Orinoco: сборка мусора для молодого поколения
Объекты JavaScript в V8 размещаются в куче, управляемой сборщиком мусора V8. В предыдущих публикациях в блоге мы уже обсуждали, как мы уменьшаем время пауз при сборке мусора (неоднократно) и потребление памяти. В этом посте мы представляем параллельный Scavenger, одну из последних функций Orinoco, преимущественно параллельного сборщика мусора V8, и обсуждаем принятые проектные решения и альтернативные подходы, которые мы реализовали в процессе.
V8 делит управляемую кучу на поколения, где объекты изначально размещаются в «ясли» молодого поколения. После прохождения сборки мусора объекты копируются в промежуточное поколение, которое все еще является частью молодого поколения. После прохождения еще одной сборки мусора эти объекты переносятся в старшее поколение (см. Рисунок 1). V8 реализует два сборщика мусора: один, который часто собирает молодое поколение, и один, который собирает всю кучу, включая молодое и старшее поколение. Ссылки от старшего к молодому поколению являются корнями для сборки мусора молодого поколения. Эти ссылки записываются для обеспечения эффективной идентификации корней и обновлений ссылок при перемещении объектов.

Так как молодое поколение является относительно небольшим (до 16MiB в V8), оно быстро заполняется объектами и требует частой сборки. До версии M62 V8 использовал сборщик мусора Cheney semispace, который делит молодое поколение на две половины. Во время выполнения JavaScript доступна только одна половина молодого поколения, в то время как другая остается пустой. Во время сборки мусора молодого поколения живые объекты копируются из одной половины в другую, уплотняя память на лету. Живые объекты, которые уже были скопированы один раз, считаются частью промежуточного поколения и переходят в старшее поколение.
Начиная с версии 6.2, V8 заменил алгоритм сборки молодого поколения на параллельный Scavenger, аналогичный сборщику Halstead semispace, с той разницей, что V8 использует динамическое, а не статическое воровство работы между несколькими потоками. Далее мы объясняем три алгоритма: a) однопоточный сборщик мусора Cheney semispace, b) параллельную схему Mark-Evacuate и c) параллельный Scavenger.
Однопоточный алгоритм копирования Cheney semispace
До версии 6.2 V8 использовал алгоритм копирования Cheney semispace, который хорошо подходит как для выполнения на одном ядре, так и для поколенческой схемы. Перед сборкой мусора молодого поколения обе половины семипространства памяти коммитятся и получают соответствующие метки: страницы, содержащие текущий набор объектов, называются from-space, а страницы, куда объекты копируются, называются to-space.
Scavenger считает ссылки в стеке вызовов и ссылки от старшего к молодому поколению корнями. Рисунок 2 иллюстрирует алгоритм, где Scavenger изначально сканирует эти корни и копирует объекты, доступные в from-space, которые еще не были скопированы в to-space. Объекты, которые уже пережили сборку мусора, переходят (перемещаются) в старшее поколение. После сканирования корней и первого раунда копирования объекты в недавно размещенном to-space сканируются на предмет наличия ссылок. Аналогично, все перемещенные объекты сканируются на новые ссылки на from-space. Эти три фазы чередуются в основном потоке. Алгоритм продолжается до тех пор, пока не останутся больше недоступных новых объектов ни в to-space, ни в старшем поколении. В этот момент from-space содержит только недоступные объекты, т.е., только мусор.

