Ускорение spread-элементов
Во время своей трехмесячной стажировки в команде V8 Хай Дан работал над улучшением производительности [...array], [...string], [...set], [...map.keys()] и [...map.values()] (когда spread-элементы находятся в начале литерала массива). Он также сделал Array.from(iterable) намного быстрее. Эта статья объясняет некоторые подробности его изменений, которые включены в V8, начиная с версии v7.2.
Spread-элементы
Spread-элементы — это компоненты литералов массивов в форме ...iterable. Они были введены в ES2015 для создания массивов из итерируемых объектов. Например, литерал массива [1, ...arr, 4, ...b] создает массив, первый элемент которого — 1, за которым следуют элементы массива arr, затем 4, и, наконец, элементы массива b:
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
Еще один пример: любая строка может быть преобразована в массив ее символов (кодовых точек Unicode):
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
Точно так же любое множество можно преобразовать в массив его элементов, упорядоченных по порядку добавления:
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
В общем случае синтаксис spread-элементов ...x в литерале массива предполагает, что x предоставляет итератор (доступный через x[Symbol.iterator]()). Этот итератор используется для получения элементов, которые будут вставлены в результирующий массив.
Простой случай использования spread-элемента для создания нового массива из массива arr без добавления дополнительных элементов — [...arr] — считается лаконичным, идиоматическим способом поверхностного клонирования arr в ES2015. К сожалению, в V8 производительность этого подхода значительно отставала от его аналога в ES5. Целью стажировки Хая было это изменить!
Почему spread-элементы были (или остаются!) медленными?
Существует множество способов поверхностного клонирования массива arr. Например, можно использовать arr.slice(), arr.concat() или [...arr]. Или написать свою функцию clone, которая использует стандартный for-цикл:
function clone(arr) {
// Предварительно выделить правильное количество элементов, чтобы избежать
// необходимости увеличивать массив.
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
В идеале, у всех этих вариантов должны быть схожие характеристики производительности. К сожалению, если вы выберете [...arr] в V8, он с вероятностью (или был) будет медленнее, чем clone! Причина в том, что V8 фактически транспилирует [...arr] в итерацию следующего вида:
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
Этот код, как правило, медленнее clone по нескольким причинам:
- В начале нужно создать
iterator, загрузив и вычислив свойствоSymbol.iterator. - На каждом шаге требуется создавать и работать с объектом
iteratorResult. - На каждом шаге выполнения итерации массив
resultрастет, вызываяpush, что приводит к неоднократной перераспределению памяти для сокрытия.
Причина использования такой реализации заключается в том, что, как было упомянуто ранее, spread может применяться не только к массивам, но и, фактически, к произвольным итерируемым объектам, и должен следовать протоколу итерации. Тем не менее, V8 должен быть достаточно умным, чтобы определить, что объект, распространяемый в массив, является массивом, и, таким образом, мог извлечь его элементы на более низком уровне и:
- избежать создания объекта итератора,
- избежать создания объектов результата итератора,
- избежать постоянного роста и перераспределения массива (мы знаем количество элементов заранее).
Мы реализовали эту простую идею с использованием CSA для быстрых массивов, то есть массивов с одним из шести наиболее распространенных типов элементов. Оптимизация применяется для общих реальных сценариев, где spread происходит в начале литерала массива, например, [...foo]. Как показано на графике ниже, этот новый быстрый путь обеспечивает примерно трехкратное улучшение производительности для массива длиной 100,000 элементов, что делает его примерно на 25% быстрее, чем написанный вручную цикл clone.
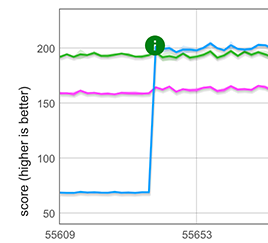
:::примечание
Примечание: Хотя это здесь не показано, быстрый путь также применяется, когда элементы разворачивания следуют за другими компонентами (например, [...arr, 1, 2, 3]), но не когда они предшествуют другим (например, [1, 2, 3, ...arr]).
:::
Осторожно идите по этому быстрому пути
Это явно впечатляющее ускорение, но мы должны быть очень осторожны в отношении того, когда это правильно использовать быстрый путь: JavaScript позволяет программисту изменять поведение итерации объектов (даже массивов) различными способами. Поскольку элементы разворачивания определены для использования протокола итерации, мы должны убедиться, что такие изменения уважаются. Мы делаем это, полностью избегая быстрого пути всякий раз, когда оригинальный механизм итерации был изменен. Например, это включает ситуации, подобные следующим.
Собственное свойство Symbol.iterator
Обычно массив arr не имеет собственного свойства Symbol.iterator, поэтому при поиске этого символа он будет найден на прототипе массива. В приведенном ниже примере прототип обходится, определяя свойство Symbol.iterator непосредственно для самого arr. После этого изменения, поиск Symbol.iterator для arr приводит к пустому итератору, и поэтому распространение arr не дает элементов, а литерал массива оценивается как пустой массив.
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
Изменённый %ArrayIteratorPrototype%
Метод next также можно изменить непосредственно на %ArrayIteratorPrototype%, прототипе итераторов массива (что влияет на все массивы).
