Кэширование кода для разработчиков JavaScript
Кэширование кода (также известное как кэширование байткода) представляет собой важную оптимизацию в браузерах. Оно сокращает время запуска часто посещаемых веб-сайтов путем кэширования результата анализа и компиляции. Большинство популярных браузеров реализуют различные формы кэширования кода, и Chrome не является исключением. На самом деле, мы писали и рассказывали о том, как Chrome и V8 сохраняют скомпилированный код в кэше.
В этой статье мы предлагаем несколько советов разработчикам JS по максимально эффективному использованию кэширования кода для улучшения старта их веб-сайтов. Эти советы сосредоточены на реализации кэширования в Chrome/V8, но большинство из них, вероятно, можно применить и к реализации кэширования кода в других браузерах.
Обзор кэширования кода
Хотя другие статьи и презентации предлагают более детальное описание нашей реализации кэширования кода, полезно быстро вспомнить, как это работает. В Chrome есть два уровня кэширования для скомпилированного кода V8 (как для классических скриптов, так и для модульных скриптов): недорогой "максимально эффективный" кэш в памяти, поддерживаемый V8 (кэш Isolate), и полностью сериализованный кэш на диске.
Кэш Isolate работает со скриптами, скомпилированными в той же изоляции V8 (т.е. тот же процесс, примерно "страницы одного веб-сайта при навигации в той же вкладке"). Он является "максимально эффективным" в том смысле, что пытается быть как можно быстрее и минимальным, используя уже доступные нам данные, в ущерб более низкой частоте попадания и отсутствию кэширования между процессами.
- Когда V8 компилирует скрипт, скомпилированный байткод сохраняется в хэш-таблицу (на куче V8), индексируемую по исходному коду скрипта.
- Когда Chrome просит V8 скомпилировать другой скрипт, V8 сначала проверяет, совпадает ли исходный код этого скрипта с чем-либо в этой хэш-таблице. Если да, то мы просто возвращаем существующий байткод.
Этот кэш быстрый и практически бесплатный, и мы наблюдаем его эффективность в 80% случаев в реальном мире.
Кэш кода на диске управляется Chrome (в частности, Blink) и восполняет пробелы, которые не может покрыть кэш Isolate: совместное использование кэшей кода между процессами и между несколькими сеансами Chrome. Он использует существующий HTTP-кэш ресурсов, который управляет кэшированием и истечением данных, полученных из веба.
- Когда файл JS запрашивается впервые (т.е. холодный запуск), Chrome скачивает его и передает V8 для компиляции. Он также сохраняет файл в кэше браузера на диске.
- Когда файл JS запрашивается второй раз (т.е. теплый запуск), Chrome берет файл из кэша браузера и снова передает его V8 для компиляции. На этот раз скомпилированный код сериализуется и добавляется кэшируемому файлу скрипта в качестве метаданных.
- В третий раз (т.е. горячий запуск), Chrome берет как файл, так и метаданные файла из кэша и передает их V8. V8 десериализует метаданные и может пропустить компиляцию.
В итоге:

Исходя из этого описания, мы можем дать лучшие советы по улучшению использования кэшей кода на вашем веб-сайте.
Совет 1: ничего не делать
Идеально, лучшее, что вы как разработчик JS можете сделать для улучшения кэширования кода, – "ничего". На самом деле это означает две вещи: пассивно ничего не делать и активно ничего не делать.
Кэширование кода, в конечном счете, является деталью реализации браузера; производительной оптимизацией, основанной на эвристике и компромиссе между данными и пространством, реализация и эвристики которой могут (и действительно) регулярно меняться. Мы, как инженеры V8, делаем все возможное, чтобы эти эвристики работали для всех в развивающемся вебе, и чрезмерная оптимизация для текущих деталей реализации кэширования кода может привести к разочарованию через несколько релизов, когда эти детали изменятся. Кроме того, другие движки JavaScript, вероятно, имеют различные эвристики для своей реализации кэширования кода. Поэтому во многих отношениях наш лучший совет по получению кэшируемого кода похож на наш совет по написанию JS: пишите чистый, идиоматический код, и мы сделаем все возможное, чтобы оптимально его кэшировать.
