Una pasantía sobre la pereza: desvinculación perezosa de funciones desoptimizadas
Hace aproximadamente tres meses, me uní al equipo de V8 (Google Munich) como pasante y desde entonces he estado trabajando en el Desoptimizador de la máquina virtual, algo completamente nuevo para mí que resultó ser un proyecto interesante y desafiante. La primera parte de mi pasantía se enfocó en mejorar la seguridad de la máquina virtual. La segunda parte se centró en mejoras de rendimiento, específicamente en la eliminación de una estructura de datos utilizada para la desvinculación de funciones previamente desoptimizadas, que representaba un cuello de botella de rendimiento durante la recolección de basura. Esta publicación describe esta segunda parte de mi pasantía. Explicaré cómo V8 solía desvincular funciones desoptimizadas, cómo cambiamos esto y qué mejoras de rendimiento se obtuvieron.
Recapitulemos (muy brevemente) el flujo de trabajo de V8 para una función JavaScript: el intérprete de V8, Ignition, recoge información de perfil sobre esa función mientras la interpreta. Una vez que la función se vuelve frecuente, esta información se pasa al compilador de V8, TurboFan, que genera código máquina optimizado. Cuando la información de perfil ya no es válida, por ejemplo, porque uno de los objetos perfilados obtiene un tipo diferente durante la ejecución, el código máquina optimizado podría volverse inválido. En ese caso, V8 necesita desoptimizarlo.
Durante la optimización, TurboFan genera un objeto de código, es decir, el código máquina optimizado, para la función en optimización. La próxima vez que se invoque esta función, V8 sigue el vínculo al código optimizado para esa función y lo ejecuta. Al desoptimizar esta función, necesitamos desvincular el objeto de código para asegurarnos de que no se ejecutará nuevamente. ¿Cómo ocurre esto?
Por ejemplo, en el siguiente código, la función f1 será invocada muchas veces (siempre pasando un entero como argumento). TurboFan luego genera código máquina para ese caso específico.
function g() {
return (i) => i;
}
// Crear un cierre.
const f1 = g();
// Optimizar f1.
for (var i = 0; i < 1000; i++) f1(0);
Cada función también tiene un trampolín hacia el intérprete —más detalles en estas diapositivas— y mantendrá un puntero a este trampolín en su SharedFunctionInfo (SFI). Este trampolín se utilizará cada vez que V8 necesite volver al código no optimizado. Por lo tanto, al desoptimizar, activado al pasar un argumento de un tipo diferente, por ejemplo, el Desoptimizador puede simplemente establecer el campo de código de la función JavaScript en este trampolín.
Aunque esto parece sencillo, obliga a V8 a mantener listas débiles de funciones JavaScript optimizadas. Esto se debe a que es posible tener diferentes funciones apuntando al mismo objeto de código optimizado. Podemos extender nuestro ejemplo de la siguiente manera, y las funciones f1 y f2 apuntan al mismo código optimizado.
const f2 = g();
f2(0);
Si la función f1 es desoptimizada (por ejemplo, al invocarla con un objeto de tipo diferente {x: 0}) necesitamos asegurarnos de que el código invalidado no se ejecutará nuevamente al invocar f2.
Por lo tanto, al desoptimizar, V8 solía iterar sobre todas las funciones JavaScript optimizadas, y desvincularía aquellas que apuntaban al objeto de código que estaba siendo desoptimizado. Esta iteración en aplicaciones con muchas funciones JavaScript optimizadas se convirtió en un cuello de botella de rendimiento. Además, además de ralentizar la desoptimización, V8 solía iterar sobre estas listas durante los ciclos de recolección de basura con interrupción del mundo, haciéndolo aún peor.
Para tener una idea del impacto de dicha estructura de datos en el rendimiento de V8, escribimos un micro-benchmark que estresa su uso, activando muchos ciclos de recuperación después de crear muchas funciones JavaScript.
function g() {
return (i) => i + 1;
}
// Crear un cierre inicial y optimizar.
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// Crea 2M closures; estos obtendrán el código previamente optimizado.
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// Ahora causa colecciones rápidas; todas serán lentas.
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
Al ejecutar este benchmark, pudimos observar que V8 gastó alrededor del 98% de su tiempo de ejecución en la recolección de basura. Luego eliminamos esta estructura de datos y, en su lugar, utilizamos un enfoque de desvinculación perezosa, y esto fue lo que observamos en x64:

Aunque esta es solo una microprueba que crea muchas funciones de JavaScript y desencadena muchos ciclos de recolección de basura, nos da una idea del overhead introducido por esta estructura de datos. Otras aplicaciones más realistas donde vimos algo de overhead, y que motivaron este trabajo, fueron el router benchmark implementado en Node.js y la suite de pruebas ARES-6.
