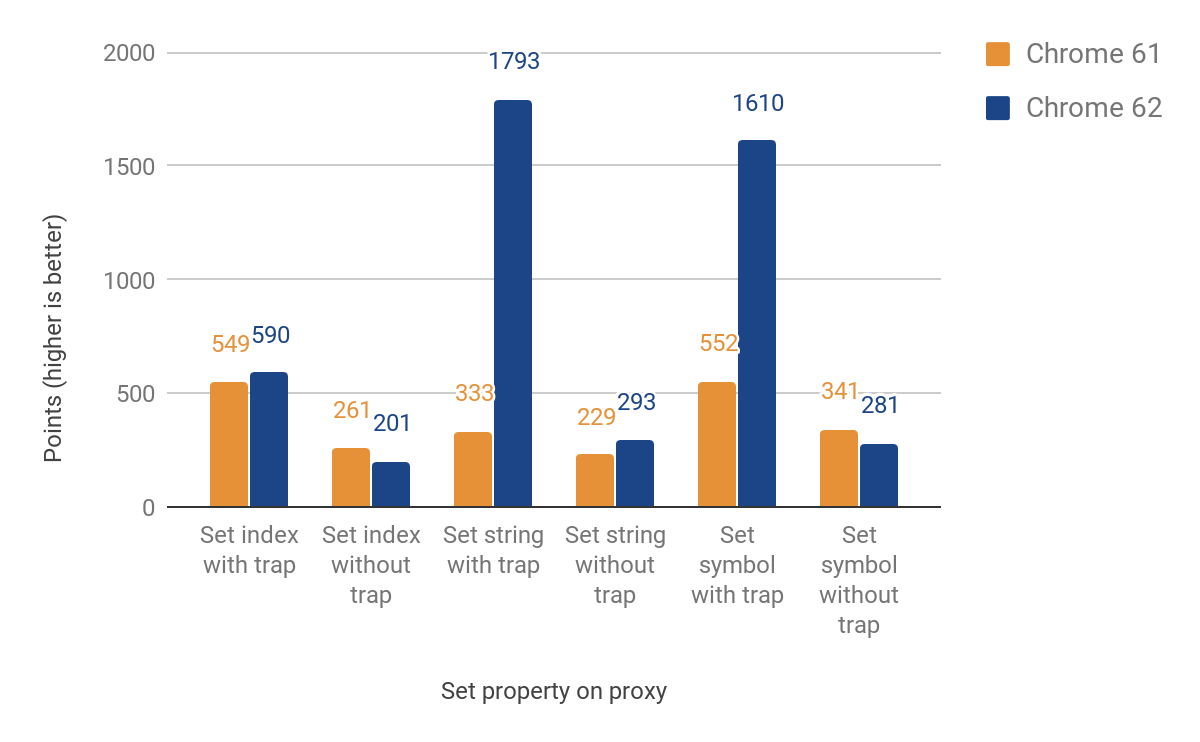
Использование в реальном мире
Результаты из jsdom-proxy-benchmark
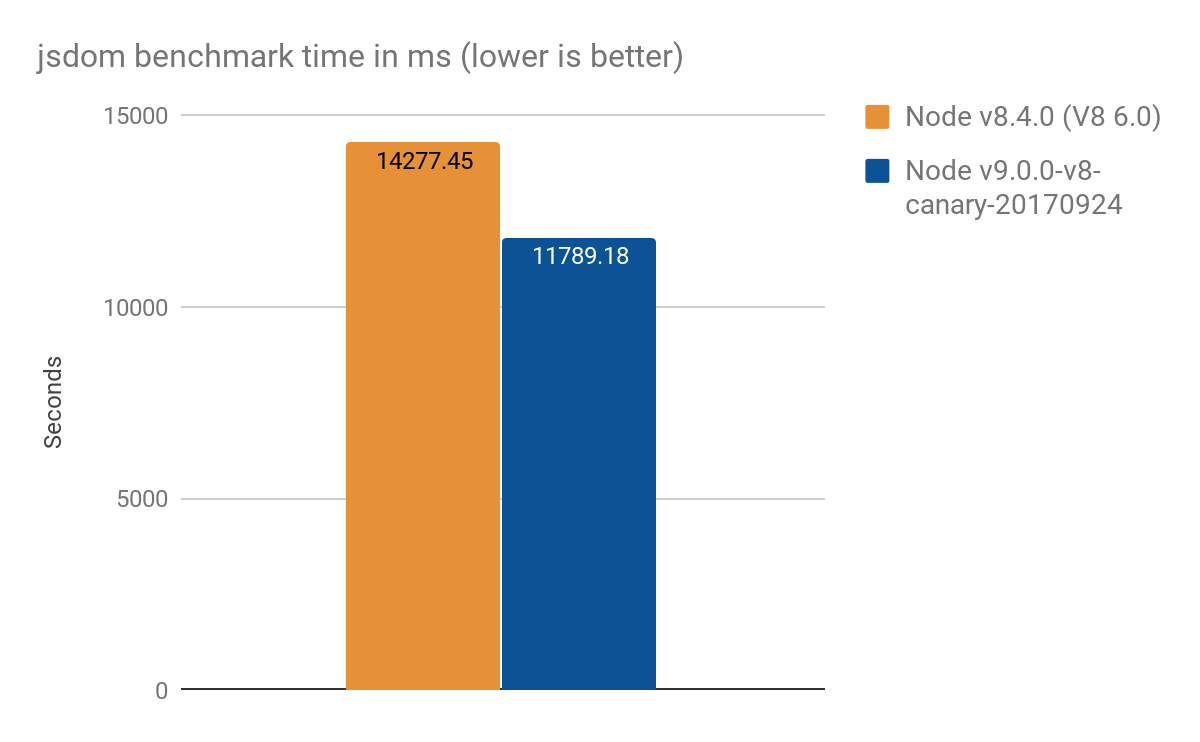
Проект jsdom-proxy-benchmark компилирует спецификацию ECMAScript с использованием инструмента Ecmarkup. Начиная с версии v11.2.0, проект jsdom (который лежит в основе Ecmarkup) использует прокси для реализации общих структур данных NodeList и HTMLCollection. Мы использовали этот тест для получения обзора более реалистичного использования, чем синтетические микротесты, и получили следующие результаты, в среднем 100 запусков:
- Node v8.4.0 (без оптимизаций Proxy): 14277 ± 159 мс
- Node v9.0.0-v8-canary-20170924 (с только половиной перенесённых ловушек): 11789 ± 308 мс