Помимо пассивного бездействия, вы также должны стараться активно ничего не делать. Любая форма кеширования по своей природе зависит от неизменности данных, поэтому бездействие — лучший способ позволить кешированным данным оставаться кешированными. Существует несколько способов активно ничего не делать.
Не изменяйте код
Это может показаться очевидным, но стоит сказать это явно — когда вы выпускаете новый код, этот код еще не кеширован. Каждый раз, когда браузер делает HTTP-запрос по URL скрипта, он может включить дату последнего получения этого URL, и если сервер знает, что файл не изменился, он может отправить ответ 304 Not Modified, который сохраняет кеш нашего кода горячим. В противном случае, ответ 200 OK обновляет наш ресурс в кеше и очищает кеш кода, возвращая его в состояние холодного запуска.

Существует соблазн всегда немедленно отправлять ваши последние изменения кода, особенно если вы хотите измерить влияние определенного изменения, но для кешей гораздо лучше оставить код в покое или обновлять его как можно реже. Подумайте о введении ограничения в ≤ x релизов в неделю, где x — это параметр, который вы можете настроить для баланса между кешированием и устареванием.
Не изменяйте URL
Кеши кода (в настоящее время) ассоциированы с URL скрипта, так как это делает их удобными для поиска без необходимости читать содержимое самого скрипта. Это означает, что изменение URL скрипта (включая любые параметры запроса!) создает новую запись ресурса в нашем кеше ресурсов, а вместе с ней — новую запись холодного кеша.
Конечно, это также может быть использовано для принудительного очистки кеша, хотя это тоже является деталями реализации; однажды мы можем решить ассоциировать кеши с текстом исходного кода, а не с URL, и этот совет больше не будет актуальным.
Не изменяйте поведение выполнения
Одной из последних оптимизаций в реализации кеширования кода является сериализация скомпилированного кода после его выполнения. Это делается для того, чтобы поймать лениво скомпилированные функции, которые компилируются только во время выполнения, а не в процессе начальной компиляции.
Эта оптимизация работает лучше всего, когда каждое выполнение скрипта выполняет один и тот же код, или по крайней мере одни и те же функции. Это может быть проблемой, если, например, у вас есть A/B-тесты, которые зависят от решения во время выполнения:
if (Math.random() > 0.5) {
A();
} else {
B();
}
В этом случае только A() или B() компилируются и выполняются при горячем запуске и добавляются в кеш кода, но любая из них может быть выполнена в последующих запусках. Вместо этого постарайтесь сделать выполнение детерминированным, чтобы оно оставалось на пути кеширования.
Совет 2: делайте что-нибудь
Конечно, совет «ничего не делать», будь то пассивно или активно, не очень удовлетворителен. Поэтому, помимо «ничего не делать», учитывая наши текущие эвристики и реализации, есть вещи, которые вы можете сделать. Однако, пожалуйста, помните, что эвристики могут измениться, этот совет может измениться, и нет ничего лучше профилирования.

Разделите библиотеки и код, который их использует
Кеширование кода выполняется грубым образом на уровне каждого скрипта, что означает, что изменения любой части скрипта аннулируют кеш всего скрипта. Если ваш размещаемый код состоит из стабильных и изменяющихся частей в одном скрипте, например, библиотек и бизнес-логики, то изменения в бизнес-логике аннулируют кеш кода библиотек.
Вместо этого вы можете разделить стабильный код библиотек в отдельный скрипт и подключить его отдельно. Тогда код библиотек может быть кеширован один раз и оставаться в кеше при изменении бизнес-логики.
