2019 年 JavaScript 的成本
注意: 如果你更喜欢观看演讲而不是阅读文章,请欣赏以下视频!如果不是,请跳过视频继续阅读。
过去几年 JavaScript 的成本 的一个重大变化是浏览器解析和编译脚本的速度有所提高。在 2019 年,处理脚本的主要成本现在是下载和 CPU 执行时间。
如果浏览器的主线程忙于执行 JavaScript,用户交互可能会被延迟,因此优化脚本执行时间和网络瓶颈可以产生重大影响。
可操作的高级指导
这对网络开发者意味着什么?解析和编译成本不再像我们曾经认为的那么慢。JavaScript 包的三个重点是:
- 提高下载时间
- 将你的 JavaScript 包保持小型化,特别是针对移动设备。小型包可以提高下载速度,降低内存使用并减少 CPU 成本。
- 避免只有一个大的包;如果一个包超过约 50–100 kB,请将其拆分成几个较小的包。(使用 HTTP/2 多路复用,多条请求和响应消息可以同时在传输中,从而降低额外请求的开销。)
- 在移动设备上,你需要传送更少的内容,尤其是由于网络速度原因,同时也要保持较低的内存使用。
- 提高执行时间
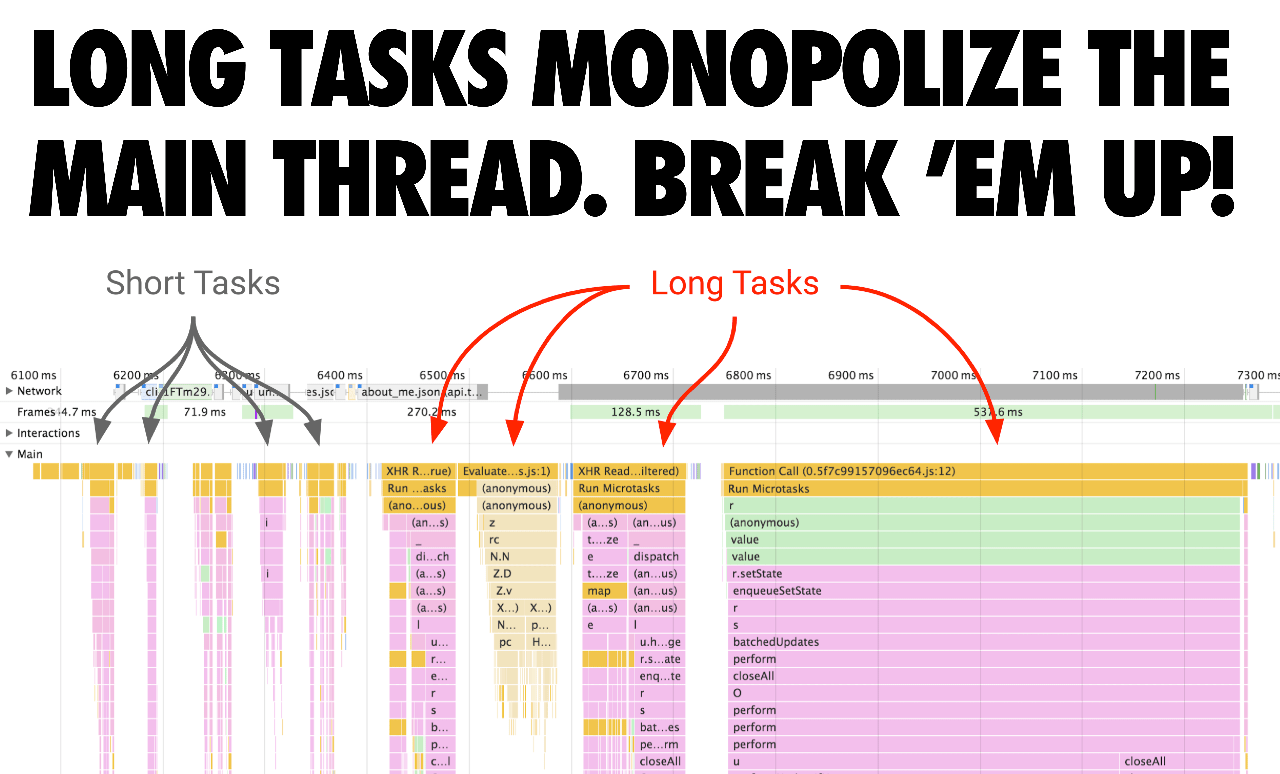
- 避免 长任务 它们可能使主线程忙于处理,并延迟页面互动的时间。下载完成后,脚本执行时间现在是一个主要成本。
- 避免大的内联脚本(因为它们仍然在主线程上被解析和编译)。一个好的经验法则是:如果脚本超过 1 kB,请避免内联(同时因为 1 kB 是 代码缓存 对外部脚本开始生效的临界值)。
为什么下载和执行时间很重要?
为什么优化下载和执行时间非常重要?下载时间对低端网络来说至关重要。尽管全球范围内 4G(甚至 5G)的普及在增加,我们的 有效连接类型 仍然不稳定,许多人在外出时会遇到看似 3G(或更糟)的网络速度。
JavaScript 执行时间对 CPU 慢速的手机来说非常重要。由于 CPU、GPU 和热节流的差异,高端手机和低端手机之间的性能存在巨大差异。这对 JavaScript 的性能至关重要,因为执行是受 CPU 限制的。
实际上,在像 Chrome 这样的浏览器中页面加载的总时间,有高达 30% 的时间可能用于 JavaScript 执行。以下是一个作为典型工作负载的站点(Reddit.com)在高端桌面设备上的页面加载情况:

在移动设备上,一个中档手机(Moto G4)执行 Reddit 的 JavaScript 所需时间是高端设备(Pixel 3)的 3–4 倍,而低端设备(售价 <$100 的 Alcatel 1X)则需要 6 倍以上的时间:

注意: Reddit 在桌面和移动网络上有不同的体验,因此 MacBook Pro 的结果无法与其他结果进行比较。
当你试图优化 JavaScript 执行时间时,需要注意可能长时间占用 UI 线程的长任务。即使页面看起来已经准备就绪,这些任务可能会阻碍关键任务的执行。将这些任务拆分为更小的任务。通过拆分代码并优先处理加载顺序,可以更快地让页面变得可交互,并降低输入延迟。
V8 为改进解析/编译做了哪些努力?
自 Chrome 60 起,V8 的原始 JavaScript 解析速度提高了 2 倍。同时,由于 Chrome 中其它并行化优化工作的推进,原始解析(和编译)成本变得不那么显眼/重要。
V8 通过在工作线程上解析和编译,仅在主线程上进行了平均 40% 的解析和编译工作减少(例如 Facebook 上减少 46%,Pinterest 上减少 62%),最高提升达到 81%(YouTube)。这使得主线程外的流式解析/编译得以实现。

我们还可以通过 Chrome 发布版中不同版本的 V8 来可视化这些变化对 CPU 时间的影响。在 Chrome 61 解析 Facebook 的 JS 所需的时间内,Chrome 75 现在可以解析 Facebook 的 JS 和 Twitter 的 JS 6 倍。

让我们探讨一下这些变化是如何实现的。简单来说,脚本资源可以在工作线程上以流式方式解析和编译,这意味着:
- V8 可以解析+编译 JavaScript 而不阻塞主线程。
- 一旦完整的 HTML 解析器遇到
<script>标签,就会启动流式解析。对于阻塞解析的脚本,HTML 解析器会暂停,而对于异步脚本则继续。 - 对于大多数实际的网络连接速度来说,V8 的解析速度比下载速度更快,因此 V8 会在下载最后一个脚本字节后的几毫秒内完成解析和编译。
稍微详细一些的解释是……更旧版本的 Chrome 会在完全下载脚本后再开始解析,这是一种简单的方法,但没有充分利用 CPU。在 41 到 68 版本之间,Chrome 开始在下载开始时对异步和延迟脚本在单独的线程上进行解析。

在 Chrome 71 中,我们转向基于任务的设置,调度器能够一次解析多个异步/延迟脚本。这一变化的影响是主线程解析时间减少约 20%,实际网站上的 TTI/FID 整体改善约 2%。