Desvinculación perezosa
En lugar de desvincular el código optimizado de las funciones de JavaScript al realizar una desoptimización, V8 lo pospone para la próxima invocación de dichas funciones. Cuando se invocan esas funciones, V8 verifica si han sido desoptimizadas, las desvincula y luego continúa con su compilación perezosa. Si estas funciones nunca se vuelven a invocar, entonces nunca se desvincularán y los objetos de código desoptimizados no se recopilarán. Sin embargo, dado que durante la desoptimización invalidamos todos los campos incrustados del objeto de código, solo mantenemos ese objeto de código vivo.
El commit que eliminó esta lista de funciones de JavaScript optimizadas requirió cambios en varias partes de la VM, pero la idea básica es la siguiente. Al ensamblar el objeto de código optimizado, verificamos si este es el código de una función de JavaScript. Si es así, en su prólogo, ensamblamos código máquina para salir si el objeto de código ha sido desoptimizado. Al realizar la desoptimización no modificamos el código desoptimizado —el parche de código desaparece. Por lo tanto, su bit marked_for_deoptimization aún está configurado al invocar la función nuevamente. TurboFan genera código para verificarlo y, si está configurado, V8 salta a un nuevo builtin, CompileLazyDeoptimizedCode, que desvincula el código desoptimizado de la función de JavaScript y luego continúa con la compilación perezosa.
En más detalle, el primer paso es generar instrucciones que carguen la dirección del código que se está ensamblando actualmente. Podemos hacerlo en x64, con el siguiente código:
Label current;
// Carga la dirección efectiva de la instrucción actual en rcx.
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
Después de eso, necesitamos obtener dónde en el objeto de código vive el bit marked_for_deoptimization.
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
Luego podemos probar el bit y si está configurado, saltamos al builtin CompileLazyDeoptimizedCode.
// Prueba si el bit está configurado, es decir, si el código está marcado para desoptimización.
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// Salta al builtin si lo está.
__ j(not_zero, /* manejador para el código builtin aquí */, RelocInfo::CODE_TARGET);
En el lado de este builtin CompileLazyDeoptimizedCode, todo lo que queda por hacer es desvincular el campo de código de la función de JavaScript y configurarlo al trampolín para la entrada del intérprete. Entonces, considerando que la dirección de la función de JavaScript está en el registro rdi, podemos obtener el puntero al SharedFunctionInfo con:
// Lectura del campo para obtener el SharedFunctionInfo.
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
…y de manera similar el trampolín con:
// Lectura del campo para obtener el objeto de código.
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
Luego podemos usarlo para actualizar la ranura de función para el puntero de código:
// Actualiza el campo de código de la función con el trampolín.
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// Barrera de escritura para proteger el campo.
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
Esto produce el mismo resultado que antes. Sin embargo, en lugar de cuidar la desvinculación en el Desoptimizer, necesitamos preocuparnos por ello durante la generación de código. De ahí el ensamblaje manual.
Lo anterior es cómo funciona en la arquitectura x64. Lo hemos implementado para ia32, arm, arm64, mips, y mips64 también.
Esta nueva técnica ya está integrada en V8 y, como discutiremos más adelante, permite mejoras de rendimiento. Sin embargo, viene con una pequeña desventaja: Antes, V8 consideraba desvincular solo en caso de desoptimización. Ahora, tiene que hacerlo en la activación de todas las funciones optimizadas. Además, la forma de comprobar el bit marked_for_deoptimization no es tan eficiente como podría ser, dado que necesitamos hacer algunos trabajos para obtener la dirección del objeto del código. Observa que esto sucede cada vez que se entra en una función optimizada. Una posible solución para este problema es mantener en un objeto de código un puntero a sí mismo. En lugar de hacer trabajo para encontrar la dirección del objeto de código cada vez que se invoca la función, V8 lo haría solo una vez, después de su construcción.
Resultados
Ahora observamos las ganancias y regresiones de rendimiento obtenidas con este proyecto.
Mejoras generales en x64
El siguiente gráfico nos muestra algunas mejoras y regresiones, en relación al commit anterior. Observa que cuanto más alto, mejor.
