Покрытие кода JavaScript
Покрытие кода предоставляет информацию о том, были ли определённые части приложения выполнены и, при необходимости, как часто. Оно обычно используется для определения того, насколько тщательно тестовый набор проверяет конкретную кодовую базу.
Зачем это полезно?
Как разработчик JavaScript, вы часто можете оказаться в ситуации, когда покрытие кода может быть полезным. Например:
- Интересует качество вашего набора тестов? Рефакторите большой проект с наследием? Покрытие кода может показать вам, какие части вашей кодовой базы покрыты.
- Хотите быстро узнать, достигнута ли определённая часть кодовой базы? Вместо того, чтобы инструментировать с помощью
console.logдля отладки в стилеprintfили вручную проходить по коду, покрытие кода может отображать информацию в реальном времени о том, какие части вашего приложения были выполнены. - Или, возможно, вы оптимизируете скорость и хотите знать, на каких частях сосредоточиться? Счётчики выполнения могут указать горячие функции и циклы.
Покрытие кода JavaScript в V8
В начале этого года мы добавили встроенную поддержку покрытия кода JavaScript в V8. Первоначальный выпуск, версия 5.9, предоставил покрытие на уровне функций (показывая, какие функции были выполнены), что позже было расширено для поддержки покрытия на уровне блоков в версии 6.2 (аналогично, но для индивидуальных выражений).
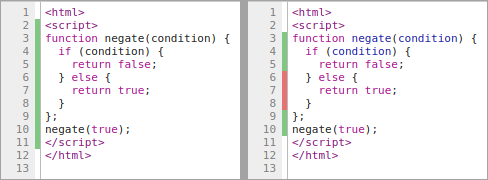
Для разработчиков JavaScript
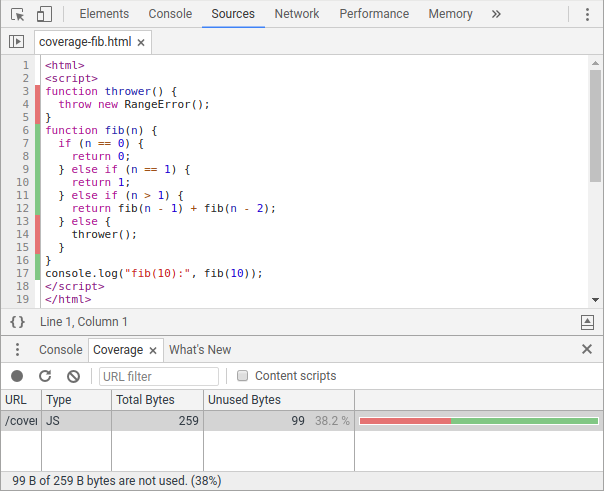
На данный момент есть два основных способа доступа к информации о покрытии. Для разработчиков JavaScript вкладка Coverage в Chrome DevTools позволяет узнать соотношение покрытия JS (и CSS) и выделяет мёртвый код в панели Источников.