在 Chrome 72 中,我们切换到使用流式解析作为主要方法:现在甚至常规的同步脚本也以这种方式解析(但内联脚本除外)。我们还停止了在主线程需要时取消基于任务的解析,因为这样只会不必要地重复已经完成的工作。
以前的 Chrome 版本支持流式解析和编译,但来自网络的脚本源数据必须先传递到 Chrome 的主线程,然后再转发给流处理器。
这通常导致流式解析器等待已经从网络传入的数据,但由于被主线程上的其他工作(如 HTML 解析、布局或 JavaScript 执行)阻塞,尚未转发给流式任务。
我们现在正在尝试在预加载时启动解析,而主线程的阻塞此前是一个障碍。
Leszek Swirski 的 BlinkOn 演示提供了更多细节:
这些变化在 DevTools 中如何体现?
除了上面提到的内容之外,DevTools 中有一个问题,呈现了解析器任务的整体状态,暗示它正在使用 CPU(完整块)。然而,解析器在数据不够(需要通过主线程)时会阻塞。由于我们从单一流线程转变为流式任务,这变得非常明显。以下是你可能在 Chrome 69 中见到的情况:

“解析脚本”任务显示耗时1.08秒。然而,解析JavaScript并没有这么慢!大部分时间都花在等待数据通过主线程上传输。
Chrome 76展示了不同的情况:
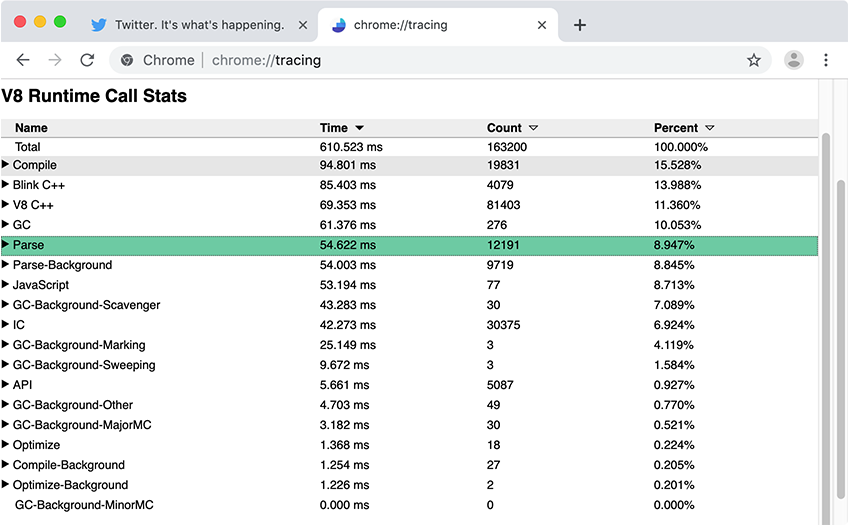
一般来说,开发者工具的性能面板非常适合获取页面上发生的高层次概况。对于详细的V8特定指标(例如JavaScript解析和编译时间),我们推荐使用带Runtime Call Stats (RCS)的Chrome Tracing。在RCS的结果中,Parse-Background 和 Compile-Background 表示在非主线程上解析和编译JavaScript所花费的时间,而 Parse 和 Compile 捕获的是主线程的相关指标。
这些变化对实际使用有什么影响?
让我们来看看一些实际网站的案例以及脚本流式解析的应用。

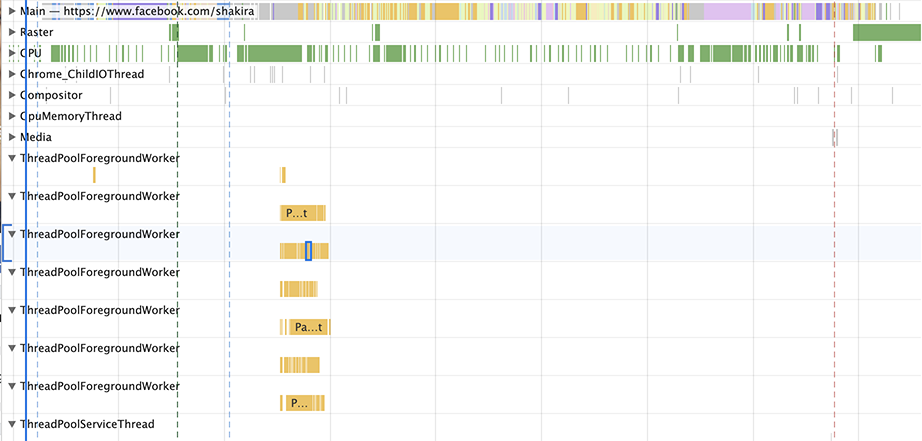
Reddit.com有多个100 kB以上的包裹,这些包裹被外函数包装,导致主线程上大量延迟编译。在上面的图表中,主要线程的时间才真正重要,因为主线程的繁忙可能会延迟页面交互。Reddit几乎所有时间都花在了主线程上,对Worker/Background线程的使用非常少。
他们可以通过将一些较大的包分割成较小的包(例如每个50 kB)并避免包装来提高并行化——这样每个包可以分别进行流式解析和编译,从而在启动时减少主线程的解析/编译时间。

我们也可以看看像Facebook.com这样的站点。Facebook通过约292个请求加载了约6MB压缩的JavaScript,其中一些是异步加载,一些是预加载,还有一些是以较低优先级获取的。他们的很多脚本都非常小而且粒度细——这可以在后台/Worker线程上帮助整体的并行化,因为这些较小的脚本可以同时进行流式解析/编译。
请注意,你可能不是Facebook,可能没有像Facebook或Gmail这样的长生命周期应用,桌面端这么多脚本可能不合理。然而,总的来说,将你的包保持粗粒度并仅加载你需要的内容。
虽然大多数JavaScript解析和编译工作可以在后台线程以流式方式完成,但仍有一些工作需要在主线程上进行。当主线程繁忙时,页面无法响应用户输入。请注意代码的下载和执行对用户体验的影响。
:::注意 注意: 当前,并非所有JavaScript引擎和浏览器都实现了作为加载优化的脚本流式处理。然而,我们仍然相信这里总体的指导可以带来良好的用户体验。 :::
解析JSON的成本
由于JSON语法比JavaScript的语法更简单,JSON可以比JavaScript更高效地解析。这一知识可以应用于改进大型JSON形式配置对象字面量(比如内联Redux存储)的Web应用启动性能。与其将数据内联为JavaScript对象字面量,如下所示:
const data = { foo: 42, bar: 1337 }; // 🐌
…可以以JSON字符串形式表示,然后在运行时进行JSON解析:
const data = JSON.parse('{"foo":42,"bar":1337}'); // 🚀
只要JSON字符串仅被解析一次,与JavaScript对象字面量相比,使用JSON.parse方法会更快,尤其是冷启动时。一个好的经验法则是对大小达到10 kB或更大的对象应用这种技巧——但和所有性能建议一样,在做出任何更改之前请测量实际影响。

