Un stage sur la paresse : délier paresseusement les fonctions désoptimisées
Il y a environ trois mois, j’ai rejoint l’équipe V8 (Google Munich) en tant que stagiaire et depuis, j’ai travaillé sur le Deoptimizer de la VM — quelque chose de totalement nouveau pour moi qui s’est avéré être un projet intéressant et stimulant. La première partie de mon stage s’est concentrée sur l’amélioration de la sécurité de la VM. La deuxième partie portait sur les améliorations des performances. Notamment, sur la suppression d’une structure de données utilisée pour délier les fonctions précédemment désoptimisées, ce qui était un goulot d’étranglement de performance durant la collecte des ordures. Cet article de blog décrit cette deuxième partie de mon stage. J’expliquerai comment V8 délait les fonctions désoptimisées auparavant, comment nous avons changé cela et quelles améliorations de performance ont été obtenues.
Reprenons (très) brièvement le pipeline V8 pour une fonction JavaScript : l’interpréteur de V8, Ignition, collecte des informations de profilage sur cette fonction pendant qu’il l’interprète. Une fois que la fonction devient chaude, ces informations sont transmises au compilateur de V8, TurboFan, qui génère du code machine optimisé. Lorsque les informations de profilage ne sont plus valables — par exemple parce qu’un des objets profilés obtient un type différent à l’exécution — le code machine optimisé pourrait devenir invalide. Dans ce cas, V8 doit la désoptimiser.
Lors de l’optimisation, TurboFan génère un objet de code, c’est-à-dire le code machine optimisé, pour la fonction en cours d’optimisation. Lorsque cette fonction est invoquée la prochaine fois, V8 suit le lien vers le code optimisé pour cette fonction et l’exécute. Lors de la désoptimisation de cette fonction, nous devons délier l’objet de code afin de nous assurer qu’il ne sera pas exécuté à nouveau. Comment cela se passe-t-il ?
Par exemple, dans le code suivant, la fonction f1 sera invoquée de nombreuses fois (en passant toujours un entier en argument). TurboFan génère alors du code machine pour ce cas spécifique.
function g() {
return (i) => i;
}
// Créer une fermeture.
const f1 = g();
// Optimiser f1.
for (var i = 0; i < 1000; i++) f1(0);
Chaque fonction possède également un trampoline vers l’interpréteur — plus de détails dans ces diapositives — et gardera un pointeur vers ce trampoline dans son SharedFunctionInfo (SFI). Ce trampoline sera utilisé chaque fois que V8 doit revenir à du code non optimisé. Ainsi, lors de la désoptimisation, déclenchée par exemple en passant un argument d’un type différent, le Désoptimisateur peut simplement définir le champ de code de la fonction JavaScript sur ce trampoline.
Bien que cela semble simple, cela force V8 à conserver des listes faibles des fonctions JavaScript optimisées. En effet, il est possible d’avoir différentes fonctions pointant vers le même objet de code optimisé. Nous pouvons étendre notre exemple comme suit, et les fonctions f1 et f2 pointent toutes deux vers le même code optimisé.
const f2 = g();
f2(0);
Si la fonction f1 est désoptimisée (par exemple en l’invoquant avec un objet de type différent {x: 0}), nous devons nous assurer que le code invalidé ne sera pas exécuté à nouveau en invoquant f2.
Ainsi, lors de la désoptimisation, V8 effectuait une itération sur toutes les fonctions JavaScript optimisées, et déliait celles qui pointaient vers l’objet de code en cours de désoptimisation. Cette itération, dans les applications comportant de nombreuses fonctions JavaScript optimisées, est devenue un goulot d’étranglement des performances. En outre, en ralentissant la désoptimisation, V8 effectuait également une itération sur ces listes lors des cycles d'arrêt complet de la collecte des ordures, ce qui rendait la situation encore pire.
