V8中的快速属性
在这篇博客中,我们想解释一下V8如何在内部处理JavaScript属性。从JavaScript的角度来看,属性的区分需求只有少数几种。JavaScript对象大多像字典一样工作,具有字符串键和任意对象值。然而,规范在迭代期间将整数索引属性和其他属性区别对待。除此之外,不论属性是否是整数索引,它们的行为大致相同。
然而,在幕后,出于性能和内存原因,V8实际上依赖于几种不同的属性表示方法。在这篇博客中,我们将解释V8如何在处理动态添加的属性时提供快速的属性访问。了解属性的工作原理对于解释像内联缓存这样的V8优化功能是至关重要的。
此篇文章解释了整数索引属性和命名属性的处理差异。之后我们展示了当添加命名属性时,V8如何维护HiddenClasses以提供一种快速识别对象形状的方法。接下来我们将深入解析命名属性如何根据使用情况优化为快速访问或快速修改。在最后一部分,我们将详细介绍V8如何处理整数索引属性或数组索引。
命名属性与元素
让我们从分析一个非常简单的对象开始,例如{a: "foo", b: "bar"}。这个对象具有两个命名属性,"a"和"b"。它没有任何整数索引的属性名称。数组索引属性,更常见的是元素,主要出现在数组上。例如数组["foo", "bar"]有两个数组索引属性:0,其值为"foo",以及1,其值为"bar"。这是V8一般处理属性的第一个主要区分点。
下面的图表展示了一个基本的JavaScript对象在内存中的样子。
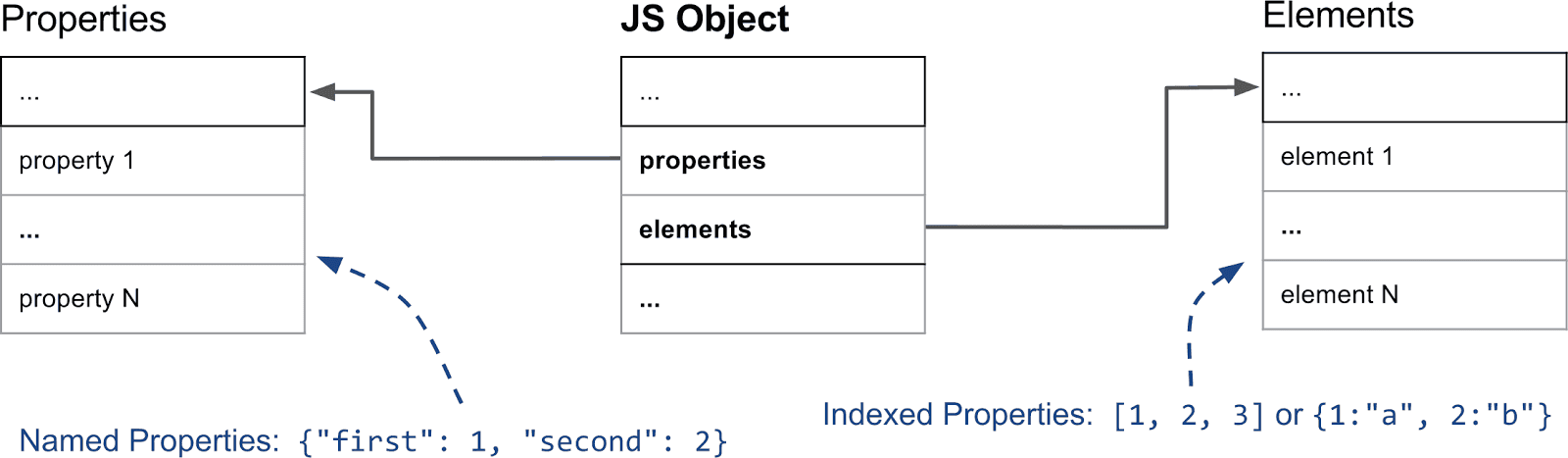
元素和属性存储在两个独立的数据结构中,这使得根据不同的使用模式,添加和访问属性或元素更高效。
