加速 V8 堆快照
这篇博客文章由 José Dapena Paz (Igalia) 撰写,并得到了 Jason Williams (Bloomberg)、Ashley Claymore (Bloomberg)、Rob Palmer (Bloomberg)、Joyee Cheung (Igalia) 和 Shu-yu Guo (Google) 的贡献。
在这篇关于 V8 堆快照的文章中,我将谈谈由 Bloomberg 工程师发现的一些性能问题,以及我们如何解决这些问题,使 JavaScript 内存分析比以往更快。
问题描述
Bloomberg 的工程师正在诊断一个 JavaScript 应用中的内存泄漏问题。应用程序由于 内存不足 错误而失败。对于测试的应用程序,V8 的堆限制配置约为 1400 MB。一般情况下,V8 的垃圾收集器应该能够将堆使用保持在该限制以下,因此这些错误表明可能存在泄漏。
在调试这种常见的内存泄漏场景时,通常的技术是先捕获堆快照,然后在 DevTools 的“内存”标签中加载它,并通过检查各种摘要和对象属性,找出占用内存最多的部分。在 DevTools 的界面中,可以在“内存”标签中拍摄堆快照。对于 Node.js 应用程序,可以使用 此 API 编程触发堆快照:
require('v8').writeHeapSnapshot();
他们希望在应用程序生命周期的不同点捕获多个快照,以便使用 DevTools 内存查看器显示不同时间点的堆之间的差异。问题是,捕获一个单独的完整大小(500 MB)快照需要 超过 30 分钟!
我们需要解决的是这种内存分析工作流程中的缓慢问题。
缩小问题范围
随后,Bloomberg 的工程师开始使用一些 V8 参数调查问题。正如 这篇文章 所描述的,Node.js 和 V8 有一些很好的命令行参数可以帮助解决问题。这些选项用于创建堆快照、简化复现并提高可观测性:
--max-old-space-size=100:将堆限制为 100 MB,从而更快地复现问题。--heapsnapshot-near-heap-limit=10:这是一个 Node.js 特定的命令行参数,用于告诉 Node.js 每次内存即将耗尽时生成一个快照。它被配置为最多生成 10 个快照。这样可以防止内存不足的程序产生过多的快照。--enable-etw-stack-walking:允许像 ETW、WPA 和 xperf 这样的工具查看在 V8 中调用的 JS 堆栈。(适用于 Node.js v20+)--interpreted-frames-native-stack:此标志与 ETW、WPA 和 xperf 等工具结合使用,以便在分析时查看原生堆栈。(适用于 Node.js v20+)。
当 V8 堆的大小接近限制时,V8 会强制执行一次垃圾回收以降低内存使用率。同时它会通知嵌入器此情况。Node.js 中的 --heapsnapshot-near-heap-limit 标志在接收到通知时生成一个新的堆快照。在测试案例中,内存使用量会减少,但经过多次迭代后,垃圾收集最终无法释放足够的空间,因此应用程序因 内存不足 错误而终止。
他们使用 Windows 性能分析器(见下文)记录数据以缩小问题范围。这揭示了大多数 CPU 时间都花费在 V8 堆浏览器中。具体来说,仅仅遍历堆以访问每个节点并收集名称就花费了大约 30 分钟。这似乎有点不合常理——为什么记录每个属性的名称会花费这么久?
就在这时,我被请来一探究竟。
量化问题
第一步是为 V8 增加支持,以便更好地了解在捕获堆快照时时间花费在哪里。捕获过程本身分为两个阶段:生成和序列化。我们在上游提交了 此补丁,在 V8 中引入了一个新的命令行标志 --profile_heap_snapshot,用于记录生成和序列化时间。
使用此标志,我们了解到了一些有趣的事情!
