V8에서 빠른 속성
이 블로그 게시물에서는 V8이 JavaScript 속성을 내부적으로 어떻게 처리하는지 설명하고자 합니다. JavaScript의 관점에서 속성에 대한 몇 가지 구별만 필요합니다. JavaScript 객체는 대부분 문자열 키와 임의 객체를 값으로 하는 사전처럼 작동합니다. 하지만 사양에서는 정수 인덱스 속성과 다른 속성을 반복 중 다르게 취급합니다. 그 외에는 정수 인덱스인지 아닌지에 관계없이 서로 다른 속성이 대부분 동일하게 작동합니다.
그러나 내부적으로 V8은 성능 및 메모리 문제로 인해 속성의 여러 다른 표현에 의존합니다. 이 블로그 게시물에서는 V8이 동적으로 추가된 속성을 처리하는 동시에 빠른 속성 접근을 제공하는 방법을 설명할 것입니다. 속성이 작동하는 방식에 대한 이해는 V8에서 인라인 캐시와 같은 최적화가 작동하는 방식을 설명하는 데 필수적입니다.
이 게시물에서는 정수 인덱스 속성과 이름 속성을 처리하는 차이점을 설명합니다. 그 후 V8이 이름 속성을 추가할 때 객체의 형태를 빠르게 식별하는 방법으로 HiddenClass를 유지하는 방법을 보여줍니다. 그런 다음 이름 속성이 사용 방식에 따라 빠른 접근 또는 빠른 수정에 최적화되는 방법에 대한 통찰력을 제공합니다. 마지막 섹션에서는 V8이 정수 인덱스 속성 또는 배열 인덱스를 처리하는 방법에 대한 세부 정보를 제공합니다.
이름 속성 vs 요소
먼저 {a: "foo", b: "bar"}와 같은 매우 간단한 객체를 분석해 보겠습니다. 이 객체는 "a"와 "b"라는 두 개의 이름 속성을 가지고 있습니다. 속성 이름에 대한 정수 인덱스는 포함되지 않습니다. 배열 인덱스 속성, 일반적으로 요소로 알려진 속성은 배열에서 가장 두드러지게 나타납니다. 예를 들어 배열 ["foo", "bar"]는 두 개의 배열 인덱스 속성을 가지고 있습니다: 값 "foo"를 가진 0과 값 "bar"를 가진 1입니다. 이것이 V8이 일반적으로 속성을 처리하는 방식에 대한 첫 번째 주요 차별점입니다.
다음 다이어그램은 메모리 내 기본 JavaScript 객체가 어떻게 생겼는지 보여줍니다.
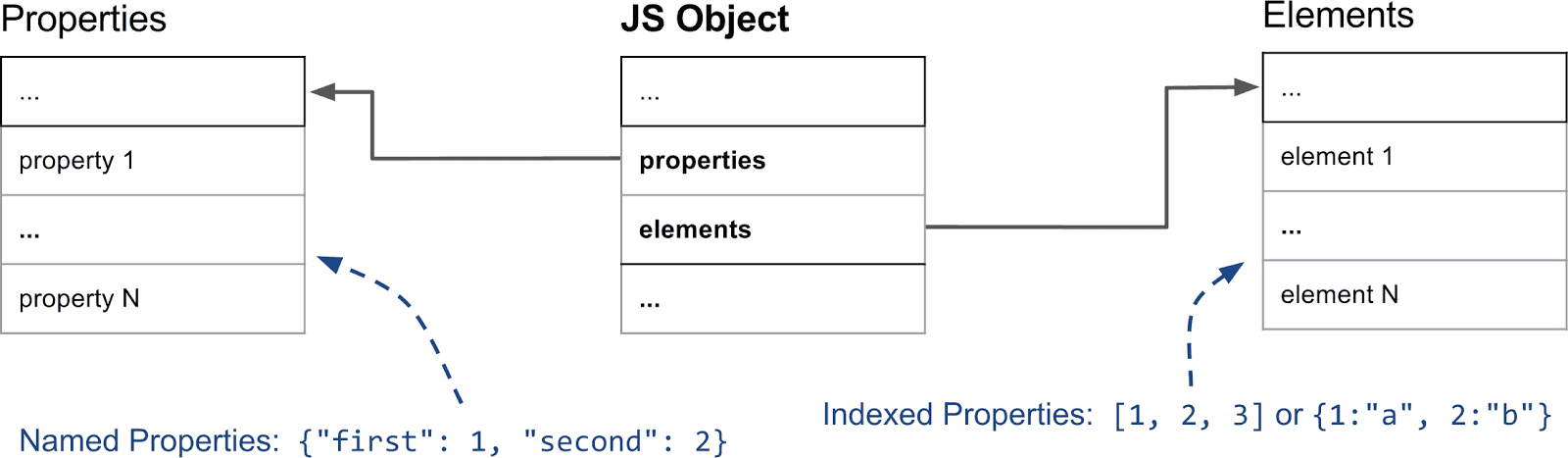
요소와 속성은 두 개의 별도 데이터 구조에 저장되며, 이는 속성 또는 요소를 추가하거나 액세스하는 데 있어 다른 사용 패턴에 대해 더 효율적으로 만듭니다.