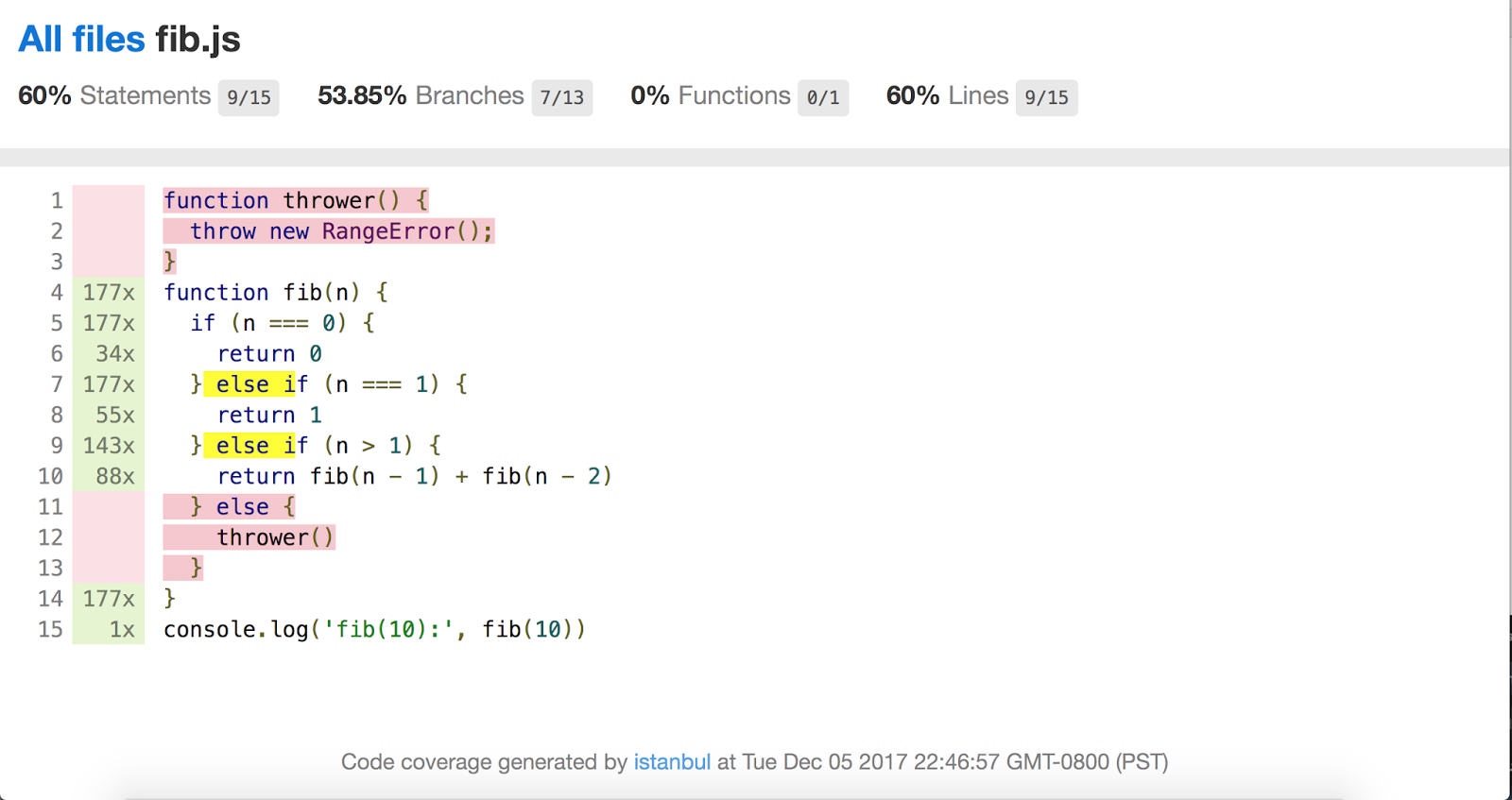
Благодаря Бенджамину Ко, также ведётся активная работа по интеграции информации о покрытии кода V8 в популярный инструмент покрытия Istanbul.js.
Для встраиваемых приложений
Встраиваемые приложения и авторы фреймворков могут напрямую подключаться к API Inspector для большей гибкости. V8 предлагает два различных режима покрытия:
-
Покрытие с наилучшим усилием собирает информацию о покрытии с минимальным влиянием на производительность, но может терять данные о функциях, собранных сборщиком мусора (GC).
-
Точное покрытие гарантирует, что данные не будут потеряны при GC, и пользователи могут выбрать получение счётчиков выполнения вместо бинарной информации о покрытии; однако производительность может пострадать из-за увеличенного накладных расходов (см. следующий раздел для более детальной информации). Точное покрытие может собираться как на уровне функций, так и блоков.
API Inspector для точного покрытия выглядит следующим образом:
-
Profiler.startPreciseCoverage(callCount, detailed)включает сбор данных о покрытии, при необходимости со счётчиками вызовов (вместо бинарного покрытия) и гранулярностью блоков (вместо функций); -
Profiler.takePreciseCoverage()возвращает собранную информацию о покрытии в виде списка исходных диапазонов с ассоциированными счётчиками выполнений; и -
Profiler.stopPreciseCoverage()отключает сбор данных и освобождает связанные структуры.