元素主要用于各种Array.prototype方法,比如pop或slice。鉴于这些函数在连续的范围内访问属性,V8通常会将它们在内部表示为简单数组。然而,稍后我们将解释为什么有时我们会切换到基于稀疏字典的表示以节省内存。
命名属性以类似方式存储在一个独立的数组中。然而,与元素不同的是,我们不能简单地通过键来推测它们在属性数组中的位置;我们需要一些额外的元数据。在V8中,每个JavaScript对象都有一个关联的HiddenClass。HiddenClass存储关于对象形状的信息,其中包括一个从属性名称到属性数组索引的映射。为了使情况复杂化,有时我们会为属性使用字典而不是简单的数组。我们将在专门的部分中详细解释这一点。
本节的要点:
- 数组索引属性存储在单独的元素存储中。
- 命名属性存储在属性存储中。
- 元素和属性可以是数组或字典。
- 每个JavaScript对象都有一个关联的HiddenClass,用于存储有关对象形状的信息。
HiddenClasses 和 DescriptorArrays
在解释了元素和命名属性的一般区别后,我们需要看看 V8 中 HiddenClass 的工作原理。这种 HiddenClass 存储有关对象的元信息,包括对象上的属性数量和对对象原型的引用。HiddenClass 在概念上类似于典型面向对象编程语言中的类。然而,在像 JavaScript 这样的基于原型的语言中,通常无法提前知道类信息。因此,在 V8 的情况下,HiddenClass 是动态创建的,并且会随着对象的变化而动态更新。HiddenClass 充当对象形状的标识符,因此是 V8 的优化编译器和内联缓存非常重要的组成部分。例如,如果通过 HiddenClass 确保对象结构兼容,优化编译器可以直接内联属性访问。