Afin d’avoir une idée de l’impact de cette structure de données sur les performances de V8, nous avons rédigé un micro-benchmark qui met en avant son utilisation, en déclenchant de nombreux cycles de ramassage après avoir créé de nombreuses fonctions JavaScript.
function g() {
return (i) => i + 1;
}
// Créer une fermeture initiale et optimiser.
var f = g();
f(0);
f(0);
%OptimizeFunctionOnNextCall(f);
f(0);
// Créez 2M de fermetures ; celles-ci utiliseront le code précédemment optimisé.
var a = [];
for (var i = 0; i < 2000000; i++) {
var h = g();
h();
a.push(h);
}
// Provoquez maintenant des collectes ; elles seront toutes lentes.
for (var i = 0; i < 1000; i++) {
new Array(50000);
}
Lors de l'exécution de ce benchmark, nous avons observé que V8 consacrait environ 98 % de son temps d'exécution à la collecte des ordures. Nous avons ensuite supprimé cette structure de données et, à la place, utilisé une approche de déliaison paresseuse, et voici ce que nous avons observé sur x64 :

Bien que ce ne soit qu'un micro-benchmark qui crée de nombreuses fonctions JavaScript et déclenche de nombreux cycles de collecte des ordures, cela nous donne une idée de la surcharge introduite par cette structure de données. D'autres applications plus réalistes où nous avons constaté une certaine surcharge, et qui ont motivé ce travail, étaient le benchmark de routeur implémenté en Node.js et la suite de benchmarks ARES-6.
Déliaison paresseuse
Plutôt que de délier le code optimisé des fonctions JavaScript lors de la désoptimisation, V8 le reporte à l'invocation suivante de ces fonctions. Lorsqu'elles sont invoquées, V8 vérifie si elles ont été désoptimisées, les délie puis continue avec leur compilation paresseuse. Si ces fonctions ne sont jamais ré-invoquées, elles ne seront jamais déliées et les objets de code désoptimisés ne seront pas collectés. Cependant, étant donné qu'au cours de la désoptimisation, nous invalidons tous les champs intégrés de l'objet code, nous ne gardons en vie que cet objet code.
Le commit qui a supprimé cette liste de fonctions JavaScript optimisées a nécessité des modifications dans plusieurs parties de la VM, mais l'idée de base est la suivante. Lors de l'assemblage de l'objet code optimisé, nous vérifions s'il s'agit du code d'une fonction JavaScript. Si tel est le cas, dans son prologue, nous assemblons du code machine pour sortir si l'objet code a été désoptimisé. Lors de la désoptimisation, nous ne modifions pas le code désoptimisé — le patching de code est supprimé. Ainsi, son bit marked_for_deoptimization est toujours défini lorsqu'il est invoqué à nouveau. TurboFan génère du code pour le vérifier, et s'il est défini, alors V8 saute vers un nouveau builtin, CompileLazyDeoptimizedCode, qui délie le code désoptimisé de la fonction JavaScript et poursuit ensuite avec une compilation paresseuse.
Plus en détail, la première étape consiste à générer des instructions qui chargent l'adresse du code actuellement assemblé. Nous pouvons faire cela sur x64, avec le code suivant :
Label current;
// Chargez l'adresse effective de l'instruction actuelle dans rcx.
__ leaq(rcx, Operand(¤t));
__ bind(¤t);
Après cela, nous devons obtenir où vit le bit marked_for_deoptimization dans l'objet code.
int pc = __ pc_offset();
int offset = Code::kKindSpecificFlags1Offset - (Code::kHeaderSize + pc);
Nous pouvons ensuite tester le bit et s'il est défini, nous sautons vers le builtin CompileLazyDeoptimizedCode.
// Testez si le bit est défini, c'est-à-dire si le code est marqué pour la désoptimisation.
__ testl(Operand(rcx, offset),
Immediate(1 << Code::kMarkedForDeoptimizationBit));
// Sautez vers le builtin si c'est le cas.
__ j(not_zero, /* gestionnaire de code builtin ici */, RelocInfo::CODE_TARGET);
Dans le builtin CompileLazyDeoptimizedCode, tout ce qu'il reste à faire est délier le champ code de la fonction JavaScript et le définir sur le trampoline vers l'entrée de l'Interprète. Ainsi, en considérant que l'adresse de la fonction JavaScript est dans le registre rdi, nous pouvons obtenir le pointeur vers le SharedFunctionInfo avec :
// Lecture du champ pour obtenir le SharedFunctionInfo.