![]()
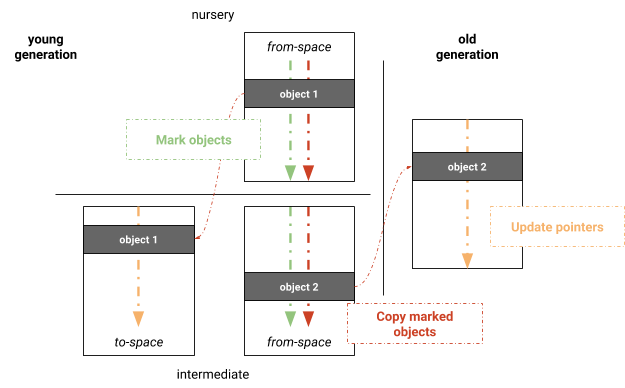
Параллельная схема Mark-Evacuate
Мы экспериментировали с параллельным алгоритмом Mark-Evacuate, основанным на полном сборщике Mark-Sweep-Compact из V8. Основное преимущество заключается в использовании уже существующей инфраструктуры сборщика мусора Mark-Sweep-Compact. Алгоритм состоит из трех фаз: маркировки, копирования и обновления указателей, как показано на Рисунке 3. Чтобы избежать очистки страниц в младшем поколении для поддержания списков свободного пространства, младшее поколение все еще поддерживается с использованием полупространства, которое всегда сохраняется компактным путем копирования живых объектов в to-space во время сборки мусора. Младшее поколение изначально маркируется параллельно. После маркировки живые объекты копируются параллельно в соответствующие пространства. Работа распределяется на основе логических страниц. Потоки, участвующие в копировании, используют свои собственные локальные буферы выделения (LABs), которые объединяются после завершения копирования. После копирования применяется такая же схема параллелизации для обновления межобъектных указателей. Эти три фазы выполняются поочередно, т.е. сами фазы выполняются параллельно, но потоки должны синхронизироваться перед переходом к следующей фазе.

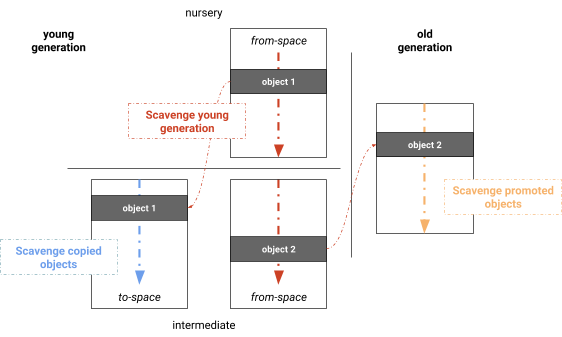
Параллельная очистка
Параллельный сборщик Mark-Evacuate разделяет фазы определения активности, копирования живых объектов и обновления указателей. Очевидная оптимизация заключается в объединении этих фаз, что приводит к алгоритму, который одновременно маркирует, копирует и обновляет указатели. Объединяя эти фазы, мы на самом деле получаем параллельный Scavenger, используемый в V8, который является версией семиспейс-коллектора Хэлстеда с добавлением механизма для динамического воровства работы и упрощенного балансировщика нагрузки для сканирования корневых объектов (см. Рисунок 4). Как и однотредовый алгоритм Чейни, фазы включают: сканирование корневых объектов, копирование в младшем поколении, повышение уровня объектов до старшего поколения и обновление указателей. Мы обнаружили, что большинство множества корневых объектов обычно составляют ссылки из старшего поколения на младшее поколение. В нашем исполнении запоминаемые множества поддерживаются на уровне страницы, что естественно распределяет множество корневых объектов между потоками сборки мусора. Объекты обрабатываются параллельно. Новообнаруженные объекты добавляются в глобальный список задач, из которого потоки сборки мусора могут воровать задачи. Этот список задач обеспечивает оперативное локальное хранилище задач, а также глобальное хранилище для совместного использования работы. Барьер гарантирует, что задачи не завершатся преждевременно, когда субграф, обрабатываемый в данный момент, не подходит для воровства работы (например, линейная цепочка объектов). Все фазы выполняются параллельно и чередуются в каждой задаче, максимально используя ресурсы рабочих задач.