我们来看看 HiddenClass 的重要部分。

在 V8 中,JavaScript 对象的第一个字段指向一个 HiddenClass。(实际上,这适用于 V8 堆中的任何对象,并由垃圾收集器管理。)在属性方面,最重要的信息是第三位字段,它存储属性数量以及指向描述符数组的指针。描述符数组包含有关命名属性的信息,例如属性名称本身以及存储值的位置。请注意,我们不会在此跟踪整数索引属性,因此描述符数组中没有相关条目。
关于 HiddenClass 的基本假设是,具有相同结构的对象——例如按相同顺序排列的相同命名属性——共享同一个 HiddenClass。为了实现这一点,当属性被添加到对象时,我们会使用不同的 HiddenClass。在以下示例中,我们从一个空对象开始,并添加了三个命名属性。
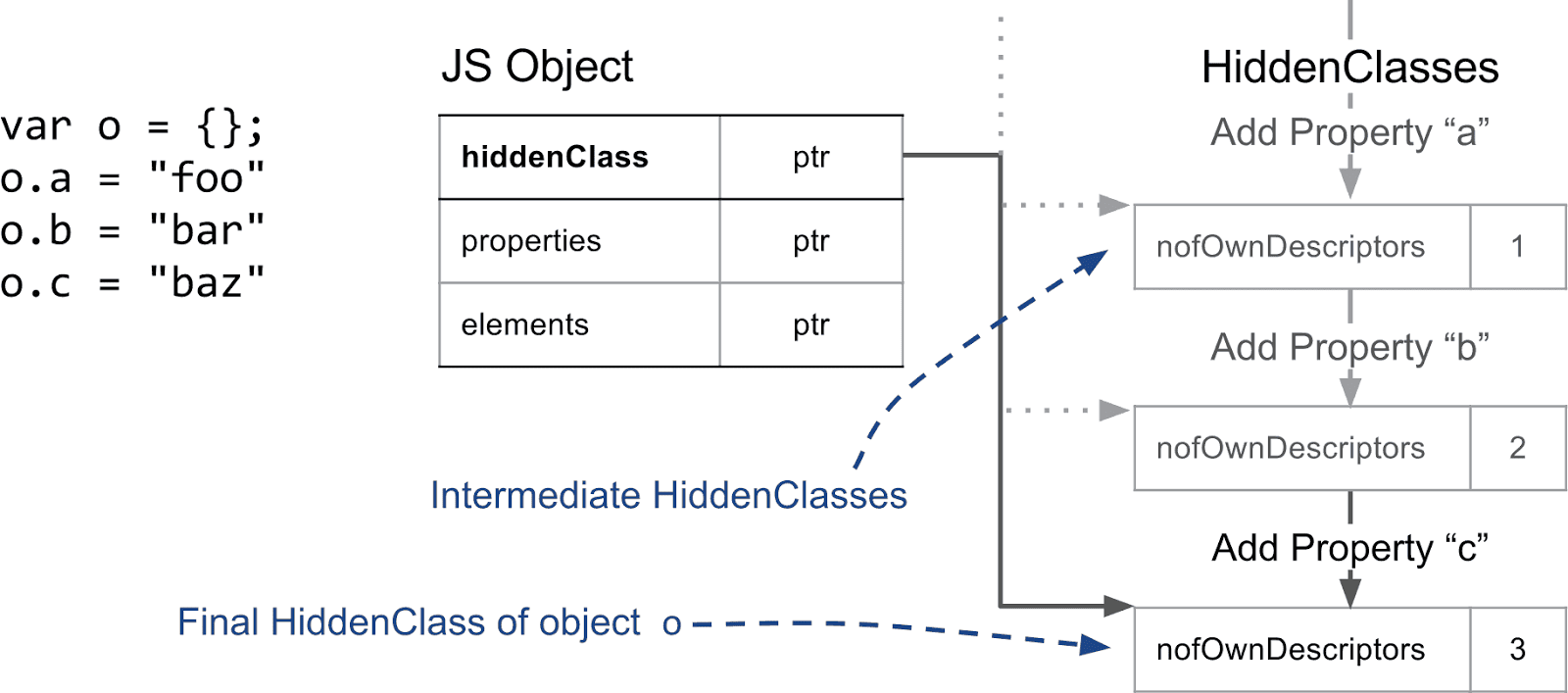
每次添加新属性时,对象的 HiddenClass 都会发生改变。在后台,V8 创建一个过渡树,将 HiddenClass 链接在一起。例如,当您向空对象添加属性 "a" 时,V8 知道应该使用哪个 HiddenClass。这个过渡树确保如果以相同的顺序添加相同的属性,会得到相同的最终 HiddenClass。下面的示例显示,即使我们在中间添加简单的索引属性,也会遵循相同的过渡树。
![]()
然而,如果我们创建一个新对象并添加不同的属性,例如属性 "d",V8 会为新的 HiddenClass 创建一个单独的分支。
![]()
本节要点:
- 具有相同结构(相同属性按相同顺序排列)的对象具有相同的 HiddenClass
- 默认情况下,每添加一个新的命名属性都会导致创建一个新的 HiddenClass。