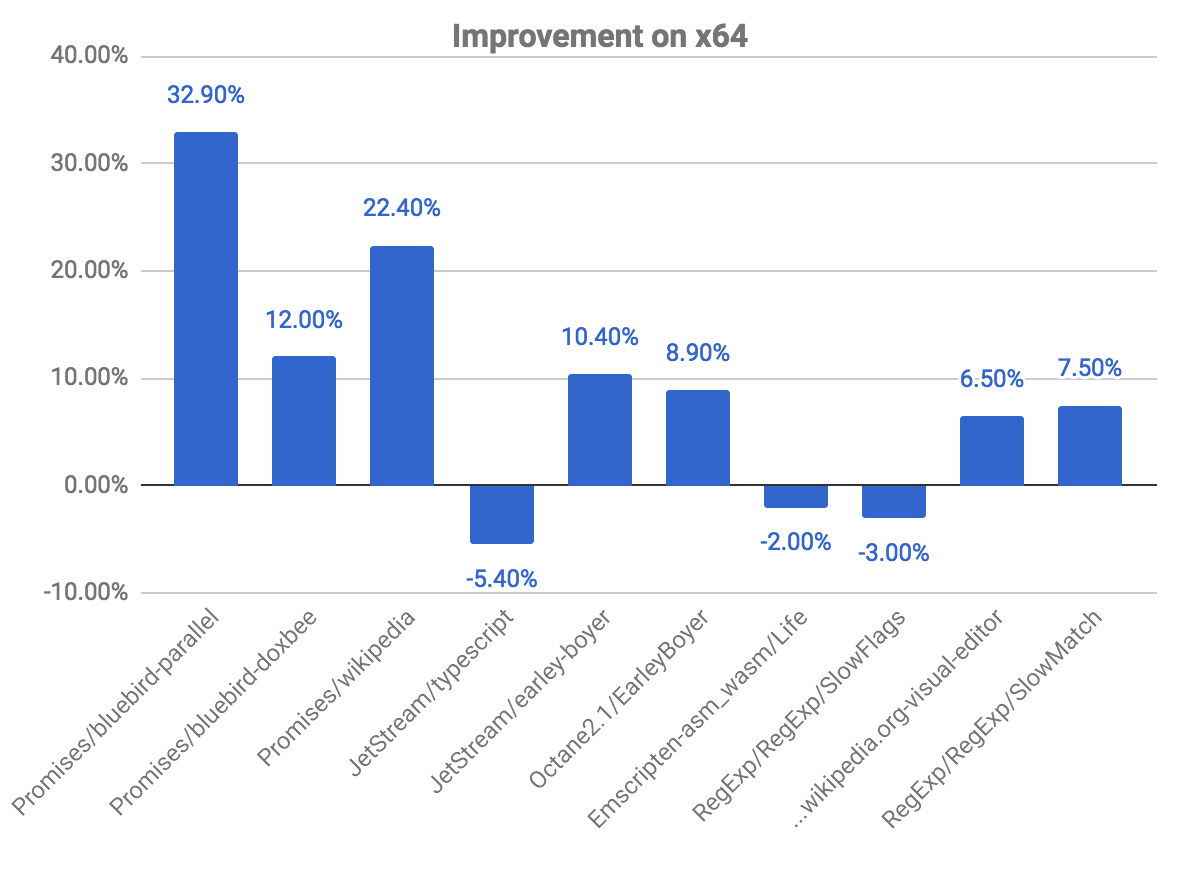
Los benchmarks de promises son aquellos donde vemos mayores mejoras, observando casi un 33% de ganancia para el benchmark bluebird-parallel, y un 22.40% para wikipedia. También observamos algunas regresiones en ciertos benchmarks. Esto está relacionado con el problema explicado anteriormente, sobre la comprobación de si el código está marcado para desoptimización.
También vemos mejoras en la suite de benchmarks ARES-6. Observa que en este gráfico también, cuanto más alto, mejor. Estos programas solían gastar una cantidad considerable de tiempo en actividades relacionadas con GC. Con la desvinculación diferida mejoramos el rendimiento en un 1.9% en general. El caso más notable es el Air steadyState, donde obtenemos una mejora de alrededor de 5.36%.

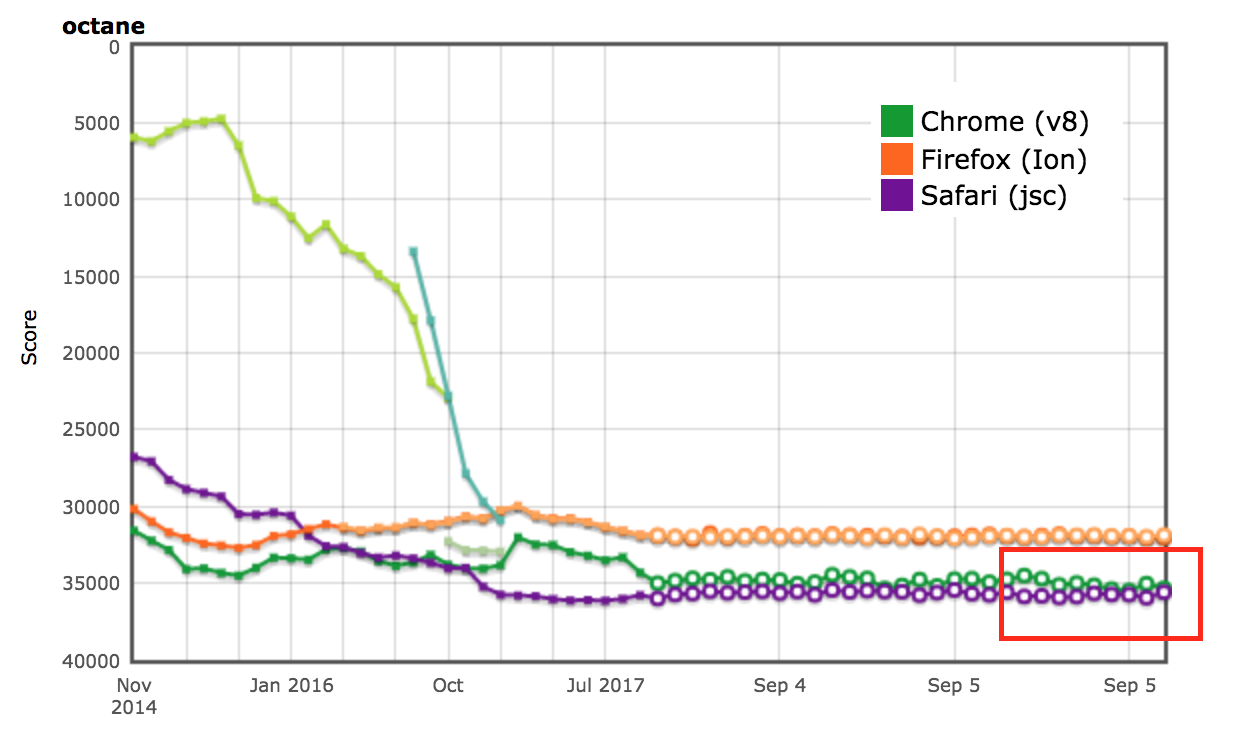
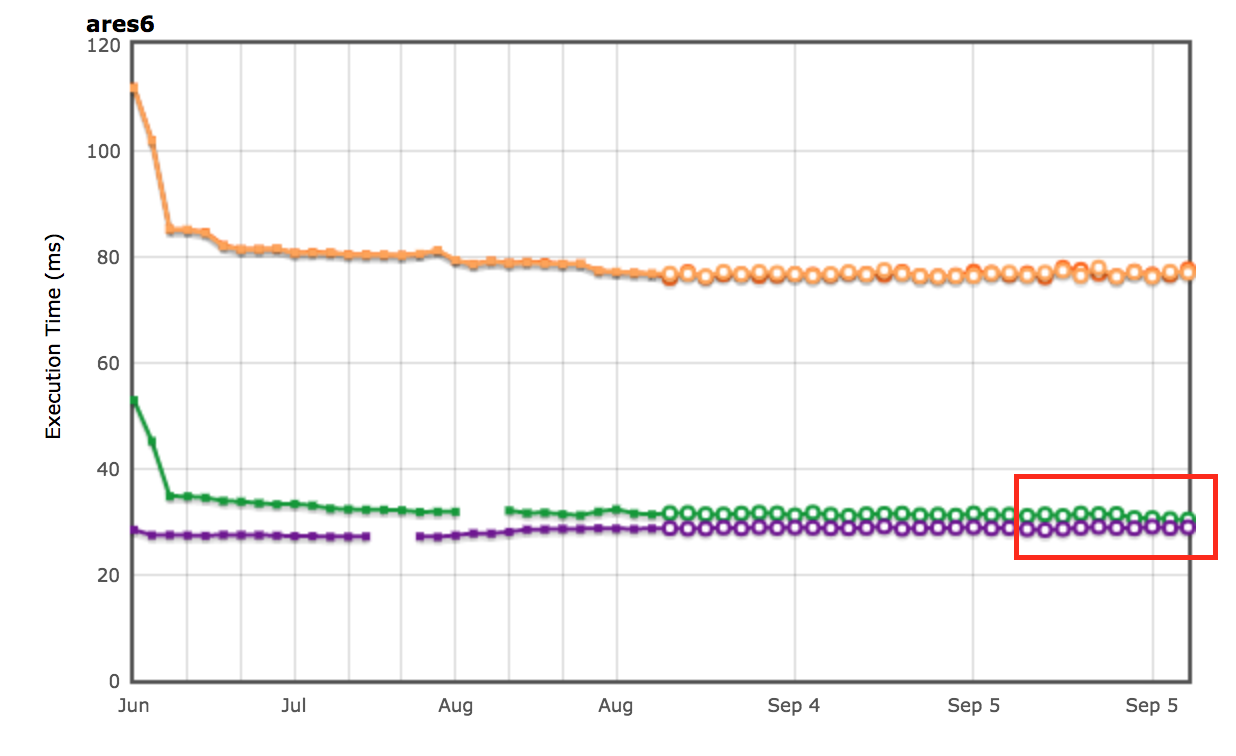
Resultados de AreWeFastYet
Los resultados de rendimiento para las suites de benchmarks Octane y ARES-6 también aparecieron en el tracker AreWeFastYet. Observamos estos resultados de rendimiento el 5 de septiembre de 2017, utilizando la máquina predeterminada proporcionada (macOS 10.10 64-bit, Mac Pro, shell).
Impacto en Node.js
También podemos observar mejoras de rendimiento en el router-benchmark. Los siguientes dos gráficos muestran el número de operaciones por segundo de cada enrutador probado. Así que, cuanto más alto, mejor. Hemos realizado dos tipos de experimentos con esta suite de benchmarks. En primer lugar, ejecutamos cada prueba por separado, para poder observar la mejora de rendimiento independientemente de las pruebas restantes. En segundo lugar, ejecutamos todas las pruebas a la vez, sin cambiar la VM, simulando así un entorno donde cada prueba está integrada con otras funcionalidades.
Para el primer experimento, observamos que las pruebas de router y express realizan aproximadamente el doble de operaciones que antes, en el mismo periodo de tiempo. Para el segundo experimento, observamos una mejora aún mayor. En algunos casos, como routr, server-router y router, el benchmark realiza aproximadamente 3.80×, 3× y 2× más operaciones, respectivamente. Esto sucede porque V8 acumula más funciones JavaScript optimizadas, prueba tras prueba. Así, cada vez que se ejecuta una prueba, si se activa un ciclo de recolección de basura, V8 tiene que visitar las funciones optimizadas de la prueba actual y de las anteriores.


