Turboalimentando o V8 com números de heap mutáveis
No V8, estamos constantemente buscando melhorar o desempenho do JavaScript. Como parte desse esforço, recentemente revisamos o conjunto de benchmarks JetStream2 para eliminar gargalos de desempenho. Este post detalha uma otimização específica que realizamos e que resultou em uma melhoria significativa de 2.5x no benchmark async-fs, contribuindo para um aumento perceptível na pontuação geral. A otimização foi inspirada pelo benchmark, mas padrões como esses aparecem em código do mundo real.
O benchmark async-fs, como o nome sugere, é uma implementação de sistema de arquivos em JavaScript, focando em operações assíncronas. No entanto, existe um surpreendente gargalo de desempenho: a implementação de Math.random. Ele usa uma implementação personalizada e determinística de Math.random para resultados consistentes entre execuções. A implementação é:
let seed;
Math.random = (function() {
return function () {
seed = ((seed + 0x7ed55d16) + (seed << 12)) & 0xffffffff;
seed = ((seed ^ 0xc761c23c) ^ (seed >>> 19)) & 0xffffffff;
seed = ((seed + 0x165667b1) + (seed << 5)) & 0xffffffff;
seed = ((seed + 0xd3a2646c) ^ (seed << 9)) & 0xffffffff;
seed = ((seed + 0xfd7046c5) + (seed << 3)) & 0xffffffff;
seed = ((seed ^ 0xb55a4f09) ^ (seed >>> 16)) & 0xffffffff;
return (seed & 0xfffffff) / 0x10000000;
};
})();
A variável chave aqui é seed. Ela é atualizada em cada chamada para Math.random, gerando a sequência pseudo-aleatória. Crucialmente, aqui seed é armazenado em um ScriptContext.
Um ScriptContext serve como um local de armazenamento para valores acessíveis dentro de um determinado script. Internamente, esse contexto é representado como um array de valores marcados do V8. Na configuração padrão do V8 para sistemas de 64 bits, cada um desses valores marcados ocupa 32 bits. O bit menos significativo de cada valor atua como uma marca. Um 0 indica um Inteiro Pequeno de 31 bits (SMI). O valor inteiro real é armazenado diretamente, deslocado para a esquerda por um bit. Um 1 indica um ponteiro comprimido para um objeto no heap, onde o valor do ponteiro comprimido é incrementado em um.

Essa marcação diferencia como os números são armazenados. SMIs residem diretamente no ScriptContext. Números maiores ou aqueles com partes decimais são armazenados indiretamente como objetos imutáveis HeapNumber no heap (um double de 64 bits), com o ScriptContext contendo um ponteiro comprimido para eles. Essa abordagem lida eficientemente com vários tipos numéricos enquanto otimiza para o caso comum de SMI.
O gargalo
O perfil de Math.random revelou dois grandes problemas de desempenho:
-
Alocação de
HeapNumber: O slot dedicado à variávelseedno contexto de script aponta para um padrãoHeapNumberimutável. Cada vez que a funçãoMath.randomatualizaseed, um novo objetoHeapNumberprecisa ser alocado no heap, resultando em significativa pressão de alocação e coleta de lixo. -
Aritmética de ponto flutuante: Embora os cálculos dentro de
Math.randomsejam fundamentalmente operações de inteiros (usando deslocamentos e adições bit a bit), o compilador não consegue tirar total vantagem disso. Comoseedé armazenado como umHeapNumbergenérico, o código gerado usa instruções mais lentas de ponto flutuante. O compilador não pode provar queseedsempre conterá um valor representável como um inteiro. Enquanto o compilador poderia potencialmente especular sobre intervalos de inteiros de 32 bits, o V8 foca principalmente emSMIs. Mesmo com a especulação sobre inteiros de 32 bits, uma conversão possivelmente custosa de ponto flutuante de 64 bits para inteiro de 32 bits, juntamente com uma verificação sem perdas, ainda seria necessária.