- 添加数组索引属性不会创建新的 HiddenClass。
三种不同类型的命名属性
在概述了 V8 如何使用 HiddenClass 跟踪对象形状之后,让我们深入了解这些属性实际上是如何存储的。如上所述,属性可以分为两类:命名属性和索引属性。以下部分涵盖命名属性。
一个简单的对象,比如 {a: 1, b: 2},在 V8 中可以有各种内部表示。从表面上看,JavaScript 对象更像是简单的字典,但 V8 尽量避免使用字典,因为它会阻碍某些优化,比如 内联缓存,我们将在单独的文章中对此进行解释。
对象内的属性 vs. 常规属性:V8 支持所谓的对象内属性,它们直接存储在对象本身上。这些是 V8 中最快的属性,因为它们无需任何间接访问即可访问。对象内属性的数量由对象的初始大小确定。如果添加的属性数量超出对象的可用空间,它们会存储在属性存储区中。属性存储区增加了一级间接性,但可以独立增长。
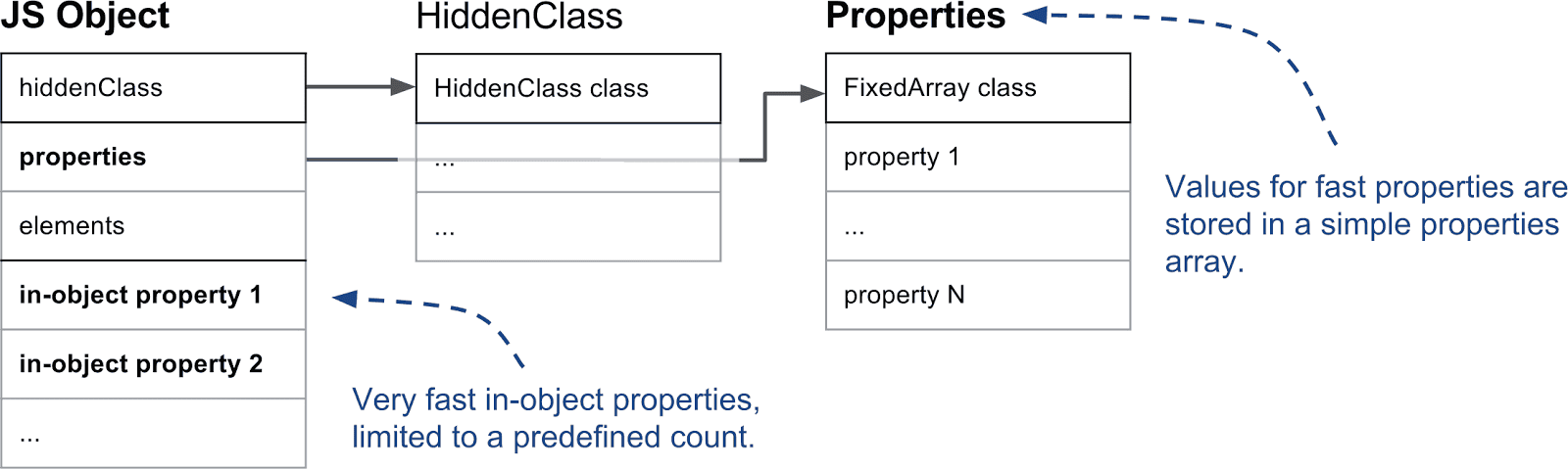
快速属性与慢速属性:另一个重要的区别是快速属性和慢速属性之间的区别。通常,我们将存储在线性属性存储区中的属性定义为“快速属性”。快速属性只是通过属性存储中的索引访问的。要从属性名称到实际位置,我们必须查阅 HiddenClass 上的描述符数组,如前所述。
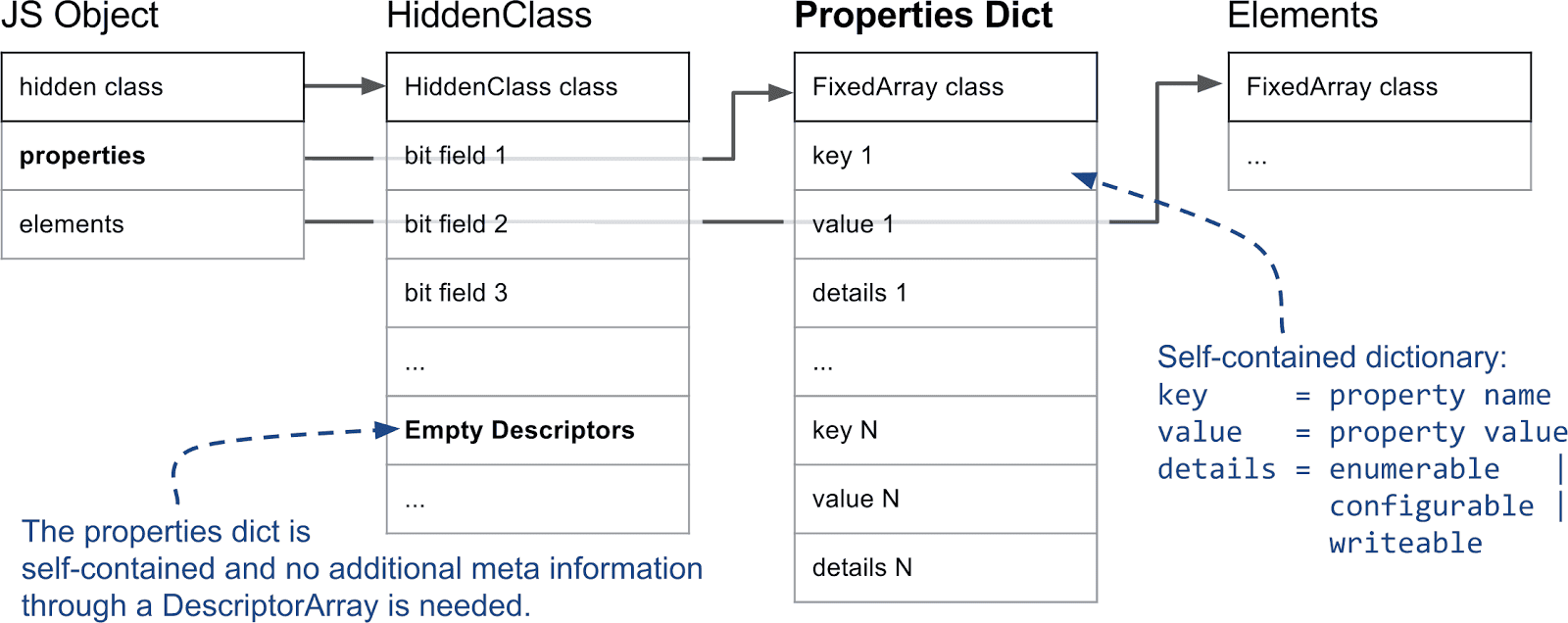
然而,如果从对象中添加和删除了许多属性,维护描述符数组和 HiddenClass 会产生大量时间和内存开销。因此,V8 还支持所谓的慢速属性。具有慢速属性的对象有一个独立的字典作为属性存储区。所有属性的元信息不再存储在 HiddenClass 的描述符数组中,而是直接存储在属性字典中。因此,属性可以添加和删除,而无需更新 HiddenClass。由于内联缓存无法与字典属性配合使用,这些属性通常比快速属性要慢。