Это имеет дополнительные преимущества, если библиотеки используются на разных страницах вашего сайта: поскольку кеш кода связан со скриптом, кеш кода библиотек также будет общим между страницами.
Объедините библиотеки и код, который их использует
Кеширование кода выполняется после выполнения каждого скрипта, что означает, что кеш кода будет включать только те функции в скрипте, которые были скомпилированы, когда выполнение скрипта завершилось. Это имеет несколько важных последствий для кода библиотек:
- Кеш кода не будет включать функции из ранних скриптов.
- Кеш кода не будет включать лениво скомпилированные функции, вызванные поздними скриптами.
В частности, если библиотека состоит исключительно из лениво скомпилированных функций, то эти функции не будут кешироваться, даже если они используются позже.
Одно из решений этой проблемы — объединить библиотеки и их использование в один скрипт, чтобы кэширование кода «видело», какие части библиотеки используются. К сожалению, это прямо противоположно приведенному выше совету, потому что нет универсальных решений. В общем, мы не рекомендуем объединять все ваши JS-скрипты в один большой пакет; лучше разбить их на несколько небольших скриптов — это, как правило, более выгодно по другим причинам, помимо кэширования кода (например, множественные сетевые запросы, потоковая компиляция, интерактивность страницы и т. д.).
Используйте эвристики IIFE
К кэшу кода относятся только те функции, которые компилируются к моменту завершения выполнения скрипта, поэтому существует множество типов функций, которые не будут кэшироваться, несмотря на их выполнение позже. Обработчики событий (даже onload), цепочки обещаний, неиспользуемые функции библиотек и все остальное, что компилируется лениво без вызова до момента, когда браузер видит </script>, остаются ленивыми и не кэшируются.
Один из способов заставить такие функции кэшироваться — принудительно их компилировать, и одним из распространенных способов принудительной компиляции является использование эвристики IIFE. IIFE (Immediately-Invoked Function Expressions — немедленно вызываемые выражения функций) — это паттерн, в котором функция вызывается сразу же после создания:
(function foo() {
// …
})();
Так как IIFE вызываются немедленно, большинство JavaScript-движков пытаются обнаружить их и скомпилировать сразу, чтобы избежать затрат на ленивую компиляцию, а затем на полную компиляцию. Существует несколько эвристик для раннего обнаружения IIFE (до того, как функция должна быть разобрана), самая распространенная из которых — это ( перед ключевым словом function.
Поскольку эта эвристика применяется рано, она запускает компиляцию, даже если функция фактически не вызывается сразу:
const foo = function() {
// Компиляция пропущена лениво
};
const bar = (function() {
// Компиляция произведена немедленно
});
Это означает, что функции, которые должны быть в кэше кода, можно принудительно туда поместить, обернув их в круглые скобки. Однако это может замедлить время запуска, если подсказка применяется неправильно, и в целом это некоторый вид злоупотребления эвристиками, поэтому мы советуем избегать этого, если это не необходимо.
Группируйте небольшие файлы вместе
В Chrome существует минимальный размер для кэшей кода, который в данный момент установлен на 1 КиБ исходного кода. Это означает, что более мелкие скрипты вообще не кэшируются, так как мы считаем, что затраты превышают выгоды.
Если на вашем веб-сайте много таких небольших скриптов, расчет затрат может больше не применяться таким же образом. Вы можете рассмотреть возможность их объединения, чтобы они превышали минимальный размер кода, а также сократить накладные расходы на скрипты.
Избегайте встроенных скриптов
Теги скриптов, чей код встроен в HTML, не имеют внешнего файла, с которым они связаны, и, следовательно, не могут быть кэшированы описанным выше механизмом. Chrome пытается кэшировать встроенные скрипты, прикрепляя их кэш к ресурсу HTML-документа, но такие кэши зависят от всего HTML-документа, а также не могут быть разделены между страницами.
Поэтому, для нетривиальных скриптов, которые могли бы выиграть от кэширования кода, старайтесь не встраивать их в HTML, а предпочитайте включать их как внешние файлы.
