Быстрый `for`-`in` в V8
for-in — это широко используемая языковая конструкция, присутствующая во многих фреймворках. Несмотря на свою распространенность, с точки зрения реализации, это одна из наиболее сложных конструкций. V8 приложил большие усилия, чтобы сделать эту функциональность максимально быстрой. За последний год for-in стал полностью совместим со спецификацией и до 3 раз быстрее в зависимости от контекста.
Многие популярные сайты активно используют for-in и выигрывают от его оптимизации. Например, в начале 2016 года Facebook тратил примерно 7% всего времени выполнения JavaScript при запуске на реализацию самого for-in. Для Wikipedia эта цифра была еще выше — около 8%. Улучшив производительность определённых медленных случаев, Chrome 51 значительно повысил производительность этих двух сайтов:


Wikipedia и Facebook оба уменьшили общее время выполнения скриптов на 4% благодаря различным улучшениям for-in. Заметьте, что за тот же период остальные части V8 также стали быстрее, благодаря чему общий прирост производительности составил более 4%.
В остальной части этого блога мы объясним, как нам удалось ускорить эту ключевую языковую функцию и одновременно устранить давнее нарушение спецификации.
Спецификация
TL;DR; Семантика итерации в for-in неоднозначна по причинам производительности.
Если взглянуть на текст спецификации for-in, он написан неожиданно расплывчато, что заметно в различных реализациях. Рассмотрим пример, когда происходит итерация через объект Proxy с установленными ловушками.
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
В V8/Chrome 56 вывод будет следующим:
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
А в Firefox 51 для того же фрагмента код вывод будет другим:
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
Оба браузера соблюдают спецификацию, но в данном случае спецификация не задает строгий порядок инструкций. Чтобы правильно понять эти лазейки, взглянем на текст спецификации:
EnumerateObjectProperties ( O ) Когда абстрактная операция EnumerateObjectProperties вызывается с аргументом O, выполняются следующие шаги:
- Утверждение: Тип(O) — Object.
- Возвращается объект итератора (25.1.1.2), метод next которого выполняет итерацию всех строковых ключей перечисляемых свойств O. Объект итератора никогда не доступен напрямую для кода ECMAScript. Механика и порядок перечисления свойств не определены, но должны соответствовать указанным ниже правилам.
Обычно инструкции в спецификации точны и указывают, в каких именно шагах нужно выполнять. Но в этом случае они ссылаются на простой список текста, и даже порядок выполнения оставлен на усмотрение разработчиков. Это, как правило, происходит в тех случаях, когда части спецификации пишутся постфактум, а движки JavaScript уже имеют различные реализации. Спецификация пытается связать эти несоответствия, предоставляя следующие инструкции:
- Методы throw и return итератора равны null и никогда не вызываются.
- Метод next итератора обрабатывает свойства объекта, чтобы определить, нужно ли возвращать ключ свойства как значение итератора.
- Возвращаемые ключи свойств не включают ключи, являющиеся символами.
- Свойства целевого объекта могут быть удалены во время перечисления.
- Свойства, которые удалены до обработки методом next итератора, игнорируются. Если новые свойства добавлены в целевой объект во время перечисления, нет гарантии, что они будут обработаны в активном перечислении.
- Имя свойства будет возвращено методом next итератора не более одного раза за итерацию.
- Перечисление свойств целевого объекта включает перечисление свойств его прототипа и прототипа прототипа и так далее, рекурсивно; но свойство прототипа не обрабатывается, если оно имеет то же имя, что и свойство, которое уже было обработано методом next итератора.
- Значения атрибутов
[[Enumerable]]не учитываются при определении того, был ли уже обработан какой-либо объект свойства прототипа. - Имена перечисляемых свойств объектов прототипа должны быть получены путем вызова EnumerateObjectProperties с передачей объекта прототипа в качестве аргумента.
- EnumerateObjectProperties должен получать собственные ключи свойств целевого объекта, вызывая его внутренний метод
[[OwnPropertyKeys]].
Эти шаги звучат утомительно, однако в спецификации также содержится пример реализации, который является явным и гораздо более читаемым:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
Теперь, дойдя до этого момента, вы могли заметить из предыдущего примера, что V8 не точно следует примерной реализации спецификации. Во-первых, пример генератора for-in работает постепенно, в то время как V8 собирает все ключи заранее — в основном по причинам производительности. Это совершенно нормально, и на самом деле текст спецификации прямо заявляет, что порядок операций A - J не определен. Тем не менее, как вы узнаете позднее в этом посте, есть некоторые крайние случаи, когда V8 не полностью соблюдал спецификацию до 2016 года.
Кэш перечислений
Пример реализации генератора for-in следует постепенному образцу сбора и вывода ключей. В V8 ключи свойств собираются на первом этапе и используются только затем в фазе итерации. Для V8 это упрощает несколько вещей. Чтобы понять, почему, нам нужно взглянуть на модель объекта.
