关于懒惰的实习:被优化函数的懒惰取消链接
大约三个月前,我作为实习生加入了V8团队(Google Munich),从那时起,我一直在研究虚拟机的 去优化器 —— 这是对我来说全新的领域,但也证明了是一个有趣且具挑战性的项目。实习的第一部分重点在于提高虚拟机的安全性。第二部分则集中于性能改进,即删除用于取消链接以前被优化的函数的数据结构,而这个结构在垃圾回收时是性能瓶颈。本博客文章描述了我实习的第二部分。我将解释V8过去如何取消链接被优化的函数,我们如何对其进行更改,以及获得了哪些性能提升。
让我们(非常)简要回顾一下JavaScript函数的V8管道:V8的解释器Ignition在解释这个函数时收集该函数的性能信息。一旦这个函数变得热门,这些信息就会传递给V8的编译器TurboFan,后者生成优化的机器代码。当性能信息不再有效时——例如因为一个被分析的对象在运行时得到不同的类型——优化的机器代码可能变得无效。在这种情况下,V8需要对其进行去优化。
在优化过程中,TurboFan为正在优化的函数生成代码对象,即优化的机器代码。当这个函数下一次被调用时,V8会跟随到该函数优化代码的链接并执行它。在这个函数被去优化时,我们需要取消代码对象的链接,以确保它不会被再次执行。那么这是如何实现的呢?
例如,在以下代码中,函数 f1 将被多次调用(每次都传入一个整数作为参数)。TurboFan为特定情况生成机器代码。
function g() {
return (i) => i;
}
// 创建一个闭包。
const f1 = g();
// 优化f1。
for (var i = 0; i < 1000; i++) f1(0);
每个函数也有一个指向解释器的跳板——有关更多详情,请参阅这些幻灯片——并且会在其 SharedFunctionInfo (SFI) 中保存一个指向这个跳板的指针。每当V8需要返回未优化的代码时,这个跳板就会被使用。因此,在去优化过程中,触发的原因可能是传入不同类型的参数,例如,去优化器只需要将JavaScript函数的代码字段设置为这个跳板。
虽然这看起来很简单,但它迫使V8保留优化的JavaScript函数的弱列表。这是因为可能会有不同的函数指向同一个优化代码对象。我们可以扩展我们的例子,函数 f1 和 f2 都指向相同的一段优化代码。
const f2 = g();
f2(0);
如果函数 f1 被去优化(例如通过调用其不同类型的对象 {x: 0}),我们需要确保通过调用 f2 不会再次执行已失效的代码。
