Стажировка по ленивости: ленивое удаление неактивных функций
Примерно три месяца назад я начала работать в команде V8 (Google Munich) в качестве стажера и с тех пор занимаюсь дезоптимизатором виртуальной машины — задачей, которая была для меня абсолютно новой, но оказалась интересной и сложной. Первая часть моей стажировки была направлена на улучшение безопасности виртуальной машины. Вторая часть касалась повышения производительности, а именно удаления структуры данных, используемой для отмены оптимизации функций, которая была узким местом для производительности при сборке мусора. В этой записи блога я описываю вторую часть своей стажировки, объясняя, как V8 раньше удалял неактивные функции, как мы это изменили и какие улучшения производительности были достигнуты.
Давайте (очень) кратко вспомним работу V8 с функцией JavaScript: интерпретатор V8, Ignition, собирает информацию о профилировании этой функции, пока интерпретирует её. Как только функция становится «горячей», эта информация передается компилятору V8, TurboFan, который генерирует оптимизированный машинный код. Когда информация о профилировании становится недействительной — например, из-за того, что у одного из профилируемых объектов меняется тип в процессе выполнения — сгенерированный машинный код может стать недействительным. В этом случае V8 нужно его дезоптимизировать.
При оптимизации TurboFan создает объект кода, то есть оптимизированный машинный код, для функции под оптимизацией. Когда эта функция вызывается в следующий раз, V8 следует ссылке на оптимизированный код этой функции и выполняет его. При дезоптимизации этой функции нам нужно удалить связь с объектом кода, чтобы гарантировать, что он больше не будет выполняться. Как это происходит?
Например, в следующем коде функция f1 будет вызвана много раз (всегда с передачей целого числа в качестве аргумента). Затем TurboFan генерирует машинный код для этого конкретного случая.
function g() {
return (i) => i;
}
// Создать замыкание.
const f1 = g();
// Оптимизировать f1.
for (var i = 0; i < 1000; i++) f1(0);
Каждая функция также имеет переходник к интерпретатору — подробнее в этих слайдах — и будет хранить указатель на этот переходник в своем SharedFunctionInfo (SFI). Этот переходник используется всякий раз, когда V8 нужно вернуться к неоптимизированному коду. Таким образом, при дезоптимизации, вызванной, например, передачей аргумента другого типа, дезоптимизатор просто задает поле кода JavaScript функции на этот переходник.
Хотя это кажется простым, это заставляет V8 поддерживать слабые списки оптимизированных JavaScript функций. Это потому, что возможно наличие разных функций, указывающих на один и тот же объект оптимизированного кода. Мы можем расширить наш пример следующим образом, и функции f1 и f2 обе указывают на один и тот же оптимизированный код.
const f2 = g();
f2(0);
Если функция f1 дезоптимизируется (например, вызовом с объектом другого типа {x: 0}), нам нужно убедиться, что инвалидированный код больше не будет выполнен при вызове f2.
Таким образом, при дезоптимизации V8 раньше выполнял итерацию по всем оптимизированным JavaScript функциям и разрывал связь для тех, которые указывали на дезоптимизированный объект кода. Эта итерация в приложениях с большим количеством оптимизированных JavaScript функций становилась узким местом для производительности. Кроме того, помимо замедления дезоптимизации, V8 также раньше выполнял итерацию по этим спискам во время stop-the-world циклов сборщика мусора, что делало ситуацию еще хуже.
Чтобы оценить влияние такой структуры данных на производительность V8, мы написали микробенчмарк, который нагружает ее использование, вызывая множество циклов очистки после создания множества JavaScript функций.
function g() {
return (i) => i + 1;
}
// Создать начальное замыкание и оптимизировать.
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// Создать 2М замыканий; они получат ранее оптимизированный код.
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// Теперь вызвать сборки; все они будут медленными.
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
При запуске этого теста мы могли наблюдать, что V8 тратил около 98% времени выполнения на сборку мусора. Затем мы удалили эту структуру данных и вместо этого использовали подход для ленивой отвязки, и вот что мы наблюдали на x64:

Хотя это всего лишь микротест, который создает множество функций JavaScript и вызывает множество циклов сборки мусора, он дает нам представление о накладных расходах, вносимых этой структурой данных. Другие, более реалистичные приложения, где мы видели некоторую нагрузку и которые мотивировали эту работу, включают тест маршрутизатора, реализованный в Node.js, и ARES-6 benchmark suite.
