JavaScript开发者的代码缓存
代码缓存(也称为字节码缓存)是浏览器中的一个重要优化。它通过缓存解析和编译的结果来减少经常访问的网站的启动时间。大多数主流 浏览器都实现了某种形式的代码缓存,而Chrome也不例外。事实上,我们过去曾撰写 和 讨论过Chrome和V8是如何缓存已编译代码的。
在这篇博客文章中,我们为希望利用代码缓存来提高网站启动性能的JavaScript开发者提供了一些建议。这些建议专注于Chrome/V8中的缓存实现,但大多数建议也可能适用于其他浏览器的代码缓存实现。
代码缓存回顾
虽然其他博客文章和演讲更详细地介绍了我们的代码缓存实现,但快速回顾其工作原理是值得的。Chrome对V8编译代码(包括传统脚本和模块脚本)有两个级别的缓存:由V8维护的低成本“尽力而为”内存缓存(Isolate缓存)和完全序列化的磁盘缓存。
Isolate缓存用于同一V8隔离环境中编译的脚本(即同一进程,粗略地说是“同一网站的页面在同一标签页中的导航”)。它是“尽力而为”的,因为它尝试尽可能快速和最小化地使用我们已有的数据,但代价是潜在较低的命中率以及跨进程无法缓存的限制。
- 当V8编译脚本时,已编译的字节码会存储在一个哈希表(位于V8堆)中,由脚本的源代码作为键。
- 当Chrome要求V8编译另一个脚本时,V8首先检查该脚本的源代码是否与哈希表中的某个项匹配。如果匹配,我们直接返回已有的字节码。
这个缓存快速且几乎没有成本,我们观察到它在真实世界中的命中率达到80%。
磁盘代码缓存由Chrome(具体来说是由Blink模块)管理,填补了Isolate缓存无法解决的空白:在多个进程间以及多个Chrome会话间共享代码缓存。它利用现有的HTTP资源缓存来管理从网页接收的缓存和过期数据。
- 当第一次请求JS文件时(即_冷启动_),Chrome下载它并交给V8编译。同时将该文件存储在浏览器的磁盘缓存中。
- 当第二次请求同一JS文件时(即_暖启动_),Chrome从浏览器缓存中获取该文件并再次交给V8编译。但这次,编译后的代码会被序列化,并作为元数据附加到缓存的脚本文件中。
- 第三次请求时(即_热启动_),Chrome从缓存中获取文件及其元数据,并将两者交给V8。V8反序列化元数据,可跳过编译过程。
总结如下:

根据此描述,我们可以为优化网站代码缓存使用提供最佳建议。
提示1:什么都不做
理想情况下,作为JavaScript开发者,你能够改善代码缓存的最好方法就是“什么都不做”。这实际上意味着两件事:被动的什么都不做,以及主动的什么都不做。
代码缓存归根结底是浏览器实现的细节;一种基于启发式的数据/空间权衡性能优化,其实现和启发式规则可能会经常发生变化。我们作为V8工程师,会尽力使这些启发式规则在不断发展的网络中对所有人都有效,而针对当前代码缓存实现在细节上的过度优化,在几次版本更新后可能会因细节变化而失望。此外,其他JavaScript引擎可能会对它们的代码缓存实现采用不同的启发式规则。所以,在许多方面,我们关于如何让代码缓存的最佳建议就像我们关于编写JavaScript代码的建议一样:编写干净的惯用代码,我们会尽力优化如何缓存它。
除了被动地什么都不做,你也应该尽力主动地什么都不做。任何形式的缓存本质上都依赖于事物不发生变化,因此什么都不做是使缓存数据保持缓存的最佳方式。有几种方式可以主动地什么都不做。
不修改代码
这可能很明显,但是值得明确说明——只要你发布新代码,这些代码就还没有被缓存。当浏览器对脚本 URL 发起 HTTP 请求时,可以包括该 URL 上一次获取的日期,如果服务器知道文件没有更改,它可以返回一个 304 未修改响应,从而使代码缓存保持热状态。否则,一个 200 OK 的响应会更新缓存资源,并清除代码缓存,使其退回到冷运行状态。

总是立即推送最新代码更新是很诱人的,尤其是当你想要衡量某个改动的效果时,但对缓存来说,最好让代码保持原样,或者至少尽可能少地更新它。考虑限制每周部署的次数不超过 ≤ x,其中 x 是你可以调整以平衡缓存和陈旧性的滑动条。
不更改URL
代码缓存(当前)与脚本的URL相关联,因为这样可以在不读取实际脚本内容的情况下轻松查找缓存。这意味着更改脚本的URL(包括任何查询参数!)会在资源缓存中创建新的资源条目,并随之产生新的冷缓存条目。
当然,这也可以用于强制清缓存,尽管这也是实现细节;我们可能有一天会决定将缓存与源文本而非源URL相关联,此建议将不再有效。
不更改执行行为
我们代码缓存实现的较新优化之一是仅在编译代码执行后进行序列化。这样可以尝试捕捉那些延迟编译的函数,这些函数仅在执行时进行编译,而不是在初次编译时。
当每次脚本执行执行相同的代码或至少相同的函数时,此优化效果最好。如果 e.g. 你的代码中有依赖于运行时决策的A/B测试,这可能会成为问题。
if (Math.random() > 0.5) {
A();
} else {
B();
}
在这种情况下,只有 A() 或 B() 在热运行时被编译并执行,并进入代码缓存,但之后的运行中两者都可能被执行。而是尝试保持执行行为确定性,以确保其走在缓存路径上。
提示2:做点什么
当然,无论是被动还是主动地什么都不做的建议都不是很令人满意。因此除了做“什么都不做”,根据我们的当前启发性方法和实现,你可以做一些事情。但请记住,启发性方法可能会改变,此建议也可能改变,没有什么能够替代性能分析。

将库代码与使用它的代码分离
代码缓存是在粗粒度的、每脚本的基础上进行的,这意味着脚本的任何部分的变化都会使整个脚本的缓存失效。如果你的代码同时包含稳定与变化的部分,例如库代码和业务逻辑代码,那么业务逻辑代码的变化会使库代码的缓存失效。
相反,你可以将稳定的库代码拆分为一个独立的脚本,并单独包含。这样库代码可以被一次性缓存,当业务逻辑发生变化时仍然保留缓存。
如果这些库代码在你的网站不同页面之间共享,这还具有额外的好处:由于代码缓存附着在脚本上,库代码的缓存也在页面之间共享。
将库代码合并到使用它的代码中
代码缓存是在每一次脚本执行后进行的,这意味着脚本的代码缓存将仅包括在脚本执行完成后编译的那些函数。这对库代码有几个重要影响:
- 代码缓存不会包含早期脚本的函数。
- 代码缓存不会包含由后续脚本调用的延迟编译函数。
尤其是,如果一个库完全由延迟编译函数组成,那么即使这些函数在稍后被使用,它们也不会被缓存。
一种解决方法是将库及其使用合并到一个脚本中,这样代码缓存就能够“看到”库的哪些部分被使用。不幸的是,这完全与上面的建议相反,因为并没有银弹。在一般情况下,我们不建议将所有脚本JS合并到一个大的包中;将其分成多个较小的脚本总体上会更有利,因为除了代码缓存,还有其他原因(例如多次网络请求、流式编译、页面交互性等)。
利用IIFE的启发式方法
只有在脚本执行完成时已经编译的函数才会计入代码缓存,因此有很多类型的函数尽管稍后会执行却不会被缓存。这些函数包括事件处理程序(即使是onload)、Promise链、未使用的库函数,以及任何其他延迟编译但在</script>被看到之前没有被调用的内容,这些都是延迟的并且不会进入缓存。
强制这些函数进入缓存的一种方法是强制其编译,而强制编译的一种常见方式是使用IIFE启发式方法。IIFE(立即调用函数表达式)是一种模式,其中函数在创建后立即调用:
(function foo() {
// …
})();
由于IIFE会被立即调用,大多数JavaScript引擎会尝试检测它们并立即编译,以避免延迟编译后再次完全编译所带来的成本。存在各种启发式方法来提早检测IIFE(在函数需要解析之前),最常见的标志是function关键字之前的(。
由于此启发式方法在早期应用,即使函数实际并未立即调用,也会触发编译:
const foo = function() {
// 延迟跳过
};
const bar = (function() {
// 立即编译
});
这意味着应该进入代码缓存的函数可以通过用圆括号包装来强制进入缓存。然而,如果提示应用不正确,可能会导致启动时间变长,并且总体上这属于某种程度的滥用启发式规则,因此我们的建议是除非必要不要这样做。
将小文件合并
Chrome对代码缓存有一个最小大小限制,目前设置为1KiB的源代码。这意味着较小的脚本根本不会被缓存,因为我们认为其开销大于好处。
如果您的网站拥有许多这样的较小脚本,则开销计算可能不再适用。您可能需要考虑将它们合并在一起,以便超过最低代码大小,并且总体减少脚本的开销。
避免内联脚本
源代码直接内联到HTML中的脚本标签没有与之关联的外部源文件,因此无法通过上述机制进行缓存。Chrome确实尝试缓存内联脚本,通过将其缓存附加到HTML文档的资源上,但这些缓存随后依赖于整个HTML文档内容保持不变,并且不会在页面之间共享。
因此,对于那些可以从代码缓存中受益的非琐碎脚本,请避免将它们内联到HTML中,而应优先将它们作为外部文件引入。
使用Service Worker缓存
Service Worker是一种机制,可以让您的代码拦截页面中资源的网络请求。特别是,它允许您构建一些资源的本地缓存,并在资源需要时从缓存中提供。这对想要离线运行的页面(例如PWA)特别有用。
使用Service Worker的网站的典型示例是在某个主脚本文件中注册Service Worker:
// main.mjs
navigator.serviceWorker.register('/sw.js');
Service Worker添加了安装(创建缓存)和获取(提供资源,可能来自缓存)事件处理程序。
// sw.js
self.addEventListener('install', (event) => {
async function buildCache() {
const cache = await caches.open(cacheName);
return cache.addAll([
'/main.css',
'/main.mjs',
'/offline.html',
]);
}
event.waitUntil(buildCache());
});
self.addEventListener('fetch', (event) => {
async function cachedFetch(event) {
const cache = await caches.open(cacheName);
let response = await cache.match(event.request);
if (response) return response;
response = await fetch(event.request);
cache.put(event.request, response.clone());
return response;
}
event.respondWith(cachedFetch(event));
});
这些缓存可以包括缓存的JS资源。然而,由于我们可以做出不同假设,对于它们的启发式方法有所不同。由于Service Worker缓存遵循配额管理的存储规则,更可能长时间保留,缓存的收益会更大。此外,我们还可以通过预缓存资源推断资源的重要性。
最大的启发式差异发生在资源在服务工作线程安装事件期间被添加到服务工作线程缓存时。上述示例展示了这种用法。在这种情况下,代码缓存会在资源被放入服务工作线程缓存时立即创建。此外,我们为这些脚本生成了“完整”的代码缓存——我们不再延迟编译函数,而是编译所有内容并将其放入缓存。这样做的好处是性能快速且可预测,并且无执行顺序依赖,但代价是增加了内存使用。
如果通过缓存 API 在服务工作线程安装事件之外存储 JavaScript 资源,则代码缓存不会立即生成。相反,如果服务工作线程从缓存中响应该响应,那么将在首次加载时生成“普通”代码缓存。此代码缓存将在第二次加载时可供使用,比典型代码缓存场景快了一次加载。当在 fetch 事件中以“逐步”缓存资源的方式或从主窗口而不是服务工作线程更新缓存 API 时,资源可能会在安装事件之外存储到缓存 API 中。
请注意,预缓存的“完整”代码缓存假定运行脚本的页面将使用 UTF-8 编码。如果页面最终使用其他编码,则代码缓存将被丢弃,并替换为“普通”代码缓存。
此外,预缓存的“完整”代码缓存假定页面将以经典的 JS脚本加载该脚本。如果页面最终以 ES模块加载它,则代码缓存将被丢弃,并替换为“普通”代码缓存。
跟踪
以上建议无法保证一定会加速您的网络应用。不幸的是,目前开发者工具中尚未暴露代码缓存信息,因此寻找有关您的网络应用脚本哪些被代码缓存的最可靠方法是使用稍微底层一点的 chrome://tracing。
chrome://tracing 记录了一段时间内 Chrome 的测量跟踪,其中生成的跟踪可视化看起来像这样:
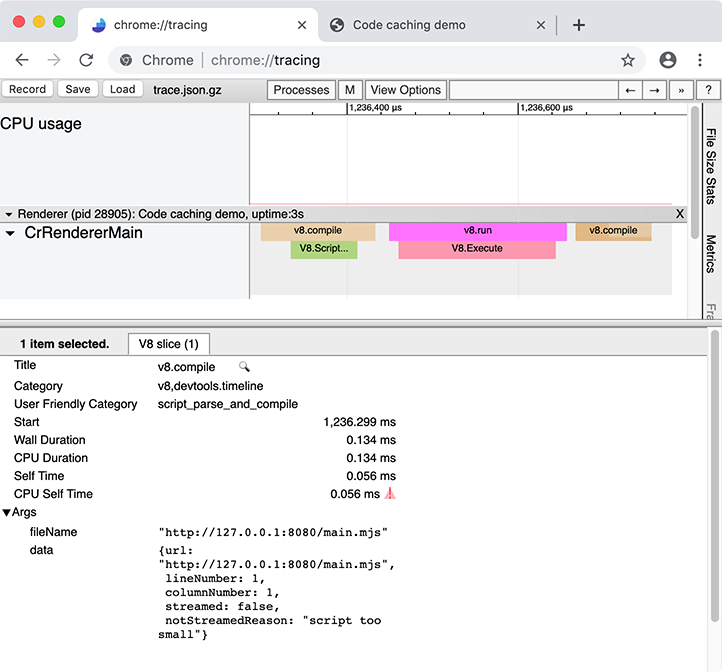
跟踪记录了整个浏览器的行为,包括其他标签页、窗口和扩展程序,因此在清洁用户配置文件中进行此操作效果最佳,同时禁用扩展程序并且没有打开其他浏览器标签页:
# 启动一个新的 Chrome 浏览器会话,使用一个干净的用户配置文件并禁用扩展程序
google-chrome --user-data-dir="$(mktemp -d)" --disable-extensions
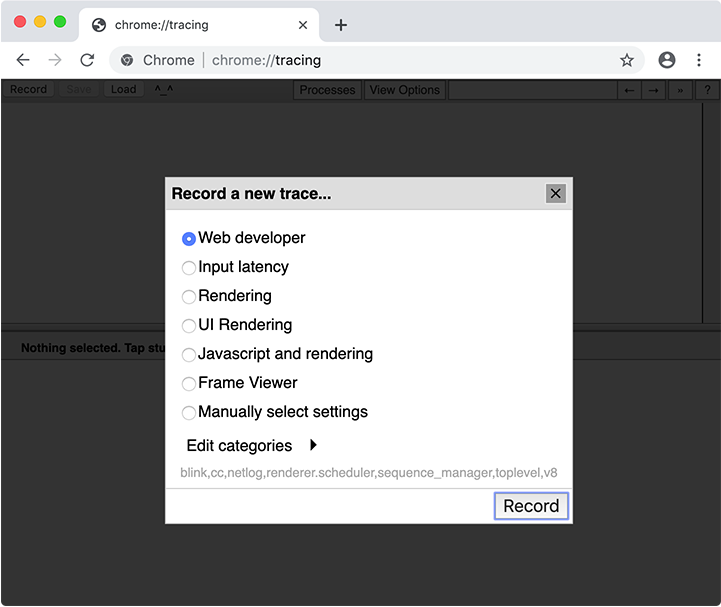
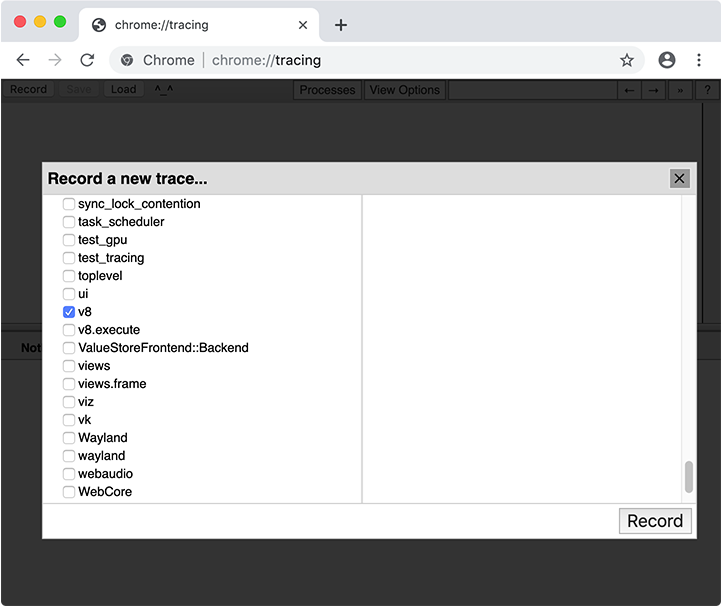
在收集跟踪时,您需要选择要跟踪的类别。在大多数情况下,您可以简单地选择“Web开发者”类别集,但也可以手动选择类别。代码缓存的重要类别是 v8。
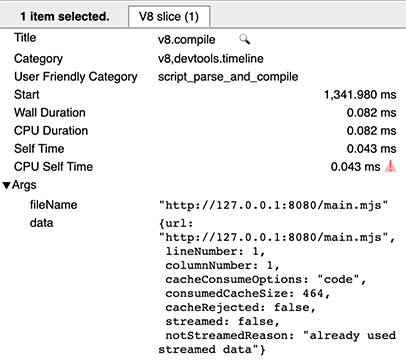
在记录了 v8 类别的跟踪后,请在跟踪中寻找 v8.compile 切片。(另外,您可以在跟踪界面的搜索框中输入 v8.compile。)这些条目列出了正在编译的文件以及一些关于编译的元数据。
在一次脚本的冷启动中,没有关于代码缓存的信息——这意味着脚本没有涉及生产或消费缓存数据。
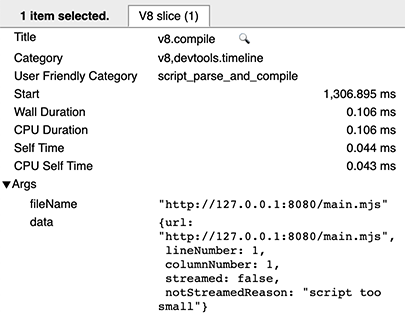
在一次暖启动中,每个脚本有两个 v8.compile 条目:一个用于实际编译(如上),另一个(执行后)用于生成缓存。您可以通过其 cacheProduceOptions 和 producedCacheSize 元数据字段识别后者。
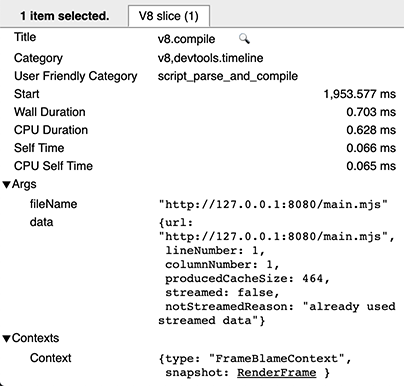
在一次热启动中,您会看到一个用于消费缓存的 v8.compile 条目,其中包含元数据字段 cacheConsumeOptions 和 consumedCacheSize。所有大小以字节为单位。
结论
对于大多数开发者来说,代码缓存应该“正常工作”。像任何缓存一样,它在保持不变的情况下效果最佳,并且基于版本之间可能变化的启发式方法运行。然而,代码缓存确实具有可以利用的行为和可以避免的限制,使用 chrome://tracing 进行仔细分析可以帮助您调整并优化您的网络应用对缓存的使用。