Ускорение создания снимков кучи V8
Этот блог-пост подготовлен Хосе Дапена Пазом (Igalia) при содействии Джейсона Уильямса (Bloomberg), Эшли Клеймора (Bloomberg), Роба Пальмера (Bloomberg), Джойи Чюн (Igalia) и Шу-Юй Гуо (Google).
В этом посте о снимках кучи V8 я расскажу о некоторых проблемах производительности, обнаруженных инженерами Bloomberg, и о том, как мы их решили, чтобы сделать анализ памяти JavaScript быстрее, чем когда-либо.
Проблема
Инженеры Bloomberg работали над диагностикой утечки памяти в JavaScript-приложении. Оно завершалось с ошибками Out-Of-Memory. Для тестируемого приложения предел кучи V8 был настроен примерно на 1400 МБ. Обычно сборщик мусора V8 должен быть способен удерживать использование кучи ниже этого предела, поэтому сбои указывали на вероятную утечку.
Распространенной техникой работы с подобной ситуацией утечки памяти является захват снимка кучи, затем его загрузка в вкладку «Память» в DevTools и анализ того, что потребляет больше всего памяти, исследуя различные сводки и атрибуты объектов. В интерфейсе DevTools снимок кучи можно сделать во вкладке «Память». Для приложений Node.js создание снимка кучи может быть инициировано программно с использованием этого API:
require('v8').writeHeapSnapshot();
Они хотели захватить несколько снимков в разных моментах времени в жизненном цикле приложения, чтобы в DevTools Memory viewer можно было показать разницу между кучами в разные моменты времени. Проблема заключалась в том, что создание одного полного снимка размером 500 МБ занимало более 30 минут!
Эта медлительность в процессе анализа памяти была тем, что нам нужно было решить.
Уточнение проблемы
Затем инженеры Bloomberg начали расследование проблемы, используя некоторые параметры V8. Как описано в этом посте, Node.js и V8 имеют несколько удобных параметров командной строки, которые могут помочь в этом. Эти настройки использовались для создания снимков кучи, упрощения воспроизведения и улучшения наблюдаемости:
--max-old-space-size=100: Ограничивает размер кучи до 100 мегабайт и помогает быстрее воспроизвести проблему.--heapsnapshot-near-heap-limit=10: Конкретный параметр командной строки Node.js, который указывает Node.js генерировать снимок каждый раз, когда куча приближается к исчерпанию памяти. Настроен на генерацию до 10 снимков в общей сложности, чтобы предотвратить чрезмерное создание снимков.--enable-etw-stack-walking: Позволяет инструментам, таким как ETW, WPA и xperf, видеть стек JavaScript, вызванный в V8. (доступно в Node.js v20+)--interpreted-frames-native-stack: Этот флаг используется совместно с инструментами, такими как ETW, WPA и xperf, для отображения нативного стека при профилировании. (доступно в Node.js v20+).
Когда размер кучи V8 начинает приближаться к пределу, V8 насильно запускает сборку мусора для снижения использования памяти. Он также уведомляет встроенное приложение об этом. Флаг --heapsnapshot-near-heap-limit в Node.js генерирует новый снимок кучи при получении уведомления. В тестовом случае использование памяти уменьшалось, но после нескольких итераций сборщик мусора уже не мог освободить достаточно памяти, и приложение завершалось с ошибкой Out-Of-Memory.
Они провели запись с помощью Windows Performance Analyzer (см. ниже), чтобы уточнить проблему. Это показало, что большая часть времени процессора тратится на V8 Heap Explorer. В частности, одна лишь обработка кучи для обхода каждого узла и сбора имени занимала около 30 минут. Это казалось неразумным — почему запись имени каждого свойства занимает столько времени?
Именно тогда меня попросили взглянуть на это.
Квантификация проблемы
Первым шагом было добавление поддержки в V8 для лучшего понимания, где тратится время при создании снимков кучи. Процесс создания снимка разделён на два этапа: генерацию и сериализацию. Мы внедрили этот патч в основной код, чтобы добавить новый флаг командной строки --profile_heap_snapshot в V8, который включает логирование как времени генерации, так и времени сериализации.