__ movq(rcx, FieldOperand(rdi, JSFunction::kSharedFunctionInfoOffset));
…et de manière similaire le trampoline avec :
// Lecture du champ pour obtenir l'objet code.
__ movq(rcx, FieldOperand(rcx, SharedFunctionInfo::kCodeOffset));
Nous pouvons alors l'utiliser pour mettre à jour la slot de la fonction pour le pointeur de code :
// Mettez à jour le champ code de la fonction avec le trampoline.
__ movq(FieldOperand(rdi, JSFunction::kCodeOffset), rcx);
// Barrière d'écriture pour protéger le champ.
__ RecordWriteField(rdi, JSFunction::kCodeOffset, rcx, r15,
kDontSaveFPRegs, OMIT_REMEMBERED_SET, OMIT_SMI_CHECK);
Cela produit le même résultat qu'avant. Cependant, plutôt que de s'occuper de la déliaison dans le Deoptimizer, nous devons nous en préoccuper lors de la génération de code. D'où l'assemblage écrit à la main.
Voici comment cela fonctionne dans l'architecture x64. Nous l'avons implémenté pour ia32, arm, arm64, mips, et mips64 également.
Cette nouvelle technique est déjà intégrée dans V8 et, comme nous le discuterons plus tard, permet des améliorations de performance. Cependant, elle comporte un léger