因此,在去优化过程中,V8过去会迭代所有优化的JavaScript函数,并取消链接那些指向正在去优化的代码对象的函数。这种迭代在拥有许多优化JavaScript函数的应用程序中成为性能瓶颈。此外,除了降低了去优化速度之外,V8过去还会在垃圾收集的全局暂停周期中迭代这些列表,使得情况变得更加糟糕。
为了了解这种数据结构对V8性能的影响,我们编写了一个微基准测试,通过创建许多JavaScript函数后触发多次清理周期来对其用法进行测试。
function g() {
return (i) => i + 1;
}
// 创建初始闭包并优化。
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// 创建200万个闭包;它们将获取先前优化的代码。
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// 现在触发垃圾回收;所有的回收都很慢。
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
在运行此基准测试时,我们观察到V8在垃圾回收上花费了大约98%的执行时间。然后我们移除了该数据结构,转而使用_延迟取消链接_ 的方法,这是我们在x64上的观察结果:

尽管这只是一个创建许多JavaScript函数并触发多次垃圾回收循环的微基准测试,但它为我们提供了该数据结构引入的开销的概念。在其他更现实的应用中,我们也观察到了一些开销,而这些开销促使了此项工作的开展,例如在Node.js中实现的路由基准测试和ARES-6基准测试套件。
延迟取消链接
与其在去优化时取消链接优化代码与JavaScript函数的关系,不如V8将其推迟到此类函数的下一次调用。当调用这些函数时,V8会检查它们是否已被去优化,若是,则取消链接它们并继续其延迟编译。如果这些函数不再被调用,它们将永远不会被取消链接,并且去优化代码对象将不会被回收。然而,鉴于在去优化时我们使代码对象的所有内嵌字段失效,因此我们只保持代码对象本身的存活。