Используйте кэши сервис-воркера
Сервис-воркеры — это механизм для вашего кода, который позволяет перехватывать сетевые запросы ресурсов вашей страницы. В частности, они позволяют вам создать локальный кэш некоторых ресурсов и обслуживать их из кэша, когда они запрашиваются. Это особенно полезно для страниц, которые должны продолжать работать в офлайне, таких как PWA.
Типичный пример использования сайта с сервис-воркером заключается в регистрации сервис-воркера в основном файле скрипта:
// main.mjs
navigator.serviceWorker.register('/sw.js');
А сервис-воркер добавляет обработчики событий для установки (создание кэша) и загрузки (обслуживание ресурсов, возможно, из кэша):
// sw.js
self.addEventListener('install', (event) => {
async function buildCache() {
const cache = await caches.open(cacheName);
return cache.addAll([
'/main.css',
'/main.mjs',
'/offline.html',
]);
}
event.waitUntil(buildCache());
});
self.addEventListener('fetch', (event) => {
async function cachedFetch(event) {
const cache = await caches.open(cacheName);
let response = await cache.match(event.request);
if (response) return response;
response = await fetch(event.request);
cache.put(event.request, response.clone());
return response;
}
event.respondWith(cachedFetch(event));
});
Эти кэши могут включать закэшированные JS-ресурсы. Однако для них применяются несколько иные эвристики, поскольку мы можем делать другие предположения. Так как кэш сервис-воркера подчиняется правилам квотируемого хранения, он, скорее всего, будет сохраняться дольше, и выгода от кэширования станет больше. Кроме того, мы можем выводить дополнительную важность ресурсов, если они предварительно закэшированы перед загрузкой.
Наибольшие эвристические различия возникают, когда ресурс добавляется в кэш service worker во время события установки service worker. Пример выше демонстрирует такое использование. В этом случае кэш кода создается немедленно, когда ресурс помещается в кэш service worker. Кроме того, мы генерируем "полный" кэш кода для этих скриптов - мы больше не компилируем функции лениво, а вместо этого компилируем всё и размещаем это в кэше. Это дает преимущество быстрой и предсказуемой производительности без зависимостей порядка выполнения, хотя и за счет увеличенного использования памяти.
Если JS-ресурс сохраняется через Cache API вне события установки service worker, то кэш кода не генерируется немедленно. Вместо этого, если service worker отвечает с использованием этого ответа из кэша, то "обычный" кэш кода будет сгенерирован при первом загрузке. Этот кэш кода затем будет доступен при второй загрузке; на одну загрузку быстрее, чем при типичной ситуации с кэшированием кода. Ресурсы могут быть сохранены в Cache API вне события установки, если "постепенно" кэшировать ресурсы в событии fetch или если Cache API обновляется из главного окна, а не из service worker.
Обратите внимание, что предварительно закэшированный "полный" кэш кода предполагает, что страница, на которой будет выполнен скрипт, будет использовать кодировку UTF-8. Если в итоге страница использует другую кодировку, то кэш кода будет отброшен и заменен на "обычный" кэш кода.
Кроме того, предварительно закэшированный "полный" кэш кода предполагает, что страница загрузит скрипт как классический JS-скрипт. Если в итоге страница загружает его как ES-модуль, то кэш кода будет отброшен и заменен на "обычный" кэш кода.
