懒惰反序列化
简要介绍:懒惰反序列化最近在 V8 v6.4 中默认启用,平均每个浏览器标签页减少 V8 的内存占用超过 500 KB。继续阅读以了解更多信息!
引入 V8 快照
但首先,让我们回顾一下 V8 如何使用堆快照来加速新隔离环境的创建(这大致上相当于 Chrome 中的一个浏览器标签页)。我的同事杨果在他关于自定义启动快照的文章中对此作了很好的介绍:
JavaScript 规范包含许多内置功能,从数学函数到功能齐全的正则表达式引擎。每个新创建的 V8 上下文从一开始就可以使用这些功能。为使其正常工作,全局对象(例如浏览器中的
window对象)及所有内置功能必须在创建上下文时设置并初始化到 V8 的堆中。这从头开始处理需要相当多的时间。幸运的是,V8 使用一种快捷方式来加速这一过程:就像冷冻披萨解冻后快速准备晚餐一样,我们将一个预先准备好的快照直接反序列化到堆中以获得一个初始化的上下文。在普通的桌面计算机上,这可以将创建上下文的时间从 40 毫秒缩短到不足 2 毫秒。在普通的手机上,这可能意味着从 270 毫秒降至 10 毫秒的差距。
总结一下:快照对启动性能至关重要,它们通过反序列化为每个隔离环境创建了 V8 堆的初始状态。因此,快照的大小决定了 V8 堆的最小大小,而较大的快照会直接导致更高的每个隔离环境的内存消耗。
一个快照包含完全初始化新隔离环境所需的一切,包括语言常量(例如 undefined 值)、解释器使用的内部字节码处理程序、内置对象(例如 String)以及安装在内置对象上的函数(例如 String.prototype.replace),以及它们的可执行 Code 对象。
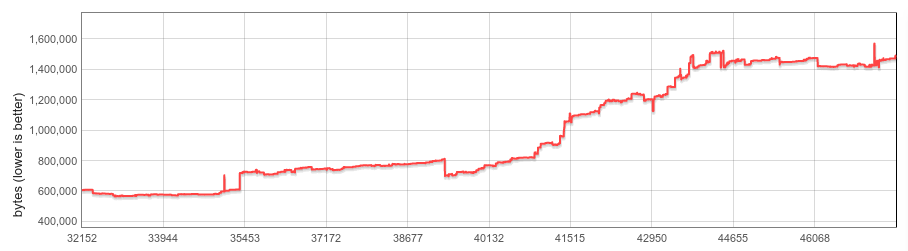
在过去两年里,快照的大小几乎增加了三倍,从 2016 年初的约 600 KB 增加到今天的超过 1500 KB。这种增长的绝大部分来自序列化的 Code 对象,这些对象的数量有所增加(例如随着 JavaScript 语言规范的演变和增长进行的新增);其大小也有所增加(通过新 CodeStubAssembler 管道生成的内置内容以本机代码形式提供,而非更紧凑的字节码或最小化的 JS 格式)。
这是个坏消息,因为我们希望尽量降低内存消耗。
懒惰反序列化
主要问题之一是我们曾经将快照的全部内容复制到每个隔离环境中。对于内置函数来说这种方式特别浪费,因为它们会无条件地全部加载,但可能永远不会被使用。
这就是懒惰反序列化的用武之地。这个概念非常简单:如果我们只在调用内置函数之前才反序列化这些函数呢?
对一些最受欢迎的网站进行一次快速调查显示,这一方法非常有吸引力:平均而言,只有 30% 的内置函数被使用,有些网站仅使用了 16%。考虑到这些网站大多数是重度 JavaScript 使用者,这些数据可以被视为为整个网络潜在内存节省的(模糊)下限,这看起来非常有希望。