本节要点:
- 命名属性有三种类型:对象内属性、快速属性和慢速/字典属性。
- 对象内属性直接存储在对象本身上,提供最快的访问速度。
- 快速属性存储在属性存储中,所有的元信息存储在HiddenClass的描述符数组中。
- 慢速属性存储在一个独立的属性字典中,元信息不再通过HiddenClass共享。
- 慢速属性允许高效的属性移除和添加,但访问速度比其他两种类型慢。
元素或数组索引的属性
到目前为止,我们已经看过了命名属性,并忽略了数组中常用的整数索引属性。处理整数索引属性并不比命名属性简单。即使所有索引属性始终单独存储在元素存储中,但仍然有20种不同类型的元素!
Packed或Holey Elements: V8所做的主要区分之一是元素的存储是否是紧凑的(packed)还是有空洞的(holey)。如果删除了某个索引元素或者未定义它,就会在存储中出现空洞。例如,简单的例子是 [1,,3],其中第二个条目是一个空洞。以下示例说明了此问题:
const o = ['a', 'b', 'c'];
console.log(o[1]); // 输出 'b'.
delete o[1]; // 在元素存储中引入一个空洞。
console.log(o[1]); // 输出 'undefined'; 属性 1 不存在。
o.__proto__ = {1: 'B'}; // 在原型上定义属性 1。
console.log(o[0]); // 输出 'a'.
console.log(o[1]); // 输出 'B'.
console.log(o[2]); // 输出 'c'.