Трассировка
Ни одно из вышеприведенных предложений не гарантирует ускорение вашего веб-приложения. К сожалению, информация о кэшировании кода в настоящее время не отображается в DevTools, поэтому наиболее надежный способ выяснить, какие скрипты вашего веб-приложения кэшируются, - это использовать слегка более низкоуровневый инструмент chrome://tracing.
chrome://tracing записывает инструментированные трассы Chrome в течение определенного периода времени, где конечная визуализация трассы выглядит примерно так:
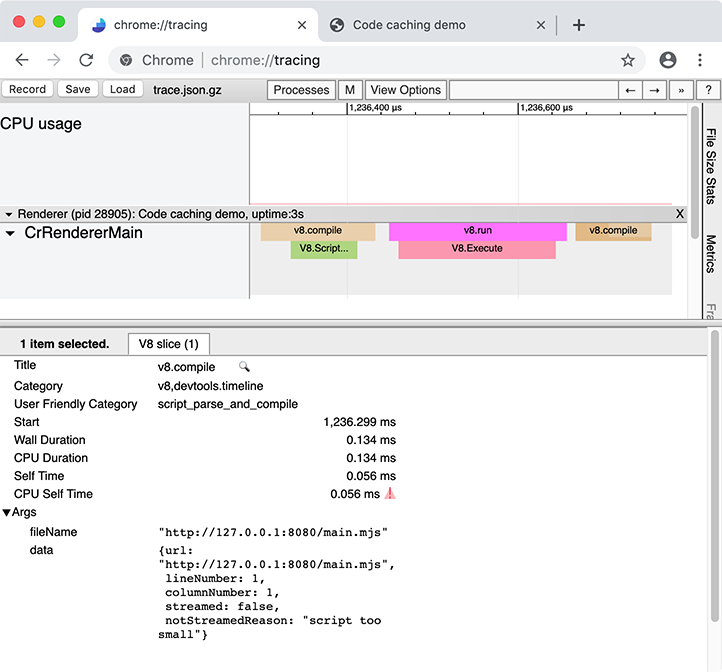
Трассировка записывает поведение всего браузера, включая другие вкладки, окна и расширения, поэтому она работает лучше всего, если запускать её в чистом профиле пользователя, с отключенными расширениями и без открытых других вкладок браузера:
# Запустите новый сеанс браузера Chrome с чистым профилем пользователя и отключенными расширениями
google-chrome --user-data-dir="$(mktemp -d)" --disable-extensions
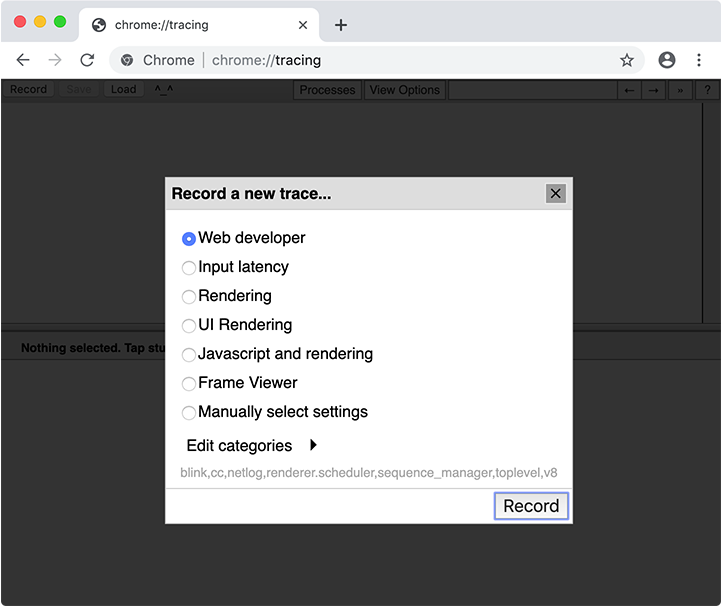
При сборе трассы вам нужно выбрать, какие категории отслеживать. В большинстве случаев можно просто выбрать набор категорий "Web developer", но можно также выбрать категории вручную. Важная категория для кэширования кода - это v8.