提交中移除了这份优化的JavaScript函数列表,这需要对虚拟机的多个部分进行更改,但基本思想如下:在组装优化代码对象时,我们检查它是否是JavaScript函数的代码。如果是的话,在其序言中,我们组装机器代码以在代码对象被去优化时退出。去优化时,我们不再修改去优化的代码——代码补丁被移除。因此,当再次调用该函数时,其marked_for_deoptimization位仍处于设置状态。TurboFan生成代码检查它,如果已设置,则V8跳转到一个新的内建函数CompileLazyDeoptimizedCode,该函数取消去优化代码与JavaScript函数的链接,然后继续延迟编译。
更详细地来看,第一步是生成加载当前组装代码地址的指令。我们可以在x64中用以下代码实现:
Label current;
// 将当前指令的有效地址加载到rcx中。
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
之后,我们需要获取代码对象中marked_for_deoptimization位所在的位置。
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
然后,我们可以测试该位,如果它已设置,则跳转到内建函数CompileLazyDeoptimizedCode。
// 测试该位是否已设置,也就是说,代码是否被标记为去优化。
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// 如果已设置,则跳转到内建函数。
__ j(not_zero, /* handle to builtin code here */, RelocInfo::CODE_TARGET);
在CompileLazyDeoptimizedCode内建函数的一侧,剩下的只是取消代码字段与JavaScript函数的链接,并将其设置为指向解释器入口的中继器。因此,考虑到JavaScript函数的地址存储在寄存器rdi中,我们可以用以下代码获取指向SharedFunctionInfo的指针:
// 字段读取以获取SharedFunctionInfo。
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
类似地,通过以下代码获取中继器:
// 字段读取以获取代码对象。
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
然后,我们可以用它来更新函数槽的代码指针:
// 使用中继器更新函数的代码字段。
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// 写屏障以保护字段。