inconvénient : auparavant, V8 considérait la dissociation uniquement en cas de désoptimisation. Maintenant, il doit le faire lors de l'activation de toutes les fonctions optimisées. De plus, la méthode pour vérifier le bit marked_for_deoptimization n'est pas aussi efficace qu'elle pourrait l'être, étant donné que nous devons effectuer certaines opérations pour obtenir l'adresse de l'objet code. Notez que cela se produit à chaque entrée dans une fonction optimisée. Une solution possible à ce problème est de conserver dans un objet code un pointeur vers lui-même. Plutôt que de faire le travail pour trouver l'adresse de l'objet code à chaque invocation de la fonction, V8 le ferait une fois, après sa construction.
Résultats
Nous examinons maintenant les gains et régressions de performance obtenus avec ce projet.
Améliorations générales sur x64
Le graphique suivant nous montre certaines améliorations et régressions, par rapport au commit précédent. Notez que plus c'est élevé, mieux c'est.
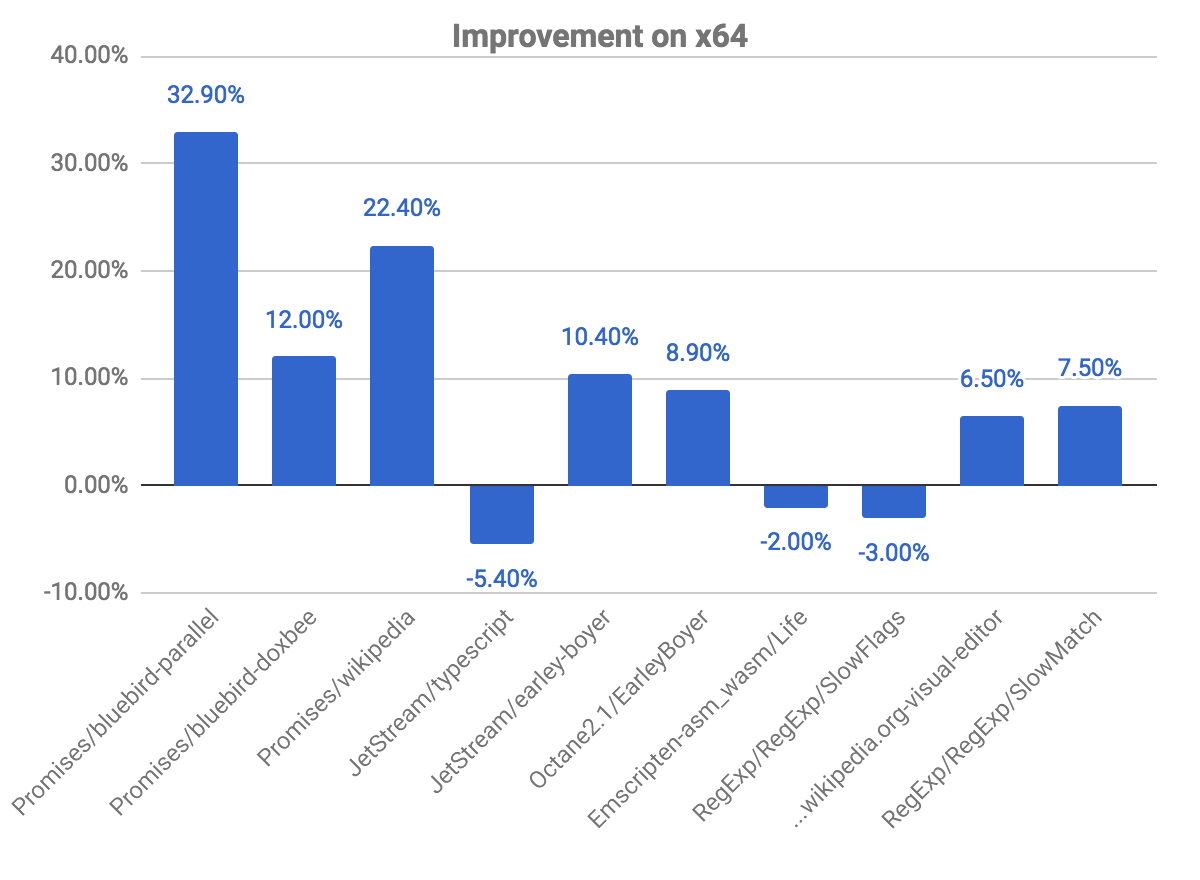
Les benchmarks promises sont ceux où nous observons de plus grandes améliorations, atteignant presque 33% de gain pour le benchmark bluebird-parallel, et 22,40% pour wikipedia. Nous avons également observé quelques régressions dans certains benchmarks. Cela est lié au problème expliqué ci-dessus concernant la vérification de si le code est marqué pour la désoptimisation.
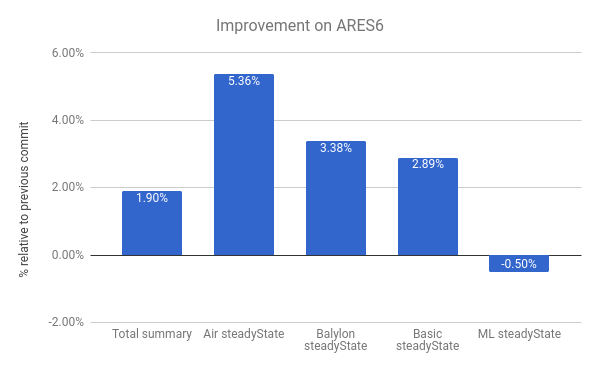
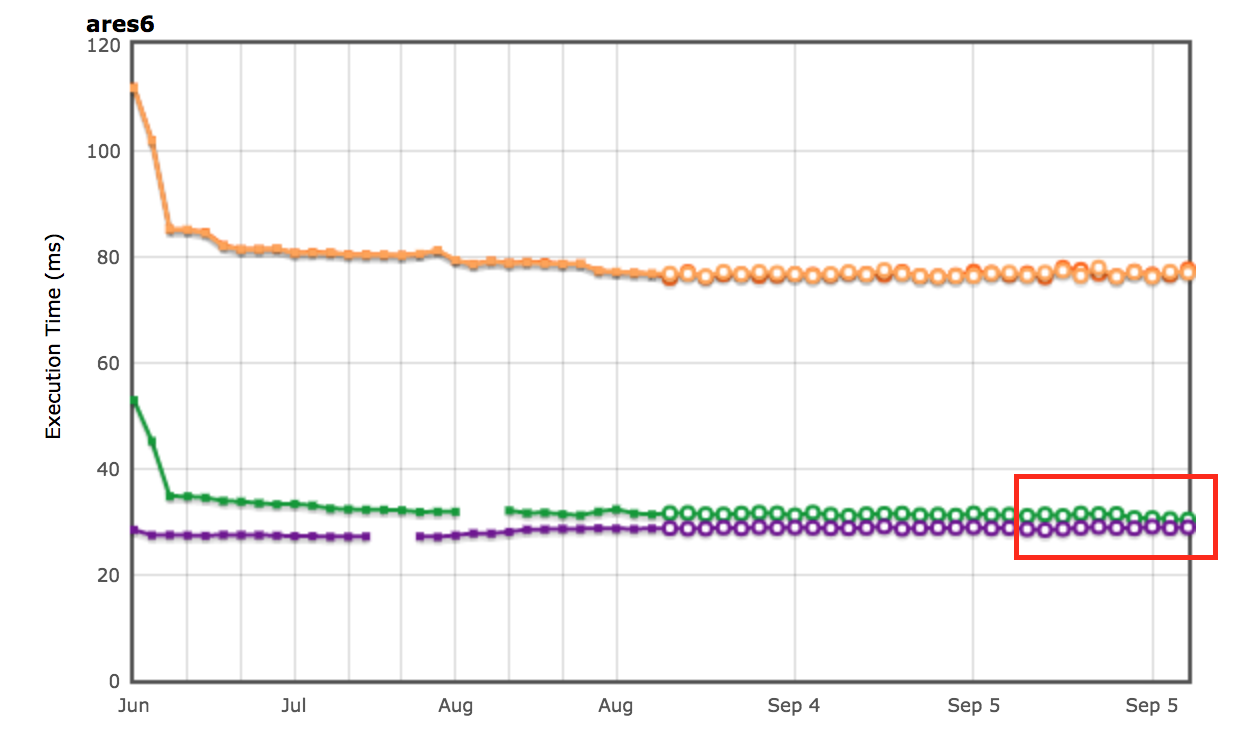
Nous observons aussi des améliorations dans la suite de benchmarks ARES-6. Notez qu'ici aussi, plus le score est élevé, mieux c'est. Ces programmes passaient auparavant une quantité considérable de temps dans des activités liées au GC. Avec le déliage paresseux, nous améliorons les performances de 1,9 % en général. Le cas le plus notable est Air steadyState où nous obtenons une amélioration d'environ 5,36%.
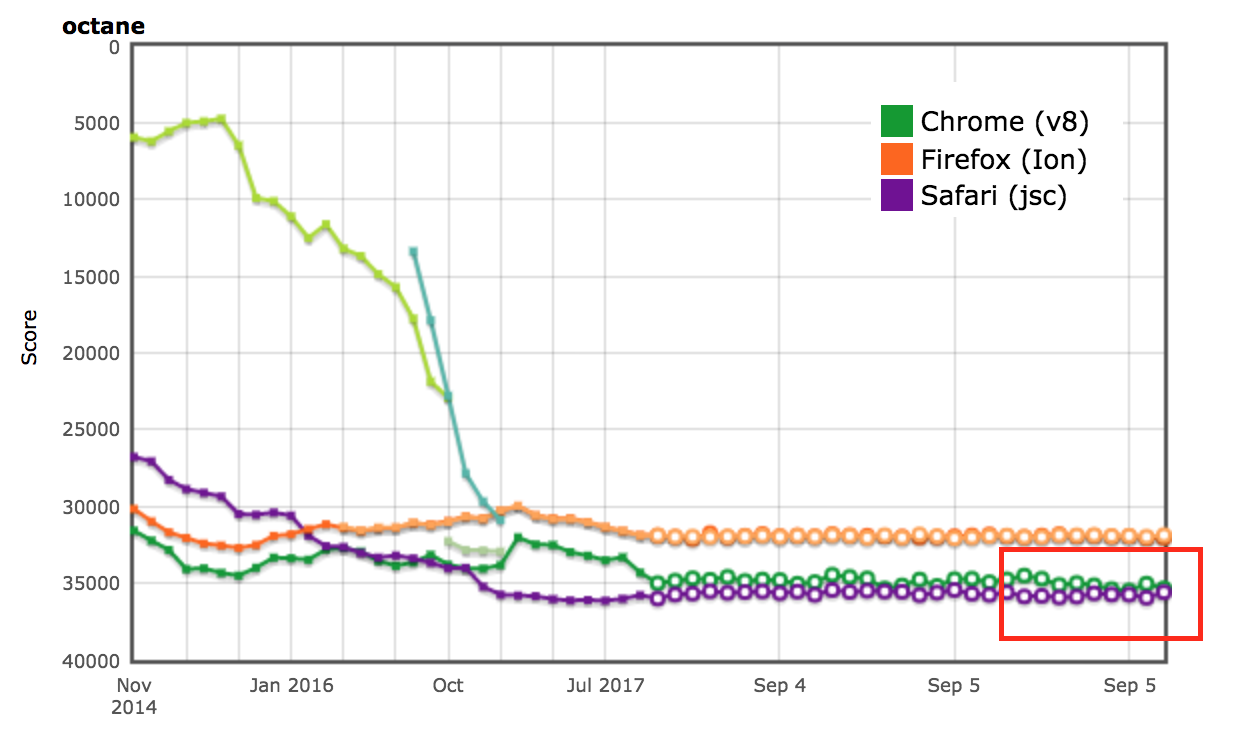
Résultats sur AreWeFastYet
Les résultats de performance pour les suites de benchmarks Octane et ARES-6 ont également été visibles sur le tracker AreWeFastYet. Nous avons examiné ces résultats de performance le 5 septembre 2017, en utilisant la machine par défaut fournie (macOS 10.10 64-bit, Mac Pro, shell).