Optimización adicional
Ahora que V8 ya no mantiene la lista enlazada de funciones JavaScript en el contexto, podemos eliminar el campo next de la clase JSFunction. Aunque esta es una modificación simple, nos permite ahorrar el tamaño de un puntero por función, lo que representa ahorros significativos en varias páginas web:
| Benchmark | Tipo | Ahorros de memoria (absolutos) | Ahorros de memoria (relativos) |
|---|---|---|---|
| facebook.com | Tamaño efectivo promedio | 170 KB | 3.70% |
| twitter.com | Tamaño promedio de objetos asignados | 284 KB | 1.20% |
| cnn.com | Tamaño promedio de objetos asignados | 788 KB | 1.53% |
| youtube.com | Tamaño promedio de objetos asignados | 129 KB | 0.79% |
Agradecimientos
A lo largo de mi pasantía, recibí mucha ayuda de varias personas, quienes siempre estuvieron disponibles para responder mis numerosas preguntas. Por lo tanto, me gustaría agradecer a las siguientes personas: Benedikt Meurer, Jaroslav Sevcik y Michael Starzinger por las discusiones sobre cómo funcionan el compilador y el desoptimizador; Ulan Degenbaev por ayudarme con el recolector de basura siempre que lo rompía; y Mathias Bynens, Peter Marshall, Camillo Bruni y Maya Armyanova por revisar este artículo.
Finalmente, este artículo es mi última contribución como pasante en Google y me gustaría aprovechar la oportunidad para agradecer a todos en el equipo de V8, y especialmente a mi anfitrión, Benedikt Meurer, por acogerme y por darme la oportunidad de trabajar en un proyecto tan interesante — ¡definitivamente aprendí mucho y disfruté mi tiempo en Google!