Ленивая отвязка
Вместо того чтобы отвязывать оптимизированный код от функций JavaScript при деоптимизации, V8 откладывает это до следующего вызова таких функций. Когда такие функции вызываются, V8 проверяет, были ли они деоптимизированы, отвязывает их, а затем продолжает их ленивую компиляцию. Если эти функции больше никогда не будут вызваны, то они никогда не будут отвязаны, и деоптимизированные объекты кода не будут собраны. Однако, учитывая, что во время деоптимизации мы аннулируем все встроенные поля объекта кода, мы сохраняем этот объект кода активным.
Коммит, удаливший этот список оптимизированных функций JavaScript, потребовал изменений в нескольких частях виртуальной машины, но основная идея такова. При сборке оптимизированного объекта кода мы проверяем, является ли это кодом функции JavaScript. Если да, то в его прологе мы собираем машинный код для выхода из режима, если объект кода был деоптимизирован. При деоптимизации мы не модифицируем деоптимизированный код — правка кода отсутствует. Таким образом, его бит marked_for_deoptimization остается установленным при повторном вызове функции. TurboFan генерирует код для проверки этого бита, и если он установлен, V8 передает управление новому встроенному объекту CompileLazyDeoptimizedCode, который отвязывает деоптимизированный код от функции JavaScript, а затем продолжает ленивую компиляцию.
Более подробно, первый шаг заключается в генерации инструкций, которые загружают адрес кода, который в данный момент собирается. Мы можем сделать это на x64 с помощью следующего кода:
Label current;
// Загрузить эффективный адрес текущей инструкции в rcx.
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
После этого нам нужно определить, где в объекте кода находится бит marked_for_deoptimization.
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
Затем мы можем проверить бит, и если он установлен, мы переходим на встроенный объект CompileLazyDeoptimizedCode.
// Проверить, установлен ли бит, то есть отмечен ли код для деоптимизации.
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// Переход к встроенному объекту, если он установлен.
__ j(not_zero, /* handle to builtin code here */, RelocInfo::CODE_TARGET);
На стороне этого встроенного объекта CompileLazyDeoptimizedCode остается только отвязать поле кода от функции JavaScript и назначить его трамплину для входа в интерпретатор. Таким образом, учитывая, что адрес функции JavaScript находится в регистре rdi, мы можем получить указатель на SharedFunctionInfo с помощью:
// Чтение поля для получения SharedFunctionInfo.
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
...и аналогично для трамплина:
// Чтение поля для получения объекта кода.
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
Затем мы можем использовать его для обновления слота функции указателя на код:
// Обновить поле кода функции трамплином.
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// Барьер записи для защиты поля.
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
Это дает тот же результат, что и раньше. Однако вместо того, чтобы заботиться об отвязке в Deoptimizer, нужно учитывать это во время генерации кода. Поэтому и требуется написание кода вручную.
Выше представлено, как это работает в архитектуре x64. Мы реализовали это для ia32, arm, arm64, mips и mips64.
Этот новый метод уже интегрирован в V8, и, как мы обсудим позже, он обеспечивает улучшение производительности. Однако есть небольшой недостаток: ранее V8 рассматривал возможность отмены связи только при деоптимизации. Теперь это необходимо при активации всех оптимизированных функций. Кроме того, подход к проверке бита marked_for_deoptimization менее эффективен, чем может быть, поскольку требуется выполнить определенные операции для получения адреса объекта кода. Учтите, что это происходит при входе в каждую оптимизированную функцию. Возможным решением этой проблемы является сохранение в объекте кода указателя на самого себя. Вместо выполнения работы для поиска адреса объекта кода при каждом вызове функции V8 будет делать это только один раз, после его создания.
Результаты
Теперь мы рассмотрим улучшения производительности и регрессии, полученные в рамках этого проекта.
Общие улучшения на x64
Следующий график показывает нам некоторые улучшения и регрессии по сравнению с предыдущей версией. Учтите, чем выше, тем лучше.