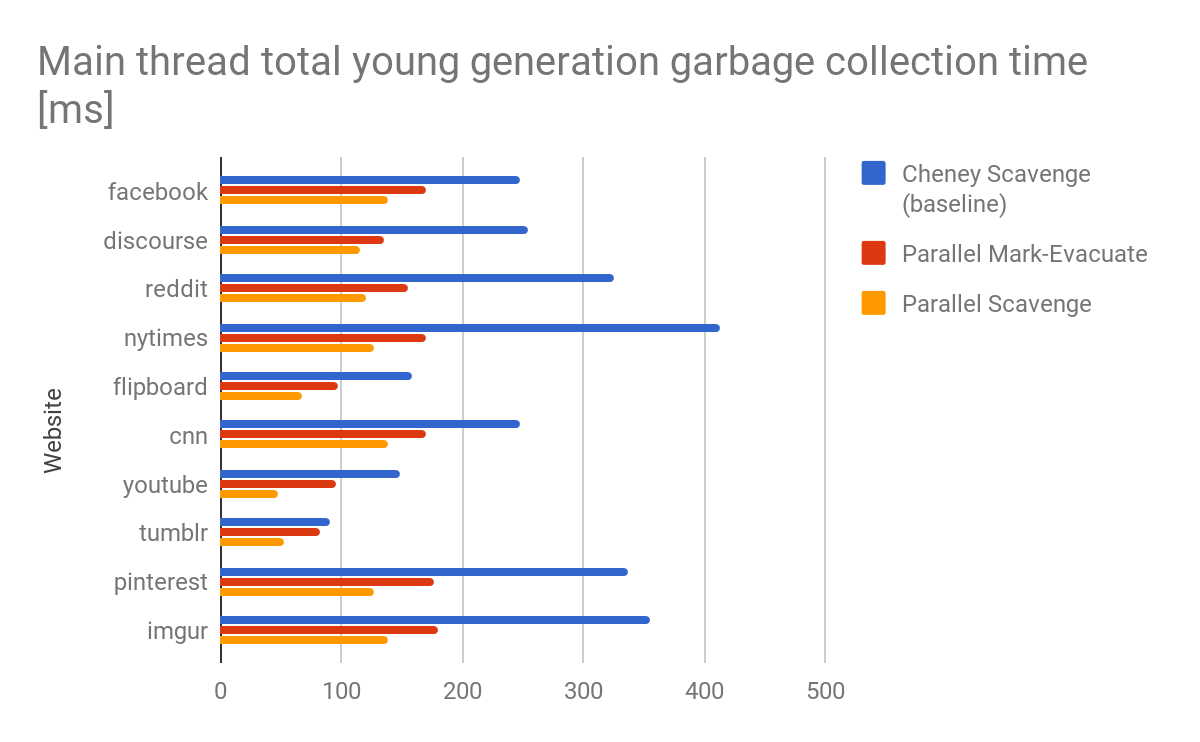
Результаты и итоги
Алгоритм Scavenger был изначально разработан с учетом оптимальной производительности на одном ядре. С тех пор ситуация изменилась. Часто даже на бюджетных мобильных устройствах имеется множество ядер ЦП. Более важно, часто эти ядра действительно активны. Чтобы полностью использовать эти ядра, один из последних последовательных компонентов сборщика мусора V8, Scavenger, пришлось модернизировать.
Большим преимуществом параллельного сборщика Mark-Evacuate является доступность точной информации об активности. Эту информацию можно, например, использовать для избегания копирования, просто перемещая и переназначая страницы, содержащие преимущественно живые объекты, что также выполняется полным сборщиком Mark-Sweep-Compact. Однако на практике это в основном наблюдалось на синтетических тестах и редко проявлялось на реальных веб-сайтах. Минус параллельного сборщика Mark-Evacuate — это накладные расходы на выполнение трех отдельных фаз на поочередной основе. Эти накладные расходы особенно заметны, когда сборщик мусора вызывается на куче, содержащей преимущественно мертвые объекты, что является обычным случаем для многих веб-страниц. Следует отметить, что вызов сборки мусора на кучах с преимущественно мертвыми объектами — это на самом деле идеальный сценарий, так как сборка мусора обычно ограничивается размером живых объектов.
Параллельный Scavenger устраняет этот разрыв в производительности, обеспечивая производительность, близкую к оптимизированному алгоритму Чейни на небольших или почти пустых кучах, в то время как все еще обеспечивает высокую пропускную способность в случае увеличения размеров куч с множеством живых объектов.
V8 поддерживает, наряду с многими другими платформами, такие как Arm big.LITTLE. Хотя разгрузка работы на небольшие ядра благоприятно влияет на срок службы батареи, это может привести к зависанию главного потока, когда пакеты задач для небольших ядер слишком велики. Мы заметили, что параллелизм на уровне страниц не обязательно эффективно сбалансирует работу на архитектуре big.LITTLE для сборки мусора младшего поколения из-за ограниченного числа страниц. Scavenger естественным образом решает эту проблему, предоставляя синхронизацию средней зернистости с использованием явных списков задач и механизма воровства работы.