요소는 주로 pop, slice와 같은 다양한 Array.prototype 메서드에 사용됩니다. 이러한 함수는 연속 범위에서 속성에 접근하므로, V8은 내부적으로 대부분 단순 배열로 이를 표현합니다. 이후에 메모리를 절약하기 위해 스파스한 사전 기반 표현으로 전환하는 경우를 설명하겠습니다.
이름 속성은 별도의 배열에 유사한 방식으로 저장됩니다. 그러나 요소와 달리 속성 배열 내에서 위치를 추론하기 위해 키를 사용할 수 없으므로 추가 메타데이터가 필요합니다. V8에서는 모든 JavaScript 객체에 HiddenClass가 연결되어 있습니다. HiddenClass는 객체 형태에 대한 정보를 저장하며, 여러 가지 중속성 이름에서 속성 배열의 인덱스에 대한 매핑 정보를 포함하고 있습니다. 간혹 속성을 단순 배열 대신 사전을 사용하기도 하는데, 이는 전용 섹션에서 자세히 설명하겠습니다.
이 섹션에서 얻을 수 있는 것:
- 배열 인덱스 속성은 별도의 요소 저장소에 저장됩니다.
- 이름 속성은 속성 저장소에 저장됩니다.
- 요소와 속성은 배열이나 사전일 수 있습니다.
- 각 JavaScript 객체에는 객체 형태에 대한 정보를 유지하는 HiddenClass가 연결되어 있습니다.
HiddenClass와 DescriptorArrays
요소와 명명된 속성의 일반적인 구분을 설명한 후, V8에서 HiddenClass가 어떻게 작동하는지 살펴봐야 합니다. HiddenClass는 객체에 대한 메타 정보를 저장하며, 여기에는 객체의 속성 수와 객체의 프로토타입에 대한 참조가 포함됩니다. HiddenClass는 전형적인 객체 지향 프로그래밍 언어의 클래스와 개념적으로 유사합니다. 그러나 JavaScript와 같은 프로토타입 기반 언어에서는 사전에 클래스를 알 수 없는 경우가 일반적입니다. 따라서 V8에서 HiddenClass는 객체가 변경됨에 따라 즉석에서 생성되고 동적으로 업데이트됩니다. HiddenClass는 객체의 모양을 식별하는 역할을 하며, V8의 최적화 컴파일러와 인라인 캐시에 매우 중요한 요소입니다. 예를 들어, 최적화 컴파일러는 HiddenClass를 통해 호환 가능한 객체 구조를 보장할 수 있다면 속성 접근을 직접 인라인화할 수 있습니다.
HiddenClass의 중요한 부분을 살펴봅시다.
