加速展开元素
在 V8 团队的三个月实习期间,Hai Dang 改进了 [...array], [...string], [...set], [...map.keys()] 和 [...map.values()] 的性能(当展开元素处于数组字面量开头时)。他还大幅加速了 Array.from(iterable)。本文将解释他所做的一些详细修改,这些优化从 V8 v7.2 开始生效。
展开元素
展开元素是数组字面量中的组件,形式为 ...iterable。它们在 ES2015 中被引入,用于从可迭代对象创建数组。例如,数组字面量 [1, ...arr, 4, ...b] 创建的数组,首个元素是 1,紧接着是数组 arr 的元素,然后是 4,最后是数组 b 的元素:
const a = [2, 3];
const b = [5, 6, 7];
const result = [1, ...a, 4, ...b];
// → [1, 2, 3, 4, 5, 6, 7]
另一个例子,任意字符串都可以展开为一个包含其字符(Unicode 代码点)的数组:
const str = 'こんにちは';
const result = [...str];
// → ['こ', 'ん', 'に', 'ち', 'は']
同样,任意集合都可以展开为一个按插入顺序排序的数组:
const s = new Set();
s.add('V8');
s.add('TurboFan');
const result = [...s];
// → ['V8', 'TurboFan']
通常,数组字面量中的展开元素语法 ...x 假定 x 提供一个迭代器(通过 x[Symbol.iterator]() 获得)。然后使用此迭代器获取要插入目标数组的元素。
仅将数组 arr 展开为一个新数组,不在之前或之后添加任何元素的简单用法 [...arr],在 ES2015 中被认为是一种简洁、惯用的浅拷贝 arr 的方式。不幸的是,在 V8 中,这种方式的性能远远落后于其 ES5 的对应方法。Hai 的实习目标就是改变这一状况!
为什么展开元素慢(或者曾经慢)?
有很多方法可以对数组 arr 进行浅拷贝。例如,可以使用 arr.slice()、或 arr.concat()、或 [...arr]。或者,你可以编写自己的 clone 函数,使用标准 for 循环:
function clone(arr) {
// 预分配正确数量的元素,以避免
// 必须增长数组。
const result = new Array(arr.length);
for (let i = 0; i < arr.length; i++) {
result[i] = arr[i];
}
return result;
}
理想情况下,所有这些选项应该具有类似的性能特征。不幸的是,如果在 V8 中选择 [...arr],它(或者曾经)可能比 clone 更慢!原因是 V8 本质上将 [...arr] 转为如下迭代:
function(arr) {
const result = [];
const iterator = arr[Symbol.iterator]();
const next = iterator.next;
for ( ; ; ) {
const iteratorResult = next.call(iterator);
if (iteratorResult.done) break;
result.push(iteratorResult.value);
}
return result;
}
这段代码通常比 clone 慢有几个原因:
- 它需要在开始时通过加载和评估
Symbol.iterator属性来创建iterator。 - 它需要在每步创建和查询
iteratorResult对象。 - 它在每一步迭代中通过调用
push来增长result数组,从而反复重新分配存储空间。
使用这种实现的原因是,正如前面所述,展开不仅可以应用于数组,实际上可以应用于任意 可迭代 的对象,并且必须遵循迭代协议。尽管如此,V8 应该足够智能以识别被展开的对象是数组,使其能在较低层次执行元素提取,从而:
- 避免创建迭代器对象,
- 避免创建迭代器结果对象,
- 避免不断增长并重新分配结果数组(我们提前知道元素数量)。
我们使用CSA在 快速 数组(即具有六种最常见元素类型之一的数组)上实现了这一简单想法。针对常见的实际场景,优化应用于展开发生在数组字面量开头的情况,例如 [...foo]。如下面的图表所示,这条新的快速路径使处理长度为 100,000 的数组时性能提高约 3 倍,比手写的 clone 循环快约 25%。
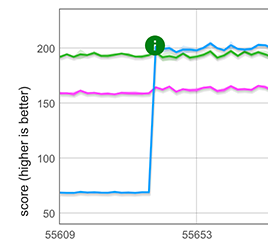
注意: 虽然此处未显示,但快速路径也适用于展开元素后跟其他组件的情况(例如 [...arr, 1, 2, 3]),但不适用于前面有其他组件的情况(例如 [1, 2, 3, ...arr])。
谨慎使用快速路径
这显然是一个令人印象深刻的加速,但我们必须非常小心以确保何时正确使用此快速路径:JavaScript 允许程序员以多种方式修改对象(甚至是数组)的迭代行为。由于展开元素被指定为使用迭代协议,因此需要确保这种修改能够被尊重。因此,只要原始的迭代机制被修改,我们都会完全避免使用快速路径。例如,包括以下情况。