随着我们开始朝这个方向努力,结果表明懒惰反序列化与 V8 的架构集成得非常好,仅需要一些基本上不具侵入性的设计更改即可启动:
- 快照内著名的位置。 在懒惰反序列化之前,序列化快照中的对象顺序是无关紧要的,因为我们始终会一次性反序列化整个堆。懒惰反序列化必须能够单独反序列化任何给定的内置函数,因此必须知道它在快照中的位置。
- 单个对象的反序列化。 V8 的快照最初是为整个堆的反序列化设计的,增加对单个对象反序列化的支持需要处理一些特殊问题,比如非连续的快照布局(一个对象的序列化数据可能与其他对象的数据交错)和所谓的反向引用(可以直接引用在当前运行中先前反序列化的对象)。
- 懒惰反序列化机制本身。 在运行时,懒惰反序列化处理程序必须能够 a) 确定要反序列化的代码对象,b) 执行实际的反序列化操作,以及 c) 将序列化的代码对象附加到所有相关函数。
我们解决前两点的方案是为快照添加一个新的专用内建区域,该区域仅包含序列化的代码对象。序列化以定义明确的顺序进行,每个 Code 对象的起始偏移量保存在内建快照区域的专用部分中。不允许反向引用和交错的对象数据。
懒惰内建反序列化 由名副其实的 DeserializeLazy 内建函数 处理,该函数在序列化时安装到所有懒惰内建函数上。在运行时调用时,它会反序列化相关的 Code 对象,最终将其安装到 JSFunction(表示函数对象)和 SharedFunctionInfo(在从相同函数文本创建的函数之间共享)上。每个内建函数最多反序列化一次。
除了内建函数,我们还实现了字节码处理程序的懒惰反序列化。字节码处理程序是代码对象,包含在 V8 的 Ignition 解释器中执行每条字节码的逻辑。与内建函数不同,它们既没有附加的 JSFunction 也没有 SharedFunctionInfo。其代码对象直接存储在 分配表 中,解释器在分派给下一个字节码处理程序时会对此表进行索引。懒惰反序列化与内建函数类似:DeserializeLazy 处理程序通过检查字节码数组确定要反序列化的处理程序,反序列化代码对象,最后将反序列化的处理程序存储在分配表中。同样,每个处理程序最多反序列化一次。
结果
我们通过使用带有和不带懒惰反序列化的 Chrome 65 在 Android 设备上加载前 1000 个最流行的网站来评估内存节省情况。
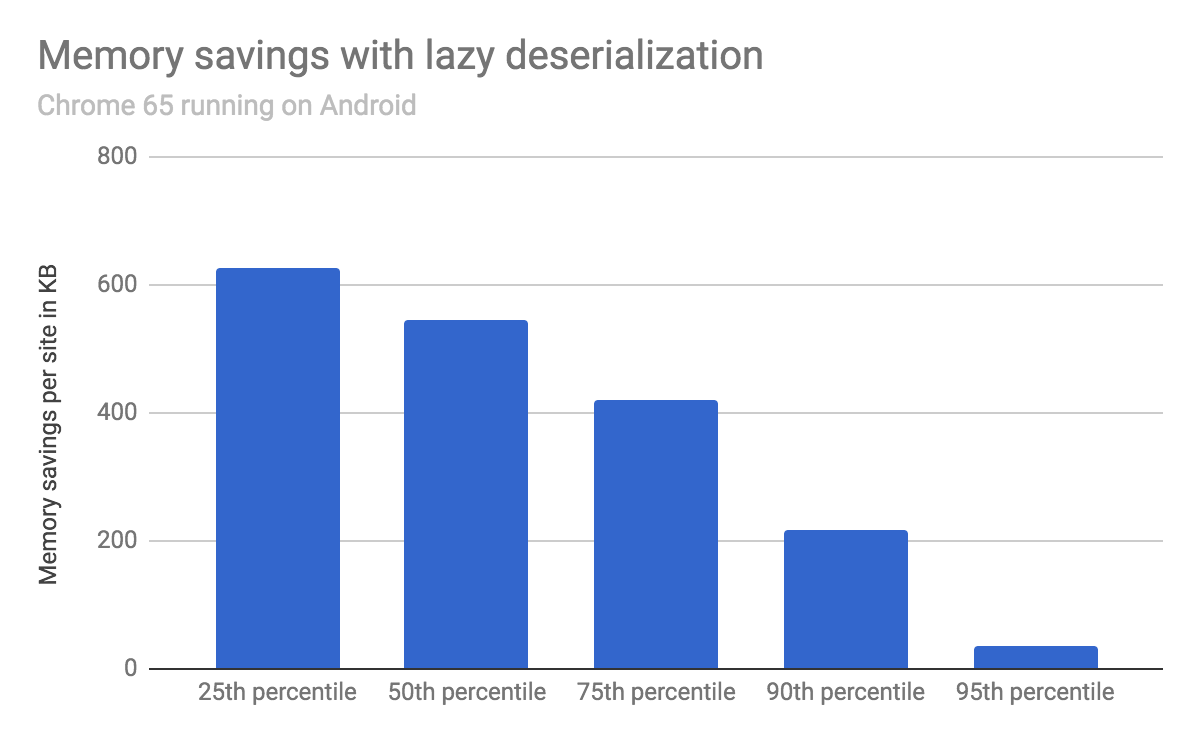
平均而言,V8 的堆大小减少了 540 KB,测试站点中 25% 节省了超过 620 KB,50% 节省了超过 540 KB,75% 节省了超过 420 KB。
运行时性能(通过 Speedometer 等标准 JS 基准测试以及一系列流行网站测量)没有受到懒惰反序列化的影响。
下一步
懒惰反序列化确保每个隔离体仅加载实际使用的内建代码对象。这已经是一个巨大的进步,但我们相信还可以更进一步,将每个隔离体的(内建相关)成本有效地降至零。
我们希望今年晚些时候在这方面为您带来更新。敬请期待!