V8 中快速的 `for`-`in`
for-in 是一种被许多框架广泛使用的语言特性。尽管它十分常见,但从实现角度来看,它是一种较为晦涩的语言构造。V8 付出了巨大努力,使得这一特性尽可能快。在过去的一年里,for-in 变得完全符合规范,并在某些情况下速度提高了 3 倍。
许多流行的网站在很大程度上依赖于 for-in,并从它的优化中受益。例如,在 2016 年初,Facebook 在启动过程中大约有 7% 的 JavaScript 时间花费在 for-in 的实现上。在 Wikipedia 上,这个数字甚至更高,接近 8%。通过改善某些慢速情况的性能,Chrome 51 显著提升了这两个网站的性能:


Wikipedia 和 Facebook 的总脚本时间由于各种 for-in 的改进提升了 4%。请注意,在同一时期,V8 的其他部分也变得更快,总的脚本性能改进超过了 4%。
在这篇博文的其余部分中,我们将解释如何在加速这一核心语言特性的同时修复一个长期存在的规范违反问题。
规范
TL;DR; 为性能原因,for-in 的迭代语义是模糊的。
当我们查看 for-in 的规范文本时,会发现它以一种意想不到的模糊方式书写,这在不同的实现中是可观察的。我们来看一个针对具有适当陷阱设置的 Proxy 对象迭代的示例。
const proxy = new Proxy({ a: 1, b: 1},
{
getPrototypeOf(target) {
console.log('getPrototypeOf');
return null;
},
ownKeys(target) {
console.log('ownKeys');
return Reflect.ownKeys(target);
},
getOwnPropertyDescriptor(target, prop) {
console.log('getOwnPropertyDescriptor name=' + prop);
return Reflect.getOwnPropertyDescriptor(target, prop);
}
});
在 V8/Chrome 56 中你会得到如下输出:
ownKeys
getPrototypeOf
getOwnPropertyDescriptor name=a
a
getOwnPropertyDescriptor name=b
b
相比之下,在 Firefox 51 中对同一代码片段的输出顺序不同:
ownKeys
getOwnPropertyDescriptor name=a
getOwnPropertyDescriptor name=b
getPrototypeOf
a
b
两个浏览器都尊重规范,但此次规范并未对指令的顺序做出明确的强制。为了更好地理解这些漏洞,我们来看看规范文本:
EnumerateObjectProperties ( O ) 当抽象操作 EnumerateObjectProperties 被传递参数 O 调用时,需执行以下步骤:
- 断言:Type(O) 是对象。
- 返回一个迭代器对象(25.1.1.2),其 next 方法迭代 O 的所有可枚举属性的字符串值键。迭代器对象不会被 ECMAScript 代码直接访问。枚举属性的机制和顺序未经明确说明,但需符合以下规则。
通常情况下,规范指令会精确说明具体的操作步骤。但在这种情况下,它们仅包含了一段简单的叙述,即使是执行顺序也交由实现者决定。通常出现这种情况的原因是,规范的这些部分是在 JavaScript 引擎已经有不同实现后才写出的。规范试图通过以下指令捆绑松散的情况:
- 迭代器的 throw 和 return 方法为 null 且永不会调用。
- 迭代器的 next 方法处理对象属性以确定属性键是否应作为迭代值返回。
- 返回的属性键不包括符号类型的键。
- 枚举期间目标对象的属性可能被删除。
- 在迭代器的 next 方法处理之前被删除的属性将被忽略。如在枚举期间新增属性,这些新增属性不保证在当前枚举中被处理。
- 任何枚举中,属性名称最多将被迭代器的 next 方法返回一次。
- 枚举目标对象的属性包括递归枚举其原型的属性及原型的原型的属性;但若原型的属性与迭代器已经处理过的属性同名,则原型的属性不会被处理。
- 在判断原型对象的属性是否已经被处理时,不会考虑
[[Enumerable]]属性的值。 - 必须通过调用EnumerateObjectProperties并将原型对象作为参数,获得原型对象的可枚举属性名。
- EnumerateObjectProperties必须通过调用目标对象的
[[OwnPropertyKeys]]内部方法来获取该对象自身的属性键。
这些步骤听起来很繁琐,不过规范也包含了一个明确且更易读的示例实现:
function* EnumerateObjectProperties(obj) {
const visited = new Set();
for (const key of Reflect.ownKeys(obj)) {
if (typeof key === 'symbol') continue;
const desc = Reflect.getOwnPropertyDescriptor(obj, key);
if (desc && !visited.has(key)) {
visited.add(key);
if (desc.enumerable) yield key;
}
}
const proto = Reflect.getPrototypeOf(obj);
if (proto === null) return;
for (const protoKey of EnumerateObjectProperties(proto)) {
if (!visited.has(protoKey)) yield protoKey;
}
}
既然已经看到这里,你可能已经注意到,上述示例中V8并没有严格遵循规范中的示例实现。首先,示例中的for-in生成器是增量式的,而V8是为了性能考虑,直接预先收集所有键。这是完全可以的,实际上规范文本明确表示,操作顺序A到J是未定义的。然而,正如本文稍后会提到的,直到2016年,V8在某些边界情况下并未完全遵循规范。
枚举缓存
for-in生成器的示例实现遵循了一种增量收集并生成键值的模式。在V8中,属性键值首先被收集,然后在迭代阶段被使用。这种方式让V8实现起来更简单。要理解原因,我们需要看看对象模型。
像{a:'value a', b:'value b', c:'value c'}这样的简单对象,在V8中可以有各种内部表示,如将在后续深入探讨属性的文章中所示。这意味着,根据属性的类型——是对象内的、快速的还是慢速的——实际的属性名会被存储在不同的地方。这使得收集可枚举键成为一项非平凡的任务。
V8通过隐藏类或所谓的Map来跟踪对象的结构。具有相同Map的对象具有相同的结构。此外,每个Map都有一个共享的数据结构,即描述符数组,包含每个属性的详细信息,如属性存储的位置、属性名以及枚举性等细节。
假设JavaScript对象已经达到最终形状,并且不会再添加或移除任何属性。在这种情况下,我们可以将描述符数组作为键值的来源。这在只有可枚举属性的情况下有效。为了避免每次都要过滤掉不可枚举的属性,V8使用一个单独的EnumCache,作为通过Map的描述符数组访问的枚举键的缓存。

由于V8假设慢速字典对象经常发生变化(如通过添加和删除属性),所以对于具有字典属性的慢速对象没有描述符数组。因此,V8不会为慢速属性提供EnumCache。类似的假设也适用于索引属性,因此它们同样被排除在EnumCache之外。
让我们总结一下重要的事实:
- Map用于跟踪对象形状。
- 描述符数组存储有关属性的信息(名称、可配置性、可见性)。
- 描述符数组可以在不同的Map之间共享。
- 每个描述符数组可以有一个EnumCache,仅列出可枚举的命名键,不包括索引属性名。
for-in的机制
现在你对Map如何工作以及EnumCache与描述符数组的关系有了部分了解。V8通过Ignition字节码解释器和TurboFan优化编译器来执行JavaScript,这两者以类似的方式处理for-in。为了简单起见,我们将使用一种伪C++样式来解释for-in在内部是如何实现的:
// For-In Prepare:
FixedArray* keys = nullptr;
Map* original_map = object->map();
if (original_map->HasEnumCache()) {
if (object->HasNoElements()) {
keys = original_map->GetCachedEnumKeys();
} else {
keys = object->GetCachedEnumKeysWithElements();
}
} else {
keys = object->GetEnumKeys();
}
// For-In Body:
for (size_t i = 0; i < keys->length(); i++) {
// For-In Next:
String* key = keys[i];
if (!object->HasProperty(key) continue;
EVALUATE_FOR_IN_BODY();
}
for-in可以分为三个主要步骤:
- 准备要迭代的键,
- 获取下一个键,
- 执行
for-in主体。
“准备”步骤是三者中最复杂的部分,这是EnumCache发挥作用的地方。在上面的例子中,如果存在EnumCache并且对象(及其原型)上没有元素(整数索引的属性),你可以看到V8直接使用EnumCache。如果存在索引属性名称,V8将跳转到一个用C++实现的运行时函数,该函数将这些索引属性添加到现有的enum cache中,如下例所示:
FixedArray* JSObject::GetCachedEnumKeysWithElements() {
FixedArray* keys = object->map()->GetCachedEnumKeys();
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* Map::GetCachedEnumKeys() {
// 从可能共享的枚举缓存中获取可枚举属性的键
FixedArray* keys_cache = descriptors()->enum_cache()->keys_cache();
if (enum_length() == keys_cache->length()) return keys_cache;
return keys_cache->CopyUpTo(enum_length());
}
FixedArray* FastElementsAccessor::PrependElementIndices(
JSObject* object, FixedArray* property_keys) {
Assert(object->HasFastElements());
FixedArray* elements = object->elements();
int nof_indices = CountElements(elements);
FixedArray* result = FixedArray::Allocate(property_keys->length() + nof_indices);
int insertion_index = 0;
for (int i = 0; i < elements->length(); i++) {
if (!HasElement(elements, i)) continue;
result[insertion_index++] = String::FromInt(i);
}
// 将属性键插入到末尾。
property_keys->CopyTo(result, nof_indices - 1);
return result;
}
如果没有找到现有的EnumCache,我们再次跳转到C++并遵循最初介绍的规范步骤:
FixedArray* JSObject::GetEnumKeys() {
// 获取接收者的枚举键。
FixedArray* keys = this->GetOwnEnumKeys();
// 遍历原型链。
for (JSObject* object : GetPrototypeIterator()) {
// 将非重复的键添加到列表中。
keys = keys->UnionOfKeys(object->GetOwnEnumKeys());
}
return keys;
}
FixedArray* JSObject::GetOwnEnumKeys() {
FixedArray* keys;
if (this->HasEnumCache()) {
keys = this->map()->GetCachedEnumKeys();
} else {
keys = this->GetEnumPropertyKeys();
}
if (this->HasFastProperties()) this->map()->FillEnumCache(keys);
return object->GetElementsAccessor()->PrependElementIndices(object, keys);
}
FixedArray* FixedArray::UnionOfKeys(FixedArray* other) {
int length = this->length();
FixedArray* result = FixedArray::Allocate(length + other->length());
this->CopyTo(result, 0);
int insertion_index = length;
for (int i = 0; i < other->length(); i++) {
String* key = other->get(i);
if (other->IndexOf(key) == -1) {
result->set(insertion_index, key);
insertion_index++;
}
}
result->Shrink(insertion_index);
return result;
}
这段简化的C++代码对应了V8中的实现,直到2016年初我们开始研究UnionOfKeys方法。如果你仔细观察,你会发现我们使用了一个天真的算法来从列表中排除重复项,这在原型链上有许多键的情况下可能导致性能问题。这就是我们决定进行以下部分的优化的原因。
for-in的问题
正如我们在上一节中暗示的,UnionOfKeys方法在最坏情况下具有糟糕的性能。它基于一个合理的假设,即大多数对象具有快速属性,因此将从EnumCache中受益。第二个假设是原型链上的可枚举属性很少,从而限制了找到重复项所消耗的时间。然而,如果对象具有缓慢的字典属性并且原型链上有许多键,UnionOfKeys就会成为一个瓶颈,因为我们每次进入for-in时都需要收集可枚举属性的名称。
除了性能问题外,现有的算法还有一个问题,即它不符合规范。以下示例多年间在V8中运行的结果是错误的:
var o = {
__proto__ : {b: 3},
a: 1
};
Object.defineProperty(o, 'b', {});
for (var k in o) console.log(k);
输出:
a
b
或许看起来反直觉,实际上这应该只打印出a,而不是a和b。如果你回想一下本文开头的规范文本,步骤G和J暗示接收者上的不可枚举属性会遮蔽原型链上的属性。
使事情更复杂的是,ES6引入了proxy对象。这破坏了许多V8代码的假设。为了以符合规范的方式实现for-in,我们需要触发以下13种proxy陷阱中的5种:
| 内部方法 | 处理器方法 |
|---|---|
[[GetPrototypeOf]] | getPrototypeOf |
[[GetOwnProperty]] | getOwnPropertyDescriptor |
[[HasProperty]] | has |
[[Get]] | get |
[[OwnPropertyKeys]] | ownKeys |
这需要一个原始 GetEnumKeys 代码的副本版本,该代码试图更紧密地遵循规范示例实现。ES6 的代理以及处理属性遮罩的缺乏是我们在 2016 年初重新设计如何提取 for-in 的所有键的核心动机。
KeyAccumulator
我们引入了一个单独的辅助类 KeyAccumulator,用于处理收集 for-in 的键的复杂性。随着 ES6 规范的不断发展,像 Object.keys 或 Reflect.ownKeys 这样的新功能需要其自己稍作修改的键收集版本。通过设置单一的可配置的位置,我们可以提高 for-in 的性能并避免代码重复。
KeyAccumulator 包括一个仅支持有限操作但非常高效完成这些操作的快速部分。慢速累加器支持所有复杂情况,比如 ES6 的代理。

为了正确过滤掉遮罩属性,我们必须维护一个单独的非枚举属性列表,这些属性是迄今为止我们已经看到的。出于性能原因,我们只在发现对象的原型链上存在枚举属性后才会执行此操作。
性能改进
有了 KeyAccumulator,一些模式就变得可以优化了。第一个是避免原始 UnionOfKeys 方法中的嵌套循环,这会导致缓慢的极端情况。第二步是执行更详细的预检查,以利用现有的 EnumCaches 并避免不必要的复制步骤。
为了说明规范兼容的实现更快,我们来看以下四种不同的对象:
var fastProperties = {
__proto__ : null,
'property 1': 1,
…
'property 10': n
};
var fastPropertiesWithPrototype = {
'property 1': 1,
…
'property 10': n
};
var slowProperties = {
__proto__ : null,
'dummy': null,
'property 1': 1,
…
'property 10': n
};
delete slowProperties['dummy']
var elements = {
__proto__: null,
'1': 1,
…
'10': n
}
fastProperties对象有标准的快速属性。fastPropertiesWithPrototype对象通过使用Object.prototype在原型链上有额外的非枚举属性。slowProperties对象有慢速字典属性。elements对象只有索引属性。
以下图表比较了在没有优化编译器帮助的情况下,在一个紧密的循环中运行一百万次 for-in 循环的原始性能。
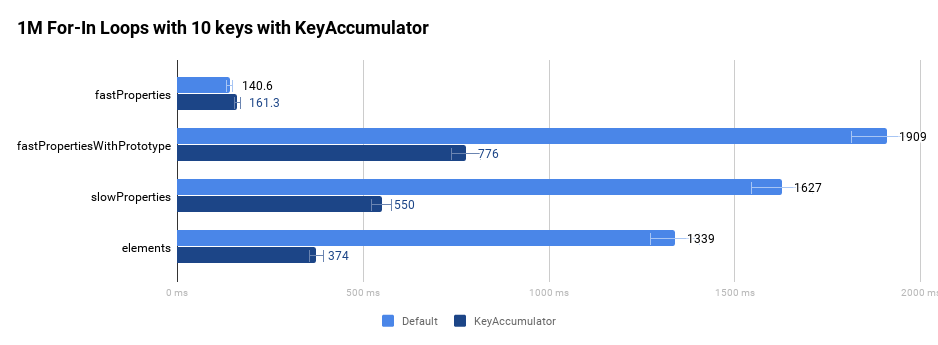
如我们在引言中所述,这些改进在特别是维基百科和 Facebook 上变得非常明显。
除了在 Chrome 51 中的初始改进外,第二次性能调整又带来了显著的改进。下图显示了我们在 Facebook 页面启动期间脚本总时间的跟踪数据。选定的范围大约在 V8 修订版 37937 周围,相当于额外的 4% 性能改进!

为了强调改进 for-in 的重要性,我们可以依赖一个工具的数据,该工具是我们在 2016 年构建的,它允许我们在一组网站上提取 V8 测量值。下表显示了 Chrome 49 在大约 25 个代表性真实网站 上 V8 C++ 入口点(运行时函数和内置函数)中花费的相对时间。
| 排序 | 名称 | 总时间 |
|---|---|---|
| 1 | CreateObjectLiteral | 1.10% |
| 2 | NewObject | 0.90% |
| 3 | KeyedGetProperty | 0.70% |
| 4 | GetProperty | 0.60% |
| 5 | ForInEnumerate | 0.60% |
| 6 | SetProperty | 0.50% |
| 7 | StringReplaceGlobalRegExpWithString | 0.30% |
| 8 | HandleApiCallConstruct | 0.30% |
| 9 | RegExpExec | 0.30% |
| 10 | ObjectProtoToString | 0.30% |
| 11 | ArrayPush | 0.20% |
| 12 | NewClosure | 0.20% |
| 13 | NewClosure_Tenured | 0.20% |
| 14 | ObjectDefineProperty | 0.20% |
| 15 | HasProperty | 0.20% |
| 16 | StringSplit | 0.20% |
| 17 | ForInFilter | 0.10% |