以下视频更详细地讲解了性能差异的来源,从02:10时间开始。
JSON.parse 提升应用速度”,由Mathias Bynens在#ChromeDevSummit 2019上展示。请参阅我们的 JSON ⊂ ECMAScript 功能解释以获取一个示例实现,该示例能够根据任意对象生成一个有效的 JavaScript 程序以 JSON.parse 它。
在处理大量数据时使用普通对象字面量有一个额外的风险:它们可能会被_解析两次_!
- 第一次解析发生在字面量被预解析时。
- 第二次解析发生在字面量被延迟解析时。
第一次解析无法避免。幸运的是,通过将对象字面量放置在顶层或一个 PIFE 中,可以避免第二次解析。
重复访问时解析/编译怎么办?
V8 的(字节)代码缓存优化可以提供帮助。当第一次请求一个脚本时,Chrome 下载并将其提供给 V8 进行编译。它还将该文件存储在浏览器的磁盘缓存中。当第二次请求该 JS 文件时,Chrome 从浏览器缓存中取出该文件,再次提供给 V8 进行编译。不过,这次编译后的代码会被序列化,并作为元数据附加到缓存的脚本文件中。
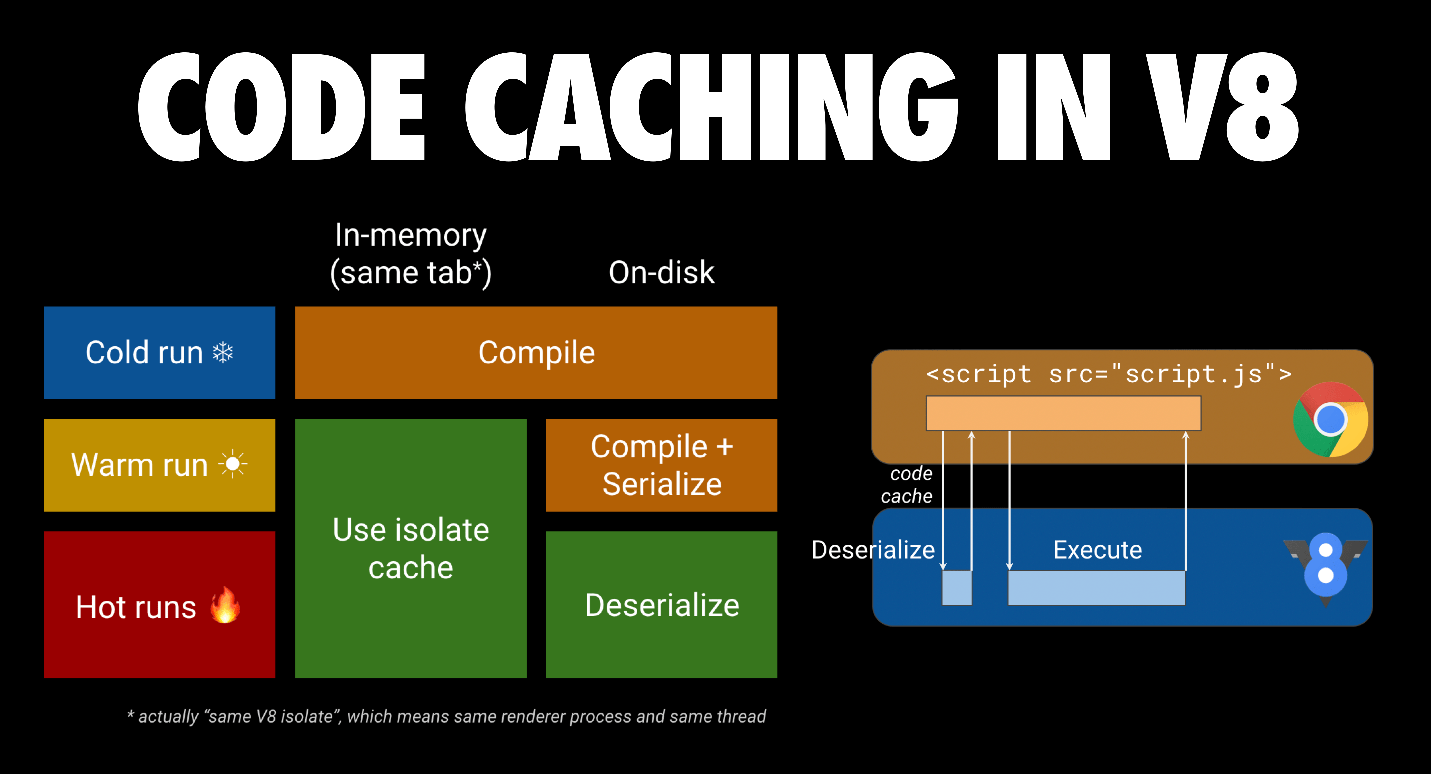
到了第三次,Chrome 从缓存中取出文件及其元数据,然后一并交给 V8。V8 反序列化元数据,可以跳过编译。如果前两次访问发生在 72 小时内,代码缓存将生效。如果使用服务工作线程缓存脚本,Chrome 也会有主动代码缓存。您可以阅读更多关于面向Web开发者的代码缓存。
结论
下载和执行时间是 2019 年加载脚本的主要瓶颈。目标是在页面首屏内容中使用一个小的同步(内联)脚本包,并为页面其余部分使用一个或多个延迟加载的脚本包。分解大的包,以便您能够专注于在用户需要时仅交付他们需要的代码。这会最大化 V8 中的并行化。
在移动设备上,由于网络、内存消耗及较慢 CPU 的执行时间,您需要交付少得多的脚本。平衡延迟和可缓存性,以最大化解析和编译工作在主线程外完成的可能性。