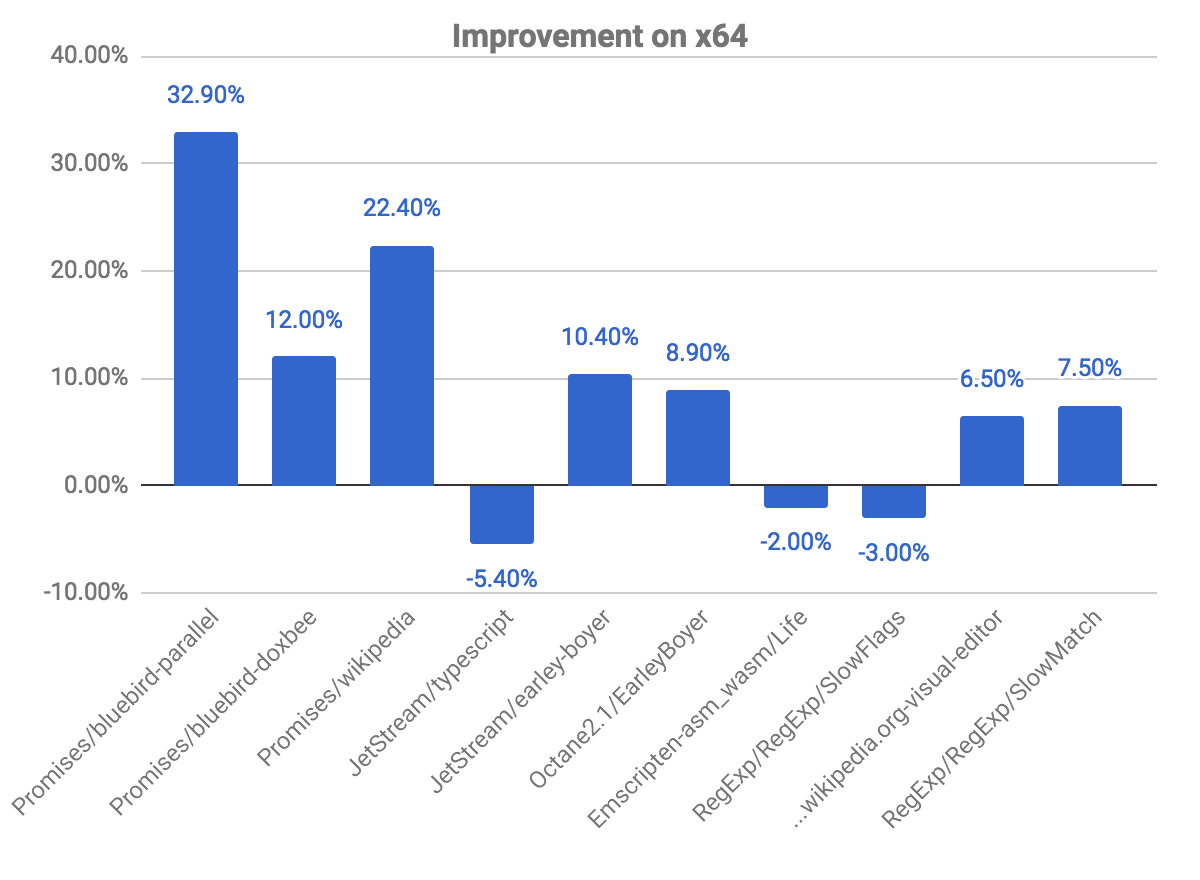
Бенчмарки для promises — это те, где мы наблюдаем наибольшие улучшения, почти 33% прироста для теста bluebird-parallel и 22.40% для wikipedia. Мы также зафиксировали несколько регрессий в некоторых бенчмарках. Это связано с упомянутой выше проблемой проверки кода на факт маркировки для деоптимизации.
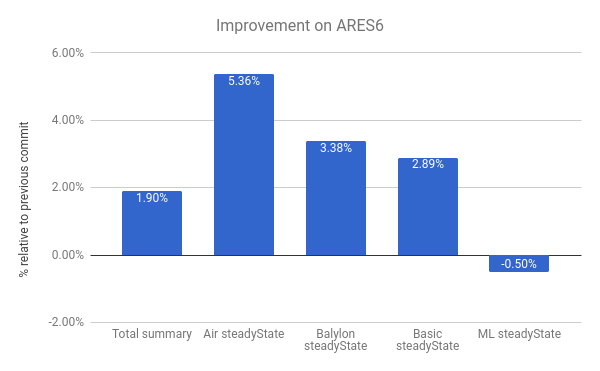
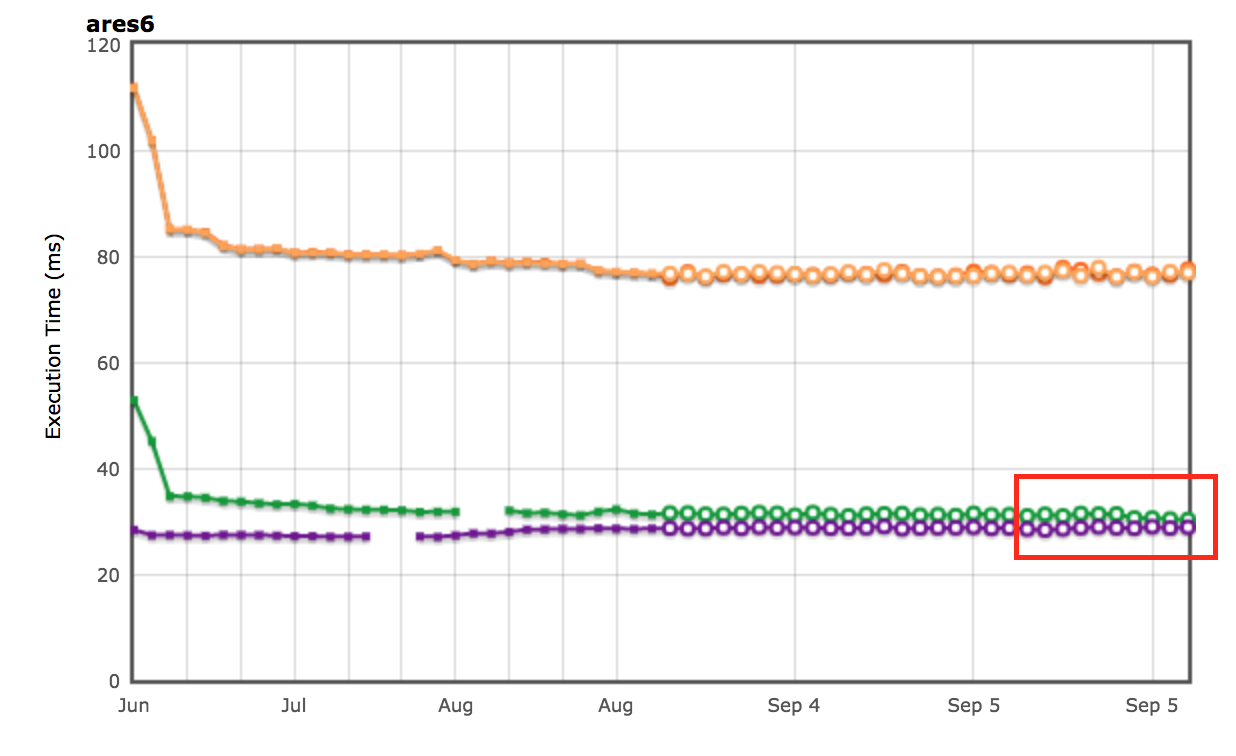
Мы также наблюдаем улучшения в наборе бенчмарков ARES-6. Обратите внимание, что на этом графике тоже — чем выше, тем лучше. Эти программы раньше тратили значительное время на операции, связанные с GC. С использованием ленивой отмены связи мы смогли улучшить производительность на 1.9% в целом. Самый заметный случай — Air steadyState, где мы получили улучшение примерно на 5.36%.
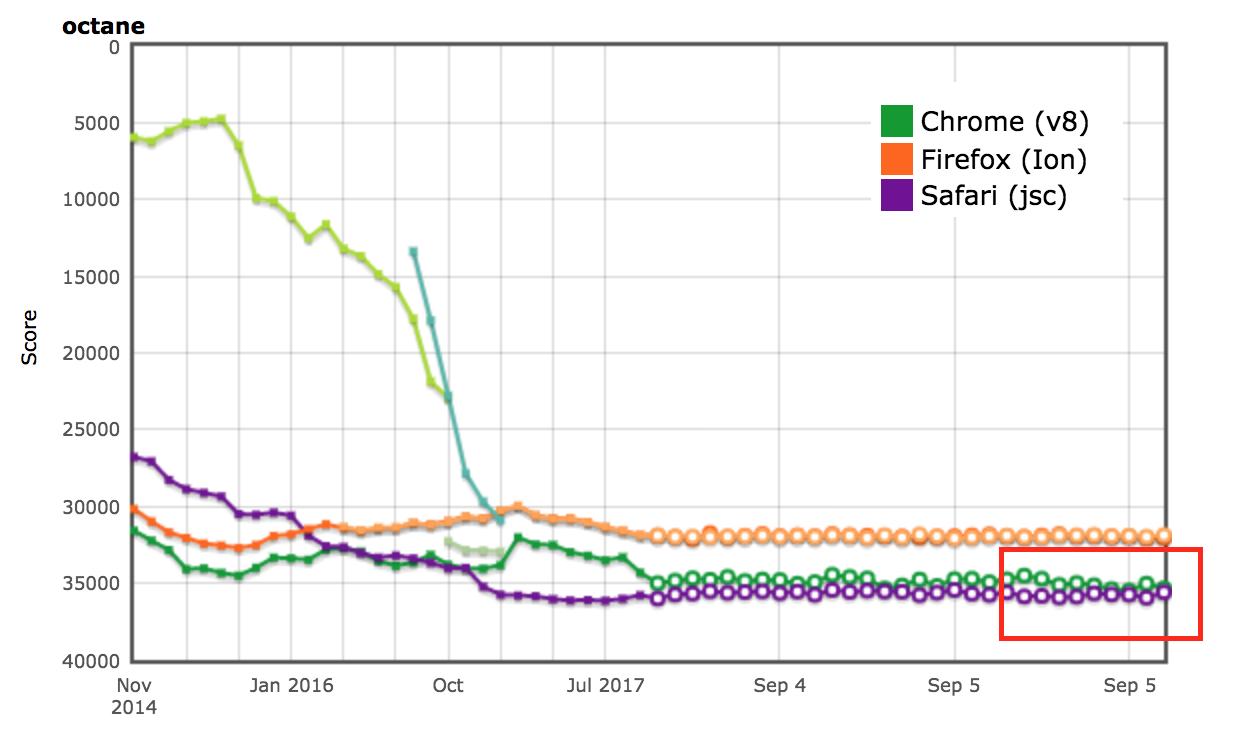
Результаты AreWeFastYet
Результаты производительности для наборов бенчмарков Octane и ARES-6 также появились в трекере AreWeFastYet. Мы изучили эти результаты производительности 5 сентября 2017 года, используя предоставленную стандартную машину (macOS 10.10 64-bit, Mac Pro, shell).
Влияние на Node.js
