嵌入的内置函数
V8内置函数(builtins)在每个V8实例中都会消耗内存。内置函数的数量、平均大小以及每个Chrome浏览器标签页中的V8实例数量显著增长。这篇博客描述了过去一年中我们如何将每个网站的V8堆大小中值减少19%。
背景
V8附带了一个广泛的JavaScript (JS) 内置函数库。许多内置函数直接作为安装在JS内置对象上的函数暴露给JS开发者,例如RegExp.prototype.exec和Array.prototype.sort;其他内置函数则实现了各种内部功能。内置函数的机器代码由V8自己编译器生成,并在每个V8实例初始化时加载到托管堆状态中。一个Isolate代表V8引擎的一个独立实例,每个Chrome浏览器标签页至少包含一个Isolate。每个Isolate都有自己的托管堆,因此也有自己的所有内置函数副本。
早在2015年,大部分内置函数是用自托管的JS、本地汇编或C++实现的。它们比较小,为每个Isolate生成一个副本相对问题较小。
这一领域在过去几年中发生了很大的变化。
2016年,V8开始使用CodeStubAssembler (CSA)实现内置函数的实验。这被证明既方便(跨平台、可读性好),又能生成高效代码,因此CSA内置函数变得普遍。出于多种原因,CSA内置函数往往会生成更大的代码,随着越来越多的函数迁移到CSA,V8内置函数的大小大约增加了三倍。到2017年中旬,它们的每个Isolate的开销显著增加,我们开始考虑系统性的解决方案。
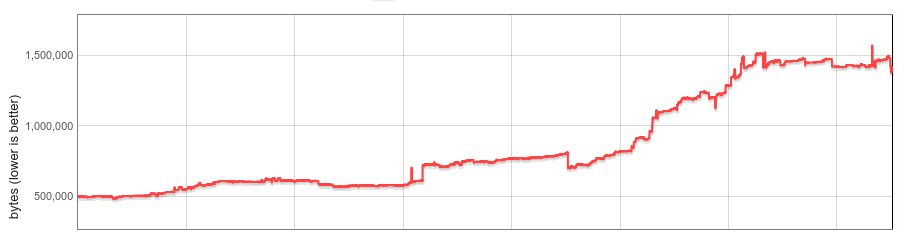
2017年底,我们作为第一步实现了懒加载内置函数(以及字节码处理程序)反序列化。我们的初步分析表明,大多数网站使用的内置函数不到一半。通过懒加载反序列化,内置函数按需加载,未使用的内置函数永远不会加载到Isolate中。懒加载反序列化在Chrome 64中发布,带来了可观的内存节省。但:内置函数的内存开销仍然随Isolate数量线性增长。
随后,Spectre漏洞被披露,Chrome最终启用了站点隔离以减少其影响。站点隔离限制了Chrome渲染进程只能处理单一来源的文档。因此,随着站点隔离,许多浏览标签会创建更多的渲染进程和更多的V8 Isolate。尽管管理每个Isolate的开销一直很重要,但站点隔离使其变得更加重要。
嵌入的内置函数
我们这个项目的目标是完全消除每个Isolate的内置函数开销。
其背后的想法很简单。从概念上讲,内置函数在各个Isolate间是相同的,只是由于实现细节才绑定到一个Isolate上。如果我们能使内置函数真正与Isolate无关,我们就可以在内存中保留一个副本,并在所有Isolate之间共享它们。如果我们能使它们与进程独立,它们甚至可以跨进程共享。
实际上,我们面临几个挑战。生成的内置代码由于嵌入的指针指向Isolate和进程特定的数据,而既非Isolate独立,也非进程独立。V8没有执行位于托管堆外部的生成代码的概念。内置函数必须跨进程共享,理想情况下通过复用现有的操作系统机制实现。最后(事实证明这是一个漫长的过程),性能不能明显下降。
以下部分详细描述了我们的解决方案。
与Isolate和进程独立的代码
内置函数由V8的内部编译管道生成,其中嵌入了对堆常量(位于Isolate的托管堆)、调用目标(也在托管堆中的Code对象)和Isolate及进程特定地址的引用(例如:C运行时函数或一个指向Isolate本身的指针,这也被称为“外部引用”)直接嵌入到代码中。在x64汇编中,对这样的对象加载可能如下所示:
// 将嵌入地址加载到寄存器rbx。
REX.W movq rbx,0x56526afd0f70
V8有一个正在运行的垃圾回收器,目标对象的位置可能会随着时间改变。如果在回收期间目标对象被移动,GC会更新生成的代码以指向新位置。
在x64(以及大多数其他架构)上,对其他Code对象的调用使用了一种高效的调用指令,该指令通过一个从当前程序计数器开始的偏移量指定调用目标(一个有趣的细节是:V8在启动时预留了整个CODE_SPACE,确保所有可能的Code对象都在彼此可寻址的偏移量内)。相关的调用序列如下所示:
// 调用指令位于 [pc + <偏移量>]。
call <偏移量>
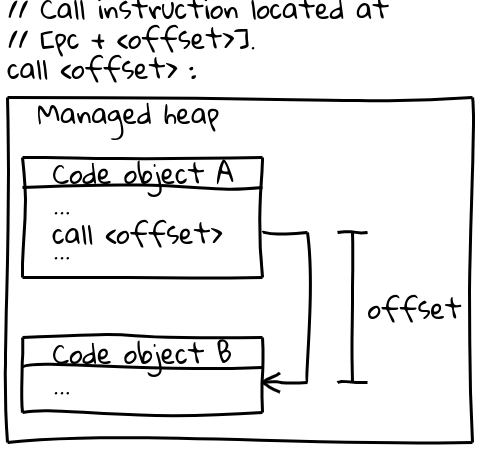
Code对象本身位于托管堆中,是可移动的。当它们被移动时,GC会更新所有相关调用点的偏移量。
为了跨进程共享内置代码,生成的代码必须是不可变的,并且与隔离和进程无关。上面两个指令序列都不符合这些要求:它们在代码中直接嵌入地址,并在运行时由GC进行修改。
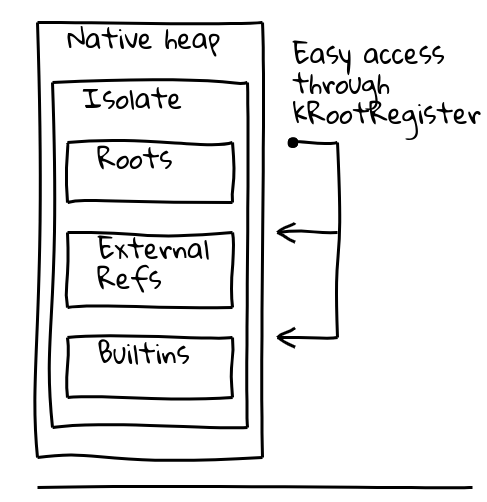
为了解决这两个问题,我们引入了一个专用的所谓根寄存器的间接方式,它保存了当前Isolate已知位置的指针。
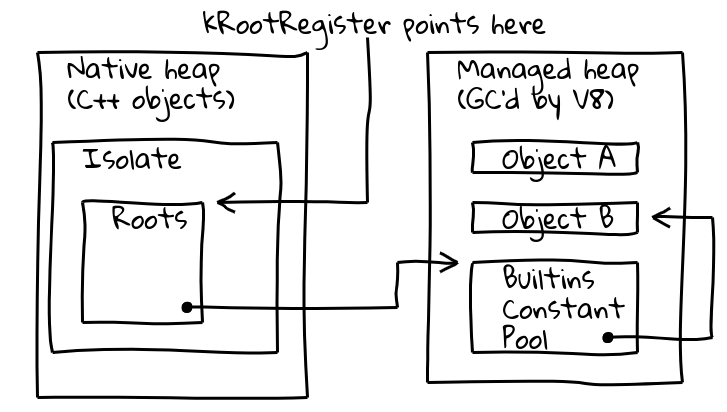
V8的Isolate类包含根表,根表本身包含指向托管堆上的根对象的指针。根寄存器始终保持根表的地址。
新的与隔离和进程无关的加载根对象的方法如下:
// 加载位于根表中给定偏移量处的常量地址。
REX.W movq rax,[kRootRegister + <偏移量>]
根堆的常量可以像上面这样直接从根列表加载。其他堆上的常量通过全球内置常量池的额外间接方式加载,该常量池本身也存储在根列表中:
// 加载内置常量池,然后加载所需的常量。
REX.W movq rax,[kRootRegister + <偏移量>]
REX.W movq rax,[rax + 0x1d7]
对于Code目标,我们最初转换为一个更复杂的调用序列,通过全球内置常量池加载目标Code对象,加载目标地址到寄存器,然后最终进行间接调用。
有了这些更改,生成的代码变得与隔离和进程无关,我们可以开始着手实现跨进程共享。
跨进程共享
我们最初评估了两种替代方案。内置代码可以通过将数据blob文件mmap到内存来共享;或者,它们可以直接嵌入到二进制文件中。我们选择了后者,因为它具有利用操作系统的标准机制在进程之间共享内存的优点,同时这种变更无需V8嵌入者(例如Chrome)进行额外的逻辑修改。我们对这种方法充满信心,因为Dart的AOT编译已经成功地将生成的代码嵌入到二进制文件中。
可执行二进制文件分为几个部分。例如,一个ELF二进制文件包含数据在.data(已初始化数据)、.ro_data(已初始化的只读数据)、.bss(未初始化数据)部分,而本地可执行代码放置在.text中。我们的目标是将内置代码与本地代码一起打包到.text部分中。
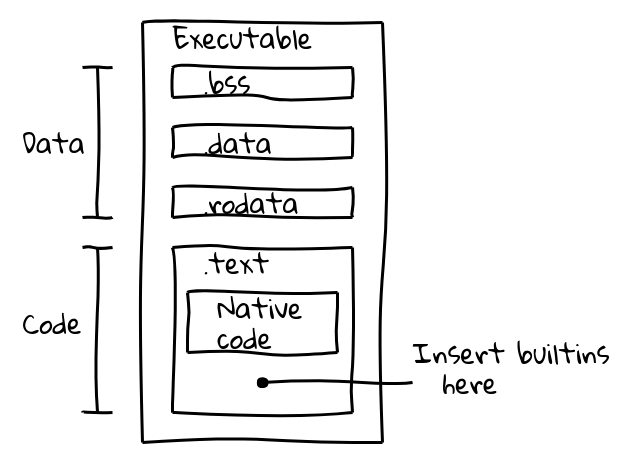
这是通过引入一个新的构建步骤来实现的,该步骤使用V8的内部编译管道为所有内置代码生成本地代码,并将其内容输出到embedded.cc中。然后,该文件被编译到最终的V8二进制文件中。
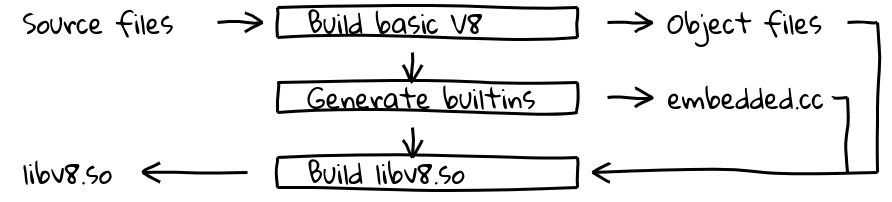
文件embedded.cc本身包含元数据和生成的内置机器代码,这些机器代码以一系列.byte指令出现,指示C++编译器(在我们的例子中是clang或gcc)将指定的字节序列直接放置到输出对象文件(以及后续的可执行文件)中。
// 包含有关嵌入内置的信息的元数据表。
V8_EMBEDDED_TEXT_HEADER(v8_Default_embedded_blob_)
__asm__(".byte 0x65,0x6d,0xcd,0x37,0xa8,0x1b,0x25,0x7e\n"
[省略元数据]
// 接着是生成的机器代码。
__asm__(V8_ASM_LABEL("Builtins_RecordWrite"));
__asm__(".byte 0x55,0x48,0x89,0xe5,0x6a,0x18,0x48,0x83\n"
[省略内置代码]
.text部分的内容在运行时映射为只读可执行内存,并且只要其中只包含位置无关代码而没有可重定位符号,操作系统就会在进程之间共享内存。这正是我们想要的。
但是 V8 的 Code 对象不仅包含指令流,还包括各种(有时与隔离状态相关的)元数据。普通的 Code 对象将元数据和指令流打包到一个可变大小的 Code 对象中,该对象位于托管堆上。
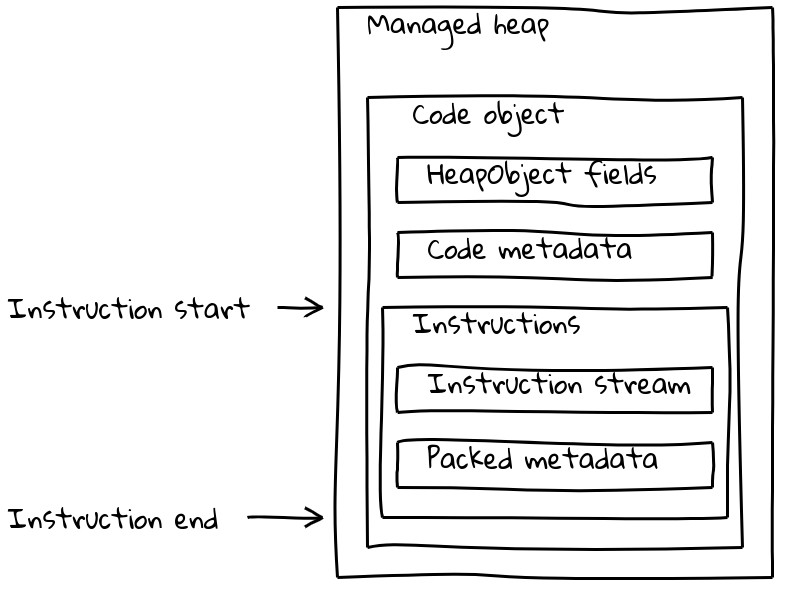
如我们已经看到的,嵌入式内建函数将其本机指令流置于托管堆外,嵌入到 .text 部分中。为了保留其元数据,每个嵌入式内建函数还会在托管堆上关联一个小型的 Code 对象,称为 堆外跳板。元数据存储在跳板上,与标准 Code 对象相同,而内联的指令流只包含一小段加载嵌入指令地址并跳转到该地址的序列。
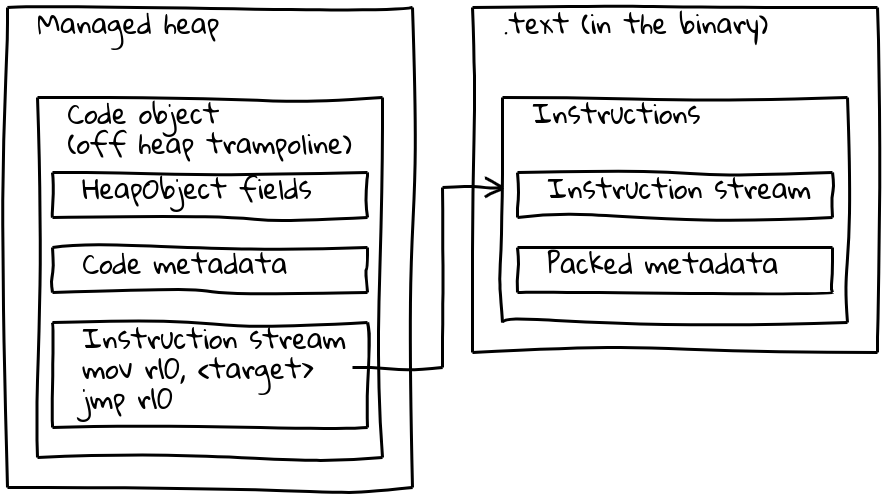
跳板使 V8 可以统一处理所有 Code 对象。在大多数情况下,给定的 Code 对象是托管堆上的标准代码还是嵌入式内建函数都无关紧要。
性能优化
根据前面各节描述的解决方案,嵌入式内建函数基本上功能全面,但基准测试显示引入了显著的性能降低。例如,我们的初始解决方案使 Speedometer 2.0 整体性能下降了超过 5%。
我们开始寻找优化机会,并确定了主要的性能降低来源。生成的代码由于频繁的间接访问与隔离状态和进程相关对象而变慢。根常量通过根列表加载(1 次间接访问),其他堆常量通过全局内建常量池加载(2 次间接访问),而外部引用还需要从堆对象中解包(3 次间接访问)。最严重的问题是我们新的调用序列,它需要加载跳板 Code 对象、调用它,然后再跳转到目标地址。最后,从托管堆和二进制嵌入代码之间的调用似乎本质上更慢,可能是由于远距离跳转干扰了 CPU 的分支预测。
因此我们的工作集中在 1. 减少间接访问,2. 改进内建函数的调用序列。为了实现前者,我们修改了 Isolate 对象的布局,使大多数对象加载转变为单次根相对加载。全局内建常量池仍然存在,但仅包含不常被访问的对象。
调用序列在两个方面得到了显著改进。内建函数之间的调用被转换为单次 pc 相对调用指令。这对于运行时生成的 JIT 代码来说是不可能的,因为 pc 相对偏移可能超过最大 32 位值。在这种情况下,我们将堆外跳板内联到所有调用点中,将调用序列从 6 条指令减少到仅 2 条指令。
通过这些优化,我们能够将 Speedometer 2.0 的性能回归限制在大约 0.5%。
结果
我们在 x64 上评估了嵌入式内建函数对前 10k 最受欢迎网站的影响,并与延迟和急速反序列化(如前所述)进行了比较。
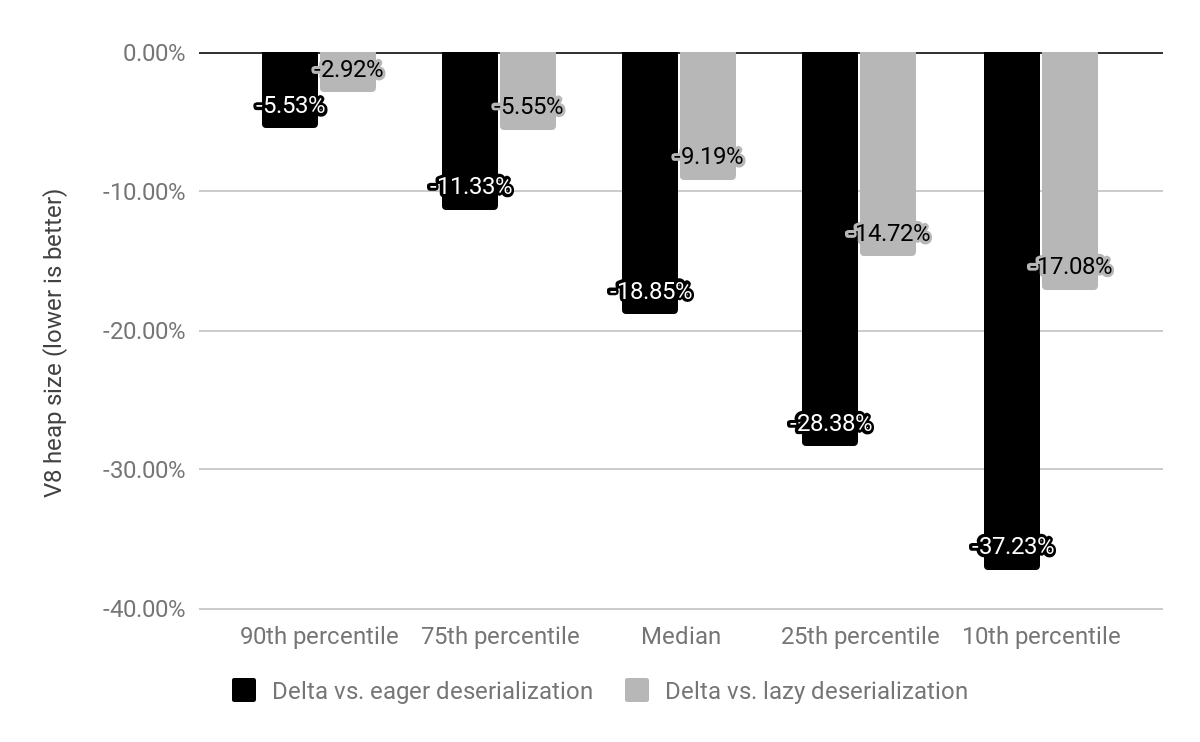
以前 Chrome 会携带一个内存映射快照,在每个 Isolate 上反序列化该快照,现在快照被嵌入式内建函数所取代,这些函数仍然是内存映射的但无需反序列化。内建函数的成本过去是 c*(1 + n),其中 n 是 Isolate 的数量,c 是所有内建函数的内存成本,而现在仅为 c * 1(实际上,每个 Isolate 的堆外跳板仍保留一小部分开销)。
与急速反序列化相比,我们将 V8 堆大小的中位数减少了 19%。每个网站的 Chrome 渲染器进程大小中位数下降了 4%。从绝对数字来看,第 50 百分位节省了 1.9 MB,第 30 百分位节省了 3.4 MB,第 10 百分位节省了 6.5 MB。
一旦字节码处理器也实现了二进制嵌入,预计将产生更多显著的内存节省。
嵌入式内建函数正在 Chrome 69 上在 x64 平台推出,移动平台将在 Chrome 70 中跟进。预计 ia32 的支持将在 2018 年底发布。
注意: 所有图表均通过 Vyacheslav Egorov 的出色工具 Shaky Diagramming 生成。