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
这产生了与之前相同的结果。然而,与其在去优化器中处理取消链接,我们需要在代码生成过程中处理这种情况,因此需要手写汇编代码。
上述是x64架构中的工作原理。我们已经为ia32、arm、arm64、mips和mips64实现了此功能。
这种新技术已集成到V8中,并且我们稍后将讨论它能够带来的性能改进。然而,它带来了一个小缺点:之前,V8仅在反优化时考虑取消链接。现在,它必须在所有优化函数的激活过程中执行。此外,检查marked_for_deoptimization位的方法效率不如理想,因为需要完成一些工作才能获得代码对象的地址。请注意,这发生在进入每个优化函数时。针对这个问题的一个可能解决方案是在代码对象中保留一个指向自身的指针。而不是在每次函数调用时寻找代码对象地址,V8可以在构建后只做一次。
结果
我们现在来看一下这个项目中获得的性能提升和回归。
x64上的整体改进
下图显示了一些相对于之前提交的改进和回归。注意,值越高越好。
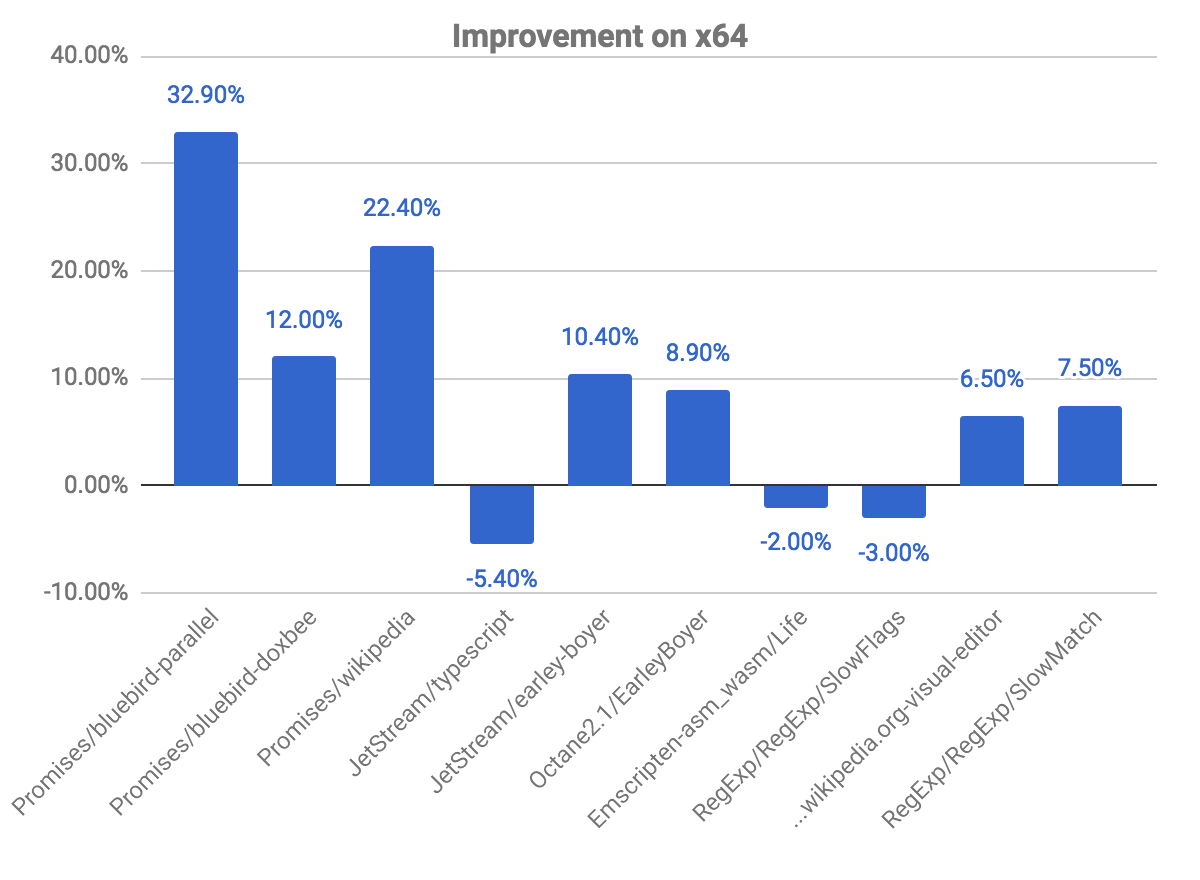
promises基准测试中我们看到的改进最大,比如bluebird-parallel基准测试的提升近33%,wikipedia的提升为22.40%。我们在一些基准测试中也观察到了一些性能回退。这与上面解释的问题有关,检查代码是否标记为反优化。
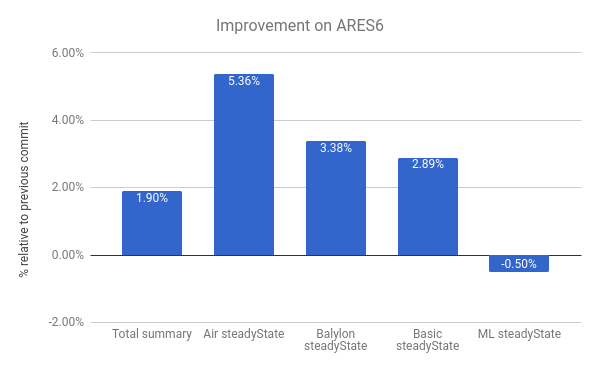
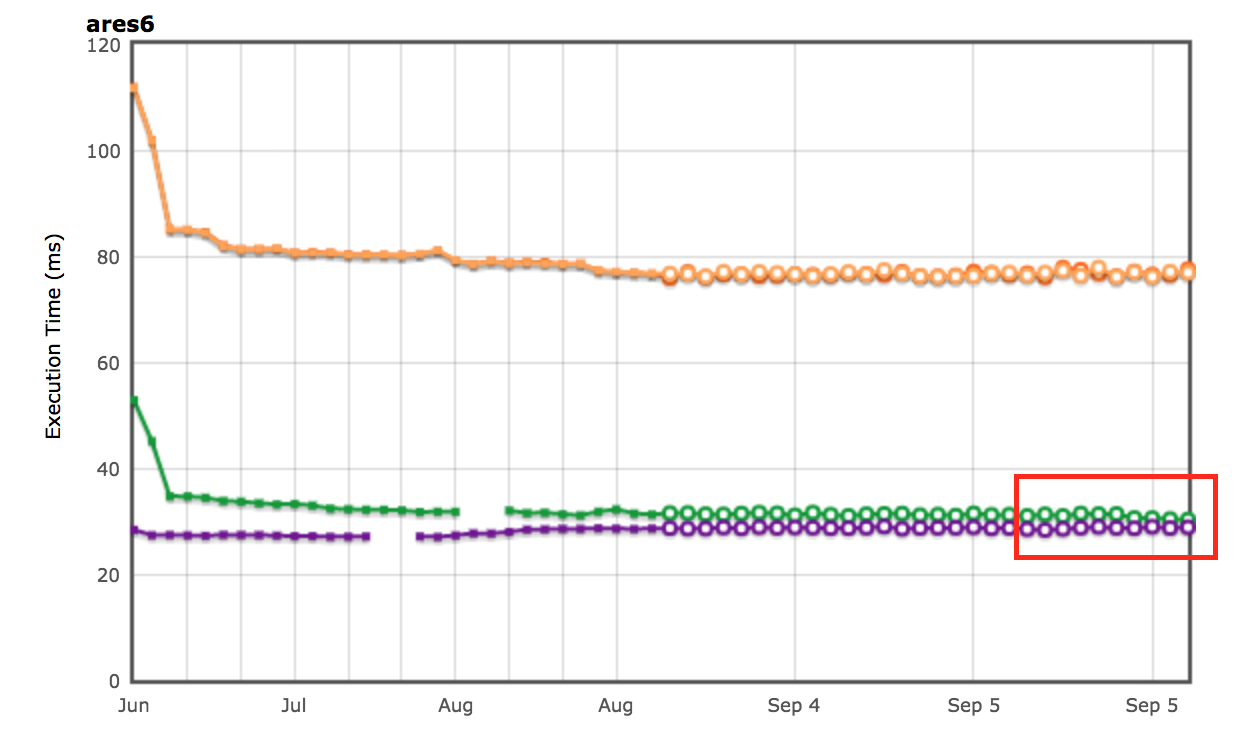
我们在ARES-6基准套件中也看到了改进。在这张图表中也注意,值越高越好。这些程序曾经在与GC相关的活动中花费了大量时间。通过懒惰取消链接,我们整体性能提高了1.9%。最显著的例子是Air steadyState,提升了约5.36%。
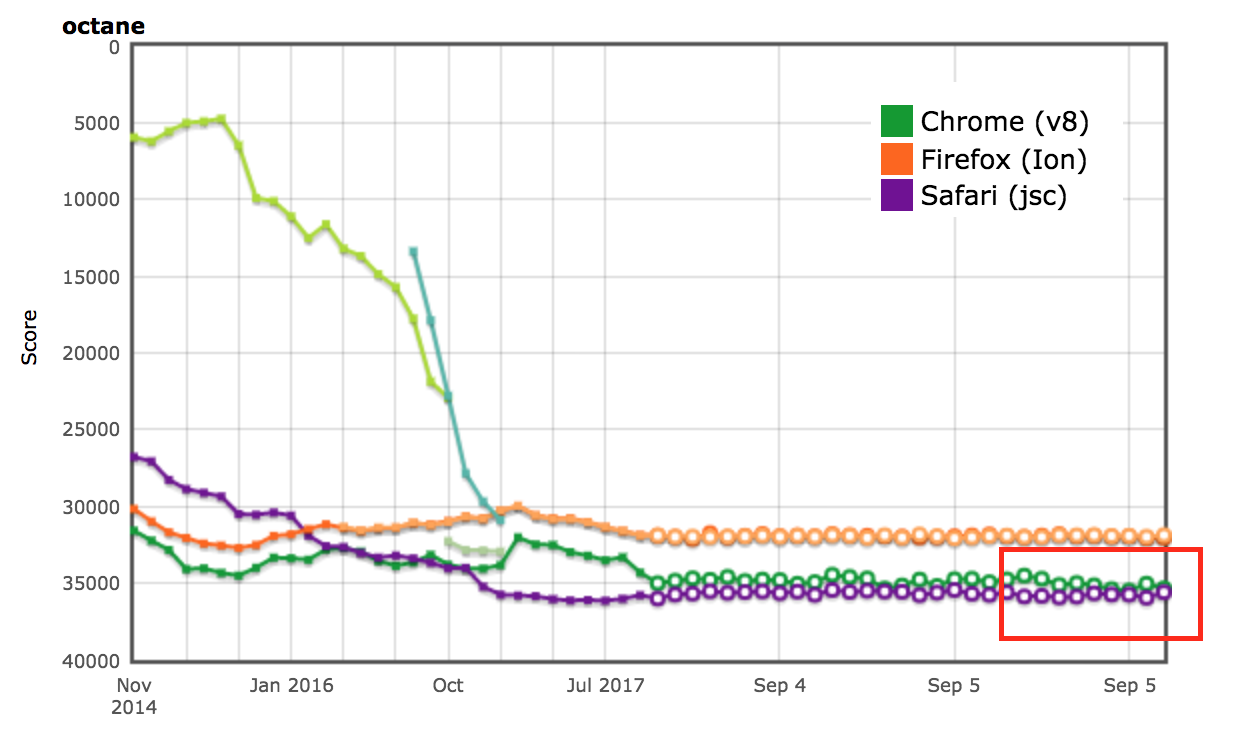
AreWeFastYet结果
Octane和ARES-6基准套件的性能结果也出现在AreWeFastYet追踪器上。我们在2017年9月5日查看了这些性能结果,使用提供的默认机器(macOS 10.10 64-bit,Mac Pro,shell)。
对Node.js的影响