Простой объект, такой как {a:'value a', b:'value b', c:'value c'}, может иметь различные внутренние представления в V8, как мы покажем в детальном последующем посте о свойствах. Это означает, что в зависимости от того, какой тип свойств у нас есть — расположенные внутри объекта, быстрые или медленные — фактические имена свойств хранятся в разных местах. Это делает сбор перечисляемых ключей непростым делом.
V8 отслеживает структуру объекта с помощью скрытого класса или так называемой карты (Map). Объекты с одной и той же картой имеют одну и ту же структуру. Кроме того, каждая карта имеет совместно используемую структуру данных — массив дескрипторов, который содержит подробности о каждом свойстве, такие как местоположение хранения свойств на объекте, имя свойства и такие подробности, как его перечисляемость.
Предположим на мгновение, что наш JavaScript объект достиг своей окончательной формы и никаких дополнительных свойств не будет добавлено или удалено. В этом случае мы могли бы использовать массив дескрипторов как источник для ключей. Это работает, если есть только перечисляемые свойства. Чтобы избежать дополнительных расходов на фильтрацию неперечисляемых свойств каждый раз, V8 использует отдельный EnumCache, доступный через массив дескрипторов карты.

Учитывая, что V8 ожидает, что медленные объекты-словари часто изменяются (например, путем добавления и удаления свойств), для медленных объектов со свойствами словаря не существует массива дескрипторов. Таким образом, V8 не предоставляет EnumCache для медленных свойств. Подобные предположения применяются к индексированным свойствам, и, как следствие, они также исключены из EnumCache.
Давайте суммируем важные факты:
- Карты используются для отслеживания форм объектов.
- Массивы дескрипторов хранят информацию о свойствах (имя, конфигурируемость, видимость).
- Массивы дескрипторов могут быть общими между картами.
- Каждый массив дескрипторов может иметь EnumCache, содержащий только перечисляемые именованные ключи, но не имена индексированных свойств.
Механика for-in
Теперь вы частично знаете, как работают карты и как EnumCache связан с массивом дескрипторов. V8 выполняет JavaScript через Ignition, интерпретатор байт-кода, и TurboFan, оптимизирующий компилятор, которые обрабатывают for-in схожими способами. Для простоты мы будем использовать псевдо-C++ стиль, чтобы объяснить, как for-in реализован внутренне:
// Подготовка для For-In:
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// Тело For-In:
for (size_t i = 0; i < keys->length(); i++) {
// Следующий For-In:
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
For-In можно разделить на три основные этапа:
- Подготовка ключей для итерации,
- Получение следующего ключа,
- Оценка тела
for-in.
"Подготовка" - самый сложный шаг из этих трех, и именно здесь вступает в игру EnumCache. В приведенном выше примере можно увидеть, что V8 напрямую использует EnumCache, если он существует и если на объекте (и его прототипе) нет элементов (свойств с целочисленными индексами). В случае, если существуют именованные свойства с индексами, V8 переходит к функции выполнения, реализованной на С++, которая добавляет их к существующему кэшу перечислений, как показано в следующем примере:
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// Получить ключи перечислимых свойств из, возможно, общего кэша перечислений
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements);
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// Вставить ключи свойств в конец.
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
В случае, когда существующий EnumCache не был найден, мы снова переходим к С++ и следуем шагам, представленным в начальной спецификации:
FixedArray* JSObject::GetEnumKeys() {
// Получить ключи перечислений получателя.
FixedArray* keys = this->GetOwnEnumKeys();
// Пройти по цепочке прототипов.
for (JSObject* object : GetPrototypeIterator()) {
// Добавить неповторяющиеся ключи в список.
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
Этот упрощенный C++ код соответствует реализации в V8 до начала 2016 года, когда мы начали анализировать метод UnionOfKeys. Если вы внимательно посмотрите, вы заметите, что мы использовали наивный алгоритм для исключения дубликатов из списка, что может привести к плохой производительности, если у нас много ключей в цепочке прототипов. Так мы решили продолжить оптимизации в следующем разделе.
Проблемы с for-in
Как мы уже упомянули в предыдущем разделе, метод UnionOfKeys имеет плохую худшую производительность. Он был основан на обоснованном предположении, что большинство объектов имеют быстрые свойства и, следовательно, будут использовать кэш EnumCache. Второе предположение заключалось в том, что в цепочке прототипов имеется лишь несколько перечислимых свойств, что ограничивает время, затрачиваемое на поиск дубликатов. Однако, если объект имеет медленные свойства словаря и множество ключей в цепочке прототипов, UnionOfKeys становится узким местом, так как нам приходится собирать имена перечислимых свойств каждый раз, когда мы используем for-in.