Impact sur Node.js
Nous pouvons également constater des améliorations de performance dans le router-benchmark. Les deux graphiques suivants montrent le nombre d'opérations par seconde de chaque routeur testé. Ainsi, plus c'est élevé, mieux c'est. Nous avons effectué deux types d'expériences avec cette suite de benchmarks. Premièrement, nous avons exécuté chaque test isolément, afin de pouvoir observer l'amélioration de performance de manière indépendante des autres tests. Deuxièmement, nous avons exécuté tous les tests en même temps, sans redémarrage de la VM, simulant ainsi un environnement où chaque test est intégré à d'autres fonctionnalités.
Pour la première expérience, nous avons constaté que les tests router et express réalisent environ deux fois plus d'opérations qu'auparavant, dans le même laps de temps. Pour la deuxième expérience, nous avons constaté une amélioration encore plus grande. Dans certains cas, tels que routr, server-router et router, le benchmark effectue environ 3,80×, 3× et 2× plus d'opérations, respectivement. Cela se produit parce que V8 accumule davantage de fonctions JavaScript optimisées, test après test. Ainsi, chaque fois qu'un test donné est exécuté, si un cycle de collecte des ordures est déclenché, V8 doit visiter les fonctions optimisées du test en cours et des précédents.


Optimisation supplémentaire
Maintenant que V8 ne conserve plus la liste chaînée des fonctions JavaScript dans le contexte, nous pouvons supprimer le champ next de la classe JSFunction. Bien que cette modification soit simple, elle nous permet d'économiser la taille d'un pointeur par fonction, ce qui représente des économies significatives sur plusieurs pages web :
| Benchmark | Type | Économies de mémoire (absolues) | Économies de mémoire (relatives) |
|---|---|---|---|
| facebook.com | Taille effective moyenne | 170 KB | 3.70% |
| twitter.com | Taille moyenne des objets alloués | 284 KB | 1.20% |
| cnn.com | Taille moyenne des objets alloués | 788 KB | 1.53% |
| youtube.com | Taille moyenne des objets alloués | 129 KB | 0.79% |
Remerciements
Tout au long de mon stage, j'ai reçu beaucoup d'aide de la part de plusieurs personnes, qui étaient toujours disponibles pour répondre à mes nombreuses questions. Je tiens donc à remercier les personnes suivantes : Benedikt Meurer, Jaroslav Sevcik, Michael Starzinger pour leurs discussions sur le fonctionnement du compilateur et du désoptimiseur, Ulan Degenbaev pour son aide avec le ramasse-miettes à chaque fois que je l'endommageais, et Mathias Bynens, Peter Marshall, Camillo Bruni, et Maya Armyanova pour avoir relu cet article.
Enfin, cet article est ma dernière contribution en tant que stagiaire chez Google et je voudrais profiter de cette occasion pour remercier toute l'équipe V8, et particulièrement mon hôte, Benedikt Meurer, pour m'avoir accueilli et m'avoir donné l'opportunité de travailler sur un projet aussi intéressant — j'ai définitivement beaucoup appris et apprécié mon temps chez Google!