自有的 Symbol.iterator 属性
通常,数组 arr 没有自己的 Symbol.iterator 属性,因此在查找该符号时,会在数组的原型上发现它。在下面的示例中,通过直接在 arr 本身上定义 Symbol.iterator 属性绕过了原型。完成此修改后,在 arr 上查找 Symbol.iterator 会得到一个空迭代器,因此 arr 的展开结果没有任何元素,并且数组字面量计算结果为空数组。
const arr = [1, 2, 3];
arr[Symbol.iterator] = function() {
return { next: function() { return { done: true }; } };
};
const result = [...arr];
// → []
修改的 %ArrayIteratorPrototype%
next 方法也可以直接在 %ArrayIteratorPrototype% 上修改,即数组迭代器的原型(这会影响所有数组)。
Object.getPrototypeOf([][Symbol.iterator]()).next = function() {
return { done: true };
}
const arr = [1, 2, 3];
const result = [...arr];
// → []
处理稀疏数组
在复制稀疏数组时需要特别小心,即诸如 ['a', , 'c'] 这样的数组,它们缺少某些元素。展开这样的数组由于遵守迭代协议,不会保留稀疏部分,而是用数组原型中对应索引位置的值填充它们。默认情况下,数组的原型中没有任何元素,这意味着任何稀疏部分都将被填充为 undefined。例如,[['a', , 'c']] 的展开结果将是一个新的数组 ['a', undefined, 'c']。
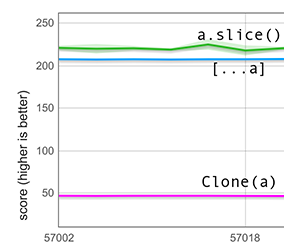
我们的快速路径足够智能,可以处理默认情况下的稀疏数组情况。它不会盲目地复制输入数组的底层存储,而是会识别出稀疏部分并将它们转换为 undefined 值。下图展示了一个长度为 100,000 的输入数组的性能测量,该数组仅包含 600 个(标记的)整数,其余部分稀疏。目前展开这样的稀疏数组的性能比使用 clone 函数快 4 倍以上。(此前两者性能大致相当,但这一点未显示在图中)。
请注意,尽管图中包含了 slice,但与其比较是不公平的,因为 slice 对稀疏数组有不同的语义:它保留所有稀疏部分,因此工作量少得多。
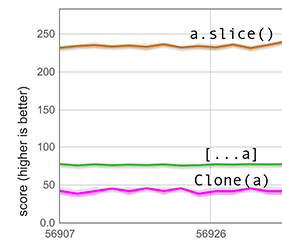
我们的快速路径需要填充稀疏部分为 undefined,但这并不像听起来那么简单:这可能需要将整个数组转换为不同的元素种类(elements kind)。下图测量了这样的情况。设置与上例相同,不同之处在于,此次 600 个数组元素是未封包的双精度数,并且数组具有 HOLEY_DOUBLE_ELEMENTS 元素种类。由于这种元素种类无法包含标记值(如 undefined),展开操作涉及昂贵的元素种类转换,因此 [...a] 的得分比前一张图显著降低。然而,它仍然比 clone(a) 快得多。
展开字符串、集合和映射
跳过迭代器对象并避免增长结果数组的想法同样适用于其他标准数据类型的展开。事实上,我们为原始字符串、集合和映射实现了类似的快速路径,每次都注意在修改后的迭代行为存在时绕过它们。
关于集合,快速路径不仅支持直接展开集合([...set]),还支持展开其键迭代器([...set.keys()])和值迭代器([...set.values()])。在我们的微基准测试中,这些操作现在比之前快约 18 倍。
Map的快速路径类似,但不支持直接展开一个Map([...map]),因为我们认为这是一个不常见的操作。同样原因,快速路径也不支持entries()迭代器。在我们的微基准测试中,这些操作现在比以前快了大约14倍。
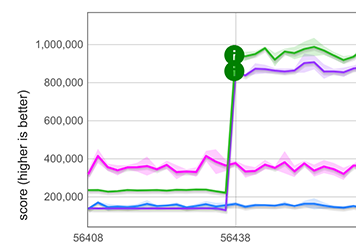
对字符串的展开操作([...string]),我们测量到了大约5倍的性能提升,如下图中的紫色和绿色线条所示。注意,这甚至比TurboFan优化的for-of循环更快(TurboFan理解字符串迭代并能够为此生成优化代码),用蓝色和粉色线条表示。在每种情况下都有两个图的原因是,这些微基准测试运行在两种不同的字符串表示(单字节字符串和双字节字符串)上。

提高Array.from性能
幸运的是,我们可以在Array.from的某些情况下重复利用展开元素的快速路径,比如Array.from使用可迭代对象并且没有映射函数时,例如Array.from([1, 2, 3])。这是可行的,因为在这种情况下,Array.from的行为与展开完全相同。这带来了巨大的性能提升,下面展示了对包含100个双精度数值的数组的结果。
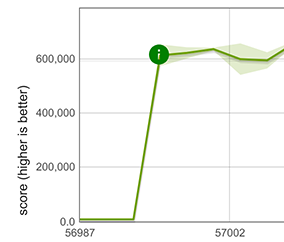
结论
V8 v7.2 / Chrome 72极大提高了数组字面值前部出现的展开元素的性能,例如[...x]或[...x, 1, 2]。此改进适用于展开数组、原始字符串、集合、Map键、Map值,以及通过扩展适用于Array.from(x)。