Кроме проблем с производительностью, у существующего алгоритма была еще одна проблема — несоответствие спецификации. V8 в течение многих лет неверно обрабатывал следующий пример:
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
Вывод:
a
b
Вопреки интуиции, этот код должен выводить только a, а не a и b. Если вы вспомните текст спецификации в начале этой статьи, шаги G и J подразумевают, что несчислимые свойства в принимающем объекте перекрывают свойства в цепочке прототипов.
Чтобы усложнить задачу, ES6 представил объект Proxy. Это сломало множество предположений в коде V8. Для реализации for-in в соответствии со спецификацией нам нужно вызвать следующие 5 из 13 разных ловушек прокси.
| Внутренний метод | Метод обработчика |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
Это потребовало создания дублированной версии исходного кода GetEnumKeys, чтобы более точно следовать примерной реализации в спецификации. Прокси ES6 и отсутствие обработки маскирующих свойств стали основной мотивацией для нас переработать способ извлечения всех ключей для цикла for-in в начале 2016 года.
KeyAccumulator
Мы представили отдельный вспомогательный класс KeyAccumulator, который справлялся со сложностями сбора ключей для for-in. С ростом спецификации ES6, новые функции, такие как Object.keys или Reflect.ownKeys, потребовали своих собственных слегка модифицированных версий сбора ключей. Наличие одного конфигурируемого места позволило улучшить производительность for-in и избежать дублирования кода.
KeyAccumulator состоит из быстрой части, которая поддерживает ограниченный набор действий, но способна выполнять их очень эффективно. Медленный накопитель поддерживает все сложные случаи, такие как прокси ES6.

Для правильной фильтрации маскирующих свойств мы должны поддерживать отдельный список ненумеруемых свойств, которые мы увидели до сих пор. По соображениям производительности мы делаем это только после того, как выясняется, что в цепочке прототипов объекта есть нумеруемые свойства.
Улучшения производительности
С появлением KeyAccumulator стало возможно оптимизировать еще несколько схем. Первым шагом было устранение вложенного цикла оригинального метода UnionOfKeys, который вызывал медленные граничные случаи. На втором этапе мы провели более детальные предварительные проверки, чтобы использовать существующие EnumCaches и избежать ненужных шагов копирования.
Чтобы показать, что реализация, соответствующая спецификации, является более быстрой, давайте рассмотрим следующие четыре различных объекта:
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
- Объект
fastPropertiesимеет стандартные быстрые свойства. - Объект
fastPropertiesWithPrototypeимеет дополнительные ненумеруемые свойства в цепочке прототипов через использованиеObject.prototype. - Объект
slowPropertiesимеет медленные свойства словаря. - Объект
elementsимеет только индексированные свойства.
Следующий график сравнивает исходную производительность выполнения цикла for-in миллион раз в быстром цикле без помощи нашего оптимизирующего компилятора.
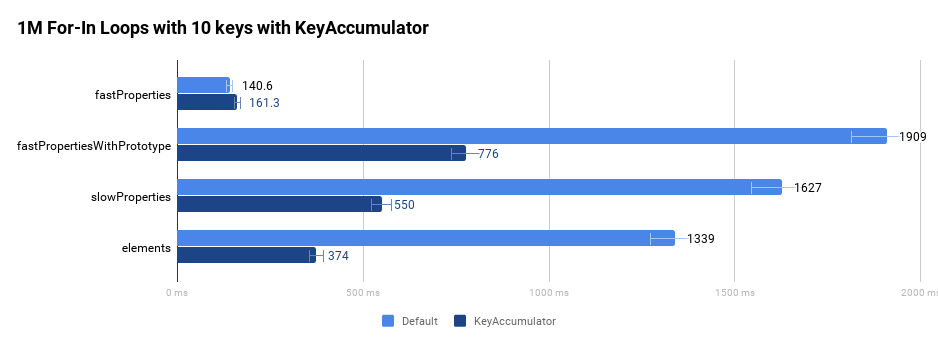
Как мы упомянули во введении, эти улучшения стали особенно заметны на таких сайтах, как Wikipedia и Facebook.
Помимо первоначальных улучшений, доступных в Chrome 51, вторая оптимизация производительности принесла еще одно значительное улучшение. Следующий график показывает наши данные о времени, потраченном на выполнение сценариев при запуске страницы Facebook. Выбранный диапазон вокруг ревизии V8 37937 соответствует дополнительному приросту производительности на 4%!

Чтобы подчеркнуть важность улучшения for-in, можно опереться на данные из инструмента, разработанного нами в 2016 году, который позволяет извлекать измерения V8 на основе набора веб-сайтов. Следующая таблица показывает относительное время, затраченное на точки входа V8 C++ (функции выполнения и встроенные функции) для Chrome 49 на основе примерно 25 репрезентативных реальных веб-сайтов.
| Позиция | Имя | Всего времени |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |