Liftoff:V8 中 WebAssembly 的新基线编译器
V8 v6.9 包括了 Liftoff,一款 WebAssembly 的新基线编译器。Liftoff 现已默认在桌面系统上启用。本文详细介绍了添加另一个编译层的动机,并描述了 Liftoff 的实现及性能表现。

自从 WebAssembly 发布超过一年以来,其在网络上的采用率稳步增长。针对 WebAssembly 的大型应用程序已经开始出现。例如,Epic 的 ZenGarden 基准测试 包含一个 39.5 MB 的 WebAssembly 二进制文件,AutoDesk 则以一个 36.8 MB 的二进制文件形式发行。由于编译时间基本上与二进制文件大小线性相关,这些应用需要相当长的启动时间。在许多机器上,启动时间超过 30 秒,这不提供很好的用户体验。
但为什么启动一个 WebAssembly 应用程序需要这么长时间,而类似的 JS 应用程序却能更快启动呢?原因是 WebAssembly 承诺提供 可预测的性能,因此一旦应用程序运行,你可以确保持续达到你的性能目标(例如渲染每秒 60 帧,无音频延迟或缺陷)。为了实现这一点,WebAssembly 代码在 V8 中被 提前编译,以避免因即时编译器引入的编译暂停而导致应用中的明显卡顿。
现有的编译管道(TurboFan)
V8 编译 WebAssembly 的方法依赖于 TurboFan,这是我们为 JavaScript 和 asm.js 设计的优化编译器。TurboFan 是一个功能强大的编译器,具有基于图的 中间表示(IR),适合高级优化,例如降低强度、内联、代码移动、指令合并和复杂的寄存器分配。TurboFan 的设计支持在机器代码附近较晚进入管道,从而绕过许多支持 JavaScript 编译所需的阶段。本质上,将 WebAssembly 代码转换为 TurboFan 的 IR(包括 SSA 构造)通过简单的单次处理非常高效,这部分归因于 WebAssembly 的结构化控制流。然而,编译过程的后端仍然耗费了相当的时间和内存。
新的编译管道(Liftoff)
Liftoff 的目标是通过尽可能快地生成代码来减少基于 WebAssembly 的应用程序的启动时间。代码质量是次要的,因为热代码最终会用 TurboFan 重新编译。Liftoff 避免了构造 IR 的时间和内存开销,而是在 WebAssembly 函数的字节码上进行单次处理直接生成机器码。

从上面的图表可以看出,Liftoff 应该能够比 TurboFan 更快地生成代码,因为管道仅由两个阶段组成。事实上,函数体解码器对原始的 WebAssembly 字节进行单次处理,并通过回调与后续阶段交互,因此代码生成是在 解码及验证 函数体时执行的。结合 WebAssembly 的 流式 API,这使得 V8 能够在通过网络下载时将 WebAssembly 代码编译为机器码。
Liftoff 中的代码生成
Liftoff 是一个简单的代码生成器,并且速度很快。它仅需对函数的操作码进行一次遍历,每次生成对应操作码的代码。对于像算术这样的简单操作码,这通常是单个机器指令,但对于像调用这样的操作码可能会更多。Liftoff 会维护操作数栈的元数据,以便知道每次操作的输入当前存储的位置。这个“虚拟栈”仅在编译期间存在。WebAssembly 的结构化控制流程和验证规则保证了这些输入的位置是可以静态确定的,因此不需要实际运行时栈来进行操作数的压入和弹出。在执行期间,虚拟栈上的每个值都会存储在寄存器中或溢出到该函数的物理栈框架中。对于小的整数常量(由 i32.const 生成),Liftoff 仅记录常量的值在虚拟栈中,而不生成任何代码。只有当后续操作使用该常量时,常量才会被发出或与操作结合,例如在 x64 上直接发出 addl <reg>, <const> 指令。这避免了将该常量加载到寄存器中,从而产生更优的代码。
让我们通过一个非常简单的函数来看看 Liftoff 是如何为其生成代码的。

这个示例函数接受两个参数并返回它们的和。当 Liftoff 解码该函数的字节时,它首先根据 WebAssembly 函数的调用约定初始化本地变量的内部状态。对于 x64,V8 的调用约定将两个参数保存在 rax 和 rdx 寄存器中。
对于 get_local 指令,Liftoff 不生成任何代码,而是仅更新其内部状态以反映这些寄存器值现已压入虚拟栈。随后,i32.add 指令弹出两个寄存器并选择一个寄存器作为结果值的寄存器。我们不能将任何输入寄存器用于结果,因为两个寄存器仍然在栈中用于保存局部变量。如果覆盖它们,会让后续的 get_local 指令返回的值发生改变。因此,Liftoff 选择一个空闲寄存器(在本例中为 rcx),并将 rax 和 rdx 的和生成到该寄存器中。rcx 随后被压入虚拟栈。
在 i32.add 指令之后,函数体完成,因此 Liftoff 必须组装函数返回。由于我们的示例函数有一个返回值,验证要求在函数体结束时虚拟栈上必须正好有一个值。因此,Liftoff 生成代码,将保存在 rcx 中的返回值移动到正确的返回寄存器 rax,然后从函数中返回。
为了简单起见,上述示例不包含任何块(如 if、loop 等)或分支。在 WebAssembly 中,块引入了控制合并,因为代码可以跳转到任何父块,而 if 块可能会被跳过。这些合并点可能来自不同的栈状态。然而,后续代码需要假设一个特定的栈状态来生成代码。因此,Liftoff 对当前虚拟栈的状态进行快照作为后续代码假设的状态(即返回到当前所在的 控制级别 时)。新块将随后以当前活动状态继续进行,可能会改变栈值或局部变量的存储位置:有些可能会溢出到栈中或保存到其他寄存器中。当跳转到另一个块或结束一个块(与跳转到父块相同)时,Liftoff 必须生成代码以将当前状态调整到预期状态,使得我们跳转到的目标代码能在期望的位置找到正确的值。验证保证当前虚拟栈的高度与预期状态的高度匹配,因此 Liftoff 只需生成代码在寄存器和/或物理栈框架之间重新排列值,如下所示。
让我们看看一个示例。

上述示例假定虚拟栈上操作数栈有两个值。在开始新块之前,虚拟栈的顶值作为 if 指令的参数弹出。剩余的栈值需要放到另一个寄存器中,因为它当前正在遮蔽第一个参数,但当返回到该状态时,我们可能需要为栈值和参数保存两个不同的值。在这种情况下,Liftoff 选择将其去重保存在 rcx 寄存器中。这个状态随后被快照,活动状态在块内被修改。在块结束时,我们隐式返回到父块,因此通过将寄存器 rbx 移动到 rcx 以及从栈框架中重新加载寄存器 rdx 来将当前状态合并到快照中。
从 Liftoff 升级到 TurboFan
有了 Liftoff 和 TurboFan,V8 现在为 WebAssembly 提供了两个编译层级:Liftoff 作为基础编译器以实现快速启动,而 TurboFan 作为优化编译器以实现最大性能。这提出了如何结合这两个编译器以提供最佳整体用户体验的问题。
对于 JavaScript,V8 使用 Ignition 解释器和 TurboFan 编译器,并采用动态升级策略。每个函数首先在 Ignition 中执行,如果函数变热,TurboFan 会将其编译为高度优化的机器代码。类似的方法也可以用于 Liftoff,但这里的权衡略有不同:
- WebAssembly 不需要类型反馈来生成快速代码。JavaScript 在收集类型反馈方面受益很大,而 WebAssembly 是静态类型的,因此引擎可以直接生成优化代码。
- WebAssembly代码应该运行得可预期地快速,没有漫长的预热阶段。应用程序瞄准WebAssembly的原因之一是为了以可预期的高性能在网络上执行。因此,我们既不能容忍长时间运行次优代码,也不能接受在执行期间的编译暂停。
- JavaScript的Ignition解释器的一个重要设计目标是借助完全不编译函数来减少内存使用。但我们发现,WebAssembly的解释器过于缓慢,无法实现可预期的快速性能这一目标。其实,我们确实构建了这样一个解释器,但它的速度比编译代码慢20倍甚至更多,无论节省了多少内存,这种解释器只能用于调试。因此,引擎无论如何必须存储编译后的代码;最终,它应该只存储最紧凑且最高效的代码,这就是TurboFan优化代码。
基于这些限制,我们得出结论:动态分级(dynamic tier-up)目前并不是V8在WebAssembly实现中的正确权衡,因为它会增加代码体积并在不确定的时间范围内降低性能。相反,我们选择了*主动分级(eager tier-up)*的策略。在Liftoff编译模块完成后,WebAssembly引擎会立即启动后台线程为模块生成优化代码。这使V8能够迅速开始执行代码(在Liftoff完成后),但仍然能尽早提供性能最佳的TurboFan代码。
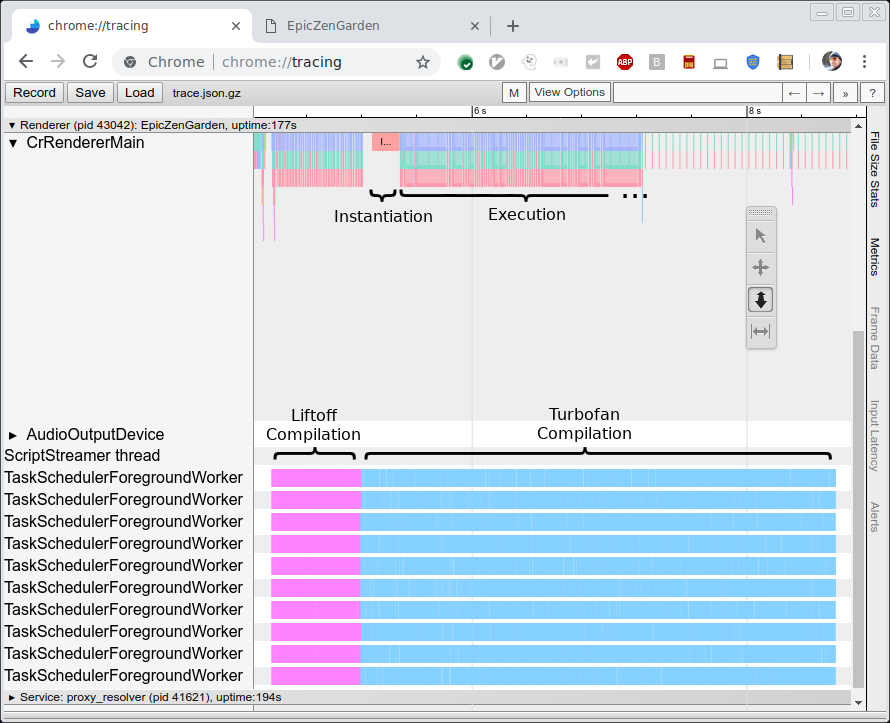
下图展示了编译和执行EpicZenGarden基准测试的跟踪信息。它显示,在Liftoff编译完成后,我们可以实例化WebAssembly模块并开始执行它。TurboFan的编译仍需几秒钟时间,因此在此分级上升期间,随着单个TurboFan函数完成后立即开始使用,观察到的执行性能会逐渐提高。
性能
有两个指标对评估新Liftoff编译器的性能很有意义。首先,我们希望将编译速度(即生成代码所需的时间)与TurboFan进行比较。其次,我们想测量生成代码的性能(即执行速度)。这里第一个指标更有趣,因为Liftoff的目标是通过尽快生成代码来减少启动时间。另一方面,生成代码的性能应该仍然相当不错,因为这些代码可能会在低端硬件上运行几秒甚至几分钟。
生成代码的性能
为了测量编译器性能本身,我们运行了一些基准测试,并使用跟踪测量了原始编译时间(见上图)。我们在一台HP Z840机器(2×Intel Xeon E5-2690 @2.6GHz,24核心,48线程)和一台Macbook Pro(Intel Core i7-4980HQ @2.8GHz,4核心,8线程)上运行这些基准测试。注意,目前Chrome不会使用超过10个后台线程,因此Z840机器的大多数核心未被使用。
我们执行了三个基准测试:
- EpicZenGarden:运行在Epic框架上的ZenGarden演示
- Tanks!:Unity引擎的一个演示
- AutoDesk
- PSPDFKit
对于每个基准,我们使用上述的跟踪输出测量原始编译时间。这个数字比基准自身报告的任何时间都更稳定,因为它不依赖于任务被调度到主线程上,也不包括像实际创建WebAssembly实例这样的无关工作。
以下图表显示了这些基准测试的结果。每个基准测试执行三次,我们报告平均编译时间。


正如预期的那样,无论是在高端桌面工作站还是在MacBook上,Liftoff编译器的代码生成速度都更快。在功能较弱的MacBook硬件上,Liftoff相较TurboFan的提速更为显著。
生成代码的性能
尽管生成代码的性能是次要目标,我们仍希望在启动阶段以高性能保留用户体验,因为Liftoff代码可能会在TurboFan代码完成之前运行几秒钟。
为了测量Liftoff代码性能,我们关闭了分级上升,以测量纯Liftoff执行。在这个设置中,我们执行了两个基准测试:
-
Unity无头基准测试
这是一系列在Unity框架中运行的基准测试。它们是无头的,因此可以直接在d8 shell中执行。每个基准测试都会报告一个分数,这并不一定与执行性能成正比,但足以比较性能。
-
此基准报告记录了在 PDF 文件上执行不同操作所需的时间,以及实例化 WebAssembly 模块(包括编译)所需的时间。
和之前一样,我们每个基准测试执行三次,并使用三次运行的平均值。由于记录的数字在基准测试之间的规模差异显著,我们报告了 Liftoff 与 TurboFan 的相对性能。一个 +30% 的值表示 Liftoff 代码运行比 TurboFan 慢 30%。负数表示 Liftoff 的执行速度更快。结果如下:

在 Unity 上,Liftoff 代码在桌面设备上的平均执行速度比 TurboFan 代码慢约 50%,在 MacBook 上则慢 70%。有趣的是,在一个案例(Mandelbrot Script)中,Liftoff 的性能优于 TurboFan。这可能是一个异常情况,例如 TurboFan 的寄存器分配器在某个热门循环中表现不佳。我们正在调查是否可以改进 TurboFan 来更好地处理这种情况。

在 PSPDFKit 基准测试中,Liftoff 代码的执行速度比优化代码慢 18%-54%,而初始化显著改善,这在预期之内。这些数据表明,对于通过 JavaScript 调用与浏览器交互的实际代码而言,未优化代码的性能损失通常低于那些计算密集型基准测试。
再次注意,对于这些数据,我们完全关闭了分层提升,因此我们只执行 Liftoff 代码。在生产配置中,Liftoff 代码将逐渐被 TurboFan 代码取代,因此 Liftoff 的较低性能仅会持续短时间。
未来工作
在 Liftoff 初次发布后,我们正在努力进一步改善启动时间、减少内存使用,并将 Liftoff 的优点带给更多用户。具体来说,我们正在改进以下内容:
- 移植 Liftoff 到 arm 和 arm64,以便在移动设备上使用。 目前,Liftoff 仅实现了针对 Intel 平台(32 和 64 位)的支持,这主要捕获了桌面使用场景。为了也能覆盖移动用户,我们将移植 Liftoff 到更多架构。
- 为移动设备实现动态分层提升。 由于移动设备的内存通常比桌面系统少得多,我们需要针对这些设备调整分层策略。仅使用 TurboFan 重新编译所有函数会轻易使存储所有代码所需的内存翻倍,至少是暂时的(直到 Liftoff 的代码被丢弃)。相反,我们正在实验将 Liftoff 的延迟编译与 TurboFan 中热点函数的动态分层提升相结合。
- 提升 Liftoff 代码生成的性能。 实现的初次迭代很少是最优的。有几个方面可以进行调整,以进一步加快 Liftoff 的编译速度。这将在接下来的发布版本中逐步实现。
- 提升 Liftoff 代码的性能。 除了编译器本身,生成代码的大小和速度也可以被优化。这也将在接下来的发布版本中逐步实现。
结论
V8 现在包含了 Liftoff,这是一款用于 WebAssembly 的新基线编译器。Liftoff 采用简单快速的代码生成器,大幅减少了 WebAssembly 应用程序的启动时间。在桌面系统上,V8 仍通过后台使用 TurboFan 重新编译所有代码以实现最高的峰值性能。Liftoff 在 V8 v6.9(Chrome 69)中默认启用,可以通过 --liftoff/--no-liftoff 和 chrome://flags/#enable-webassembly-baseline 选项分别进行显式控制。