- Прирост скорости около 2.4 секунд, что составляет ~17% лучше
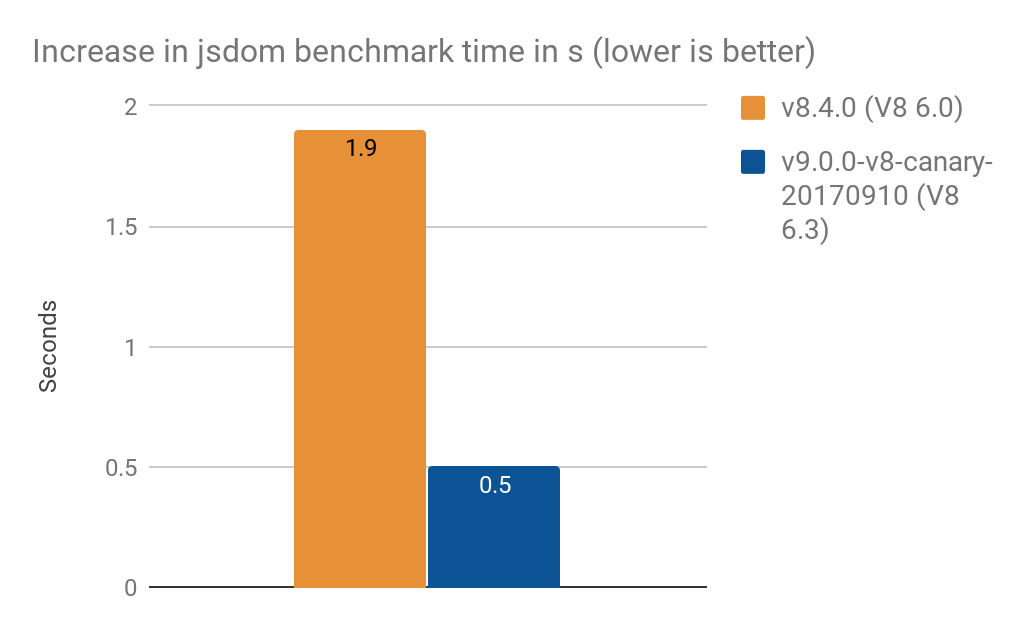
- Конвертация
NamedNodeMapдля использованияProxyувеличила время обработки на- 1.9 с на V8 6.0 (Node v8.4.0)
- 0.5 с на V8 6.3 (Node v9.0.0-v8-canary-20170910)
:::примечание Примечание: Эти результаты были предоставлены Timothy Gu. Спасибо! :::
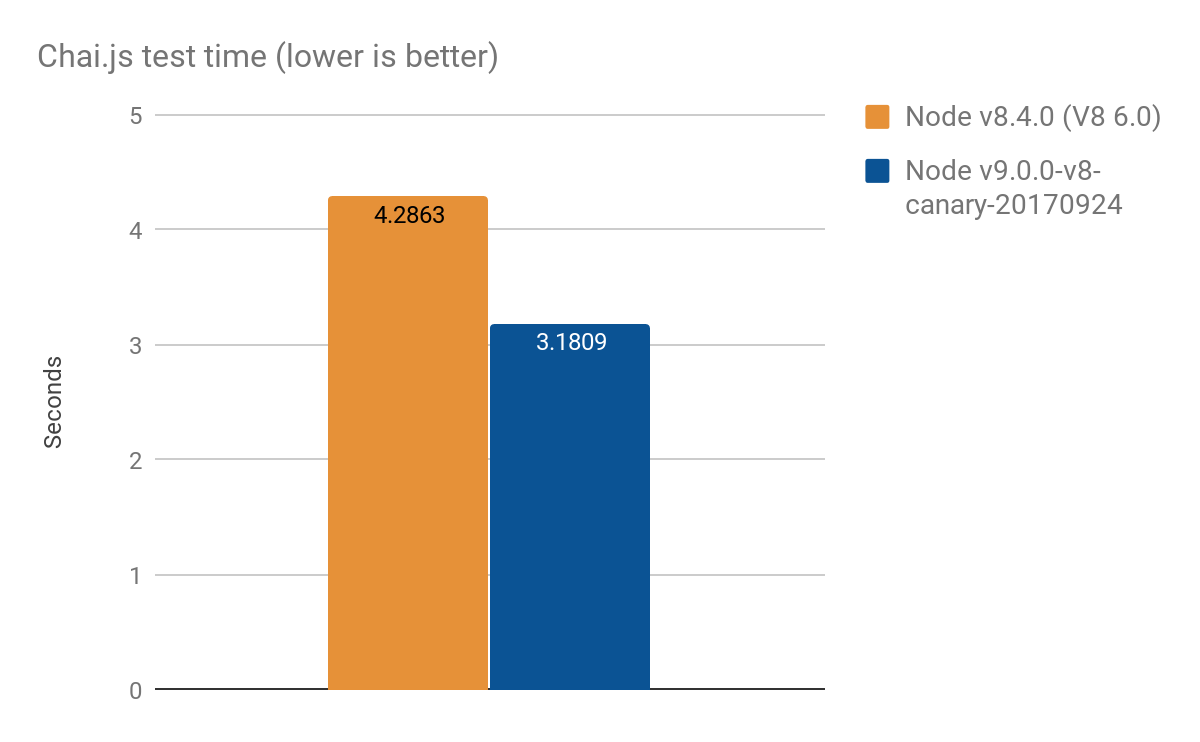
Результаты от Chai.js
Chai.js — это популярная библиотека утверждений, активно использующая прокси. Мы создали своего рода реальный тест производительности, запустив её тесты с разными версиями V8, улучшение составило примерно 1 секунда из более чем 4 секунд, среднее значение из 100 запусков:
- Node v8.4.0 (без оптимизаций Proxy): 4.2863 ± 0.14 с
- Node v9.0.0-v8-canary-20170924 (с только половиной портированных ловушек): 3.1809 ± 0.17 с
Подход к оптимизации
Мы часто решаем задачи производительности, используя универсальную схему оптимизации. Основной подход, которого мы придерживались в рамках данной работы, включал следующие шаги:
- Реализация тестов производительности для конкретного подфункционала
- Добавление дополнительных тестов на соответствие спецификациям (или их написание с нуля)
- Исследование исходной реализации на C++
- Портирование подфункционала в независимый от платформы CodeStubAssembler
- Дальнейшая оптимизация кода вручную с использованием TurboFan
- Измерение прироста производительности.
Этот подход можно применять для любой общей задачи оптимизации, которая у вас есть.