Jank克星第二部分:Orinoco
在之前的博客文章中,我们介绍了垃圾回收中断顺畅浏览体验导致的卡顿问题。在本文中,我们介绍了三种优化,这些优化为V8中的新垃圾回收器(代号为_Orinoco_)奠定了基础。Orinoco基于这样一个理念:实现一个大部分并行和并发的垃圾回收器,在没有严格代界限的情况下,可以减少垃圾回收的卡顿和内存消耗,同时提供高吞吐量。我们没有将Orinoco作为单独的垃圾回收器在标志后面实现,而是决定逐步在V8的主代码库中发布Orinoco的功能以便用户立即受益。本篇文章讨论的三个功能是并行压缩、并行记忆集处理和黑色分配。
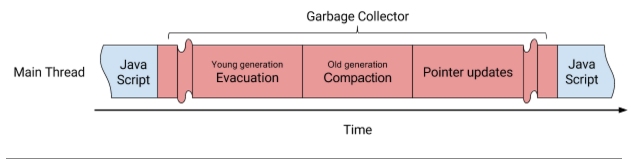
V8实现了一个代收集垃圾回收器,在这里对象可以在新生代内移动,从新生代移到老年代,以及在老年代内移动。移动对象是昂贵的,因为对象的底层内存需要复制到新位置,并且指向这些对象的指针也需要更新。图1展示了Orinoco之前的阶段及其执行方式。本质上,对象首先被移动,随后这些对象之间的指针被按顺序更新,从而导致了明显的卡顿。
V8将其堆内存划分为固定大小的块,称为页,这些页被分配给新生代空间或老年代空间。对象最初分配在新生代中。在垃圾回收时,活动对象会在新生代内移动一次。那些经历了另一次垃圾回收后仍然存活的对象会被提升到老年代。对于我们称为新生代清理的两阶段操作,我们基于页并行化了内存复制。在新生代内,移动对象总是涉及在新页上分配内存(并释放旧页),留下一个紧凑的内存布局。在老年代,这个过程有些不同,因为死亡内存会留下不可重用的空洞(碎片)。其中的一些空洞可以通过空闲列表重用,但其他则被遗弃,需要通过压缩将活动对象移动到一个更紧凑的(可能是新的)页面上。与新生代相似,这个过程在页面级别进行并行化。
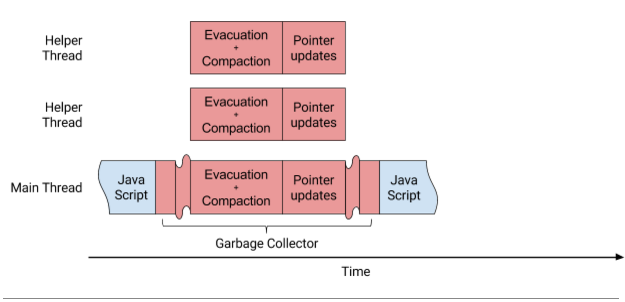
由于新生代清理和老年代压缩之间没有依赖关系,Orinoco现在并行执行这些阶段,如图2所示。这些改进的结果是压缩时间减少了75%,从约7毫秒降到平均2毫秒以下。
Orinoco引入的第二个优化改进了垃圾回收器如何跟踪指针。当对象在堆上的位置发生变化时,垃圾回收器必须找到所有包含被移动对象旧位置的指针,并用新位置更新它们。由于遍历堆以找到指针会非常慢,V8使用了一种称为_记忆集_的数据结构来跟踪堆上的所有相关指针。如果一个指针指向可能在垃圾回收期间移动的对象,那么它就是相关的。例如,从老年代到新生代的所有指针是相关的,因为新生代对象在每次垃圾回收时都会移动。指向高碎片页面中的对象的指针也是相关的,因为这些对象会在压缩过程中移动到其他页面。
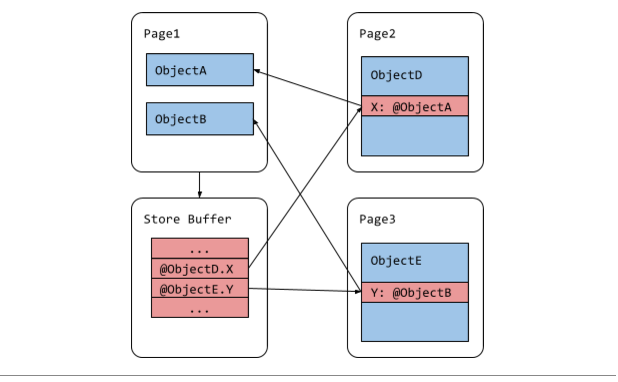
以前,V8将记忆集合实现为指针地址的数组,或者称之为_存储缓冲区_。年轻代有一个存储缓冲区,而每个被碎片化的老年代页面也有一个存储缓冲区。页面的存储缓冲区包含所有传入指针的地址,如图3所示。在JavaScript代码的写屏障中,条目会被附加到存储缓冲区中,写屏障会保护写操作。这可能导致重复条目,因为一个存储缓冲区可能多次包含同一指针,两个不同的存储缓冲区也可能包含相同的指针。重复的条目使指针更新阶段的并行化变得困难,因为两个线程尝试更新同一个指针,会引发数据竞争问题。
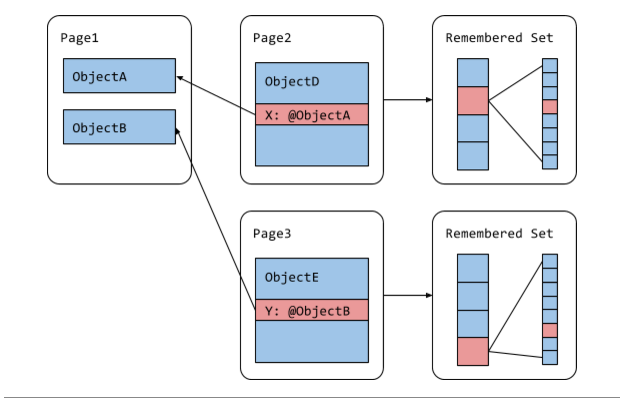
Orinoco通过重组记忆集合来简化并行化,并确保线程可以获得不相交的指针集合以进行更新,从而消除了这种复杂性。每个页面不再将传入的有趣指针存储在一个数组中,而是将页面上的有趣指针的偏移量存储在位图的桶中,如图4所示。每个桶要么为空,要么指向一个固定长度的位图。位图中的一个位对应页面中的一个指针偏移。如果某个位被设置,那么这个指针是有趣的,并且在记忆集合中。使用这种数据结构,我们可以基于页面来并行化指针更新。没有重复条目以及指针的密集表示还使我们能够移除处理记忆集合溢出的复杂代码。在我们运行的Gmail长期基准测试中,此更改减少了紧缩垃圾收集的最大暂停时间45%,从42ms减少到23ms。
Orinoco引入的第三个优化是_黑色分配_,一种改进垃圾收集器标记阶段的技术。黑色分配(在V8 5.1中推出)是一种垃圾收集技术,其中在老年代分配的所有对象(例如,预提前分配或由垃圾收集器晋升的对象)会立即被标记为黑色,以将它们指定为“存活”。黑色分配的直觉是,在老年代分配的对象可能具有较长生命周期。因此,新近在老年代分配的对象至少应该能够存活到下一次老年代垃圾收集,否则它们被错误地晋升。在将新分配的对象着色为黑色后,垃圾收集器将不再访问它们。我们通过在黑色页面上分配这些黑色对象来加快着色速度,其中页面上的所有对象默认是黑色的。黑色页面的另一个好处是不需要清扫,因为在它们上分配的所有对象(根据定义)都是存活的。黑色分配加快了增量标记进程,因为标记工作不会随着新分配而增加。在Octane Splay基准测试中,黑色分配的效果非常明显,其吞吐量和延迟分数提高了约30%,并且由于标记进程更快以及总体上垃圾收集工作减少,使用的内存减少了约20%。
我们计划很快推出更多Orinoco功能。敬请期待,我们仍在调整改进中!