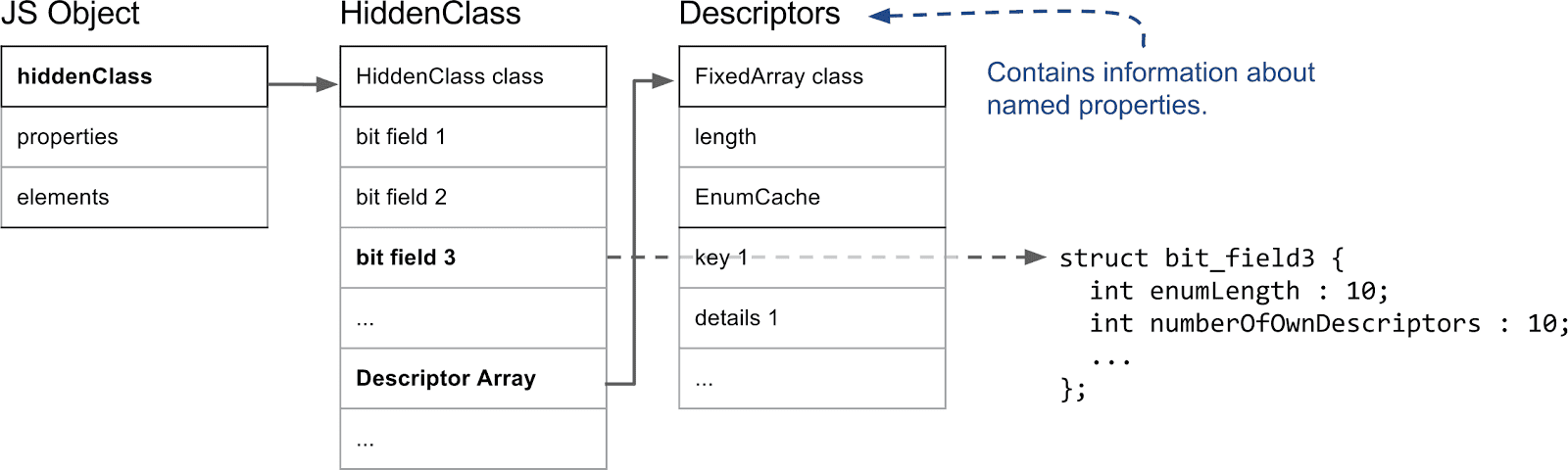
V8에서 JavaScript 객체의 첫 번째 필드는 HiddenClass를 가리킵니다. (사실, 이것은 V8 힙에 있으며 가비지 컬렉터에 의해 관리되는 모든 객체의 경우입니다.) 속성 측면에서 가장 중요한 정보는 속성 수를 저장하는 세 번째 비트 필드와 디스크립터 배열에 대한 포인터입니다. 디스크립터 배열에는 속성 이름 자체와 값이 저장된 위치와 같은 명명된 속성에 대한 정보가 포함되어 있습니다. 여기서 정수로 인덱싱된 속성은 추적하지 않으므로 디스크립터 배열에 해당 항목이 없습니다.
HiddenClass에 대한 기본 가정은 동일한 구조를 가진 객체 — 예: 동일한 순서로 동일한 이름의 속성을 가진 객체 — 는 동일한 HiddenClass를 공유한다는 것입니다. 이를 달성하기 위해 객체에 속성이 추가될 때마다 다른 HiddenClass를 사용합니다. 다음 예에서는 빈 객체에서 시작하여 세 개의 명명된 속성을 추가하는 과정을 보여줍니다.
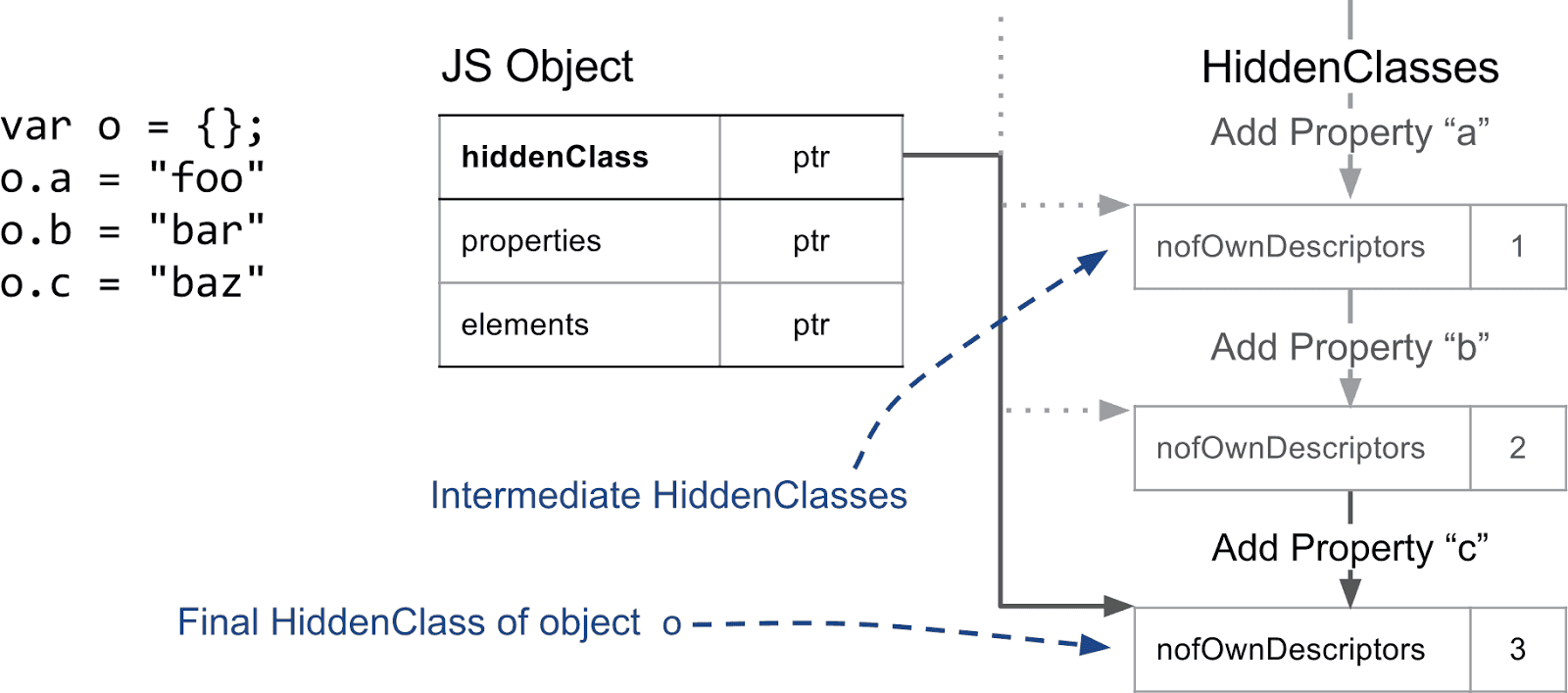
새로운 속성이 추가될 때마다 객체의 HiddenClass가 변경됩니다. 백그라운드에서 V8은 HiddenClass를 연결하는 전환 트리를 생성합니다. V8은 예를 들어 빈 객체에 "a" 속성을 추가할 때 사용할 HiddenClass를 알고 있습니다. 이 전환 트리는 동일한 순서로 동일한 속성을 추가하는 경우 동일한 최종 HiddenClass에 도달하도록 보장합니다. 다음 예는 간단히 인덱싱된 속성을 사이에 추가하더라도 동일한 전환 트리를 따르게 된다는 사실을 보여줍니다.
![]()
그러나 다른 속성을 추가하는 새로운 객체를 생성하는 경우, 이 경우 속성 "d", V8은 새로운 HiddenClass에 대한 별도의 분기를 생성합니다.
![]()
이 섹션의 요약:
- 동일한 구조(동일한 순서로 동일한 속성)를 가진 객체는 동일한 HiddenClass를 가지고 있습니다.
- 기본적으로 새 명명된 속성이 추가될 때마다 새로운 HiddenClass가 생성됩니다.
- 배열로 인덱싱된 속성을 추가해도 새로운 HiddenClass는 생성되지 않습니다.
명명된 속성의 세 가지 유형
V8이 HiddenClass를 사용하여 객체의 모양을 추적하는 방법에 대한 개요를 제공한 후 이제 이 속성이 실제로 어떻게 저장되는지 살펴보겠습니다. 위의 소개에서 설명한 것처럼 속성에는 두 가지 기본 유형이 있습니다: 명명된 속성과 인덱싱된 속성. 다음 섹션에서는 명명된 속성을 다룹니다.