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
Работа с массивами с дырками
Также требует особой осторожности копирование массивов с дырками, то есть массивов типа ['a', , 'c'], в которых отсутствуют некоторые элементы. Распространение такого массива, благодаря соблюдению протокола итерации, не сохраняет дырки, а вместо этого заполняет их значениями, найденными в прототипе массива на соответствующих индексах. По умолчанию в прототипе массива нет элементов, что означает, что любые дырки заполняются значением undefined. Например, [...['a', , 'c']] оценивается как новый массив ['a', undefined, 'c'].
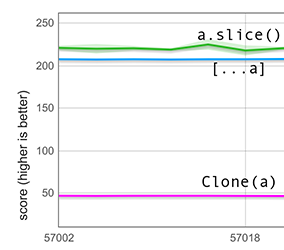
Наш быстрый путь достаточно умён, чтобы справляться с дырками в этой стандартной ситуации. Вместо того чтобы слепо копировать подложку входного массива, он отслеживает дырки и берёт на себя заботу о преобразовании их в значения undefined. График ниже содержит измерения для входного массива длиной 100,000, содержащего только (промаркированные) 600 целых чисел — остальное это дырки. Он показывает, что распространение такого дырявого массива теперь более чем в 4 раза быстрее, чем использование функции clone. (Ранее они были примерно равными, но это не показано на графике).
Отметим, что хотя slice включён в этот график, сравнение с ним является несправедливым, потому что slice имеет другую семантику для дырявых массивов: он сохраняет все дырки, поэтому у него намного меньше работы.
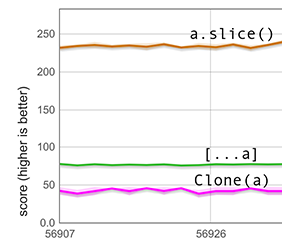
Заполнение дырок значением undefined, которое наш быстрый путь должен выполнить, не так просто, как кажется: это может потребовать преобразования всего массива в другой тип элементов. Следующий график измеряет такую ситуацию. Настройка такая же, как выше, за исключением того, что на этот раз 600 элементов массива — это неупакованные числа с плавающей точкой, и массив имеет тип элементов HOLEY_DOUBLE_ELEMENTS. Поскольку этот тип элементов не может содержать промаркированных значений, таких как undefined, распространение включает дорогостоящий переход типов элементов, из-за чего результат для [...a] значительно ниже, чем на предыдущем графике. Тем не менее, он всё равно значительно быстрее, чем clone(a).
Распространение строк, множеств и карт
Идея пропуска объекта итератора и предотвращения роста результирующего массива в равной степени применима к распространению других стандартных типов данных. Действительно, мы реализовали аналогичные быстрые пути для примитивных строк, для множеств и для карт, каждый раз заботясь об их обходе при наличии изменённого поведения итерации.
Что касается множеств, быстрый путь поддерживает не только распространение множества напрямую ([...set]), но также и распространение его итератора ключей ([...set.keys()]) и его итератора значений ([...set.values()]). В наших микротестах эти операции теперь примерно в 18 раз быстрее, чем ранее.
Быстрый путь для карт аналогичен, но не поддерживает непосредственное распространение карты ([...map]), так как мы считаем это редкой операцией. По той же причине ни один из быстрых путей не поддерживает итератор entries(). В наших микротестах эти операции теперь примерно в 14 раз быстрее, чем раньше.
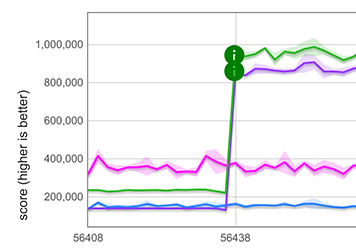
Для распространения строк ([...string]) мы измерили примерно пятикратное улучшение, как показано на графике ниже фиолетовыми и зелеными линиями. Заметьте, что это даже быстрее, чем оптимизированный TurboFan цикл for-of (TurboFan понимает итерацию строк и может генерировать оптимизированный код для этого), представленный синими и розовыми линиями. Причина наличия двух графиков в каждом случае заключается в том, что микротесты работают с двумя различными представлениями строк (однобайтовые и двухбайтовые строки).
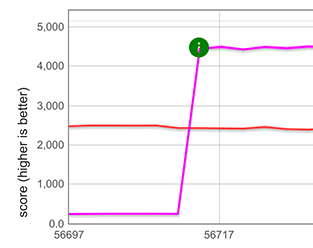
Улучшение производительности Array.from
К счастью, наши быстрые пути для элементов распространения могут быть использованы повторно для Array.from в случае, если Array.from вызывается с итерируемым объектом и без функции отображения, например, Array.from([1, 2, 3]). Повторное использование возможно, потому что в этом случае поведение Array.from точно такое же, как и у распространения. Это приводит к огромному улучшению производительности, показанному ниже для массива с 100 двойными числами.
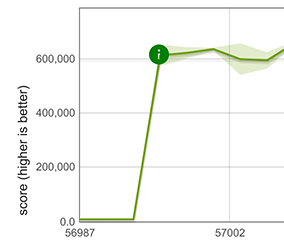
Заключение
V8 v7.2 / Chrome 72 значительно улучшает производительность элементов распространения, когда они появляются в начале литерала массива, например, [...x] или [...x, 1, 2]. Улучшение применяется к распространению массивов, примитивных строк, наборов, ключей карт, значений карт и — по расширению — к Array.from(x).