首先,我们可以观察到V8在生成每个快照上花费的具体时间。在我们的简化测试用例中,第一个快照花了5分钟,第二个花了8分钟,而每个后续快照花费的时间越来越长。几乎所有这些时间都花在了生成阶段。
这也让我们能够通过微不足道的开销量化快照生成所花费的时间,这帮助我们隔离并识别出其他广泛使用的JavaScript应用程序中类似的性能下降问题——特别是在处理TypeScript的ESLint上。因此,我们知道这个问题并非特定于某个应用。
此外,我们还发现该问题发生在Windows和Linux上。这表明问题不是平台特定的。
第一个优化:改进 StringsStorage 的哈希方法
为了确认导致延迟过长的原因,我使用Windows性能工具包对运行失败的脚本进行了性能分析。
当我使用Windows性能分析器打开记录时,这就是我发现的内容:
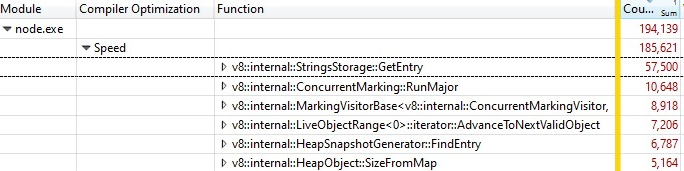
三分之一的采样时间花费在v8::internal::StringsStorage::GetEntry中:
181 base::HashMap::Entry* StringsStorage::GetEntry(const char* str, int len) {
182 uint32_t hash = ComputeStringHash(str, len);
183 return names_.LookupOrInsert(const_cast<char*>(str), hash);
184 }
由于这是在发布版本中运行的,内联函数调用的信息被折叠进了StringsStorage::GetEntry()中。为了精确测量内联函数调用花费的时间,我在分解中添加了“源代码行号”列,发现大部分时间都花在了第182行的ComputeStringHash()调用上:
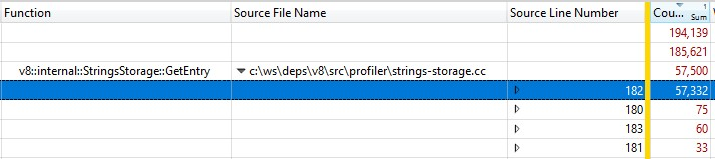
因此,超过30%的快照生成时间花费在ComputeStringHash()上,但为什么呢?
让我们先来谈谈StringsStorage。它的目的是存储堆快照中使用的所有字符串的唯一副本。为了快速访问和避免重复,这个类使用了一个数组支持的哈希表,其中冲突通过将元素存储在数组中的下一个空闲位置来处理。
我开始怀疑问题可能是由冲突引起的,这可能导致在数组中进行长时间搜索。因此,我添加了详尽的日志记录,以查看生成的哈希键值,以及在插入时查看计算的预期位置与由于冲突导致的实际最终位置之间的差距。
在日志中,事情变得……不正常:许多项的偏移超过了20,最糟糕的情况下达到了几千的量级!
问题的一部分是由数字字符串引起的——特别是,对于一范围内的连续数字字符串。哈希键算法有两种实现方式,一种针对数字字符串,另一种针对其他字符串。虽然字符串的哈希函数相当经典,但对数字字符串的实现基本上返回的是数字的值,并在前面加上数字位数:
int32_t OriginalHash(const std::string& numeric_string) {
int kValueBits = 24;
int32_t mask = (1 << kValueBits) - 1; /* 0xffffff */
return (numeric_string.length() << kValueBits) | (numeric_string & mask);
}
x | OriginalHash(x) |
|---|---|
| 0 | 0x1000000 |
| 1 | 0x1000001 |
| 2 | 0x1000002 |
| 3 | 0x1000003 |
| 10 | 0x200000a |
| 11 | 0x200000b |
| 100 | 0x3000064 |
此函数存在问题。该哈希函数的以下问题为例:
- 一旦插入某个哈希键值较小的字符串,我们尝试在该位置存储另一个数字时就会遇到冲突,而如果尝试连续存储后续数字,也会有类似的冲突。
- 甚至更糟的是:如果映射中已经有很多连续数字存储,而我们要插入一个哈希键值在该范围内的字符串时,我们不得不沿着所有占用位置移动以找到一个空闲位置。
我怎么修复它呢?由于问题主要来源于数字被表示为字符串并落在连续位置上,我修改了哈希函数,让我们将生成的哈希值向左旋转2位。