Используя этот флаг, мы узнали несколько интересных вещей!
Во-первых, мы могли наблюдать точное количество времени, которое V8 тратил на генерацию каждого снимка. В нашем сокращенном тесте первый генерация заняла 5 минут, второй — 8 минут, и каждый последующий снимок занимал все больше и больше времени. Почти все это время уходило на фазу генерации.
Это также позволило нам количественно оценить время, затраченное на генерацию снимков, с незначительным накладным расходом, что помогло нам изолировать и выявить аналогичные замедления в других широко используемых JavaScript-приложениях — в частности, ESLint на TypeScript. Таким образом, мы знаем, что проблема не была специфичной для приложения.
Что еще важно, мы обнаружили, что проблема возникала как на Windows, так и на Linux. Проблема также не была специфичной для платформы.
Первая оптимизация: улучшение хэширования StringsStorage
Чтобы определить, что вызывало чрезмерную задержку, я провел профилирование неисправного скрипта, используя Windows Performance Toolkit.
Когда я открыл запись в Windows Performance Analyzer, вот что я обнаружил:

Треть выборок была потрачена на v8::internal::StringsStorage::GetEntry:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
Поскольку это запускалось с выпускной сборкой, информация о встроенных вызовах функций была включена в StringsStorage::GetEntry(). Чтобы точно определить, сколько времени занимали встроенные вызовы функций, я добавил столбец “Source Line Number” в разбиение и выяснил, что большая часть времени была потрачена на строку 182, где выполнялся вызов ComputeStringHash():
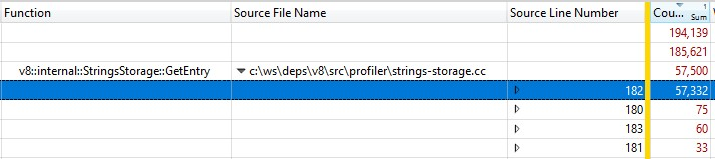
Итак, более 30% времени генерации снимка было потрачено на ComputeStringHash(), но почему?
Давайте сначала поговорим о StringsStorage. Его цель — хранить уникальную копию всех строк, которые будут использоваться в снимке кучи. Для быстрого доступа и избежания дубликатов этот класс использует хэш-таблицу, поддерживаемую массивом, где коллизии обрабатываются путем хранения элементов на следующей свободной позиции в массиве.
Я начал подозревать, что проблема могла быть вызвана коллизиями, которые могут приводить к долгим поискам в массиве. Поэтому я добавил исчерпывающие логи, чтобы увидеть сгенерированные ключи хэша, и при вставке посмотреть, насколько далеко от ожидаемой позиции, рассчитанной из ключа хэша, находилось фактическое положение записи из-за коллизий.
В логах что-то было не так: смещение многих элементов превышало 20, а в худшем случае доходило до тысяч!
Часть проблемы была вызвана числовыми строками — особенно строками для широкого диапазона последовательных чисел. Алгоритм ключа хэша имел две реализации: одну для числовых строк и другую для остальных строк. Хотя функция хэша строк была вполне классической, реализация для числовых строк фактически возвращала значение числа, предваренное количеством цифр:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
Эта функция была проблематичной. Некоторые примеры проблем с этой функцией хэша:
- Как только мы вставляли строку, чей ключ хэша был маленьким числом, мы сталкивались с коллизиями, когда пытались сохранить другое число в этом месте, и возникали аналогичные коллизии, если мы пытались сохранить последующие числа последовательно.
- Или, что еще хуже: если в карте уже было много последовательных чисел, и мы хотели вставить строку, чей ключ хэша находился в этом диапазоне, нам приходилось перемещать запись по всем занятым местам, чтобы найти свободное место.
Что я сделал, чтобы исправить это? Поскольку проблема в основном возникала из-за чисел, представленных как строки, которые попадали в последовательные позиции, я изменил функцию хэша так, чтобы мы вращали результирующее значение хэша на 2 бита влево.
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
Таким образом, для каждой пары последовательных чисел мы будем размещать 3 свободные позиции между ними. Эта модификация была выбрана, потому что эмпирическое тестирование на нескольких наборах данных показало, что она лучше всего минимизирует коллизии.