console.log(o[3]); // 输出 undefined

简而言之,如果接收者上不存在某属性,我们必须继续在原型链上查找。由于元素是独立的,例如我们不会在HiddenClass中存储有关现有索引属性的信息,我们需要一个特殊值,称为_hole,来标记不存在的属性。这对于数组函数的性能至关重要。如果我们知道没有空洞,即元素存储是紧凑的,我们可以在本地执行操作,而无需在原型链上进行代价高昂的查找。
快速或字典元素: 对元素的第二个主要区分是它们是快速的还是字典模式。快速元素是简单的VM内部数组,其中属性索引映射到元素存储中的索引。然而,对于非常大的稀疏/有空洞的数组,仅占用少量条目的情况下,这种简单的表示相当浪费。在这种情况下,我们使用基于字典的表示节省内存,但代价是访问速度稍慢:
const sparseArray = [];
sparseArray[9999] = 'foo'; // 创建一个带有字典元素的数组。
在此示例中,分配一个具有10000个条目的完整数组将非常浪费。而是V8创建一个字典,在其中存储键值-描述符三元组。在这种情况下,键将是 '9999',值是 'foo',并使用默认描述符。由于我们没有方法在HiddenClass上存储描述符详细信息,只要您使用自定义描述符定义索引属性,V8就会使用慢速元素:
const array = [];
Object.defineProperty(array, 0, {value: 'fixed', configurable: false});
console.log(array[0]); // 输出 'fixed'.
array[0] = 'other value'; // 无法覆盖索引 0。
console.log(array[0]); // 仍然输出 'fixed'.
在此示例中,我们向数组添加了一个不可配置的属性。此信息存储在慢速元素字典三元组的描述符部分中。需要注意的是,对具有慢速元素的对象进行数组函数操作会明显慢很多。
Smi和Double Elements: 对于快速元素,V8还进行了另一个重要区分。例如,如果您只在数组中存储整数,这是一个常见的用例,GC无需检查数组,因为整数直接以所谓的小整数(Smis)形式编码在原地。另一种特殊情况是仅包含双精度浮点数的数组。与Smis不同,浮点数通常表示为占用几个字的完整对象。然而,V8为纯双精度数组存储原始双精度数,以避免内存和性能开销。以下示例列出了4个Smi和双精度元素的例子:
const a1 = [1, 2, 3]; // Smi Packed
const a2 = [1, , 3]; // Smi Holey, a2[1] 从原型读取
const b1 = [1.1, 2, 3]; // Double Packed
const b2 = [1.1, , 3]; // Double Holey, b2[1] 从原型读取
特殊元素: 到目前为止的信息我们已经涵盖了20种不同元素种类中的7种。为简化起见,我们排除了TypedArrays的9种元素种类,两个用于字符串包装,以及最后两个用于参数对象的特殊元素种类。
元素访问器: 你可以想象我们并不愿意在C++中为每种元素类型编写20次Array函数。这正是一些C++魔法派上用场的地方。我们没有重复实现Array函数,而是构建了ElementsAccessor,我们只需要实现一些简单的函数来访问后备存储(backing store)中的元素即可。ElementsAccessor依赖于CRTP来创建每个Array函数的专用版本。因此,如果你在数组上调用类似slice的操作,V8在内部会调用一个用C++编写的内建函数,并通过ElementsAccessor调度到该函数的专用版本:
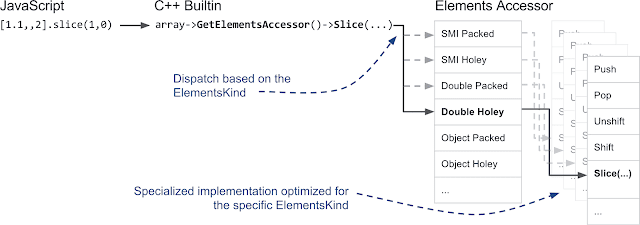
本节重点:
- 有快速模式和字典模式的索引属性与元素。
- 快速属性可以是内存密集的(packed),也可以包含空洞,这表明某个索引属性已被删除。
- 元素根据其内容类型进行了专门化,以加速Array函数并减少GC开销。
理解属性的工作原理是V8中许多优化的关键。对于JavaScript开发者来说,许多内部决策并不直接可见,但它们解释了为什么某些代码模式比其他模式更快。更改属性或元素类型通常会导致V8创建不同的HiddenClass,这可能会导致类型污染,从而阻止V8生成最佳代码。请继续关注我们更多关于V8虚拟机内部工作的帖子。