Разговор через протокол Inspector может выглядеть следующим образом:
// Встраивающий модуль указывает V8 начать сбор точного покрытия.
{ "id": 26, "method": "Profiler.startPreciseCoverage",
"params": { "callCount": false, "detailed": true }}
// Встраивающий модуль запрашивает данные о покрытии (с момента последнего запроса).
{ "id": 32, "method":"Profiler.takePreciseCoverage" }
// Ответ содержит коллекцию вложенных исходных диапазонов.
{ "id": 32, "result": { "result": [{
"functions": [
{
"functionName": "fib",
"isBlockCoverage": true, // Гранулярность блоков.
"ranges": [ // Массив вложенных диапазонов.
{
"startOffset": 50, // Смещение в байтах, включительно.
"endOffset": 224, // Смещение в байтах, исключая.
"count": 1
}, {
"startOffset": 97,
"endOffset": 107,
"count": 0
}, {
"startOffset": 134,
"endOffset": 144,
"count": 0
}, {
"startOffset": 192,
"endOffset": 223,
"count": 0
},
]},
"scriptId": "199",
"url": "file:///coverage-fib.html"
}
]
}}
// В конце встраиватель инструктирует V8 завершить сбор и
// освободить связанные структуры данных.
{"id":37,"method":"Profiler.stopPreciseCoverage"}
Аналогично, покрытие «по мере возможности» можно получить, используя Profiler.getBestEffortCoverage().
За кулисами
Как упоминалось в предыдущем разделе, V8 поддерживает два основных режима замера покрытия кода: «по мере возможности» и точное покрытие. Далее следует обзор их реализации.
Покрытие по мере возможности
Оба режима — и «по мере возможности», и точное покрытие — в значительной степени используют другие механизмы V8, первый из которых называется счетчиком вызовов. Каждый раз, когда функция вызывается через интерпретатор Ignition в V8, мы увеличиваем счетчик вызовов в ее векторе обратной связи. Когда функция начинает чаще вызываться и «повышается» через оптимизирующий компилятор, этот счетчик помогает принимать решения о встраивании функций. Теперь мы также используем его для составления отчета о покрытии кода.
Второй используемый механизм определяет диапазон исходного кода функций. При составлении отчета о покрытии кода необходимо связать количество вызовов с определенным диапазоном в исходном файле. Например, в приведенном ниже примере необходимо не только сообщить, что функция f была вызвана ровно один раз, но и отметить, что диапазон исходного кода функции f начинается с 1-й строки и заканчивается на 3-й.
function f() {
console.log('Привет, мир');
}
f();
Нам снова повезло, и мы смогли повторно использовать существующую информацию в V8. Функции уже знали свои начальные и конечные позиции в исходном коде благодаря Function.prototype.toString, который определяет местоположение функции в исходном файле для извлечения соответствующей подстроки.
При сборе покрытия «по мере возможности» эти два механизма просто связываются: сначала мы находим все живые функции, проходя по всей куче. Для каждой найденной функции мы сообщаем количество вызовов (хранящееся в векторе обратной связи, который мы можем получить из функции) и диапазон исходного кода (удобно хранящийся в самой функции).
Обратите внимание, что поскольку счетчики вызовов ведутся независимо от того, включено покрытие или нет, покрытие «по мере возможности» не вызывает дополнительной нагрузки во время выполнения. Оно также не использует отдельные структуры данных и не требует явного включения или отключения.
Так почему этот режим называется «по мере возможности»? Какие у него ограничения? Функции, которые выходят из области, могут быть освобождены сборщиком мусора. Это означает, что связанные счетчики вызовов теряются, и, по сути, мы полностью забываем, что эти функции когда-либо существовали. Отсюда и название: «по мере возможности». Даже несмотря на наши старания, собранная информация о покрытии может быть неполной.
Точное покрытие (гранулярность на уровне функции)
В отличие от режима «по мере возможности», точное покрытие гарантирует, что предоставленная информация о покрытии является полной. Для этого мы добавляем все векторы обратной связи в корневой набор ссылок V8 при включении точного покрытия, предотвращая их сбор сборщиком мусора. Хотя это позволяет сохранить всю информацию, это увеличивает объем памяти, удерживая объекты искусственно.