Мы также можем наблюдать улучшение производительности в router-benchmark. Следующие два графика показывают количество операций в секунду для каждого протестированного маршрутизатора. Таким образом, чем выше, тем лучше. Мы провели два вида экспериментов с этим набором тестов. Во-первых, мы запускали каждый тест изолированно, чтобы увидеть улучшение производительности независимо от остальных тестов. Во-вторых, мы запускали все тесты одновременно, не перезагружая виртуальную машину, моделируя среду, где каждый тест интегрирован с другими функциональностями.
В первом эксперименте мы обнаружили, что тесты router и express выполняют примерно в два раза больше операций, чем раньше, за то же время. Во втором эксперименте мы наблюдали еще более значительное улучшение. В некоторых случаях, таких как routr, server-router и router, бенчмарк выполняет приблизительно 3.80×, 3× и 2× больше операций соответственно. Это происходит потому, что V8 накапливает больше оптимизированных JavaScript функций тест за тестом. Таким образом, при выполнении данного теста, если запускается цикл сборки мусора, V8 должен обойти оптимизированные функции как текущего теста, так и предыдущих.


Последующая оптимизация
Теперь, когда V8 больше не хранит связный список функций JavaScript в контексте, мы можем удалить поле next из класса JSFunction. Хотя это простая модификация, она позволяет нам экономить размер указателя на каждую функцию, что представляет собой значительные сбережения в нескольких веб-страницах:
| Бенчмарк | Вид | Экономия памяти (абсолютная) | Экономия памяти (относительная) |
|---|---|---|---|
| facebook.com | Средний эффективный размер | 170 КБ | 3.70% |
| twitter.com | Средний размер выделенных объектов | 284 КБ | 1.20% |
| cnn.com | Средний размер выделенных объектов | 788 КБ | 1.53% |
| youtube.com | Средний размер выделенных объектов | 129 КБ | 0.79% |
Благодарности
На протяжении всей моей стажировки мне помогало множество людей, которые всегда были готовы ответить на мои многочисленные вопросы. Поэтому я хотел бы выразить благодарность следующим людям: Бенедикту Мойреру, Ярославу Шевчику и Майклу Старзингеру за обсуждения по поводу работы компилятора и деоптимизатора, Улану Дегенбаеву за помощь с сборщиком мусора, когда я его ломал, а также Матиасу Байненсу, Питеру Маршаллу, Камилло Бруни и Майе Армяновой за корректировку данной статьи.
И наконец, эта статья является моим последним вкладом в качестве стажера Google, и я хотел бы воспользоваться возможностью поблагодарить всех в команде V8, особенно моего наставника Бенедикта Мойрера, за то, что он принимал меня и предоставил мне возможность работать над таким интересным проектом — я определенно многому научился и получил удовольствие от работы в Google!