{a: 1, b: 2}와 같은 간단한 객체는 V8에서 다양한 내부 표현을 가질 수 있습니다. JavaScript 객체는 외부에서는 단순한 사전처럼 작동하지만, V8은 인라인 캐시와 같은 특정 최적화를 방해하기 때문에 사전을 사용하지 않으려고 합니다. 이는 별도의 게시물에서 설명할 것입니다.
객체 내부 속성 vs 일반 속성: V8은 객체 자체에 직접 저장되는 이른바 내부 속성을 지원합니다. 이러한 속성은 어떤 간접 참조 없이 접근할 수 있으므로 V8에서 가장 빠른 속성입니다. 객체의 초깃값에 따라 내부 속성의 수가 결정됩니다. 객체 내에 공간이 부족하여 속성을 추가해야 하는 경우 속성 저장소에 저장됩니다. 속성 저장소는 하나의 간접 참조 레벨을 추가하지만 독립적으로 확장될 수 있습니다.
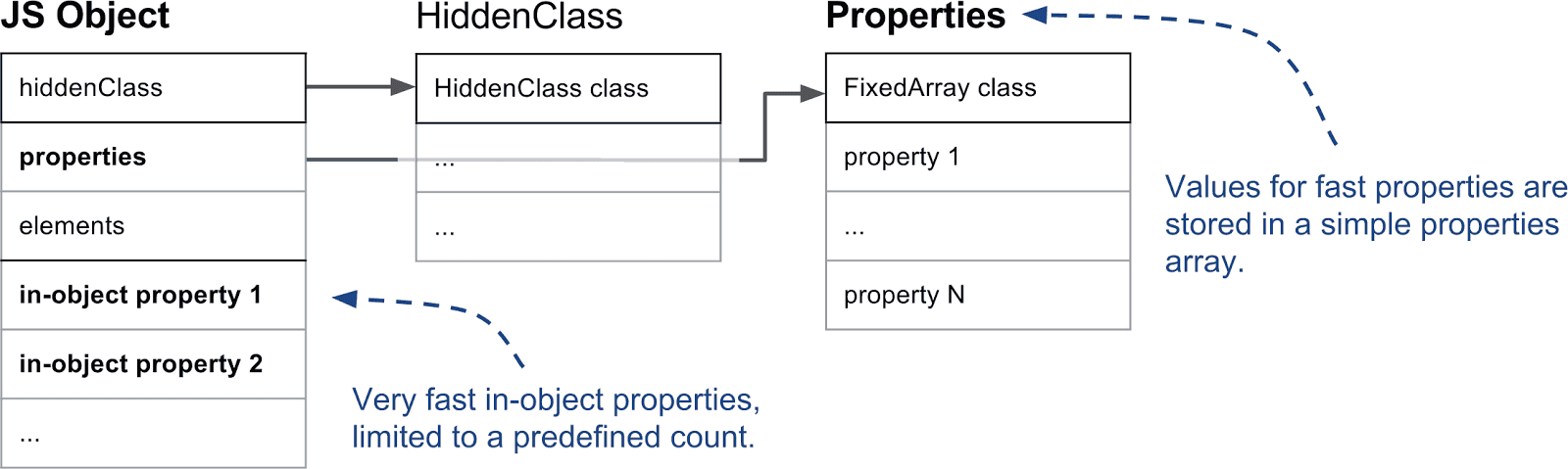
빠른 속성 vs 느린 속성: 다음 중요한 구분은 빠른 속성과 느린 속성 간의 차이입니다. 일반적으로 선형 속성 저장소에 저장된 속성을 "빠른" 속성으로 정의합니다. 빠른 속성은 단순히 속성 저장소의 인덱스를 통해 액세스됩니다. 속성 이름에서 실제 속성 저장소 위치로 이동하려면, 앞서 설명한 바와 같이 HiddenClass의 디스크립터 배열을 참조해야 합니다.
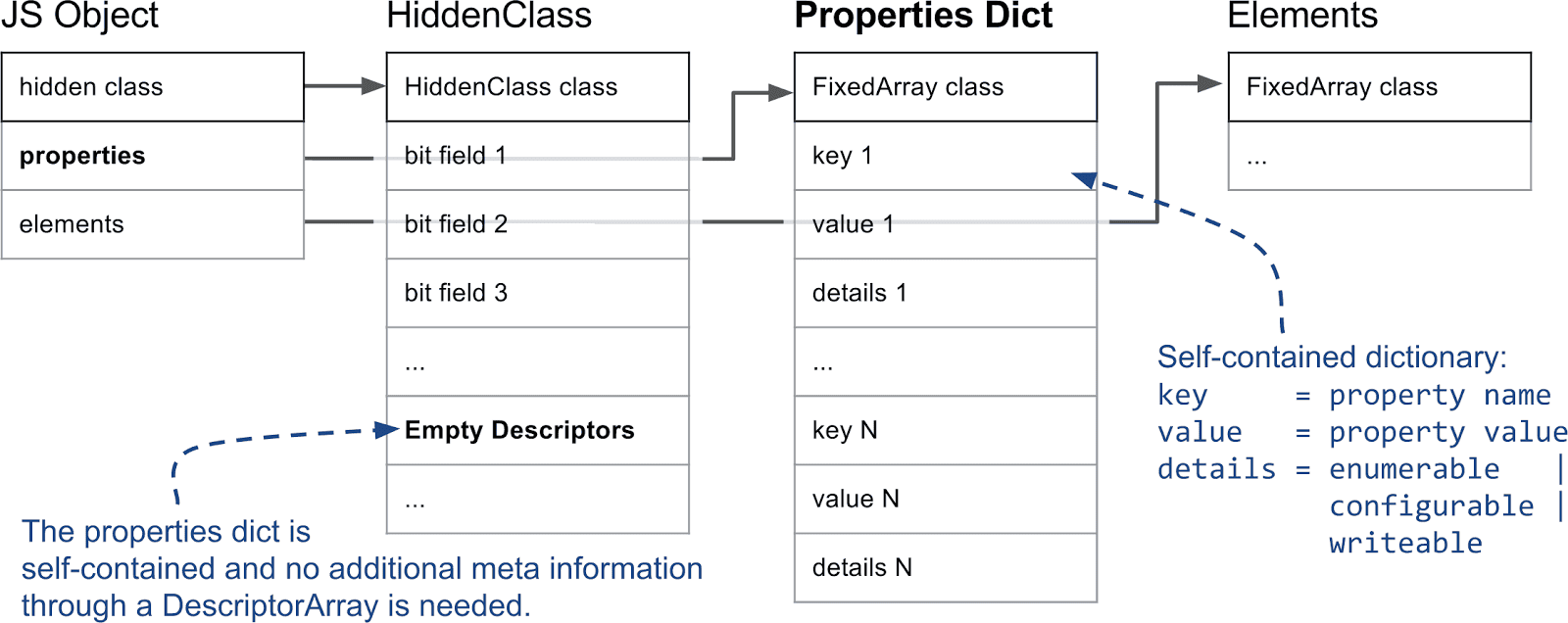
하지만 객체에서 속성이 많이 추가되고 삭제되는 경우 디스크립터 배열과 HiddenClass를 유지 관리하는 데 많은 시간과 메모리 오버헤드가 발생할 수 있습니다. 따라서 V8은 이른바 느린 속성도 지원합니다. 느린 속성을 가진 객체는 자체적으로 포함된 사전 저장소를 가집니다. 모든 속성 메타 정보는 더 이상 HiddenClass의 디스크립터 배열에 저장되지 않고 속성 사전에 직접 저장됩니다. 따라서 HiddenClass를 업데이트하지 않고도 속성을 추가 및 제거할 수 있습니다. 인라인 캐시는 사전 속성과 함께 작동하지 않으므로 후자는 일반적으로 빠른 속성보다 느립니다.
이 섹션의 요약:
- 명명된 속성에는 세 가지 유형이 있습니다: 내부 속성, 빠른 속성 및 느린/사전 속성.
- 내부 속성은 객체 자체에 직접 저장되며 가장 빠른 접근을 제공합니다.
- 빠른 속성은 속성 저장소에 있으며 모든 메타 정보는 HiddenClass의 설명자 배열에 저장됩니다.
- 느린 속성은 독립적인 속성 사전 형태로 저장되며 메타 정보는 더 이상 HiddenClass를 통해 공유되지 않습니다.
- 느린 속성은 속성 제거 및 추가에 효율적이지만, 다른 두 유형에 비해 접근 속도가 느립니다.
요소 또는 배열-인덱스형 속성
지금까지는 이름이 있는 속성만 살펴봤으며 배열에서 자주 사용되는 정수형 인덱스 속성은 무시했습니다. 정수형 인덱스 속성의 처리 과정은 이름 있는 속성만큼이나 복잡합니다. 모든 인덱스 속성은 항상 요소 저장소에 개별적으로 저장되지만 20가지 서로 다른 유형의 요소가 있습니다!
압축 또는 Holey 요소: V8이 만드는 첫 번째 주요 구분은 요소 백업 저장소가 압축되어 있는지 아니면 중간에 공백(Hole)이 있는지 여부입니다. 백업 저장소에 공백이 생기는 경우는 인덱스 요소를 삭제하거나 정의하지 않는 경우입니다. 간단한 예는 [1,,3]로, 두 번째 항목이 공백인 경우입니다. 다음 예시는 이 문제를 보여줍니다:
const o = ['a', 'b', 'c'];
console.log(o[1]); // 'b' 출력.
delete o[1]; // 요소 저장소에 공백을 삽입합니다.
console.log(o[1]); // 'undefined' 출력; 속성 1은 존재하지 않습니다.
o.__proto__ = {1: 'B'}; // 프로토타입에 속성 1을 정의합니다.
console.log(o[0]); // 'a' 출력.
console.log(o[1]); // 'B' 출력.
console.log(o[2]); // 'c' 출력.
console.log(o[3]); // undefined 출력

요약하자면, 리시버에 속성이 존재하지 않는 경우 프로토타입 체인에서 계속 검색해야 합니다. 요소는 독립적이므로 예를 들어 HiddenClass에서 존재하는 인덱스 속성에 대한 정보를 저장하지 않습니다. 따라서 존재하지 않는 속성을 표시하기 위해 _hole이라고 불리는 특별한 값을 사용해야 합니다. 이는 배열 함수의 성능에 중요합니다. 요소 저장소가 압축되어 있어 공백이 없다는 사실을 알고 있다면 프로토타입 체인에서 비싼 조회 없이 로컬 작업을 수행할 수 있습니다.
빠른 요소 또는 사전 요소: 요소에 대해 두 번째 주요 구분은 빠른 요소인지 사전 모드인지입니다. 빠른 요소는 속성 인덱스가 요소 저장소 내의 인덱스와 매핑되는 단순한 VM 내부 배열입니다. 그러나 이 단순한 표현 방식은 매우 드문 경우의 크고 공백이 많은 배열에서는 낭비가 심할 수 있습니다. 이러한 경우 메모리를 절약하기 위해 약간 느린 접근 비용으로 사전 기반 표현 방식을 사용합니다:
const sparseArray = [];
sparseArray[9999] = 'foo'; // 사전 요소로 배열을 생성합니다.
이 예제에서는 1만 개 항목이 있는 전체 배열을 할당하는 것이 낭비가 될 것입니다. 대신 V8은 키-값-설명자 트리플릿을 저장하는 사전을 생성합니다. 이 경우 키는 '9999', 값은 'foo', 기본 설명자가 사용됩니다. HiddenClass에 설명자 세부사항을 저장하는 방법이 없으므로, 직접 정의한 인덱스 속성이 사용자 지정 설명자를 가진 경우 V8은 느린 요소로 전환합니다:
const array = [];
Object.defineProperty(array, 0, {value: 'fixed' configurable: false});
console.log(array[0]); // 'fixed' 출력.
array[0] = 'other value'; // 인덱스 0을 덮어쓸 수 없습니다.
console.log(array[0]); // 여전히 'fixed' 출력.
이 예제에서는 배열에 설정 불가능한 속성을 추가했습니다. 이 정보는 느린 요소 사전 트리플릿의 설명자 부분에 저장됩니다. Array 함수는 느린 요소가 있는 객체에서 상당히 느려진다는 점을 중요하게 알아두어야 합니다.
Smi 및 Double 요소: 빠른 요소에 대해서는 V8에서 또 다른 중요한 구분이 이루어집니다. 예를 들어 배열에 정수만 저장하는 경우, 이는 GC가 배열을 살펴보지 않아도 되기 때문에 일반적인 사용 사례입니다. 정수는 소위 작은 정수(Smis)로 직접 인코딩됩니다. 또 다른 특별한 경우는 배열이 실수(Double)만 포함하는 경우입니다. Smis와 달리 부동 소수점 숫자는 일반적으로 여러 단어를 사용하는 전체 객체로 표현됩니다. 그러나 V8은 순수 실수 배열의 경우 메모리 및 성능 오버헤드를 피하기 위해 원시 실수를 저장합니다. 다음 예는 Smi 및 Double 요소의 4가지 사례를 나열합니다:
const a1 = [1, 2, 3]; // Smi 압축
const a2 = [1, , 3]; // Smi Holey, a2[1]은 프로토타입에서 읽음
const b1 = [1.1, 2, 3]; // Double 압축
const b2 = [1.1, , 3]; // Double Holey, b2[1]은 프로토타입에서 읽음
특수 요소: 지금까지 설명한 정보로 20가지 서로 다른 요소 종류 중 7가지를 다뤘습니다. 간단히 하기 위해 TypedArrays에 대한 9가지 요소 종류, 문자열 래퍼에 대한 2가지 요소 종류, 마지막으로 인자 객체에 대한 2가지 특별 요소 종류를 제외했습니다.
ElementsAccessor: 여러분이 상상할 수 있듯이, 우리는 요소 종류을 위해 C++에서 배열 함수들을 20번씩 작성하는 것을 별로 좋아하지 않습니다. 여기서 몇 가지 C++ 마법이 등장합니다. 배열 함수를 반복적으로 구현하는 대신, 우리는 ElementsAccessor를 만들어 저장소에서 요소를 접근하는 단순한 함수만 주로 구현합니다. ElementsAccessor는 CRTP를 활용하여 각 배열 함수의 전문화된 버전을 생성합니다. 배열에서 slice와 같은 것을 호출하면, V8은 내부적으로 C++로 작성된 내장 기능을 호출하고 ElementsAccessor를 통해 해당 함수의 전문화된 버전에 전달합니다:
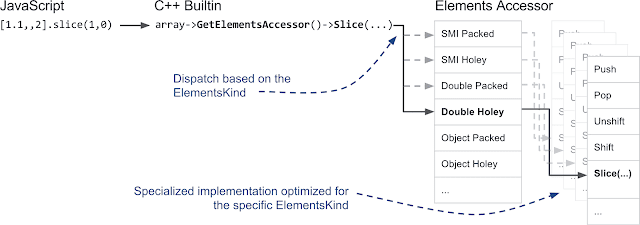
이 섹션에서의 요점:
- 빠른 모드와 딕셔너리 모드의 인덱스 속성과 요소가 있습니다.
- 빠른 속성은 압축될 수 있거나, 삭제된 인덱스 속성을 나타내는 구멍을 포함할 수 있습니다.
- 요소들은 배열 함수를 빠르게 하고 GC 부담을 줄이기 위해 그 내용에 따라 전문화됩니다.
속성이 어떻게 작동하는지 이해하는 것은 V8에서 많은 최적화의 핵심입니다. JavaScript 개발자들에게 이러한 내부 결정은 직접적으로 보이지 않지만, 특정 코드 패턴이 다른 패턴보다 왜 더 빠른지 설명합니다. 속성이나 요소 유형을 변경하면 V8이 다른 HiddenClass를 생성하여 유형 오염을 초래할 수 있으며, 이는 V8이 최적의 코드를 생성하는 것을 방해합니다. V8의 VM 내부가 어떻게 작동하는지에 대한 추가 포스팅을 기대해 주세요.