Режим точного покрытия также может предоставлять количество выполнений. Это добавляет сложности в реализацию точного покрытия. Помните, что счетчик вызовов увеличивается каждый раз, когда функция вызывается через интерпретатор V8, и что функции могут быть оптимизированы, когда они становятся часто вызываемыми. Но оптимизированные функции больше не увеличивают свой счетчик вызовов, и поэтому оптимизирующий компилятор должен быть отключен, чтобы сохранить точное количество выполнений.
Точное покрытие (гранулярность на уровне блока)
Покрытие на уровне блока должно быть точным до отдельных выражений. Например, в следующем коде покрытие на уровне блока может определить, что ветвь else в условном выражении : c никогда не выполняется, тогда как покрытие на уровне всей функции будет учитывать только, что функция f в целом покрыта.
function f(a) {
return a ? b : c;
}
f(true);
Вы можете вспомнить из предыдущих разделов, что у нас уже были доступные подсчеты вызовов функций и диапазоны исходного кода в V8. К сожалению, это было не так в случае покрытия блоков, и нам пришлось внедрить новые механизмы для сбора как количества выполнений, так и соответствующих диапазонов исходного кода.
Первым аспектом являются диапазоны исходного кода: предполагая, что у нас есть количество выполнений для конкретного блока, как мы можем сопоставить их с частью исходного кода? Для этого нам нужно собирать соответствующие позиции при синтаксическом анализе исходных файлов. До покрытия блоков V8 уже делал это в некоторой степени. Один пример — это сбор диапазонов функций из-за Function.prototype.toString, как описано выше. Другой пример — использование исходных позиций для создания обратного трассирования для объектов ошибок. Но ни один из этих подходов не является достаточным для поддержки покрытия блоков; первый доступен только для функций, а второй хранит только позиции (например, позицию токена if для конструкций if-else), а не диапазоны исходного кода.
Поэтому нам пришлось расширить парсер для сбора диапазонов исходного кода. Для демонстрации рассмотрим конструкцию if-else:
if (cond) {
/* Then branch. */
} else {
/* Else branch. */
}
Когда включено покрытие блоков, мы собираем диапазоны исходного кода для ветвей then и else и связываем их с разобранным узлом AST IfStatement. То же самое делается для других соответствующих языковых конструкций.
После сбора диапазонов исходного кода при синтаксическом анализе второй аспект заключается в отслеживании количества выполнений во время выполнения. Это достигается путем вставки нового специального байткода IncBlockCounter в стратегические позиции в массиве сгенерированных байткодов. Во время выполнения обработчик байткода IncBlockCounter просто увеличивает соответствующий счетчик (доступный через объект функции).
В приведенном выше примере конструкции if-else такие байткоды будут вставлены в три места: непосредственно перед телом ветви then, перед телом ветви else и сразу после конструкции if-else (такие счетчики продолжения необходимы из-за возможности неконтролируемого управления в ветви).
Наконец, отчетность о покрытии на уровне блоков работает аналогично отчетности на уровне функций. Но в дополнение к подсчетам вызовов (из вектора обратной связи) мы теперь также сообщаем о сборе интересных диапазонов исходного кода вместе с их подсчетами блоков (хранящимися в дополнительной структуре данных, связанной с функцией).
Если вы хотите узнать больше о технических деталях покрытия кода в V8, ознакомьтесь с документами по проектированию покрытия и покрытия блоков.
Заключение
Мы надеемся, что вам понравилось это краткое введение в поддержку нативного покрытия кода в V8. Попробуйте его и не стесняйтесь сообщать нам, что работает для вас, а что нет. Поздоровайтесь в Twitter (@schuay и @hashseed) или сообщите о проблеме на crbug.com/v8/new.
Поддержка покрытия в V8 была командным усилием, и мы хотим поблагодарить всех, кто внес свой вклад: Бенджамина Ко, Якоба Грубера, Янг Гуо, Марью Хётту, Андрея Козякова, Алексея Козятинского, Росса Маклроя, Али Шейха, Майкла Старзингера. Спасибо!