Исправление хеширования было добавлено в V8.
Вторая оптимизация: кеширование позиций исходного кода
После исправления хеширования мы повторно проанализировали производительность и обнаружили дополнительную возможность для оптимизации, которая позволила бы существенно сократить нагрузку.
При генерации снимка кучи для каждой функции в куче V8 пытается записать ее начальную позицию в виде пары номеров строки и столбца. Эта информация может быть использована DevTools для отображения ссылки на исходный код функции. Однако при обычной компиляции V8 хранит начальную позицию каждой функции в виде линейного смещения от начала скрипта. Чтобы вычислить номера строки и столбца на основе линейного смещения, V8 нужно пройти весь скрипт и зафиксировать, где происходят разрывы строк. Этот расчет оказывается очень затратным.
Обычно, после завершения расчета смещений разрывов строк в скрипте, V8 кеширует их в вновь выделяемом массиве, прикрепленном к скрипту. К сожалению, реализация снимка не может изменять кучу при ее обходе, поэтому вновь рассчитанная информация о строках не может быть закеширована.
Решение? Перед генерацией снимка кучи мы теперь заранее проходим все скрипты в контексте V8, чтобы вычислить и закешировать смещения разрывов строк. Так как это не происходит при обходе кучи для генерации снимка, остается возможно изменять кучу и хранить позиции строк исходного кода в качестве кеша.
Исправление для кеширования смещений разрывов строк также добавлено в V8.
Стало ли быстрее?
После включения обоих исправлений мы провели повторный анализ производительности. Оба наших исправления влияют только на время генерации снимков, поэтому, как и ожидалось, времена сериализации снимков не изменились.
При работе с программой на JS, содержащей…
- JS для разработки, время генерации на 50% быстрее 👍
- JS для продакшена, время генерации на 90% быстрее 😮
Почему между кодом для разработки и продакшена такая значительная разница? Продуктивный код оптимизирован с использованием бандлинга и минификации, поэтому JS файлов меньше, но они крупнее. На вычисление позиций строк исходного кода этих крупных файлов требуется больше времени, поэтому они наиболее выигрывают от кеширования позиций и избегания повторных вычислений.
Оптимизации были проверены в целевых средах Windows и Linux.
Для особенно сложной задачи, с которой изначально столкнулись инженеры Bloomberg, общее время выполнения для захвата 100МБ снимка сократилось с болезнительных 10 минут до крайне комфортных 6 секунд. Это 100× ускорение! 🔥
Эти оптимизации являются общими выигрышами, которые, как мы ожидаем, могут быть широко применимы для любого, кто выполняет отладку памяти на V8, Node.js и Chromium. Эти улучшения были включены в V8 версии 11.5.130, что означает, что они доступны в Chromium 115.0.5576.0. Мы с нетерпением ждем, когда Node.js получит эти оптимизации в следующем мажорном релизе.
Что дальше?
Во-первых, было бы полезно, чтобы Node.js принял новый флаг --profile-heap-snapshot в NODE_OPTIONS. В некоторых случаях пользователи не могут напрямую управлять параметрами командной строки, передаваемыми Node.js, и вынуждены настраивать их через переменную окружения NODE_OPTIONS. В настоящее время Node.js фильтрует параметры командной строки V8, установленные в переменной окружения, и разрешает только известное подмножество, что может усложнить тестирование новых флагов V8 в Node.js, как это произошло в нашем случае.
Точность информации в снимках может быть дополнительно улучшена. В настоящее время информация о каждой строке исходного кода скрипта хранится в представлении в куче V8. И это проблема, потому что мы хотим точно измерить кучу без того, чтобы дополнительные издержки измерения производительности влияли на объект нашего наблюдения. В идеале мы бы хранили кеш информации о строках за пределами кучи V8, чтобы сделать информацию снимков более точной.
Наконец, теперь, когда мы улучшили фазу генерации, основная затратная часть — это теперь фаза сериализации. Дальнейший анализ может выявить новые возможности для оптимизации в фазе сериализации.
Благодарности
Это стало возможным благодаря работе инженеров из Igalia и Bloomberg.