我们也可以在router-benchmark中看到性能改进。以下两个图表显示了每个测试路由器每秒操作的次数,因此值越高越好。我们在这个基准套件中进行了两种实验。首先,我们单独运行每个测试,以便单独观察性能改进,与其他测试无关。其次,我们同时运行所有测试,不切换虚拟机,从而模拟一个每个测试与其他功能集成的环境。
在第一次实验中,我们看到router和express测试在相同时间内执行的操作次数约为之前的两倍。在第二次实验中,我们看到了更大的改进。在某些情况下,比如routr、server-router和router,基准测试大约分别执行了3.80倍、3倍和2倍的操作。这是因为V8在测试之间积累了更多优化的JavaScript函数。因此,每次执行特定测试时,如果触发了垃圾回收循环,V8必须访问当前测试以及之前测试中的优化函数。


进一步优化
现在V8不再在上下文中保留JavaScript函数的链表,我们可以从JSFunction类中移除字段next。虽然这是一项简单修改,但可以让我们每个函数节省指针大小,这在多个网页中意味着显著的节省:
| 基准测试 | 类型 | 内存节省(绝对值) | 内存节省(相对值) |
|---|---|---|---|
| facebook.com | 平均有效大小 | 170 KB | 3.70% |
| twitter.com | 分配对象的平均大小 | 284 KB | 1.20% |
| cnn.com | 分配对象的平均大小 | 788 KB | 1.53% |
| youtube.com | 分配对象的平均大小 | 129 KB | 0.79% |
致谢
在我的实习期间,我得到了很多来自几位同事的帮助,他们总是很乐意回答我的众多问题。因此,我要感谢以下几位:Benedikt Meurer、Jaroslav Sevcik 和 Michael Starzinger,感谢他们与我讨论编译器和反优化器的工作原理;感谢 Ulan Degenbaev 在我弄坏垃圾回收器时给予帮助;感谢 Mathias Bynens、Peter Marshall、Camillo Bruni 和 Maya Armyanova 对本文的校对工作。
最后,这篇文章是我作为 Google 实习生的最后一项贡献,我想借此机会感谢 V8 团队的所有成员,特别是我的导师 Benedikt Meurer,感谢他接待我,并给我机会参与如此有趣的项目——我确实学到了很多,并且非常享受在 Google 的时光!