A solução
Para resolver esses problemas, implementamos uma otimização em duas partes:
-
Rastreamento de tipo de slot / slots mutáveis de número do heap: Estendemos o rastreamento de valor constante em contexto de script (variáveis
letque foram inicializadas mas nunca modificadas) para incluir informações de tipo. Rastreamos se o valor do slot é constante, umSMI, umHeapNumberou um valor genérico marcado. Também introduzimos o conceito de slots mutáveis de número do heap dentro dos contextos de script, semelhante aos campos mutáveis de número do heap paraJSObjects. Em vez de apontar para umHeapNumberimutável, o slot de contexto de script é o proprietário doHeapNumber, e seu endereço não deve vazar. Isso elimina a necessidade de alocar um novoHeapNumberpara cada atualização em código otimizado. O próprioHeapNumberé modificado localmente. -
Heap mutável
Int32: Aprimoramos os tipos de slots do contexto de script para rastrear se um valor numérico está dentro da faixaInt32. Se estiver, oHeapNumbermutável armazena o valor como umInt32bruto. Se necessário, a transição para umdoubletraz o benefício adicional de não requerer a realocação doHeapNumber. No caso deMath.random, o compilador agora pode observar queseedestá sendo consistentemente atualizado com operações de inteiros e marcar o slot como contendo umInt32mutável.

É importante notar que essas otimizações introduzem uma dependência de código do tipo do valor armazenado no slot de contexto. O código otimizado gerado pelo compilador JIT depende de o slot conter um tipo específico (neste caso, um Int32). Se algum código escrever um valor no slot seed que altere seu tipo (por exemplo, escrevendo um número de ponto flutuante ou uma string), o código otimizado precisará ser desotimizado. Essa desotimização é necessária para garantir a correção. Portanto, a estabilidade do tipo armazenado no slot é crucial para manter o desempenho máximo. No caso de Math.random, a máscara de bits no algoritmo garante que a variável seed sempre mantenha um valor Int32.
Os resultados
Essas alterações aceleram significativamente a peculiar função Math.random:
-
Sem alocações / atualizações rápidas no local: O valor
seedé atualizado diretamente dentro de seu slot mutável no contexto de script. Nenhum novo objeto é alocado durante a execução deMath.random. -
Operações de inteiros: O compilador, armado com o conhecimento de que o slot contém um
Int32, pode gerar instruções altamente otimizadas de inteiros (shifts, somas, etc.). Isso evita a sobrecarga da aritmética de ponto flutuante.
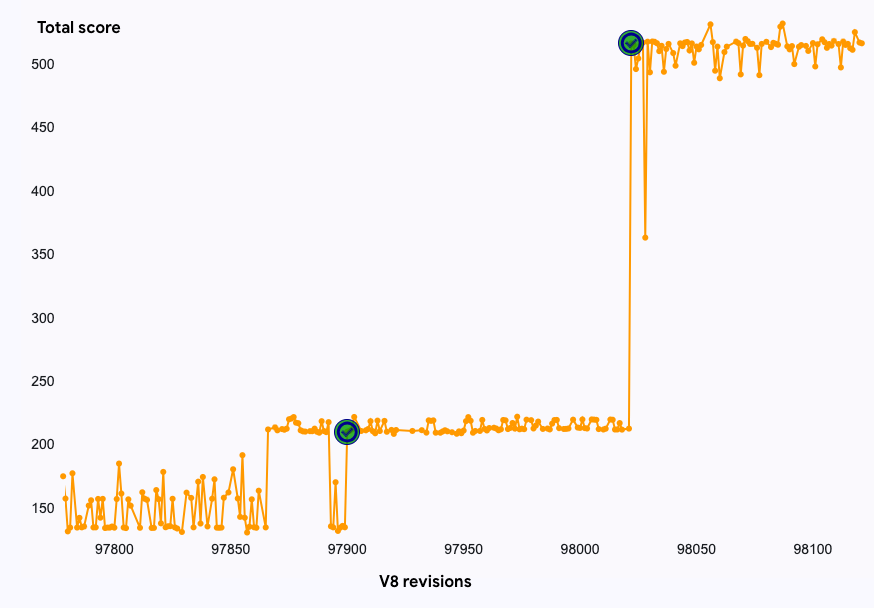
O efeito combinado dessas otimizações é um aumento notável de ~2.5x na velocidade do benchmark async-fs. Isso, por sua vez, contribui para uma melhoria de ~1.6% na pontuação geral do JetStream2. Isso demonstra que código aparentemente simples pode criar gargalos de desempenho inesperados, e que pequenas otimizações direcionadas podem ter um grande impacto não apenas para o benchmark.