int32_t NewHash(const std::string& numeric_string) {
return OriginalHash(numeric_string) << 2;
}
x | OriginalHash(x) | NewHash(x) |
|---|---|---|
| 0 | 0x1000000 | 0x4000000 |
| 1 | 0x1000001 | 0x4000004 |
| 2 | 0x1000002 | 0x4000008 |
| 3 | 0x1000003 | 0x400000c |
| 10 | 0x200000a | 0x8000028 |
| 11 | 0x200000b | 0x800002c |
| 100 | 0x3000064 | 0xc000190 |
因此,对于每对连续数字,我们将在它们之间插入3个空闲位置。这种修改是通过对几个工作集的实证测试选择的,结果显示这种方法在最小化冲突方面效果最佳。
这个哈希修复 已经在 V8 中实现。
第二项优化:缓存源代码位置
在修复了哈希问题后,我们重新进行了性能分析,并发现了一个进一步的优化机会,可以显著减少开销。
生成堆快照时,对于堆中的每个函数,V8 会尝试记录其起始位置(以行号和列号的形式表示)。这些信息可以供开发者工具用来显示函数源码链接。然而,在通常编译过程中,V8 仅以线性偏移量的形式存储每个函数的起始位置,该偏移量是从脚本的开头计算的。为了根据线性偏移量计算行号和列号,V8 需要遍历整个脚本并记录换行符的位置。此计算非常耗时。
通常,在 V8 完成脚本中换行偏移量的计算后,会将这些偏移量缓存到一个新分配的数组中并附加到脚本上。然而,快照的实现在遍历堆时无法修改堆,因此新计算的行信息无法被缓存。
解决方法是什么?现在我们在生成堆快照之前,会迭代 V8 上下文中的所有脚本,计算并缓存换行符的偏移量。由于在生成堆快照时遍历堆时不执行此操作,因此仍然可以修改堆并将源码行位置存储为缓存。
缓存换行偏移量修复 也已经在 V8 中实现。
我们让它变快了吗?
启用两个修复后,我们重新进行了性能分析。两个修复仅影响快照生成时间,因此快照序列化时间并未受到影响。
在处理一个 JS 程序时…
- 对于开发环境中的 JS,生成时间快了 50% 👍
- 对于生产环境中的 JS,生成时间快了 90% 😮
为什么生产代码和开发代码之间有如此大的差距?生产代码经过打包和压缩优化,因此 JS 文件更少、文件也更大。对于这些大文件,计算源码行位置所需的时间更长,因此当我们可以缓存源码位置并避免重复计算时,收益最大。
在 Windows 和 Linux 目标环境中对优化进行了验证。
针对 Bloomberg 工程师最初面临的特别棘手问题,捕获一个 100MB 快照的总端到端时间从令人痛苦的 10 分钟减少到了非常令人愉快的 6 秒。这是100 倍的提升! 🔥
这些优化是通用的胜利,我们预计它们会广泛适用于任何在 V8、Node.js 和 Chromium 上进行内存调试的场景。这些优化已包含在 V8 v11.5.130 版本中,这意味着它们可以在 Chromium 115.0.5576.0 中找到。我们期待 Node.js 在下一个版本更新中获得这些优化。
下一步是什么?
首先,Node.js 接受新的 --profile-heap-snapshot 标志到 NODE_OPTIONS 中将非常有帮助。在某些用例中,用户无法直接控制传递给 Node.js 的命令行选项,只能通过环境变量 NODE_OPTIONS 配置它们。目前,Node.js 会过滤环境变量中设置的 V8 命令行选项,只允许一个已知的子集,这可能会使在 Node.js 中测试新的 V8 标志变得更加困难,就像我们遇到的情况。
快照中的信息准确性可以进一步提高。目前,每个脚本的源码行信息存储在 V8 堆本身的表示中。这是个问题,因为我们希望精确地衡量堆,而性能测量开销不应影响我们观察的对象。理想情况下,我们会将行信息的缓存存储在 V8 堆外部,以使堆快照信息更准确。
最后,现在我们改进了生成阶段,最大的开销现在是序列化阶段。进一步分析可能会揭示序列化中的新优化机会。