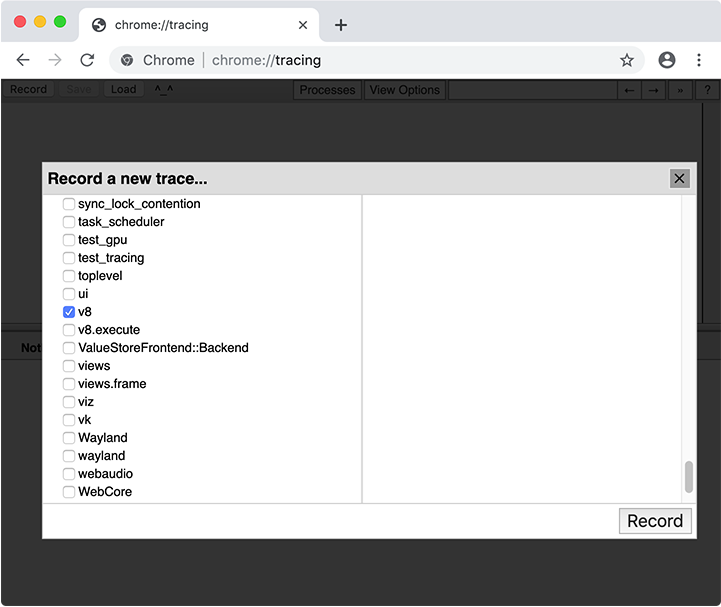
После записи трассы с категорией v8 найдите срезы v8.compile в трассе. (Кроме того, вы можете ввести v8.compile в строку поиска интерфейса трассировки.) Эти срезы отображают файл, который компилируется, и некоторую метаинформацию о компиляции.
При холодном запуске скрипта отсутствует информация о кэшировании кода — это означает, что скрипт не участвовал в создании или использовании данных кэша.
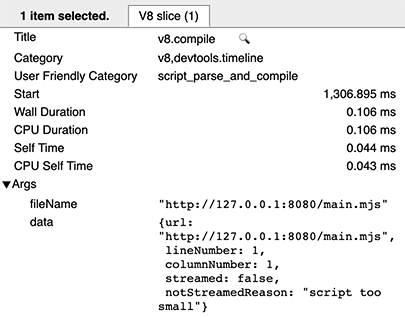
При теплом запуске есть две записи v8.compile на скрипт: одна для фактической компиляции (как выше), и одна (после выполнения) для создания кэша. Вы можете распознать последнюю, так как у неё есть метаданные cacheProduceOptions и producedCacheSize.
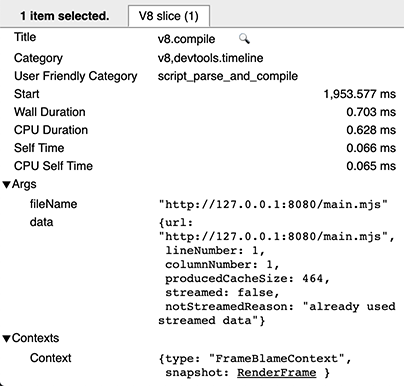
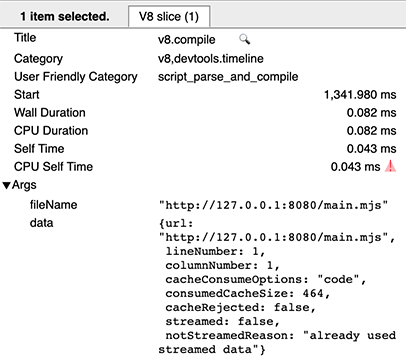
При горячем запуске вы увидите запись v8.compile для использования кэша, с метаданными cacheConsumeOptions и consumedCacheSize. Все размеры выражаются в байтах.
Заключение
Для большинства разработчиков кэширование кода должно "просто работать". Оно работает лучше, как и любой кэш, когда всё остается неизменным, и работает на основе эвристик, которые могут изменяться между версиями. Тем не менее, кэширование кода имеет поведение, которое можно использовать, и ограничения, которых можно избежать, а тщательный анализ с использованием chrome://tracing может помочь вам настроить и оптимизировать использование кэшей в вашем веб-приложении.